数据集成 Data Integration
阿里云数据集成 Data Integration是跨异构数据、低成本、弹性扩展的数据采集同步平台,为DataX的商业版,支持ETL,支持50+数据源跨网络离线(全量/增量)同步。
数据集成 Data Integration是阿里集团对外提供的可跨异构数据存储系统的、可靠、安全、低成本、可弹性扩展的数据同步平台,为400对数据源提供不同网络环境下的全量/增量数据进出通道.20+种异构数据源.20+种异构数据源.支持关系型数据库、大数据存储、非结构化存储、NoSql数据库之间的数据同步.支持经典/专有等网络环境.支持...
来自:
云产品
DTS数据同步集成MaxCompute数仓
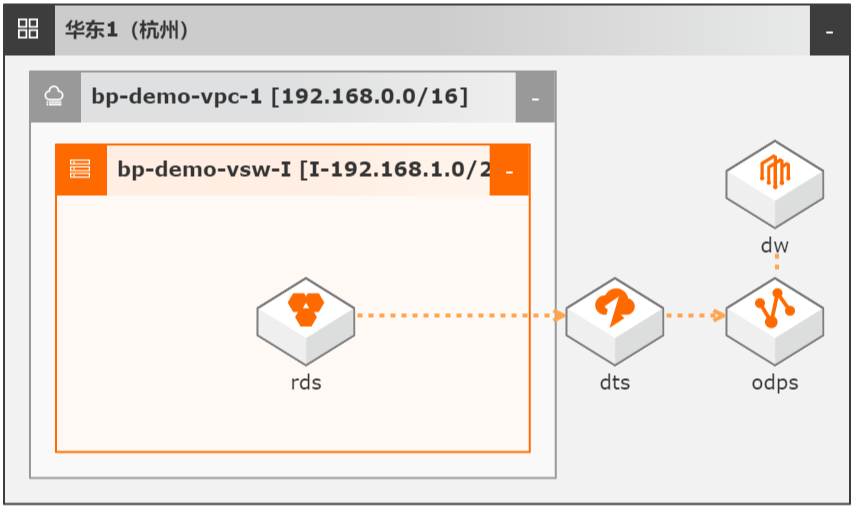
场景描述 本文Step by Step介绍了通过数据传输服务 DTS实现从云数据库RDS到MaxCompute的 数据同步集成,并介绍如何使用DTS和 MaxCompute数仓联合实现数据ETL幂等和数 据生命周期快速回溯。 解决问题 1.实现大数据实时同步集成。 2.实现数据ETL幂等。 3.实现数据生命周期快速回溯。 产品列表 MaxCompute 数据传输服务DTS DataWorks 云数据库RDS MySQL 版
数据抽取不幂等或容错率低,如凌晨 0:00启动的 ETL任务因为各种原因(数据库 HA切换、网络抖动或 MAXC写入失败等)失败后,再次抽取无法获取 0:00时的数 据状态。2.针对不规范设计表,如没有 create_time/update_time的历史遗留表,传统 ETL需 全量抽取。3.实时性差,抽取数据+重试任务往往需要 1-3小时。另外数据库的数据...
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
使用 sed命令替换转储文件中的 Location相关信息,其中蓝色字体和红色字 体内容可以在步骤 2中分别查看到:sed-i"s/hdfs:\/\/master:9000/oss:\/\/databricks-data-source/g"hive_databases.sql 文档版本:20210425 31 自建 Hive数据仓库跨版本迁移到阿里云 Databricks数据洞察 Hive数据迁移 其中红色字体为数据存储在 oss...
数据传输服务DTS
阿里云数据传输服务集数据迁移、订阅及实时同步功能于一体,能够解决公共云、混合云场景下,远距离、毫秒级异步数据传输难题,支持关系型数据库、NoSQL、大数据(OLAP)等数据源,其底层基础设施采用阿里双11异地多活架构,为数千下游应用提供实时数据流,已在线上稳定运行7年之久。
MySQL、SQL Server->SQL Server、PostgreSQL->PostgreSQL、MongoDB->MongoDB、Redis->Redis、Oracle->Oracle等多种数据源到RDS的上云迁移。查看迁移支持的数据库类型>异构数据源间数据迁移 支持Oracle->MySQL、MySQL->DRDS、MySQL->OceanBase、DB2->MySQL等异构数据源间的数据迁移。热迁移 支持数据的结构迁移、全量迁移、...
来自:
云产品
基于DataWorks的大数据一站式开发及数据治理

概述 基于Dataworks做大数据一站式开发,包含数据实时采集到kafka通过实时计算对数据进行ETL写入HDFS,使用Hive进行数据分析。通过Dataworks进行数据治理,数据地图查看数据信息和血缘关系,数据质量监控异常和报警。 适用场景 日志采集、处理及分析 日志使用Flink实时写入HDFS 日志数据实时ETL 日志HIVE分析 基于dataworks一站式开发 数据治理 方案优势 大数据一站式开发,完善的数据治理能力。 性能优越:高吞吐,高扩展性。 安全稳定:Exactly-Once,故障自动恢复,资源隔离。 简单易用:SQL语言,在线开发,全面支持UDX。 功能强大:支持SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据源计算等Data Lake相关功能 ,以及各种流式及静态数据源关联查询。
基于 DataWorks的大数据一站式开发及数据治理 最佳实践 业务架构 场景描述 解决问题 本实践基于 Dataworks做大数据一站式开发,包含 日志采集、处理及分析 数据实时采集到 kafka 通过实时计算对数据进行 日志使用 Flink实时写入 HDFS ETL写入 HDFS,使用 Hive进行数据分析。通过 日志数据实时 ETL Dataworks进行数据治理,...
