自建Hadoop迁移到阿里云EMR
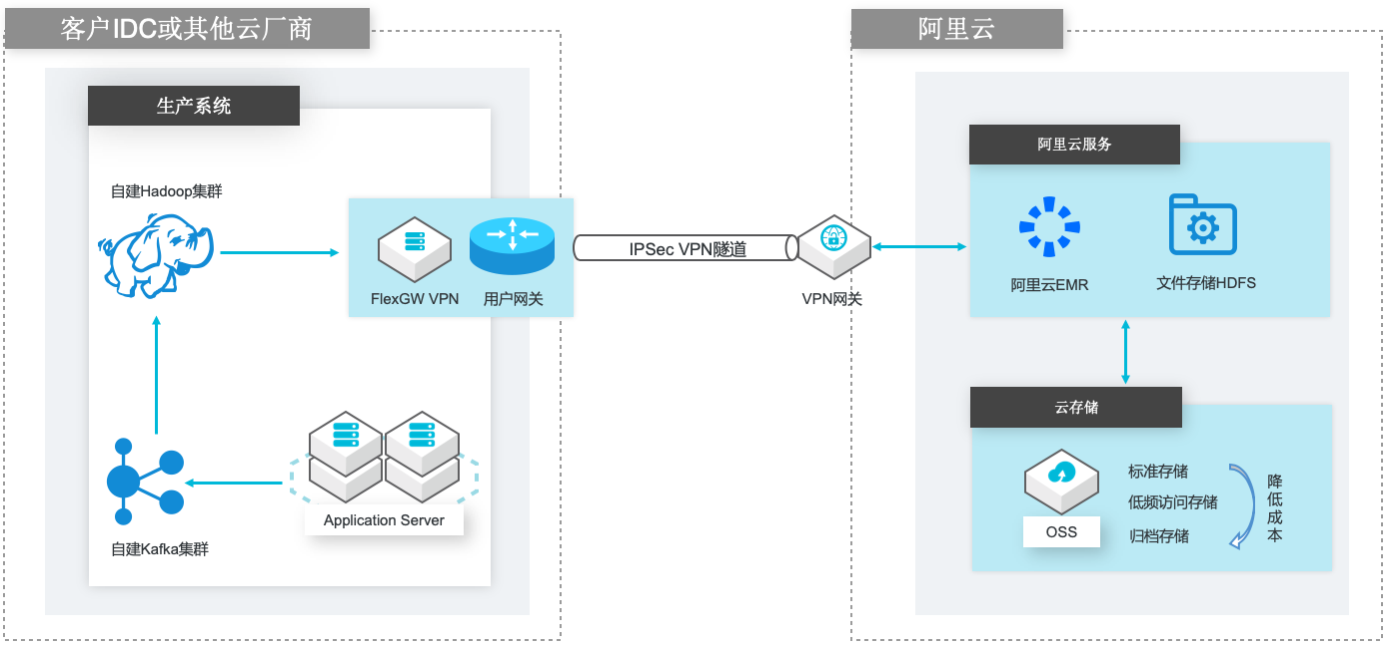
场景描述 场景1:自建Hadoop集群数据(HDFS)迁移到 阿里云EMR集群的HDFS文件系统; 场景2:自建Hadoop集群数据(HDFS)迁移到 计算存储分离架构的阿里云EMR集群,以OSS 和JindoFS作为EMR集群的后端存储。 解决的问题 客户自建Hadoop迁移到阿里云EMR集群的 技术方案; 基于IPSecVPN隧道构建安全和低成本数据 传输链路 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
低成本 在阿里云创建 Hadoop类型的 EMR集群和自建 Hadoop集群相比有一定成本优 势,同时阿里云 EMR可以使用 OSS作为底层存储空间,进一步降低成本。文档版本:20210714 1 自建Hadoop数据迁移到阿里云 EMR 前置条件 前置条件 在进行本文操作之前,您需要完成以下准备工作:拥有阿里云实名认证账号。拥有已经通过备案的域名。...
