自建Hadoop迁移MaxCompute
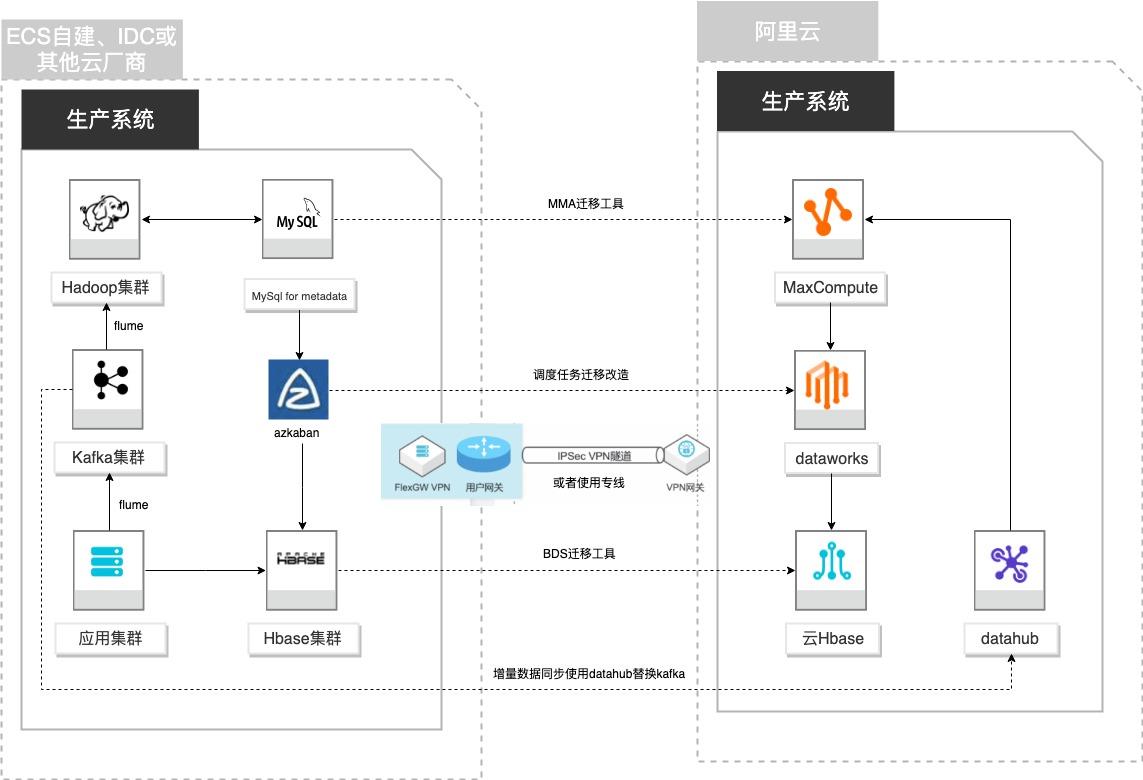
场景描述 客户基于ECS、IDC自建或在友商云平台自建了大数 据集群,为了降低企业大数据计算平台的成本,提高 大数据应用开发效率,更有效保障数据安全,把大数 据集群的数据、作业、调度任务以及业务数据库整体 迁移到MaxCompute和其他云产品。 解决的问题 自建Hadoop集群搬迁到MaxCompute 自建Hbase集群搬迁到云Hbase 自建Kafka或应用数据准实时同步到 MaxCompute 自建Azkaban任务迁移到Dataworks任务 产品列表 MaxCompute,Dataworks、云数据库Hbase版、Datahub、VPC,ECS。
VPN网关 VPN网关是一款基于 Internet的网络连接服务,通过加密通道的方式实现企业数 据中心、企业办公网络或 Internet终端与阿里云专有网络(VPC)安全可靠的连 接。VPN 网关提供 IPSec-VPN 连接和 SSL-VPN 连接。详情请查看 https://www.aliyun.com/product/vpn IPSec VPN 基于路由的 IPSec-VPN,不仅可以更方便的配置和...
