自建Hadoop迁移到阿里云EMR
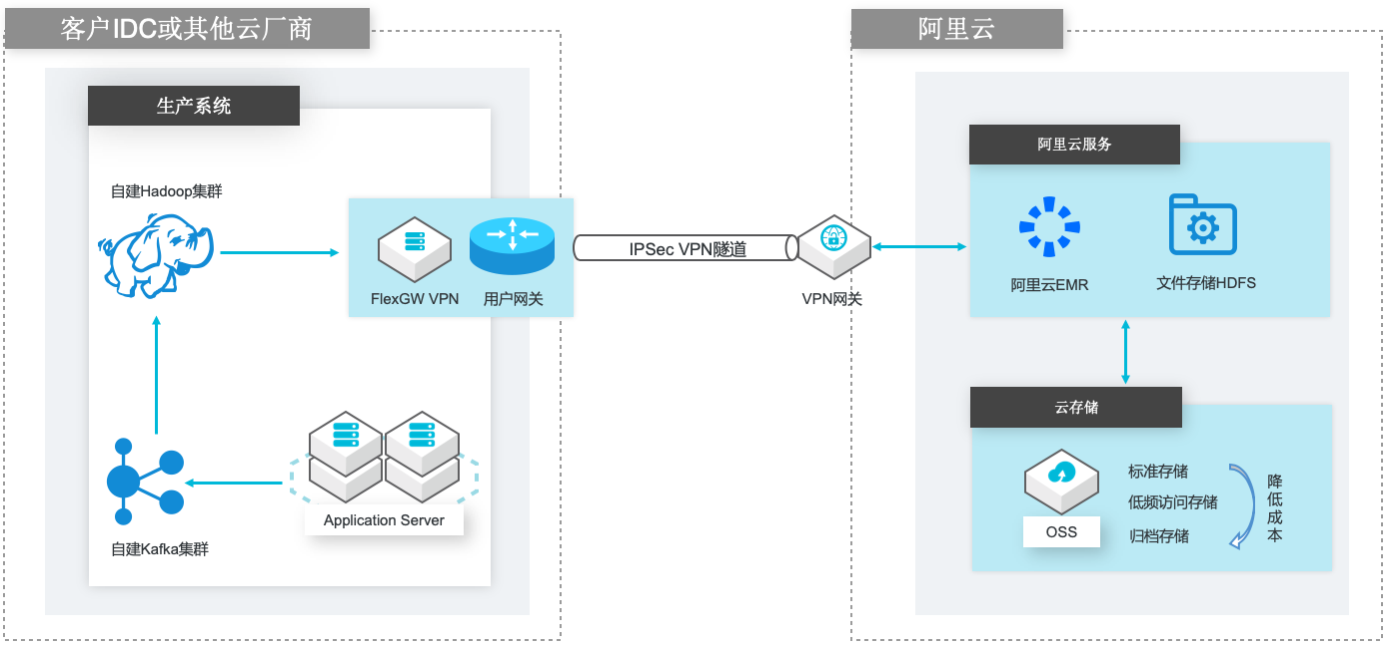
场景描述 场景1:自建Hadoop集群数据(HDFS)迁移到 阿里云EMR集群的HDFS文件系统; 场景2:自建Hadoop集群数据(HDFS)迁移到 计算存储分离架构的阿里云EMR集群,以OSS 和JindoFS作为EMR集群的后端存储。 解决的问题 客户自建Hadoop迁移到阿里云EMR集群的 技术方案; 基于IPSecVPN隧道构建安全和低成本数据 传输链路 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
如下所示(请根据您环境的实际 IP地 址进行修改):192.168.100.37 master 192.168.100.38 slave1 192.168.100.39 slave2 192.168.100.41 slave3 文档版本:20210714 16 自建Hadoop数据迁移到阿里云 EMR 自建 Hadoop集群环境搭建 通过 SSH远程登录 hadoop-master节点所在的 ECS实例,通过 vim编辑器将上面 的信息粘贴到/etc...
电商网站业务安全
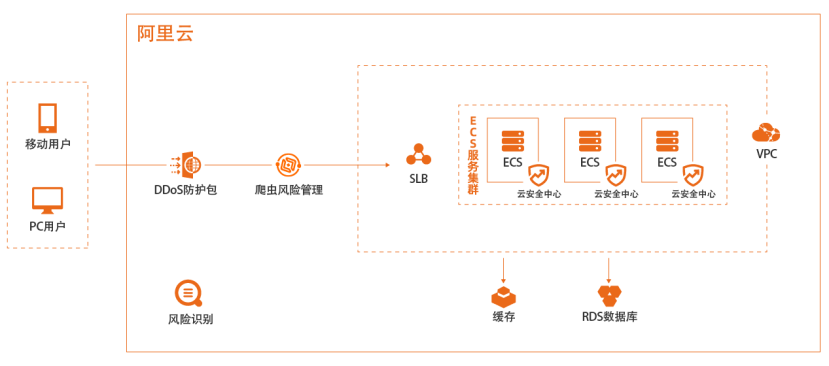
场景描述 业务运营活动是电商行业开展业务必不可少的 手段,但大流量带来的系统可用性、优惠券带来 的“薅羊毛”等问题屡见不鲜,都会影响到运营 效果、甚至出现负面影响。阿里云基于集团电商 业务多年的运营经验,为云上客户提供完整的电 商网站运营期间的防护方案。 解决问题 1.保障业务运维活动系统稳定运行 2.防止“薅羊毛” 3.运营优惠给到真实的客户 产品列表 爬虫风险管理 风险识别 DDoS防护包
运营优惠给到真实的客户 产品列表 Web应用防火墙 风险识别 DDoS防护包 RDS MySQL版 负载均衡 SLB 云服务器 ECS 云速搭 CADT 阿里云最佳实践技术分享群 最佳实践频道 如二维码过期,请搜索群号:31852400 企业上云实践 电商网站业务安全最佳实践|文档版本信息 阿里云 企业上云实践 电商网站业务安全最佳实践 文档版本:...