Spark on ECI大数据分析

场景描述 方案优势 1.计算引擎弹性扩缩容,兼顾资源弹性与计 算资源成本优化。 2.计算与存储分离架构,结合阿里云原生云 存储产品,海量数据湖优势。 3.Kubernetes原生的调度性能优势,提升在 大规模分析作业时的分析性能优势分。 4.集群资源隔离和按需分配。 解决问题 1.计算资源弹性能力不足,计算资源成本管 控能力欠缺. 2.集群资源调度能力和隔离能力不足。 3.计算与存储无法分离,大数据量分析时出 现数据存储资源瓶颈。 4.Spark submit方式提交分析作业参数支持 有限等缺点。 产品列表 容器服务Kubernetes版(ACK) 弹性容器实例(ECI) 文件存储HDFS 对象存储OSS 专有网络VPC 容器镜像服务ACR
2.关于 Hadoop的核心配置文件的说明介绍如下图所示:文档版本:20200409 5 Spark on ECI大数据分析 环境准备 3.修改 core-site.xml文件,路径位于 Hadoop目录下的/etc/hadoop/目录下。步骤5 配置环境变量。1.修改/etc/profile文件并保存。2.在配置最后加入相应路径信息。3.执行 source/etc/profile命令以便环境变量配置生效...
开源Flink迁移实时计算Flink全托管版最佳实践
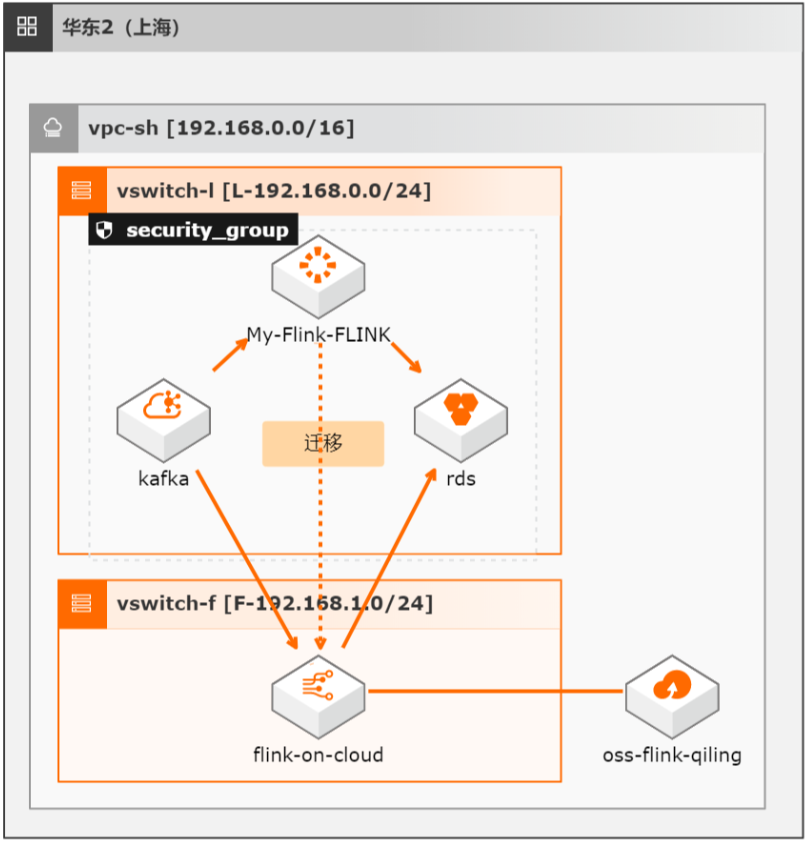
本方案介绍如何将自建开源Flink集群的流式任务(包含Datastream、Table/SQL、PyFlink任务)迁移至阿里云实时计算全托管版。
适用场景 Flink各类任务如何迁移 数据准确性如何校验 业务稳定性如何验证 Flink集群容量如何评估 技术架构 本实践方案基于如下图所示的技术架构和主要流程编写操作步骤:文档版本:20211222 1 开源 Flink迁移实时计算Flink全托管版 最佳实践概述 迁移实施流程如下:方案优势 您只需要专注于业务开发,无需关心集群运维。...