EMR本地盘实例大规模数据集测试
场景描述 阿里云为了满足大数据场景下的存储需求,在云 上推出了本地盘D1机型,这个系列提供了本地 盘而非云盘作为存储,提高了磁盘的吞吐能力, 发挥Hadoop的就近计算优势。阿里云EMR 产品针对本地盘机型,推出了一整套的自动化运 维方案,帮助用户方便可靠地使用本地盘机型, 不需要关注整个运维过程同时数据的高可靠和 服务的高可用。 解决问题 1.云盘多份冗余数据导致成本高 2.磁盘吞吐量不高 3.节点的高可靠分布问题 4.本地盘与节点的故障监控问题 5.数据迁移时自动决策问题 6.自动故障节点迁移与数据平衡问题 产品列表 EMR(E-MapReduce) 本地盘 VPC
阿里 云 EMR产品针对本地盘机型,推出了一整套 的自动化运维方案,帮助用户方便可靠地使用 本地盘机型,不需要关注整个运维过程同时数 据的高可靠和服务的高可用。解决问题 1.云盘多份冗余数据导致成本高 2.磁盘吞吐量不高 3.节点的高可靠分布问题 4.本地盘与节点的故障监控问题 5.数据迁移时自动决策问题 6.自动故障节点...
游戏数据运营融合分析
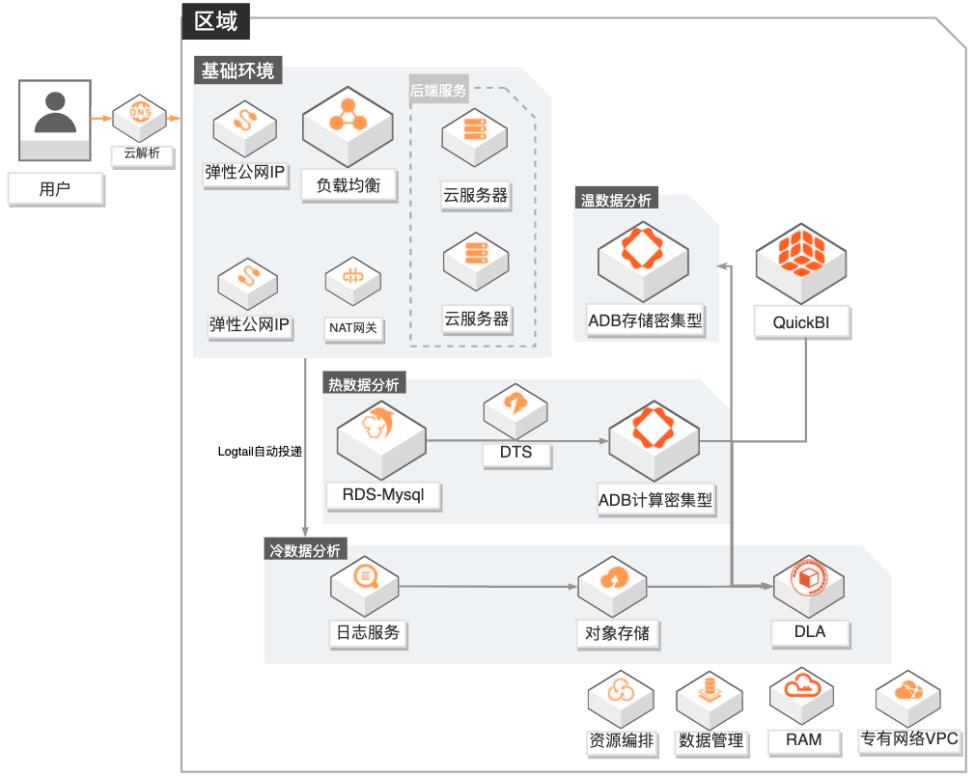
场景描述 1.游戏行业有结构化和非结构化数据融合分 析需求的客户。 2.游戏行业有数据实时分析需求的客户,无法 接受T+1延迟。 3.对数据成本有一定诉求的客户,希望物尽其 用尽量优化成本。 4.其他行业有类似需求的客户。 方案优势/解决问题 1.秒级实时分析:依托ADB计算密集型实例, 秒级监控DAU等数据,为广告投放效果提 供有力的在线决策支撑。 2.高效数据融合分析:打通结构化和非结构化 数据,支撑产品体验分析;广告买量投放效 果实时(分钟级)分析,渠道的评估更准确。 3.低成本:DLA融合冷数据分析+ADB存储密 集型温数据分析+ADB计算密集型热数据分 析,在满足各种分析场景需求的同时,有效 地降低的客户的总体使用成本。 4.学习成本低:DLA和ADB兼容标准SQL语 法,无需额外学习其他技术。 产品列表 专有网络VPC、负载均衡SLB、NAT网关、弹性公网IP 云服务器ECS、日志服务SLS、对象存储OSS 数据库RDSMySQL、数据传输服务DTS、数据管理DMS 分析型数据库MySQL版ADS 数据湖分析DLA、QuickBI
数据存储与投递:ᅳ 利用 OSS近乎无限的云数据湖存储能力,利用 DLA内建的灵活可定制的 ETL能力。ᅳ 打通 SLS->OSS->DLA->ADB,进行数据湖投递、处理、分析,数据源到可 视化端的扭转时间从小时级降低到分钟级的同时,成本降低到原有的 1/10。数据融合分析:文档版本:20210224 3 游戏数据运营融合分析 最佳实践概述 ᅳ DLA...