多账号下企业分账
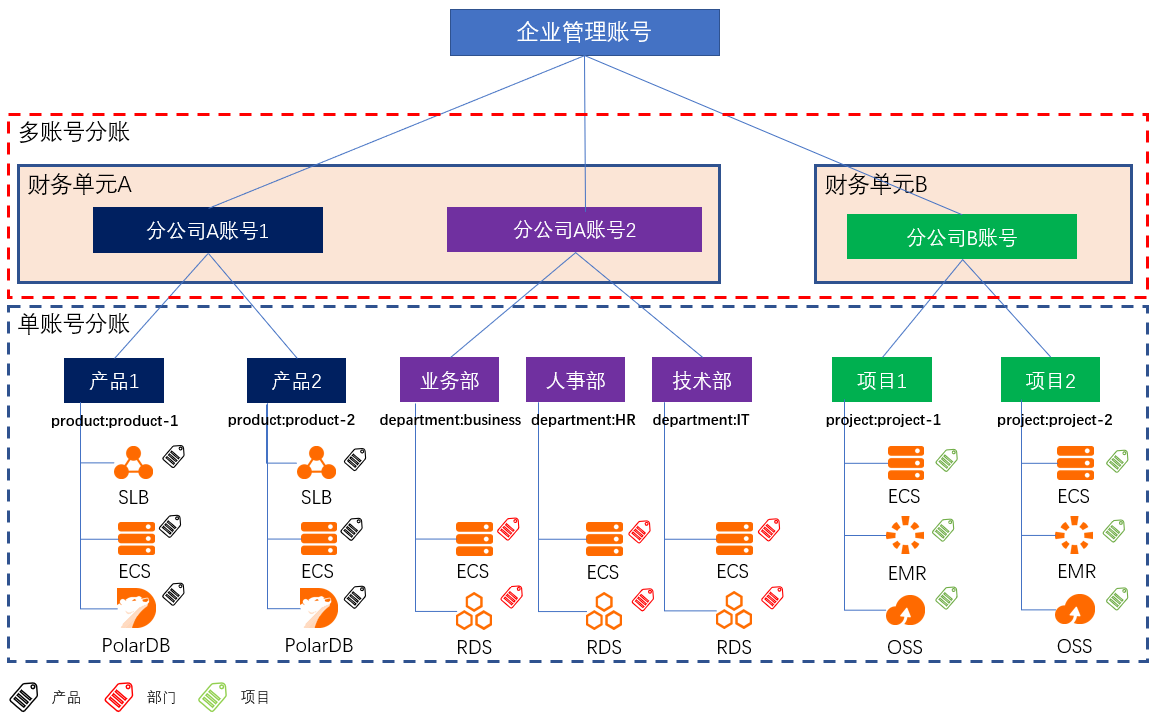
场景描述 财务分账,是根据企业的成本中心,将云上资源的成本划分到给各个项目组/业务部门;助力企业快速梳理云上成本结构,搭建复杂组织架构下的成本关系,便捷地进行财务和云上成本的管理。 大型企业或集团公司,由于组织架构复杂,业务复杂等原因,通常拥有多个阿里云账号来管理规模庞大的云上资源。针对云上资源,如何建立有效的分账方案,是财务关注的重要问题。 解决问题 解决CIO/CTO最关心的云上IT治理,IT成本核算等问题。 弄清楚企业内各部门成本及云上IT成本结构。 让CIO/CTO准确地掌握云上资源成本情况,清楚业务与成本的关系。 让采购/运维轻松搞定每月的IT成本汇报。
基 于阿里云分布式文件系统和 SSD盘高性能存储,RDS支持 MySQL、SQL Server、PostgreSQL、PPAS(Postgre Plus Advanced Server,高度兼容 Oracle数据库)和 MariaDB TX引擎,并且提供了容灾、备份、恢复、监控、迁移等方面的全套解 决方案。详见:https://www.aliyun.com/product/rds/mysql 负载均衡 SLB:阿里云提供全托管...