混合云HBR云上备份VMware虚拟机
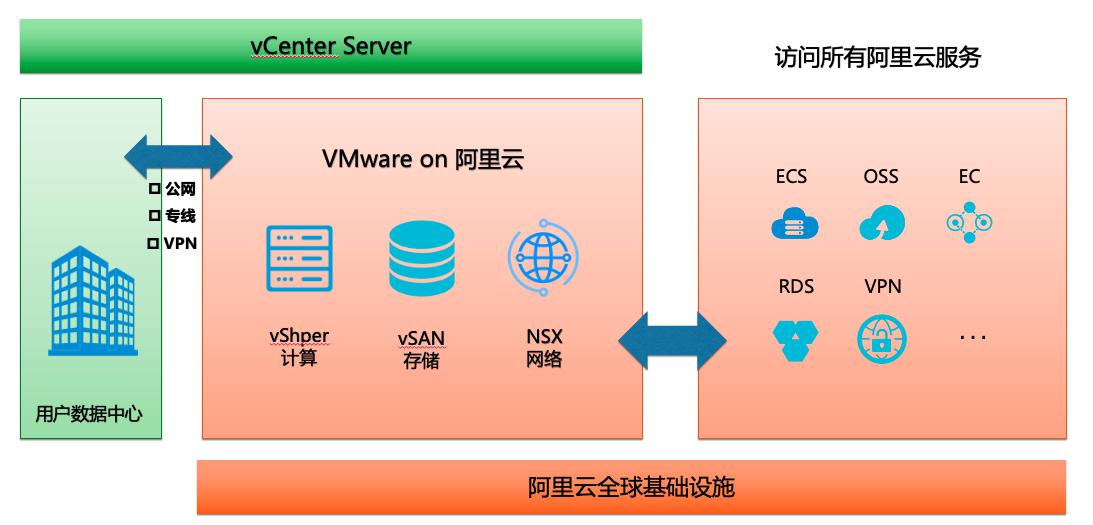
场景描述 本文主要介绍一种简单且具备成本效益的混合云下 的备份解决方案,可以为任何位置的客户虚拟机和数 据提供强有力的保护,包括企业数据中心、远程和分 支机构以及云上资源;支持加密、压缩、重删,保证 数据快速、安全、高效地备份到云上,本文重点介绍 混合云下的VMware虚拟机备份。 解决问题 1.混合云下的备份解决方案。 2.VMware虚拟机备份解决方案。 产品列表 1.弹性裸金属服务器 2.文件系统NAS 3.弹性公网IP 4.NAT网关
ENI:弹性网卡(ElasticNetworkInterface),是一种可附加在专有网络VPC类型 ECS实例上的虚拟网卡,通过弹性网卡,可实现高可用集群搭建、低成本故障转 移和精细化的网络管理。 VPC:专有网络(VirtualPrivateCloud),是用户基于阿里云创建的自定义私有网 络,不同的专有网络之间二层逻辑隔离,用户可以在自己创建的...
VMware on 弹性裸金属
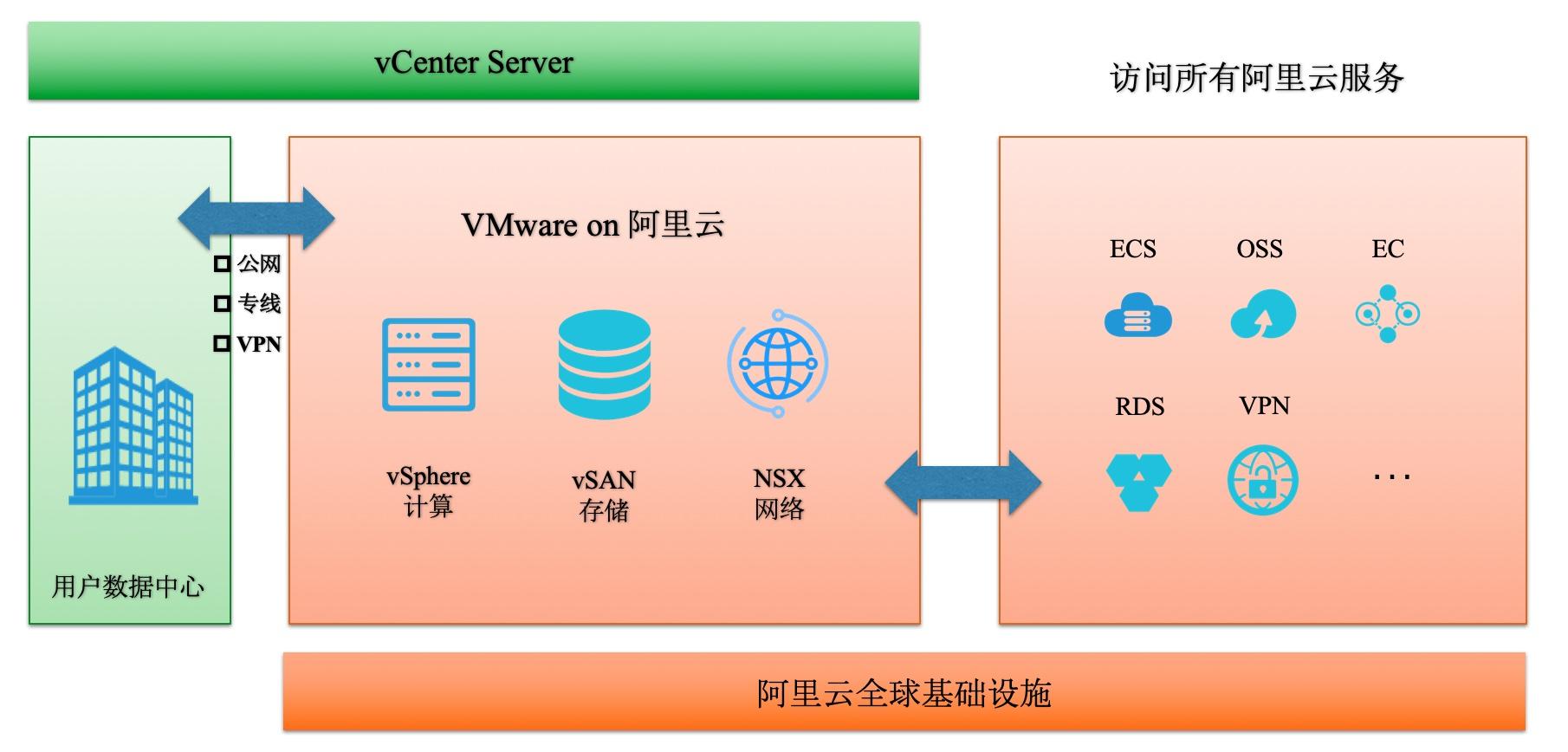
场景描述 传统企业将VMware迁移到阿里云弹性裸 金属,利用云计算平台提供的弹性基础设 施,降低部分运维成本和学习成本,使用其 擅长的技术工具专注自身业务,实现线下业 务平滑迁移上云。 解决问题 1.VMware业务平滑迁移上云 2.集成云产品能力增强业务创新 3.降低混合云成本和复杂度 4.增强系统可用性 产品列表 EBM神龙 ECS NAS OSS ENI NAT EIP
步骤3 将 vCenter ISO 文 件 下 载 拷 贝 到 windows 服 务 器。本 示 例 使 用 VMware-VIM-all-6.5.0-8307201.iso。文档版本:20191121 51 VMwareon弹性裸金属 安装和部署VMware 步骤4 双击vCenter安装文件。步骤5 双击autorun。步骤6 根据安装向导,完成VMwarevCenterServer的安装。1.在适用于Windows的vCenterServer页面...