企业上云数据安全
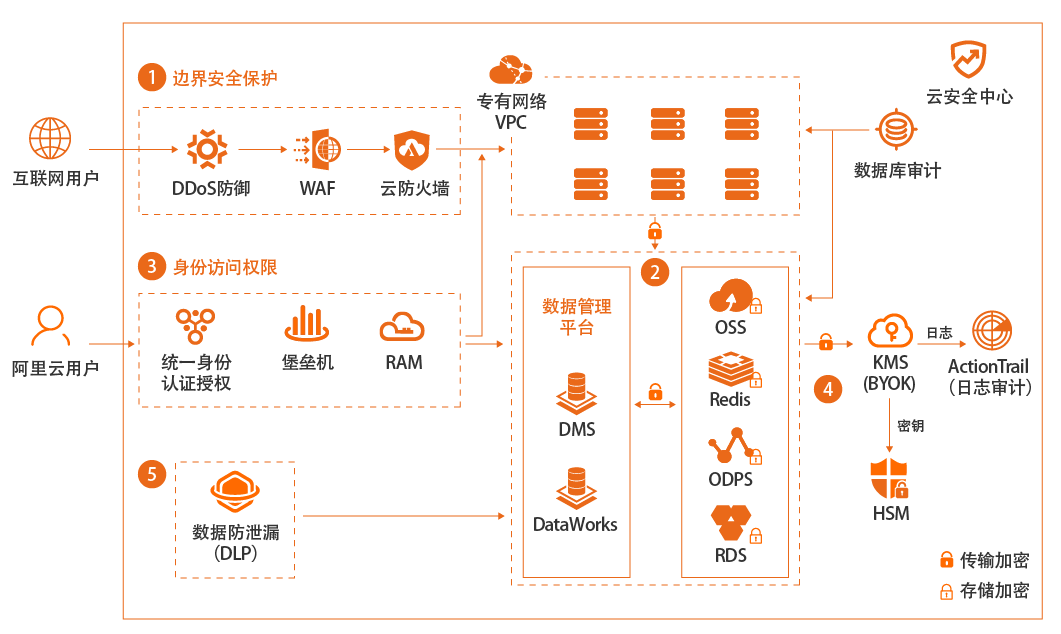
场景描述 企业是否选择上公共云,或者哪些系统或数据上 公共云,对数据安全的关心是重要因素之一。本 最佳实践重点在于介绍狭义的数据加密存储安 全范畴,即首先使用SDDP产品进行敏感数据发 现和分级分类,然后对高级别敏感数据进行按 需、不同类型的全链路加密存储。 解决问题 1.帮助客户发现敏感数据 2.对敏感数据进行分类、分级 3.对不同级别的数据如何选择加密方式 4.具体如何进行加密 产品列表 敏感数据识别SDDP 密钥管理服务KMS 云数据库RDS 对象存储OSS
3.下载对象:客户端首先会从 OSS服务端下载加密的对象以及作为对象元数据存储 的数据密文密钥(Encrypted data key)。4.解密数据:客户端将数据密文密钥(Encrypted data key)以及 CMK ID发送至 KMS 服务器。作为响应,KMS将使用指定的 CMK解密,并且将数据明文密钥(Data key)返回给本地加密客户端。本实践中,通过一个 ...
异地双活场景下的数据双向同步
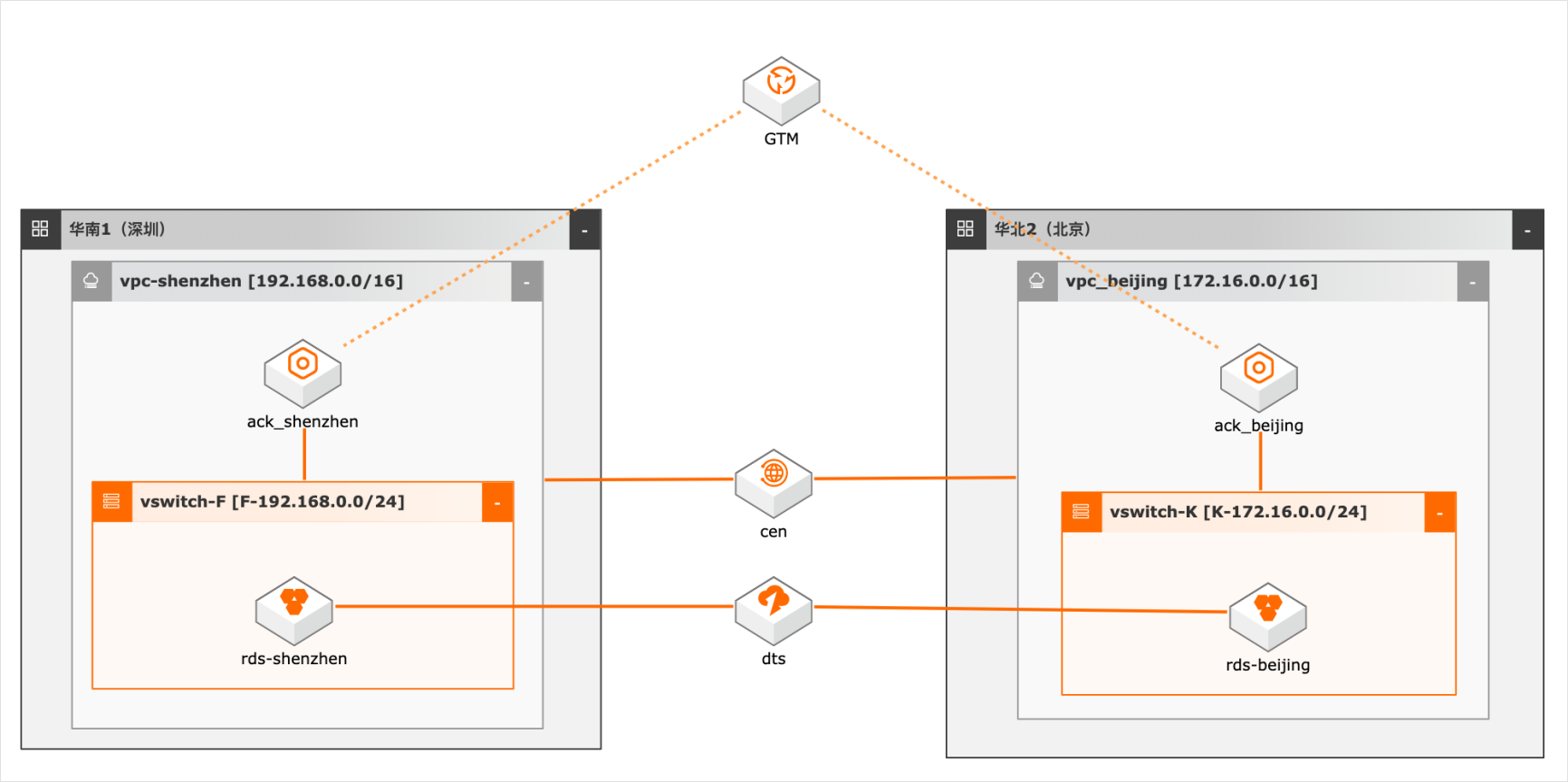
概述 随着客户业务规模的扩大,对系统高可用性要求越来越高,越来越多用户采用异地双活/多活架构,多活架构往往涉及业务侧做单元化改造,本方案仅模拟用户已做单元化改造后的数据双向同步,数据库采用双主架构,本地写本地读,同时又保证双库的数据一致性,为业务增加可用性和灵活性。 