SLS多云日志采集、处理及分析
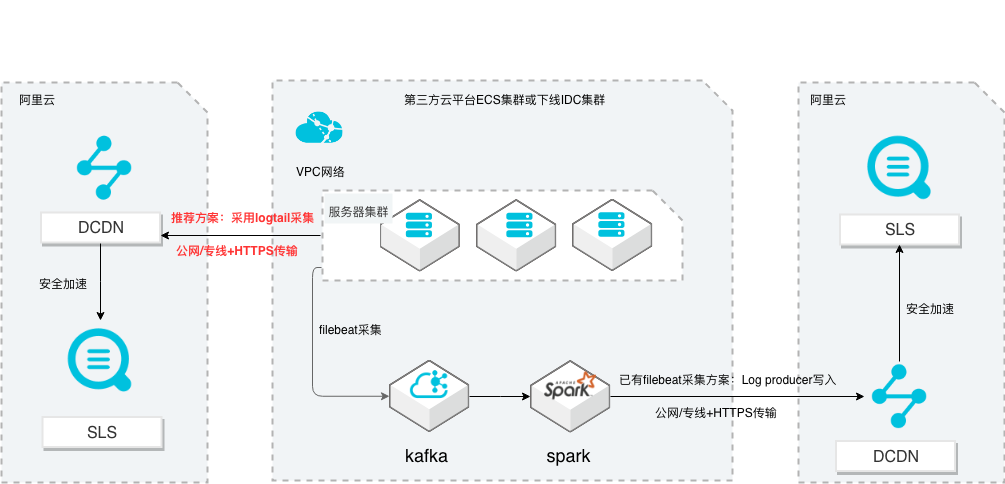
场景描述 从第三方云平台或线下IDC服务器上采集 日志写入到阿里云日志服务,通过日志服务 进行数据分析,帮助提升运维、运营效率, 建立DT 时代海量日志处理能力。 针对未使用其他日志采集服务的用户,推荐 在他云或线下服务器安装logtail采集并使用 Https安全传输;针对已使用其他日志采集 工具并且已有日志服务需要继续服务的情 况,可以通过Log producer SDK写入日志 服务。 解决问题 1.第三方云平台或线下IDC客户需要使用 阿里云日志服务生态的用户。 2.第三方云平台或线下IDC服务器已有完 整日志采集、处理及分析的用户。 产品列表 E-MapReduce 专有网络VPC 云服务器ECS 日志服务LOG DCDN
相比较于普通的公网访 问,全球加速公网在延迟、高安全性、稳定性上具备明显优势。日志服务全球加速功 能依赖于阿里云全站加速产品提供的加速环境,解决了跨运营商、网络不稳定、公网 传输安全性、网络用塞等诸多问题,提升全站性能和用户体验,应用于广告、游戏、金融、物联网等行业。4.1.开通全站加速产品 步骤1 登录 ...
数据湖-在线学习场景数据分析

场景描述 本场景以在线教育中一个答题闯关类的应用为 例,使用WebServer来模拟演示这类日志数据 的分析处理。通过Nginx和Pythonflask搭建 WebServer,模拟应用中的关键页面,比如登 录、课程内容等,之后构造若干用户使用的模拟 日志数据,投递到数据湖进行分析后获取应用 PV、UV、课程内容访问排行、平均得分等等。 解决问题 基于数据湖(EMR+OSS)搭建大数据平台。 EMR和OSS使用和配置。 数据统一存储到OSS。 产品列表 E-MapReduce 对象存储OSS 云服务器ECS 访问控制RAM 专有网络VPC
此外,对于Hadoop集群上的任务,不同类型的任务对于机器配置的要求不同,比如 推荐和算法业务可能对集群的计算能力要求较高,而 ETL 类型的任务,可能又对存 储或内存要求较高。因此我们通过EMR和OSS的方案,可以通过对EMR集群指定 机型来达到优化架构、减低成本的要求。1.2.JindoFS简介 当数据量达到一定级别时,比如日...
E-MapReduce Serverless Spark 版
E-MapReduce Serverless Spark 是阿里云 E-MapReduce 基于 Spark 提供的一款全托管、一站式的数据计算平台。它为用户提供任务开发、调试、发布、调度和运维等全方位的产品化服务,显著简化了大数据计算的工作流程,使用户能更专注于数据分析和价值提炼。
得益于其开放的产品架构,EMR Serverless Spark 使得在数据湖中对结构化和非结构化数据进行分析与处理变得简单高效。此外,其还内置了任务调度系统,允许用户轻松构建和管理数据 ETL 任务,实现数据管道的自动化和周期性数据处理。EMR Serverless Spark 还内嵌了先进的版本管理系统,并提供了开发与生产环境的完全隔离,...