云基础产品与基础设施
云基础产品与基础设施作为阿里云产品六大版块之一,主要包含弹性计算、存储、网络、安全、云原生应用平台以及无影和基础设施类产品,向客户提供高度自动化的标准化产品对网络功能、计算机(虚拟或专用硬件)和数据存储空间进行访问,同时支持灵活扩展,可以直接使用自助服务界面。
以前构建应用需要买 ECS 实例,搭建开源软件体系然后维护它,根据流量大小扩缩容,整个过程复杂。Serverless 服务可简化这些,从半托管到全托管,所有服务 API 化,无限容量充分弹性,生产力大幅改变.Serverless 奇点已来,下一个十年将驶向何方?网络安全升级支持IPV6.天弘基金成立于2004年11月8日,是经中国证监会批准...
来自:
云产品
混合云存储构建VMware虚拟化平台
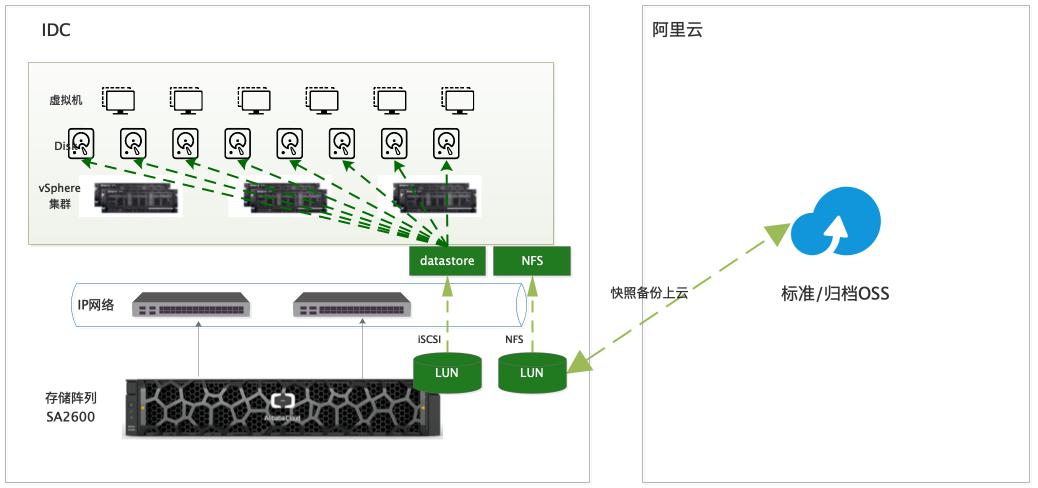
场景描述 本文以混合云存储阵列SA2600系统为例,介绍如 何在混合云存储环境下部署VMware虚拟化平台, 以及混合云环境下虚拟机的部署、扩容、云备份等功 能演示。 解决问题 1.如何使用混合云存储部署VMware虚拟化平台。 2.存储阵列在混合云环境下的使用,比如虚拟机部 署、扩容、云备份等。 产品列表 1.混合云存储阵列 2.对象存储OSS
步骤8 出现重新启动Web服务器界面后等待2分钟左右,直到下一步按钮点亮为止,并单 击下一步。文档版本:20191223 14 混合云存储构建VMware虚拟化平台 存储阵列系统初始化配置 步骤9 此时系统初始化工作已完成,弹出摘要界面,显示了接下来需要执行的操作,按照步 骤完成以后,单击完成即可进入系统的管理界面。说明:系统...