适用场景 数据库双向同步 数据库全局ID不冲突 双活架构的数据库建设问题 技术架构 本实践方案基于如下图所示的技术架构和主要流程编写操作步骤: 方案优势 DTS双向同步,采用独立模块避免数据同步占用系统资源。 奇偶ID涉及,避免数据冲突。 DTS多种处理冲突的方式供业务选择。 安全:原生的多租户系统,以项目进行隔离,所有计算任务在安全沙箱中运行。
随着客户业务规模的扩大,对系统高可用性要求越 数据库双向同步 来越高,越来越多用户采用异地双活/多活架构,多 数据库全局 ID不冲突 活架构往往涉及业务侧做单元化改造,本方案仅模 双活架构的数据库建设问题 拟用户已做单元化改造后的数据双向同步,数据库 采用双主架构,本地写本地读,同时又保证双库的数 据一致性,为...
数据可视化DataV
数据可视化DataV是阿里云一款数据可视化应用搭建工具,旨让更多的人看到数据可视化的魅力,帮助非专业的工程师通过图形化的界面轻松搭建专业水准的可视化应用,满足您会议展览、业务监控、风险预警、地理信息分析等多种业务的展示需求。
推荐产品 DataV-数据看板 相关产品 RDS MySQL 版 大数据开发治理平台 DataWorks AnalyticDB MySQL版 实时数仓 Hologres产品版本DataV-Board 数据看板 DataV-Note 智能分析 DataV-TwinFabric 数字孪生 DataV-Atlas 分析地图 产品资源数量 工作空间数量 用户数数量 大屏项目数量 演示预案数量 组件收藏数量 设计资产存储空间 ...