实时数仓Hologres
Hologres(原交互式分析)是一站式实时数据仓库引擎,支持海量数据实时写入、实时更新、实时分析,支持标准SQL(兼容PostgreSQL协议),支持PB级数据多维分析(OLAP)与自助分析(Ad Hoc),支持高并发低延迟的在线数据服务(Serving),与MaxCompute、Flink、DataWorks深度融合,提供离在线一体化全栈数仓解决方案。
实时数仓Hologres(原交互式分析).Hologres是一站式实时数据仓库引擎,支持海量数据实时写入、实时更新、实时分析,支持标准SQL(兼容PostgreSQL协议),支持PB级数据多维分析(OLAP)与即席分析(Ad Hoc),支持高并发低延迟的在线数据服务(Serving),与MaxCompute、Flink、DataWorks深度融合,提供离在线一体化全栈数仓...
来自:
云产品
阿里云最佳实践离线大数据workshop

本最佳实践,首先搭建一个简化的电商 demo 系统,然后为此 demo 系统构建一套离 线大数据分析系统。 实践目标 1. 学习搭建一个离线大数据分析系统,学习从数据采集到数据存储和业务分析的业 务流程。 2. 整个离线大数据分析系统全部基于阿里云产品进行搭建,学习掌运用各个服务组 件及各个组件之间如何联动。 背景知识要求 熟练掌握 SQL 语法 对大数据体系系统知识有一定的了解