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
文档版本:20210425 6 自建 Hive数据仓库跨版本迁移到阿里云 Databricks数据洞察 基础环境搭建 注:目前 CADT暂不支持 Databricks数据洞察集群搭建,下面将通过控制台操作,为 了更好地模拟用户的自建 Hive1.2.2版本数仓环境,选择在 ECS上安装 4个节点的 Hadoop集群。如果您使用的是 Hive2.x版本可以选择搭建 EMR集群。1.2....
SAP S/4HANA上云最佳实践
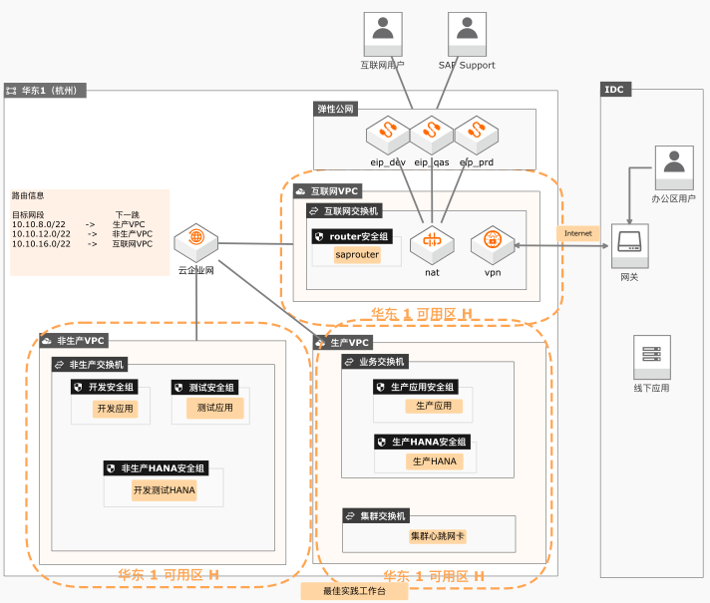
本实践以SAP S/4HANA上阿里云的场景为原型,阐述了如何通过CADT在阿里云上快速交付符合最佳实践的基础云架构。
云服务器 ECS免去了您采购 IT 硬件的前期准备,让您像使用水、电、天然气等公共资源一样便捷、高效地使用服 务器,实现计算资源的即开即用和弹性伸缩。阿里云ECS持续提供创新型服务器,解决多种业务需求,助力您的业务发展。详见:https://www.aliyun.com/product/ecs 云速搭 CADT:是一款为上云应用提供自助式云架构管理的...
CDH迁移升级CDP最佳实践
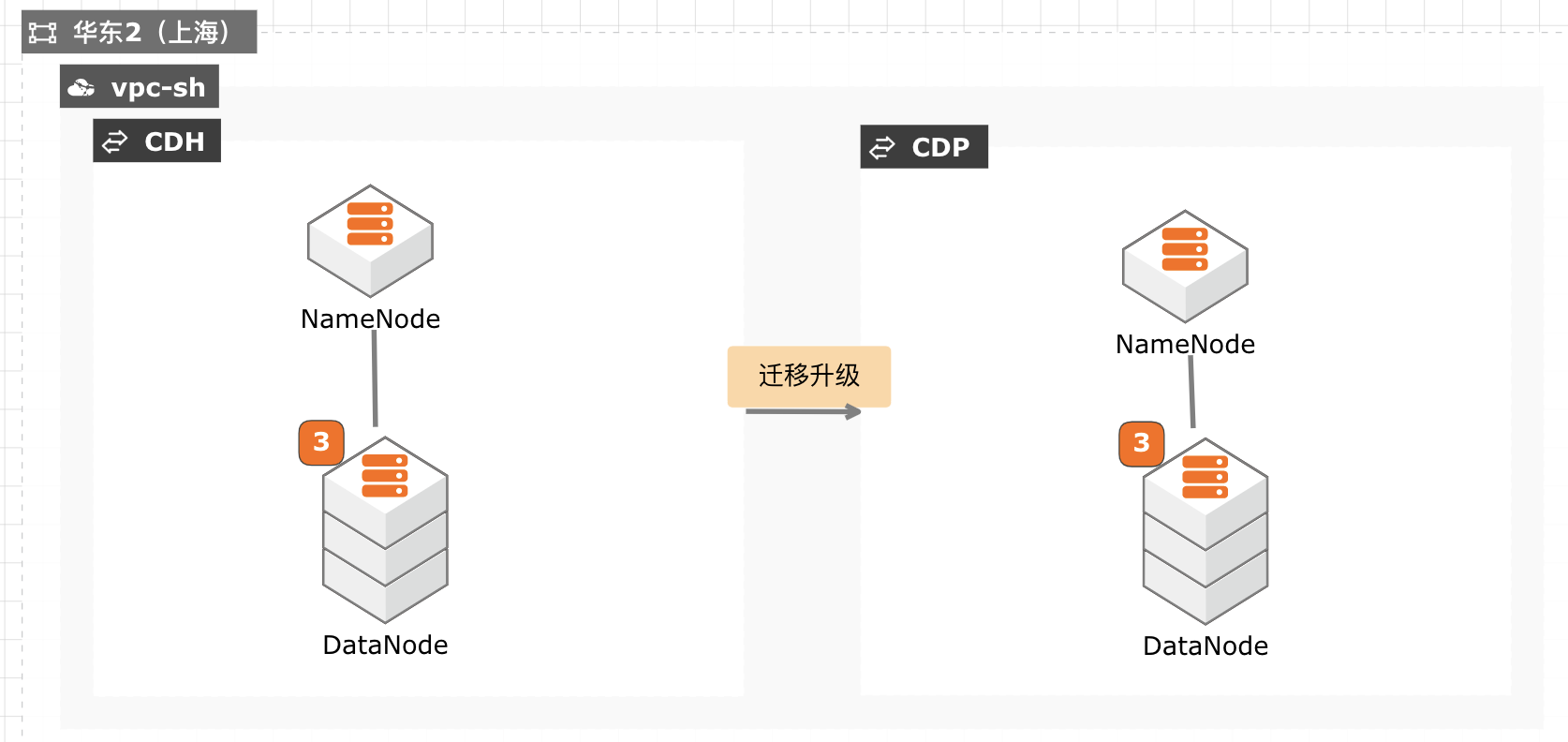
当前 CDH 免费版停止下载,终止服务,针对需要企业版服务能力并且CDH 升级过程对业务影响较小的客户,通过安装新的 CDP 集群,将现有数据拷贝至新集群,然后将新集群切换为生产集群,升级过程没有数据丢失风险,停机时间较短,适合大部分互联网客户升级使用。
数据一致性校验 最佳实践频道 阿里云最佳实践技术分享群 云服务器 ECS(产品名称)文档模板(手册名称)/文档版本信息 阿里云 CDH迁移升级 CDP 最佳实践 文档版本:20211029 文档版本:20150122(发布日期)II CDH迁移升级 CDP最佳实践 文档版本信息 文档版本信息 文本信息 属性 内容 文档名称 CDH迁移升级 CDP最佳实践 ...