来自:
云产品
利用交互式分析(Hologres)进行数据查询
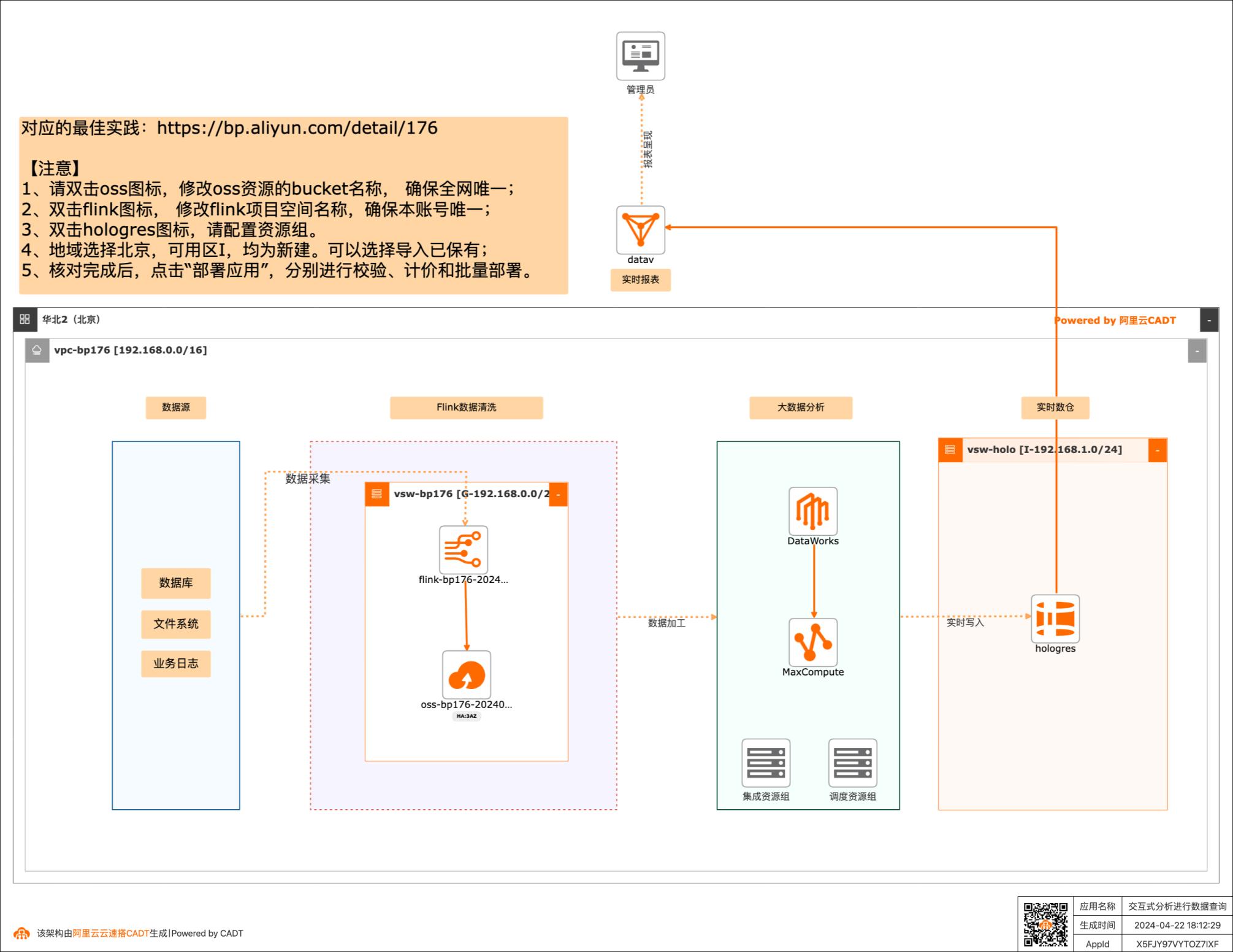
场景描述:随着收集数据的方式不断丰富,企业信息化 程度越来越高,企业掌握的数据量呈TB、 PB或EB级别增长。同时,数据中台的快 速推进,使数据应用主要为数据支撑、用户 画像、实时圈人及广告精准投放等核心业务 服务。高可靠和低延时地数据服务成为企业 数字化转型的关键。 Hologres致力于低成本和高性能地大规模 计算型存储和强大的查询能力,为您提供海 量数据的实时数据仓库解决方案和实时交 互式查询服务。 解决问题 1.加速查询MaxCompute数据 2.快速搭建实时数据仓库 3.无缝对接主流BI工具 产品列表 MaxCompute Hologres 实时计算Flink 专有网络VPC DataWorks DataV
Hologres常见使用场景 联邦分析实时数据和离线数据 业务数据分为冷数据和热数据,冷数据存储在离线数据仓库MaxCompute中,热数 据存储在Hologres中。Hologres可以联邦分析实时数据和离线数据,对接BI分析 工具,快速响应简单查询与复杂查询的业务需求。图1.联邦分析架构图 实时数据仓库 实时写入业务数据至实时计算,使用...