MaxCompute向用户提供了完善的数据导入方 案以及多种经典的分布式计算模型,能够更快速的解决用户海量数据计算问题,有 效 降 低 企 业 成 本,并 保 障 数 据 安 全。详 见:https://help.aliyun.com/product/27797.html Dataworks:DataWorks基于MaxCompute/EMR/MC-Hologres等大数据计算引 文档版本:20210802(发布...
来自:
最佳实践
相关产品:云服务器ECS,云数据库RDS MySQL 版,对象存储 OSS,日志服务(SLS),大数据计算服务 MaxCompute,DataV数据可视化,数据总线,Quick BI,云速搭
基于Flink+ClickHouse构建实时游戏数据分析
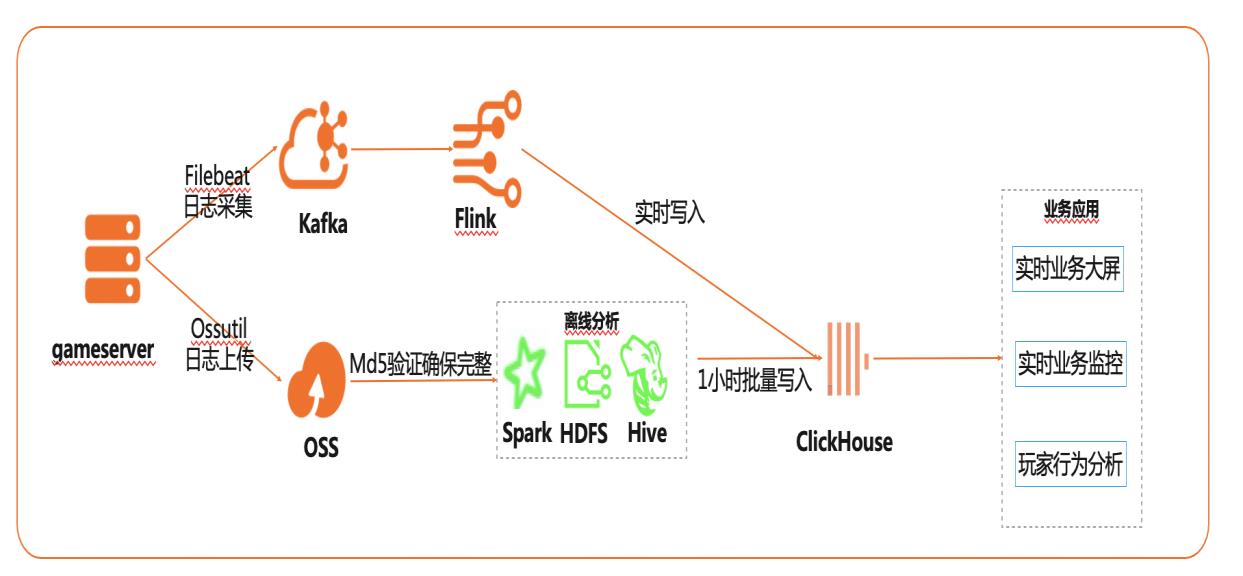
在互联网、游戏行业中,常常需要对用户行为日志进行分析,通过数据挖掘,来更好地支持业务运营,比如用户轨迹,热力图,登录行为分析,实时业务大屏等。当业务数据量达到千亿规模时,常常导致分析不实时,平均响应时间长达10分钟,影响业务的正常运营和发展。 本实践介绍如何快速收集海量用户行为数据,实现秒级响应的实时用户行为分析,并通过实时流计算Flink/Blink、云数据库ClickHouse等技术进行深入挖掘和分析,得到用户特征和画像,实现个性化系统推荐服务。 通过云数据库ClickHouse替换原有Presto数仓,对比开源Presto性能提升20倍。 利用云数据库ClickHouse极致分析性能,千亿级数据分析从10分钟缩短到30秒。 云数据库ClickHouse批量写入效率高,支持业务高峰每小时230亿的用户数据写入。 云数据库ClickHouse开箱即用,免运维,全球多Region部署,快速支持新游戏开服。 Flink+ClickHouse+QuickBI