云端影视渲染
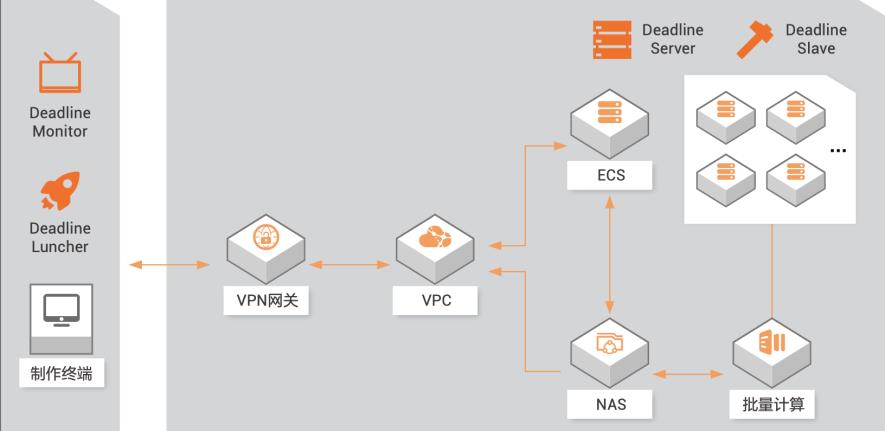
场景描述 本文介绍如何搭建一个完整的混合云渲染服务架构,本地与云端的网络以SSL-VPN方式进行互联。 解决问题 1、使用SSL-VPN构建本地网络与云上VPC环境的安全互联。 2、使用批量计算服务管理渲染计算集群,集群计算节点自动加入Deadline资源池。 3、使用Deadline做渲染任务管理。 4、批量计算集群计算节点根据Deadline渲染任务自动扩容和收缩,资源管理自动化。 产品列表 1、云服务器ECS 2、GPU云服务器GPU 3、批量计算BCS 4、专有网络VPC 5、弹性公网IP 6、文件存储NAS
产品列表 云服务器 ECS GPU云服务器 GPU 批量计算 BCS 专有网络 VPC 弹性公网 IP EIP VPN网关 VPN 文件存储 NAS 阿里云最佳实践技术分享群 最佳实践频道 如二维码过期,请搜索群号:31852400 云服务器 ECS(产品名称)文档模板(手册名称)/文档版本信息 阿里云 企业上云实践 云端影视渲染 最佳实践 文档版本:20200220 ...
EMR本地盘实例大规模数据集测试
场景描述 阿里云为了满足大数据场景下的存储需求,在云 上推出了本地盘D1机型,这个系列提供了本地 盘而非云盘作为存储,提高了磁盘的吞吐能力, 发挥Hadoop的就近计算优势。阿里云EMR 产品针对本地盘机型,推出了一整套的自动化运 维方案,帮助用户方便可靠地使用本地盘机型, 不需要关注整个运维过程同时数据的高可靠和 服务的高可用。 解决问题 1.云盘多份冗余数据导致成本高 2.磁盘吞吐量不高 3.节点的高可靠分布问题 4.本地盘与节点的故障监控问题 5.数据迁移时自动决策问题 6.自动故障节点迁移与数据平衡问题 产品列表 EMR(E-MapReduce) 本地盘 VPC
Hue(Hadoop User Experience)是一个开源的 Apache Hadoop UI 系统,最早是由 Cloudera.Desktop演化而来,由 Cloudera贡献给开源社区,它是基于 Python Web 框架 Django实现的,通过使用 Hue可以在浏览器的 Web控制上与 Hadoop集群来进 行交互分析来处理数据,例如操作 HDFS上的数据,管理和查询 Hive数据库的数据 等等。...
数据湖-在线学习场景数据分析

场景描述 本场景以在线教育中一个答题闯关类的应用为 例,使用WebServer来模拟演示这类日志数据 的分析处理。通过Nginx和Pythonflask搭建 WebServer,模拟应用中的关键页面,比如登 录、课程内容等,之后构造若干用户使用的模拟 日志数据,投递到数据湖进行分析后获取应用 PV、UV、课程内容访问排行、平均得分等等。 解决问题 基于数据湖(EMR+OSS)搭建大数据平台。 EMR和OSS使用和配置。 数据统一存储到OSS。 产品列表 E-MapReduce 对象存储OSS 云服务器ECS 访问控制RAM 专有网络VPC
通过Nginx和Python flask搭建Web Server,模拟应用中的关键页面,比如登录、课程 内容等,之后构造若干用户使用的模拟日志数据,投递到数据湖进行分析后获取应用PV、UV、课程 内容访问排行、平均得分等等。解决问题 1.基于数据湖(EMR+OSS)搭建大数据平台。2.EMR和OSS使用和配置。3.数据统一存储到OSS。产品列表 E-...