湖仓一体架构EMR元数据迁移DLF
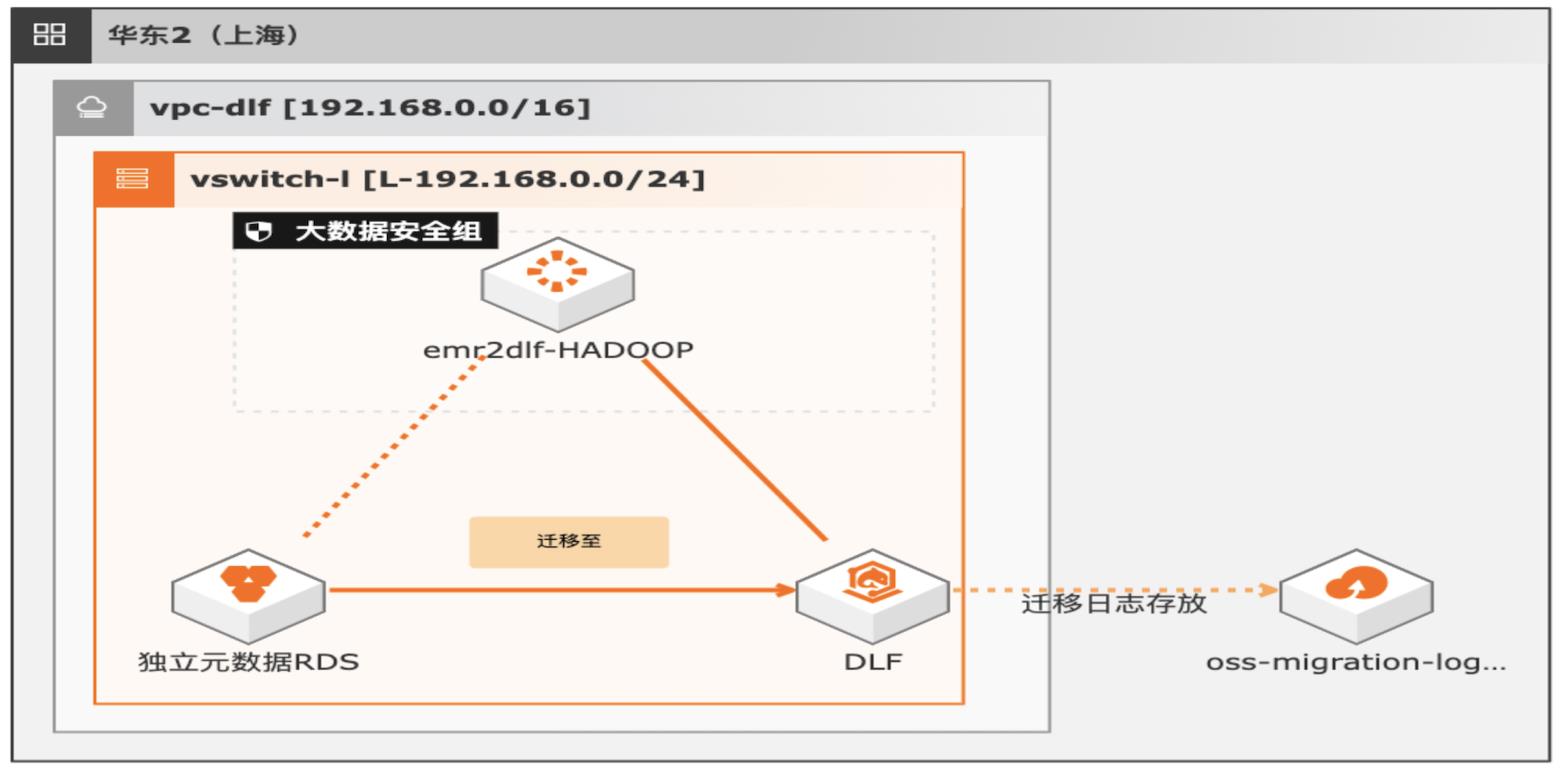
通过EMR+DLF数据湖方案,可以为企业提供数据湖内的统一的元数据管理,统一的权限管理,支持多源数据入湖以及一站式数据探索的能力。本方案支持已有EMR集群元数据库使用RDS或内置MySQL数据库迁移DLF,通过统一的元数据管理,多种数据源入湖,搭建高效的数据湖解决方案。
湖仓一体架构 EMR元数据迁移 DLF最佳实践 业务架构 场景描述 解决的问题 通过 EMR+DLF数据湖方案,可以为企业提供数据 EMR元数据迁移至 DLF 湖内的统一的元数据管理,统一的权限管理,支持多 元数据迁移验证 源数据入湖以及一站式数据探索的能力。本方案支 数据一致性校验 持已有 EMR集群元数据库使用 RDS或内置 MySQL ...
Function Compute构建高弹性大数据采集系统
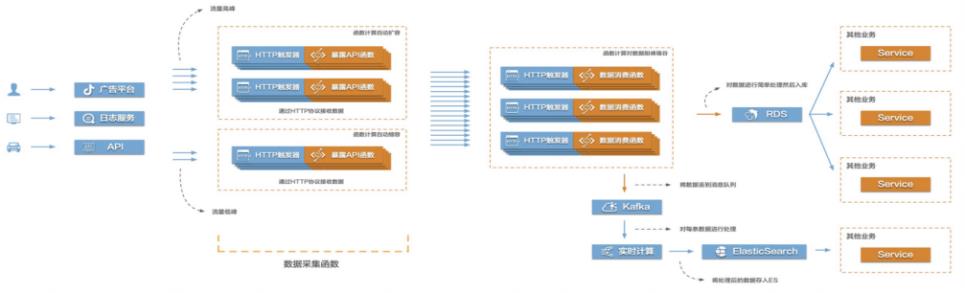
当前互联网很多场景都存在需要将大量的数据信息采集起来然后传输到后端的各类系统服务中,对数据进行处理、分析,形成业务闭环。比如游戏行业中的游戏发行、游戏运营,产互行业中的数字营销,物联网、车联网行业中的硬件、车辆信息上报等等。这些场景普遍存在数据采集量大、数据传输需要稳定且吞吐量大的特点,给整个数据采集传输系统带来很大的挑战。在这个场景中,有三个关键的环节,数据采集、数据传输、数据处理。该最佳实践主要涉
Function Compute构建高弹性大数据采集系统 最佳实践 业务架构 场景描述 当前互联网很多场景都存在需要将大量的数据 信息采集起来然后传输到后端的各类系统服务 中,对数据进行处理、分析,形成业务闭环。比 如游戏行业中的游戏发行、游戏运营,产互行业 中的数字营销,物联网、车联网行业中的硬件、车辆信息上报等等。这些...