关键技术选型 1.1.ClickHouse vs Presto 面对海量的数据,我们如何进行数据库的选项,这里对比了开源的两种常见分析性数 据库。ClickHouse对数据采用有序存储的方式,其核心思想是充分利用了磁盘批量顺序读写 的性能要远远高于随机读写的特征,并且结合 LSM tree的设计进一步进行优化,使得 写性能达到最优(可达到 200MB/S...
自建Hive数仓迁移到阿里云EMR
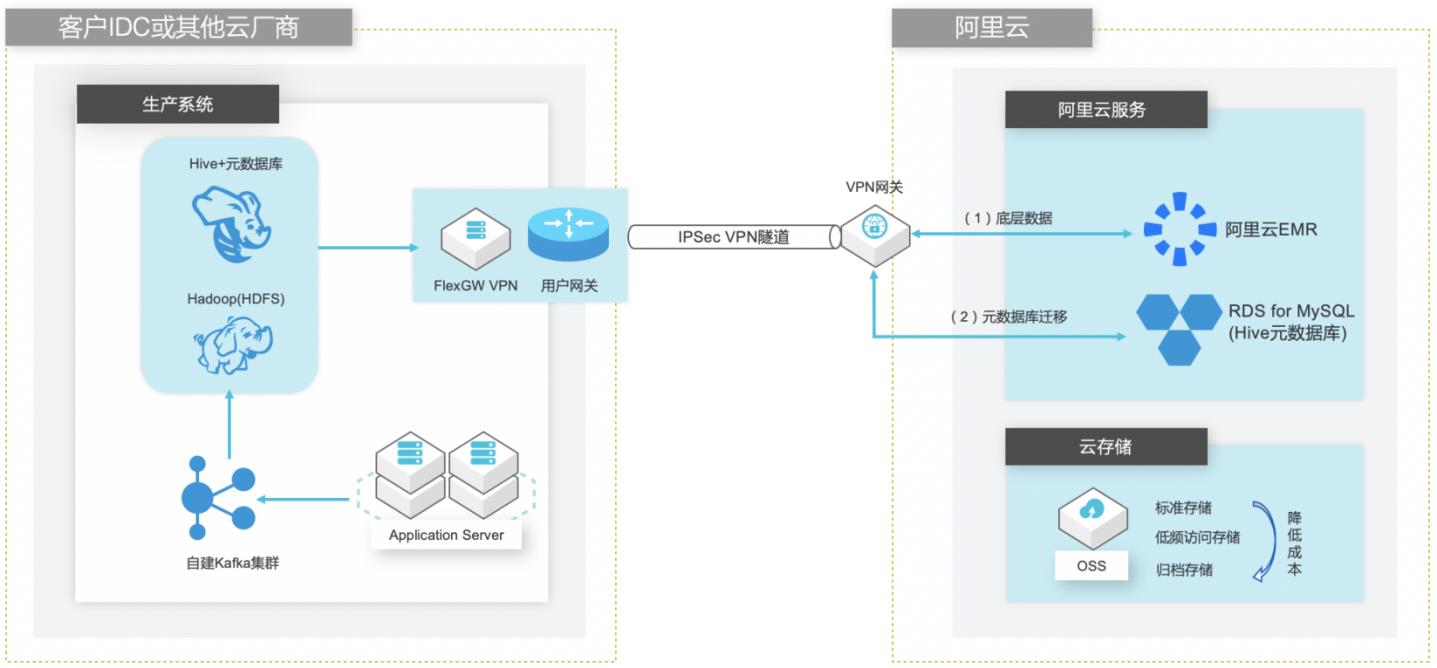
场景描述 客户在IDC或者公有云环境自建Hadoop集群构 建数据仓库和分析系统,购买阿里云EMR集群之 后,涉及到将数据仓库和Hive元数据的数据库迁 移上云。目前主流Hive数据仓库迁移场景为1.x 版本迁移到阿里云EMR(Hive2.x版本),涉及到 数据订正更新步骤。 解决的问题 Hive数据仓库的数据迁移方案 Hive元数据库的迁移方案 Hive跨版本迁移后的数据订正 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
步骤2 部署完成后,重启 Hive MetaStore和 HiveServer2 步骤3 由于在创建 EMR集群时我们指定了 RDS for MySQL实例的数据库作为 Hive的元数 据库,但是此时元数据库还未创建,因此在 EMR控制台可以看到 Hive MetaStore服 务异常停止。文档版本:20210721 25 自建Hive数据仓库跨版本迁移到阿里云 EMR 创建 EMR集群 通过查看 ...