混合云自有K8S弹性使用ECI
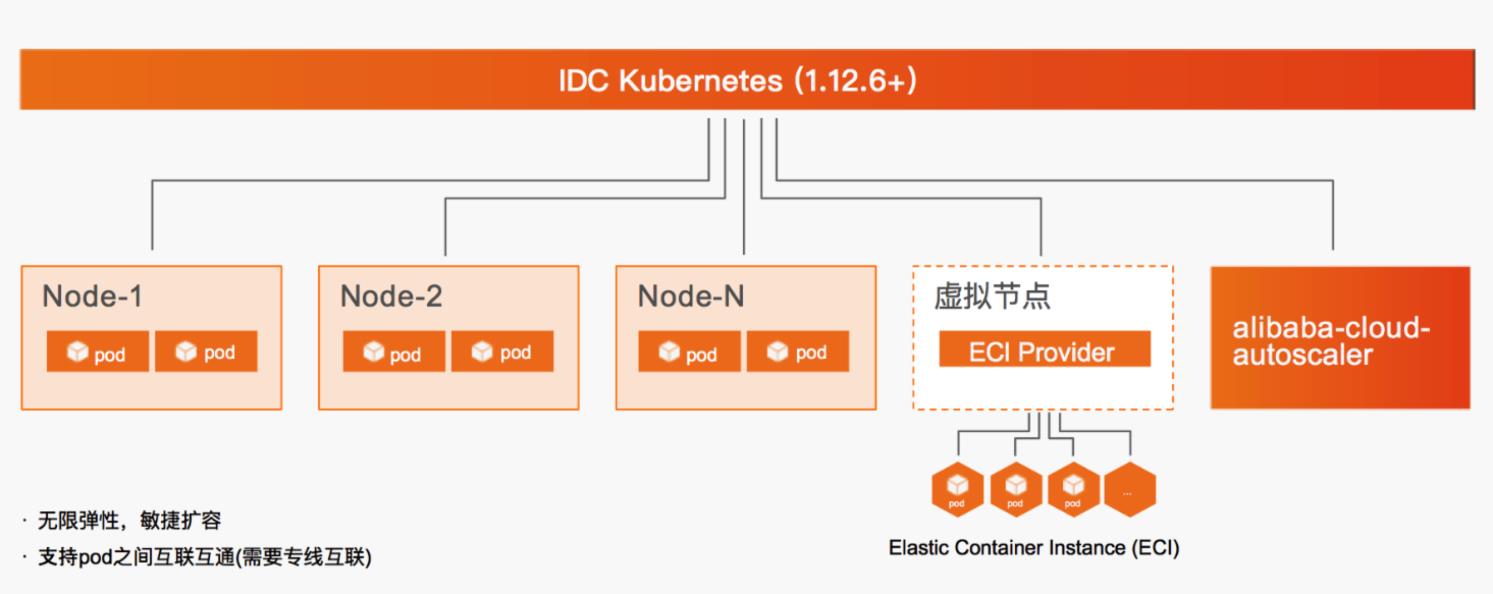
场景描述 本文介绍线下IDC与云端通过专线构建混合云架构,自有K8S利用虚拟节点弹性调用ECI承载业务高峰期资源需求的最佳实践。 解决问题 混合云环境下,自有K8S集群注册至ACK,实现云端纳管。纳管K8S集群部署Virtual Node,使集群具备ECI资源调度能力。在以上环境中部署Web及离线作业应用,并使用ECI资源作为弹性资源池满足业务波峰需求。 产品列表 云服务器ECS 云架构设计工具CADT 专有网络VPC 访问控制RAM 云企业网CEN 弹性容器实例ECI Nat网关NAT 容器镜像服务ACR 负载均衡SLB 容器服务Kubernetes版ACK 弹性公网IPEIP
混合云 IDC自有 K8S弹性使用 ECI 最佳实践 业务架构 场景描述 解决问题 混合云环境下,自有 K8S集群注册至 ACK,本文介绍线下 IDC与云端通过专线构建混合云架构,自 实现云端纳管。纳管 K8S集群部署 Virtual Node,使集群具备 有 K8S利用虚拟节点弹性调用 ECI承载业务高峰期资 ECI资源调度能力。在以上环境中部署 Web应用,...
Spark on ECI大数据分析

场景描述 方案优势 1.计算引擎弹性扩缩容,兼顾资源弹性与计 算资源成本优化。 2.计算与存储分离架构,结合阿里云原生云 存储产品,海量数据湖优势。 3.Kubernetes原生的调度性能优势,提升在 大规模分析作业时的分析性能优势分。 4.集群资源隔离和按需分配。 解决问题 1.计算资源弹性能力不足,计算资源成本管 控能力欠缺. 2.集群资源调度能力和隔离能力不足。 3.计算与存储无法分离,大数据量分析时出 现数据存储资源瓶颈。 4.Spark submit方式提交分析作业参数支持 有限等缺点。 产品列表 容器服务Kubernetes版(ACK) 弹性容器实例(ECI) 文件存储HDFS 对象存储OSS 专有网络VPC 容器镜像服务ACR
如果我 们想提升作业的运行速度,就需要提升并发的 Spark executor Pod的数量,如果我们 将并发的 Spark executor Pod的数量修改为 10,再次提交作业,由于测试使用的集 群是 2台 2核 8GB的 ECS搭建的,集群资源是非常有限的,因此会出现由于集群 Worker节点的 CPU资源不足无法起更多的 Spark executor Pod导致没有办法提升...