互联网电商行业离线大数据分析

电商网站销售数据通过大数据分析后将业务指标数据在大屏幕上展示,如销售指标、客户指标、销售排名、订单地区分布等。大屏上销售数据可视化动态展示,效果震撼,触控大屏支持用户自助查询数据,极大地增强数据的可读性。
互联网电商行业离线大数据分析 最佳实践 业务架构 场景描述 本实践介绍了使用阿里云MaxCompute、数据库(RDS)、DataWorks等产品实现电商网站离线数据分 析,分析后的业务指标数据实时在大屏展示。通过完整 的实践Demo为例,提供从电商网站搭建,数据从RDS 同步到MaxCompute、再到DataWorks进行数据分析,最后在大屏上展示...
EMR集群安全认证和授权管理
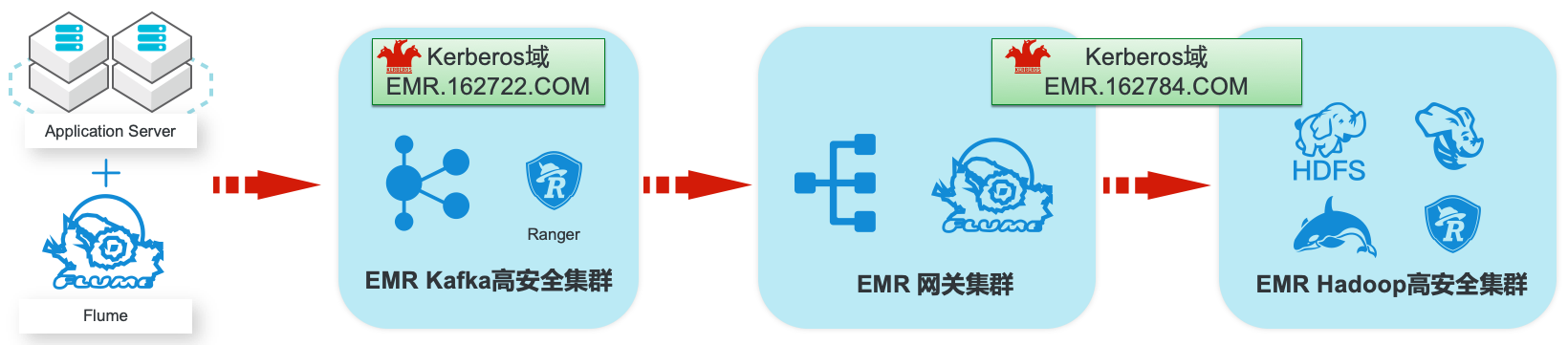
场景描述 阿里云EMR服务Kafka和Hadoop安全集群使 用Kerberos进行用户安全认证,通过Apache Ranger服务进行访问授权管理。本最佳实践中以 Apache Web服务器日志为例,演示基于Kafka 和Hadoop的生态组件构建日志大数据仓库,并 介绍在整个数据流程中,如何通过Kerberos和 Ranger进行认证和授权的相关配置。 解决问题 1.创建基于Kerberos的EMR Kafka和 Hadoop集群。 2.EMR服务的Kafka和Hadoop集群中 Kerberos相关配置和使用方法。 3.Ranger中添加Kafka、HDFS、Hive和 Hbase服务和访问策略。 4.Flume中和Kafka、HDFS相关的安全配 置。 产品列表:E-MapReduce、专有网络VPC、云服务器ECS、云数据库RDS版
在现代数据架构中,Hadoop 通过提供低成本、大规模的数据存储和处理扮演着至关重要的角色。对于在 Hadoop生态系统中存储和处理敏感数据的组织而言,安全性至关重要。在阿里云 EMR服务中,为使用者提供了多种企业级安全机制,从集群管理、用户认 证、访问授权、审计和数据保护等多方面提供了保护。名词解释 E-MapReduce:...
数据库和应用迁移 ADAM
数据库和应用迁移 Advanced Database & Application Migration(以下简称 ADAM)是一款把数据库和应用迁移到阿里云(公共云或专有云)的产品,支持 Oracle、Teradata、Db2 的异构迁移上云。ADAM 全面评估上云可行性、成本和云存储选型,内置实施协助、数据迁移、应用迁移等工具,确保可靠、快速、低成本上云。
信息采集同时,针对数据冗余、信息安全问题,数据采集器对采集结果中 SQL 数据进行脱敏、去重、一致性校验等处理,保证采集结果的准确性.数据去重、数据脱敏.提供语法转换建议、性能风险评估等兼容性建议.语法转换建议,性能风险评估.识别源库特性,识别性能风险,根据目标库特性提供转换建议.根据转换建议结果预估出大致...
来自:
云产品
云数据库RDS PostgreSQL
云数据库RDS PostgreSQL 版完全兼容开源PostgreSQL,基于云原生架构,软硬协同优化,提供稳定可靠、高性价比的数据库服务。通过丰富的插件拓展,支撑各领域场景化业务,如自研Ganos多维多模时空引擎及开源PostGIS地理信息引擎、向量引擎、时序引擎等百余款插件。
询价中 立即购买 集群系列倚天版 询价中 立即购买 Serverless 无需按固定资源付费,根据业务负载自适应动态匹配资源,秒级弹性升降资源与计费 询价中 立即购买产品优势OLTP+OLAP高效复杂查询 PostgreSQL具备强大的OLTP能力,拥有与商业数据库性能功能高度接近的查询优化器、PL/pgSQL存储过程语言、复杂SQL并行查询能力,...