EMR集群安全认证和授权管理
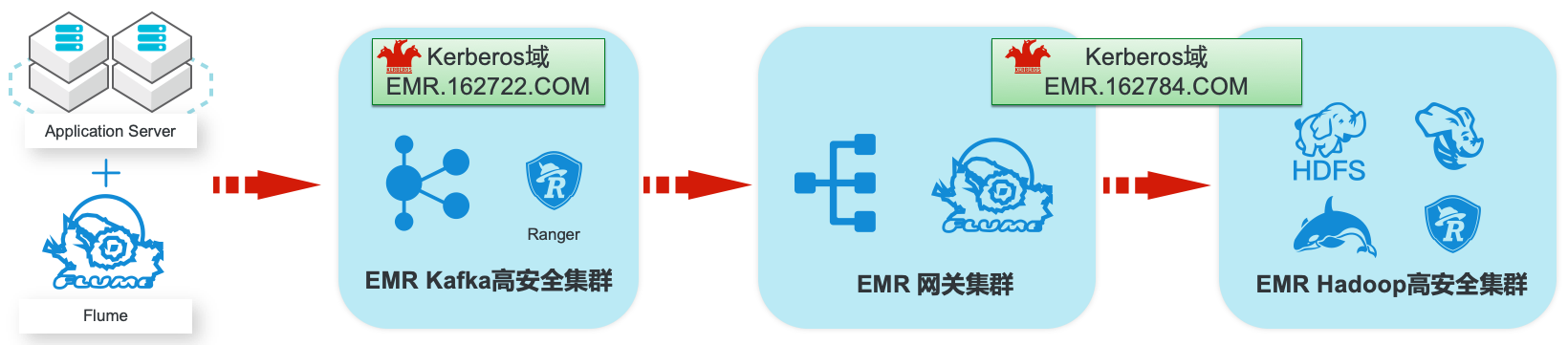
场景描述 阿里云EMR服务Kafka和Hadoop安全集群使 用Kerberos进行用户安全认证,通过Apache Ranger服务进行访问授权管理。本最佳实践中以 Apache Web服务器日志为例,演示基于Kafka 和Hadoop的生态组件构建日志大数据仓库,并 介绍在整个数据流程中,如何通过Kerberos和 Ranger进行认证和授权的相关配置。 解决问题 1.创建基于Kerberos的EMR Kafka和 Hadoop集群。 2.EMR服务的Kafka和Hadoop集群中 Kerberos相关配置和使用方法。 3.Ranger中添加Kafka、HDFS、Hive和 Hbase服务和访问策略。 4.Flume中和Kafka、HDFS相关的安全配 置。 产品列表:E-MapReduce、专有网络VPC、云服务器ECS、云数据库RDS版
详见:https://web.mit.edu/kerberos/krb5-1.4/krb5-1.4.1/doc/krb5- admin/domain_realm.html [capaths]为了执行直接(非分层)跨领域身份验证,需要一个数据库来构造领域 之间的 身份 验 证路径,本节用于定 义该 数 据库。详见:https://web.mit.edu/kerberos/krb5-1.4/krb5-1.4.1/doc/krb5-admin/capaths.html 文档版本...