容器跨可用区高可用
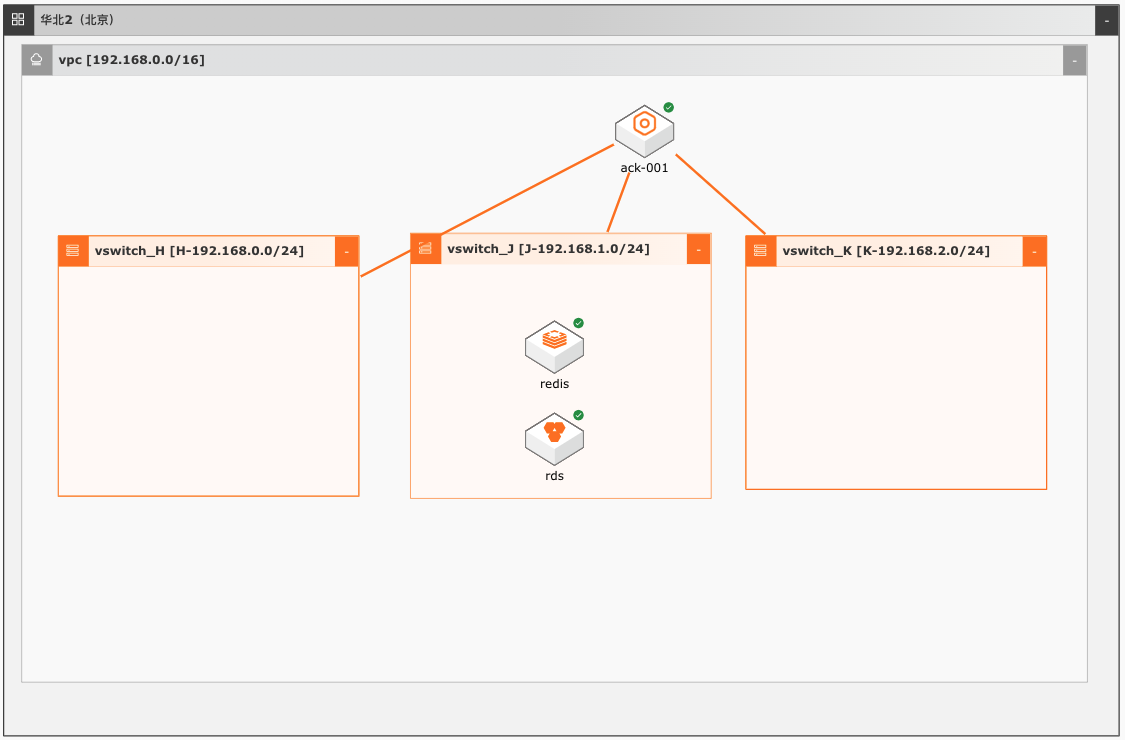
场景描述 本实践适合使用容器服务ACK结合阿里云上的 其他产品构建跨可用区高可用应用的场景。在一 开始创建容器服务ACK的时候就把容器集群建 成多个可用区的架构,某可用区挂掉后,不影响 应用和集群的高可用。容器服务ACK通常配合 高可用SLB,RDS,Redis等产品,实现跨可用 区高可用。 解决问题 1.利用容器服务ACK搭建跨可用区高可用 的应用 2.容器服务ACK结合SLB,RDS,REDIS构 建高可用应用 产品列表 容器服务ACK RDSforMysql版 云数据库Redis版 文件存储NAS
解决问题 利用容器服务 ACK搭建跨可用区高可用 产品列表 的应用 容器服务 ACK 容器服务 ACK结合 SLB,RDS,REDIS构 RDS for Mysql版 建高可用应用 云数据库 Redis 版 文件存储 NAS 云速搭 CADT 最佳实践频道 阿里云最佳实践分享群 云服务器 ECS(产品名称)文档模板(手册名称)/文档版本信息 阿里云 企业上云实践 容器跨...
传统企业业务上云基础安全防护
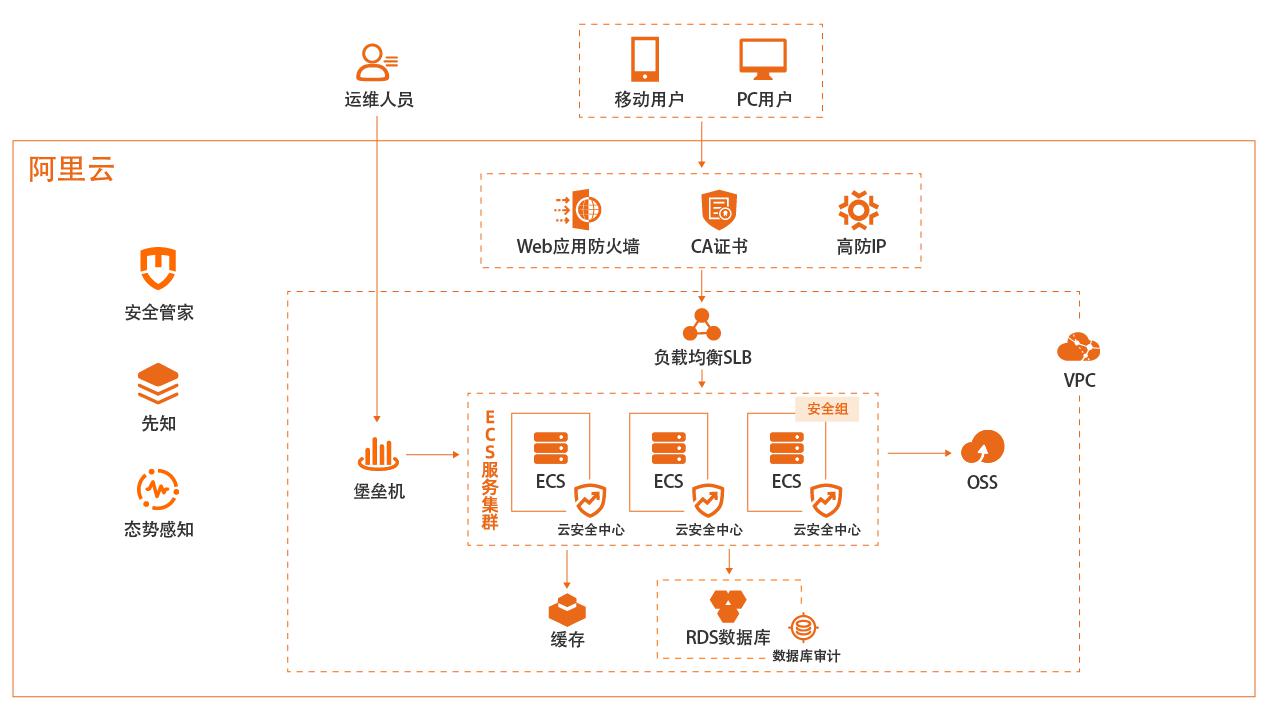
场景描述 越来越多的企业客户选择把自己的生产系统部 署在公共云平台上,以满足自身业务的发展及弹 性扩缩容、稳定性等方面的需求。如何在公共云 上构建基本的网络安全、主机安全、入侵检测、 运维审计等方案,是企业首选的最佳实践。 解决问题 1.服务器安全、应用安全 2.网络安全、数据安全 3.安全审计、安全管理 产品列表 云安全中心 Web应用防火墙 云防火墙 SSL证书 数据库审计 堡垒机
cd/var/www/html/pma/ vimconfig.inc.php 修改前 修改后 文档版本:20220210 115传统企业业务上云基础安全防护 数据库审计 步骤2 重启web服务器。systemctlrestarthttpd 7.3.2.2.制造ECS上SQL日志 步骤1 通过ECS公网IP地址(http://47.xxx.xxx.169/pma/)访问phpMyAdmin的管理页,并 登录phpMyAdmin。步骤2 执行一些查询...