来自:
云产品
自建Hadoop迁移MaxCompute
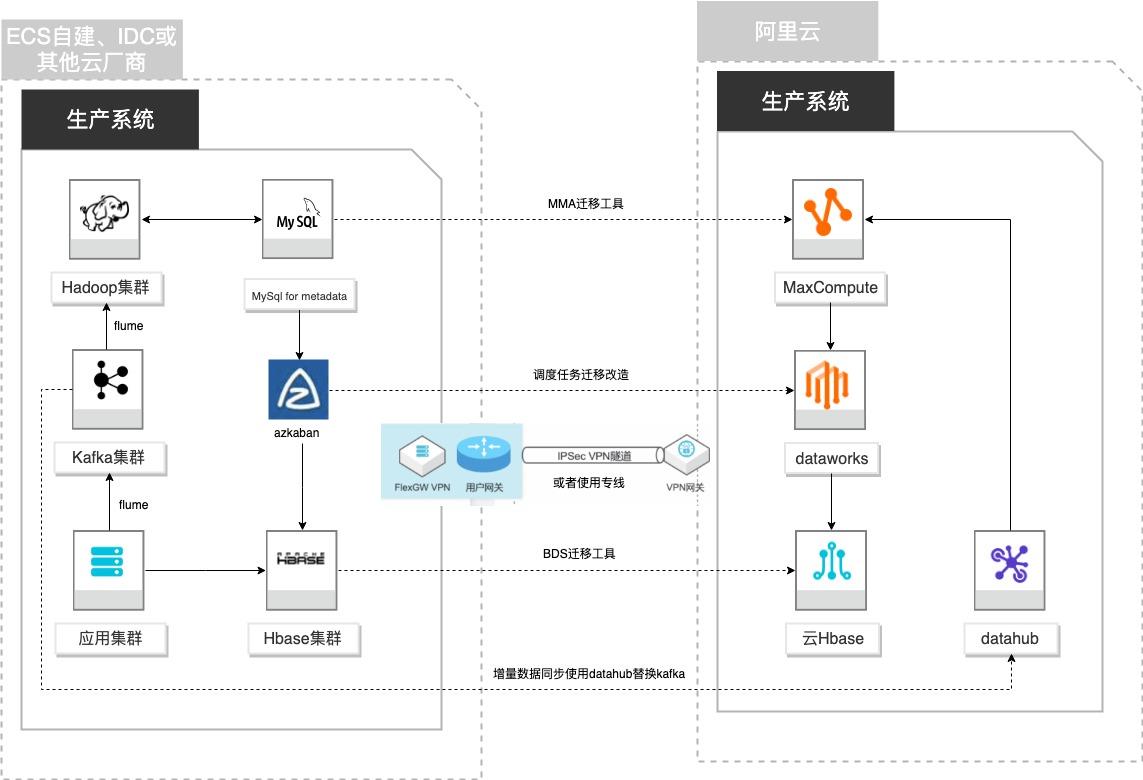
场景描述 客户基于ECS、IDC自建或在友商云平台自建了大数 据集群,为了降低企业大数据计算平台的成本,提高 大数据应用开发效率,更有效保障数据安全,把大数 据集群的数据、作业、调度任务以及业务数据库整体 迁移到MaxCompute和其他云产品。 解决的问题 自建Hadoop集群搬迁到MaxCompute 自建Hbase集群搬迁到云Hbase 自建Kafka或应用数据准实时同步到 MaxCompute 自建Azkaban任务迁移到Dataworks任务 产品列表 MaxCompute,Dataworks、云数据库Hbase版、Datahub、VPC,ECS。
Kafka 的目的是通过 文档版本:20210723 III 自建Hadoop迁移MaxCompute 前言 Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提 供实时的消息。Flume Flume是一种分布式,可靠且可用的服务,用于有效地收集,聚合和移动大量日 志数据。它具有基于流数据流的简单灵活的体系结构。它具有可调整的可靠性...
中小企业自建Hadoop集群上云解决方案
中小企业自建 Hadoop 集群上云解决方案,助力自建 Hadoop 用户快速构建云上半托管开源大数据平台,在保持原组件使用习惯延续的同时,充分利用云上服务特点,更加便捷地迭代企业大数据平台架构,聚焦业务价值开发。
提供高性能、稳定版本 Hadoop、Spark、Hive、Flink、Kafka、Hbase、Presto、Impala、Hudi、ClickHouse 等开源大数据组件,可根据场景灵活搭配使用。采用 JindoFS+OSS,在保证数据可靠性的基础上,性能大幅提升.开源生态,性能优化.分钟级创建集群,支持对集群、节点和服务进行监控和运维操作,大幅提升运维工作效率,让数据...
来自:
解决方案
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
与社区版 Spark和 Delta Lake相比,在功能和性能 上都有明显的优势。经济 文档版本:20210425 V 自建 Hive数据仓库跨版本迁移到阿里云 Databricks数据洞察 最佳实践概述 您可以按需创建 Databricks数据洞察集群,即离线作业运行结束就可以释放集群,同时支持按负载和时间的弹性伸缩。协同分析 Databricks数据洞察 Notebook...
- 产品推荐
- 这些文档可能帮助您