CDH迁移升级CDP最佳实践
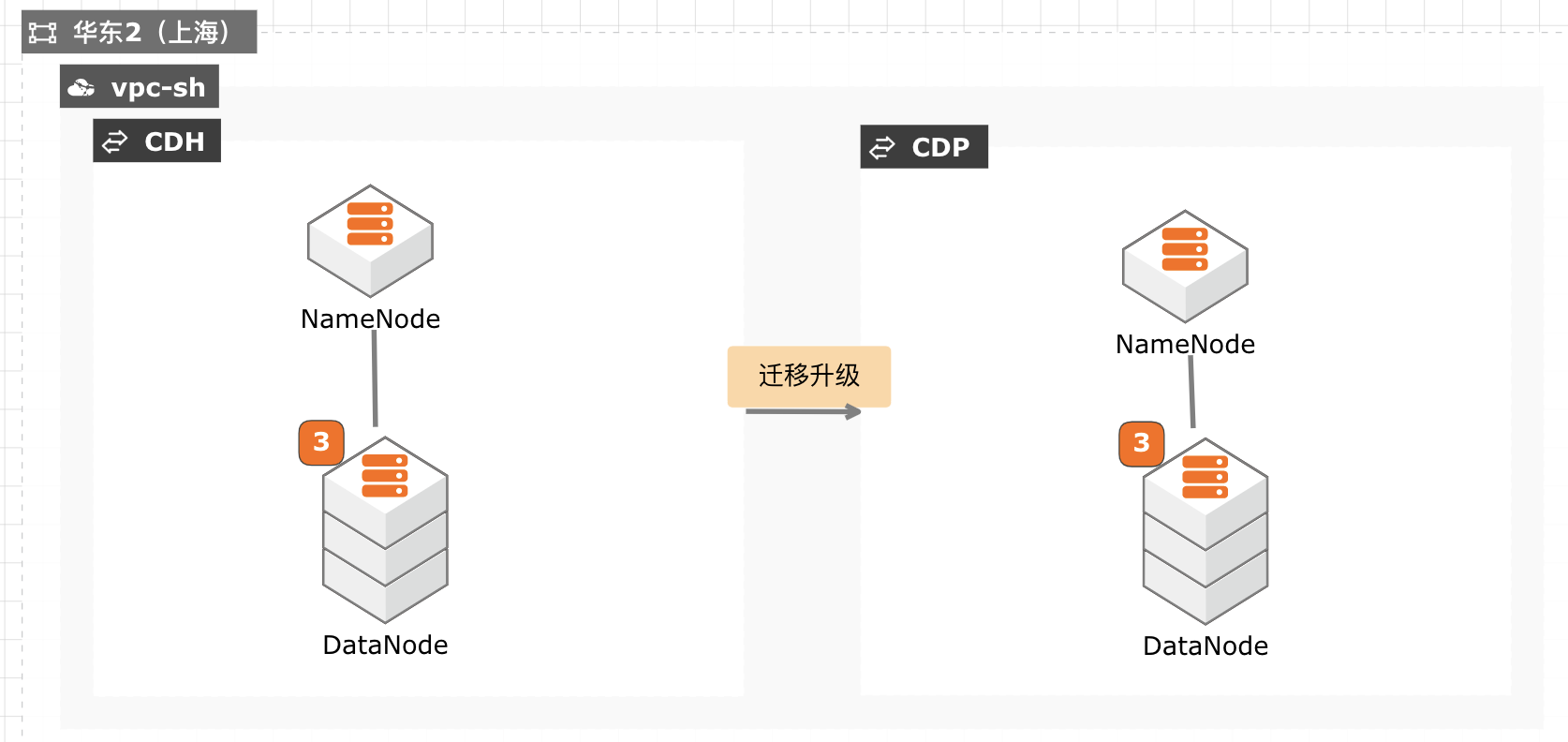
当前 CDH 免费版停止下载,终止服务,针对需要企业版服务能力并且CDH 升级过程对业务影响较小的客户,通过安装新的 CDP 集群,将现有数据拷贝至新集群,然后将新集群切换为生产集群,升级过程没有数据丢失风险,停机时间较短,适合大部分互联网客户升级使用。
除了 Navigator能够集成的那些数据源之外,Atlas还支持 NiFi和 Kafka元数 据。业务术语表:Atlas提供了一个 Web界面,用于创建和管理业务术语表,这些术 语可以帮助组织通过标准化来识别和使用数据。Data Profiling:“Data Catalog”提供自动数据标记功能,用于列出常见的数据类 型,也允许用户通过正则表达式标记其他数据...
云消息队列 Kafka 版
云消息队列 Kafka 版是阿里云基于Apache Kafka构建的大数据消息中间件,广泛用于日志收集和分析、数据处理等场景。可提供全托管服务,用户无需部署运维,更专业、更可靠、更安全。
微消息队列 MQTT 版.Demo 库>>.Demo 库>>.Kafka Serverless新用户免费试用,时间截止2022年7月1日.ASK+Kafka 玩转云上弹幕发布,千份礼品等你挑战~.【Kafka Connect】将 MySQL 数据同步至消息队列 Kafka 版.【Kafka 生态】将消息队列 Kafka 版的数据迁移至大数据计算服务 MaxCompute.【Kafka Connect】将 SQL Server 数据...