Hyper-V on 弹性裸金属最佳实践
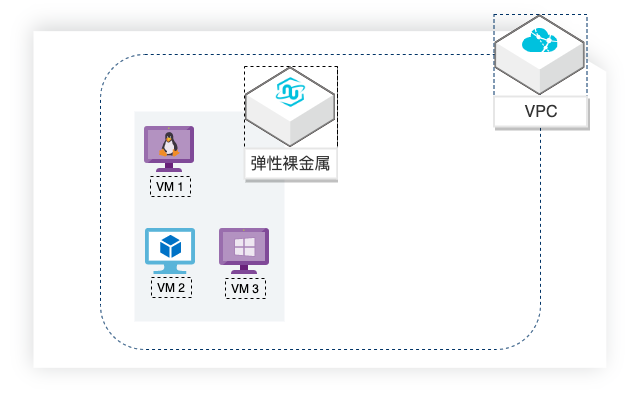
场景描述 本方案适用于基于弹性裸金属服务器(神龙)自 建Microsoft Hyper-V环境的场景。 解决问题 l使用神龙自建+Microsoft Hyper-V虚拟 化环境环境。 l创建LinuxHyper-VVM。 lHyper-VVM访问外部网络。 l外部网络访问Hyper-VVM上的服务。 产品列表 l神龙GPU云服务器(ecs.ebmg5s) l专有网络VPC
解决问题 使用神龙自建+Microsoft Hyper-V虚拟化环境 环境 创建 Linux Hyper-V VM Hyper-V VM访问外部网络 外部网络访问 Hyper-V VM上的服务 部署架构 产品列表 神龙 GPU云服务 专有网络 VPC 弹性公网 IP 云速搭 CADT 最佳实践频道 阿里云最佳实践分享群 云服务器 ECS(产品名称)文档模板(手册名称)/文档版本信息 阿里云...
基于ALB的统一流量调度和监控
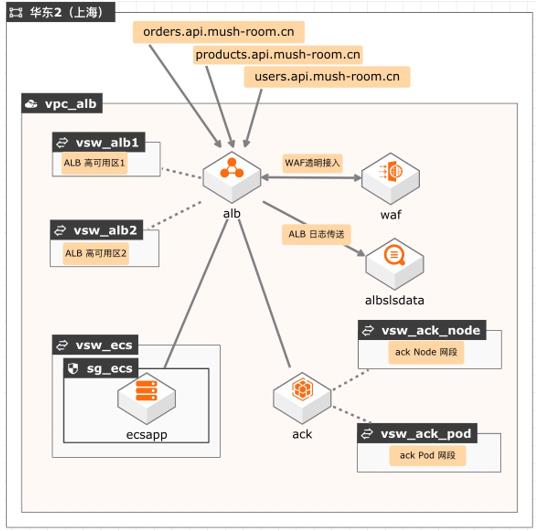
企业在走向容器化过渡阶段,内部同时存在ECS应用和容器应用的情况,在多域名业务场景下,为了对应用的入方向流量进行统一的调度和监控,可通过ALB快速完成内部应用统一流量的管控。 典型场景 多域名转发到混合应用类型场景。 方案优势 1、 高弹性,高并发 2、 减少SLB+EIP数量 3、 一键WAF透明接入 4、 配置简单易上手 5、 统一流量运营分析
云服务器 ECS免去了您采购 IT 硬件的前期准备,让您像使用水、电、天然气等公共资源一样便捷、高效地使用服 务器,实现计算资源的即开即用和弹性伸缩。阿里云ECS持续提供创新型服务器,解决多种业务需求,助力您的业务发展。详见:https://www.aliyun.com/product/ecs 云速搭 CADT:是一款为上云应用提供自助式云架构管理的...
- 产品推荐
- 这些文档可能帮助您