来自:
云产品
云上成本优化workshop
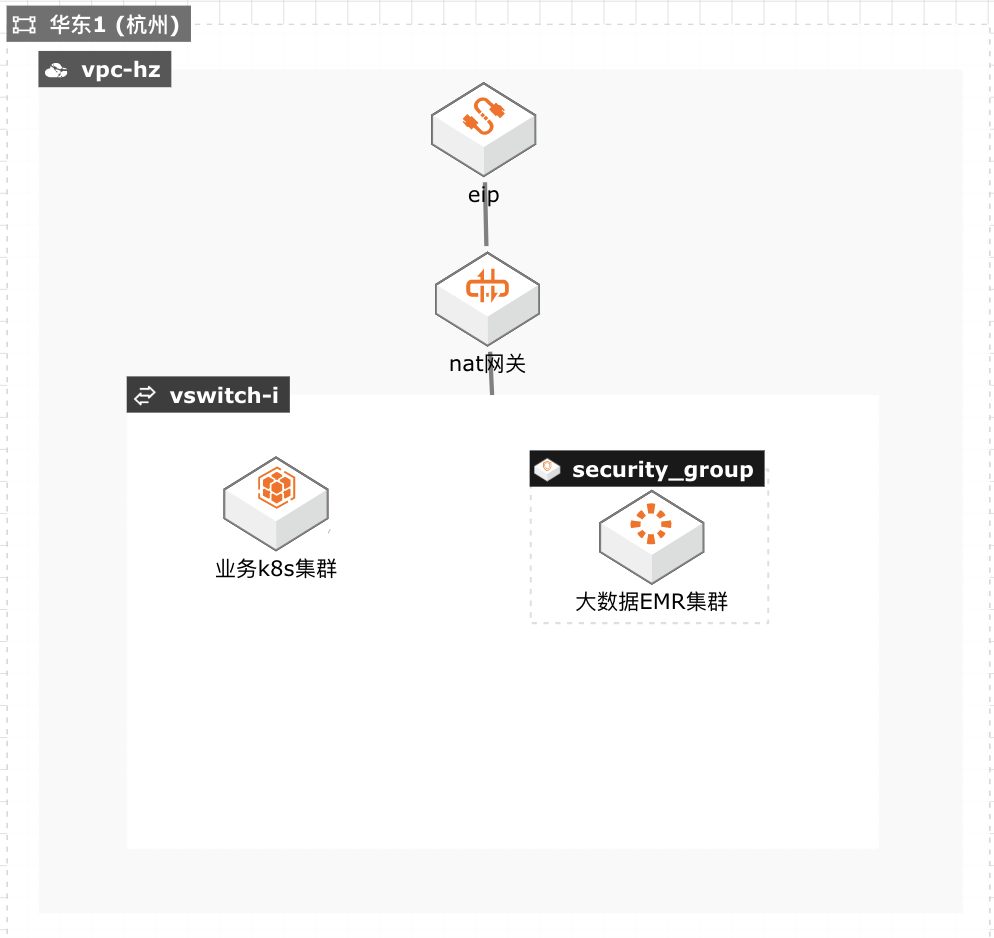
某金融科技公司,它主要提供信贷,理财,电商等 服务,目前已经拥有千万级注册用户。该公司在将 在线业务系统和大数据业务从自建 IDC 机房迁移 到阿里云后,今年大数据集群经历过多次因为资 源不足导致弹性扩容失败的故障,运维负责人非 常苦恼。由于该公司从事互联网金融的借贷业务, 白天的催收非常依赖晚上大数据计算的结果,若 因为资源不足导致计算结果失败则意味着白天催 收业务员无事可做,会对公司业务造成严重影响。 后来,通过阿里云解决方案架构师建议的方案,将 大数据集群迁移到资源较充足的可用区以及配置 弹性伸缩多规格 ECS 选型增加交付成功率等方 法,目前已阶段性的解决因资源不足导致弹性扩 容失败的问题,但该方案在 Spot 计算资源不足 时,启用大量按量收费算力,带来了较高的成本, 并且抢占式实例和按量付费实例都不保证资源 100%交付,还是存在交付失败的可能性,特别是 在双 11 期间由于其他客户的资源需求上升带来 的资源挤兑客观上存在,就进一步增加了弹性扩 容失败的风险,从而影响业务正常运行。
账单管理功能涉及 到的数据存储和计算,全部免费。首次登 录时,需要开通授权导入。成本管家地址:https://sls.console.aliyun.com/lognext/app/bill/setting 5.2. 导入账单数据 一键开通后,会自动将账单从账单中心导入到日志库中。账单是一种时间序列的数据,而日志服务的主要功能就是对时间序列数据的采集、存储和分析,...
来自:
最佳实践
相关产品:云服务器ECS,负载均衡 SLB,弹性公网IP,容器服务 ACK,日志服务(SLS),NAT网关,函数计算,E-MapReduce,云数据库PolarDB,弹性容器实例 ECI,存储容量单位包,预留实例券,Hologres
- 产品推荐
- 这些文档可能帮助您