来自:
云产品
基于链路追踪+ECI的流量洪峰应对
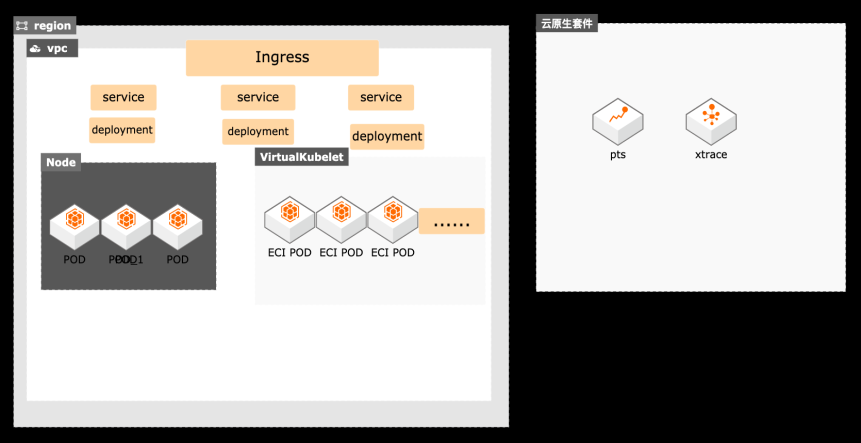
云原生技术已经为越来越多的互联网客户接受,对于在线教育、互动娱乐、电商等类型的客户会由于业务的原因存在突增业务流量,因此对于系统的稳定性非常关注,结合阿里云的容器服务、链路追踪、弹性容器ECI等产品,帮助客户业务实现容器化改造,并且方便发现系统应用架构中的瓶颈等问题,实现系统高弹性的同时优化客户的云资源使用成本。 l 方案优势 ᅳ 支持分布式追踪、调用链分析、DB调用分析、链路拓扑分析、业务指标统计等系统链路调用分析。 ᅳ 运维研发效率提高,链路追踪服务端全托管,免运维。 ᅳ 链路追踪的应用调用链分析能力结合ECI高弹性能力,提升应用系统在洪峰流量冲击下的稳定性。 ᅳ 链路追踪接入方便,ECI POD弹性伸缩,节省用户运维成本和云资源使用成本。 ᅳ 结合SLS Ingress可以基于应用前端访问性能指标做弹性伸缩,更丰富的云原生弹性能力。
文档版本:20201222 9 基于链路追踪+ECI的应用高可用弹性实践 应用部署 环境变量 SQL_ENVIRONMENT配置 mysql的访问地址,按照 1.3章节创建的数 据库服务访问地址进行配置,如下图所示:环境变量 TRACE_ENDPOINT配置链路跟踪接入点地址,获取方式如下:a.登录链路跟踪控制台(https://tracing.console.aliyun.com/)b.获取到...
云数据库 Tair(兼容 Redis)产品概述
阿里云数据库Tair(兼容Redis®)能够应对开源Redis难以覆盖的场景,并提供稳定的高性能、低时延服务,包括多线程处理能力、多种存储介质等更多企业级服务,广泛应用于缓存、内存存储场景。
产品解决方案文档与社区权益中心定价云市场合作伙伴支持与服务了解阿里云AI 助理备案控制台云数据库 Tair(兼容 Redis)产品概述产品功能选型与定价入门与试用相关资源控制台文档联系我们立即购买高性能的云数据库 Tair(兼容 Redis®*)Redis 开源版和 Tair 企业版,提供亚毫秒级的稳定时延立即购买免费试用生态兼容兼容...
来自:
云产品
自建数据库迁移到云数据库
本方案介绍如何将网站的自建数据库迁移至云数据库 RDS,解决您随着业务增长可能会面临的数据库运维难题。数据库采用高可用架构,支持跨可用区容灾,给业务带来数据安全、可用性、性能和成本方面收益。
本方案介绍如何将网站的自建数据库迁移至云数据库 RDS,解决您随着业务增长可能会面临的数据库运维难题。数据库采用高可用架构,支持跨可用区容灾,给业务带来数据安全、可用性、性能和成本方面收益。自建数据库迁移到云数据库 本方案介绍如何将网站的自建数据库迁移至云数据库 RDS,解决您随着业务增长可能会面临的数据库...
来自:
技术解决方案
- 产品推荐
- 这些文档可能帮助您