云原生数据仓库AnalyticDB MySQL数据仓库
阿里云云原生数据仓库AnalyticDB MySQL版(简称AnalyticDB)是融合数据库、大数据技术于一体的云原生企业级数据仓库平台。云原生数据仓库AnalyticDB MySQL版支持数据实时写入和同步更新、实时计算和实时服务,可用于构建企业级报表系统、数据仓库和数据服务引擎。
更多应用场景请查看.AnalyticDB MySQL使用文档.快速上手AnalyticDB MySQL.查看API使用文档.AnalyticDB MySQL技术交流.流量成本的升高,用户更加成熟,迫使客户需进行更加精细化的市场营销,提供更高品质的产品...——打造一站式实时湖仓,可替换CDH/TDH/开源自建/云服务-Spark/Hive/Presto等.AnalyticDB MySQL湖仓版重磅发布.
来自:
云产品
云原生大数据计算服务MaxCompute
阿里云云原生大数据计算服务MaxCompute是面向分析的企业级云数仓,作为一体化大数据智能计算平台ODPS的大规模批量计算引擎,MaxCompute以 Serverless 架构提供快速、全托管的在线数据仓库服务,使您经济高效的分析处理海量数据,进行敏捷的业务洞察。
使用Python机器学习三方库.深度集成 Spark 引擎.内建Apache Spark引擎,提供完整的Spark功能;与MaxCompute计算资源、数据和权限体系深度集成.集成对数据湖(OSS或Hadoop HDFS)的访问分析,支持外表映射、Spark直接访问方式开展数据湖分析;在一套数仓服务和用户接口下,实现湖与仓的关联分析.支持流式采集和近实时分析....
来自:
云产品
实时数仓Hologres
Hologres(原交互式分析)是一站式实时数据仓库引擎,支持海量数据实时写入、实时更新、实时分析,支持标准SQL(兼容PostgreSQL协议),支持PB级数据多维分析(OLAP)与自助分析(Ad Hoc),支持高并发低延迟的在线数据服务(Serving),与MaxCompute、Flink、DataWorks深度融合,提供离在线一体化全栈数仓解决方案。
与Flink、Spark等计算框架原生集成,通过内置Connector,支持高通量数据实时写入与更新,支持源表、结果表、维度表多种场景,支持多流合并等复杂操作.所见即所得的开发.数据实时写入即可查询,支持DB、Schema、Table三级体系,支持视图View,原生支持Update/Delete,支持关联、嵌套、窗口等丰富表达能力,支持半结构JSON...
来自:
云产品
云数据库 SelectDB 版
阿里云数据库 SelectDB 是现代化实时数据仓库 SelectDB 在阿里云上的全托管服务,内核基于业界领先的开源分析型数据库 Apache Doris 研发,由阿里云和飞轮科技联合打造。阿里云数据库 SelectDB 聚焦于满足企业级大数据分析需求,广泛应用于实时报表分析、即席多维分析、日志检索分析、数据联邦与查询加速等场景,致力于为客户提供极致性能、简单易用的数据分析服务。
兼容 MySQL 连接协议和语法,无缝对接数十款数据库和大数据生态产品,降低用户学习成本。提供可视化开发工具,简化数据开发过程。产品功能弹性伸缩按需进行弹性扩缩容,扩缩容过程分钟级完成、无需停服。数据湖分析 支持丰富的数据湖类型,如Hive、Iceberg、Hudi等,支持湖数据的查询与回写。半结构化数据分析提供简单极速...
来自:
云产品
云数据库MongoDB版
阿里云云数据库MongoDB版是完全兼容MongoDB协议、高度兼容DynamoDB协议的在线文档型数据库服务。支持单节点、双节点、副本集和分片集群四种部署架构,能够满足不同的业务场景需要。
专业的DMS数据管理平台,提供可视化的MongoDB数据管理,图形化轻松管理数据库(Database)、集合(Collection)、文档(Document)等对象,全面提升研发、运维效率.数据库内核版本管理.主动升级,快速修复缺陷,免去日常版本管理苦恼;优化数据库MongoDB参数配置,最大化利用系统资源.可视化管理及运维平台,简单易用,系统...
来自:
云产品
云数据库ClickHouse
云数据库ClickHouse 是阿里云提供的分布式实时分析型列式数据库服务。具有高性能、开箱即用、企业特性支持。广泛应用于流量分析、广告营销分析、行为分析、人群划分、客户画像、敏捷BI、数据集市、网络监控、分布式服务和链路监控等业务场景。
支持 Flink流计算,Spark,Kafka 实时数写入链路.大数据同步链路.支持 Dataworks 和 DMS 进行大数据及各种数据源批量同步;支持 DAG任务编排,任务调度.业务库同步链路.支持 MaterializeMySQL,MySQL 外表,Dataworks,数据同步服务 Data Transmission Service 实时同步业务数据库数据.全面数据链路接入,快速构建实时数仓.全...
来自:
云产品
云数据库 Cassandra 版
Cassandra是连续9年DB-Engines排名第一的宽表数据库,支持类SQL语法CQL,开发体验类似MySQL,可扩展PB级存储。推出企业版Lindorm for Cassandra云原生多模数据库,采用存储计算分离架构,支持海量数据的低成本存储和按需付费,具备更高性价比和更为丰富的企业级功能。
【重磅升级】企业版Lindorm for Cassandra,性价比更高,功能更丰富,推荐使用企业版.<云数据库产品总览.Cassandra是连续9年DB-Engines排名第一的宽表数据库,支持类SQL语法CQL,开发体验类似MySQL,可扩展PB级存储及千万OPS读写能力。推出企业版Lindorm for Cassandra云原生多模数据库,采用存储计算分离架构,支持海量...
来自:
云产品
云数据库产品总览(瑶池)
阿里云提供完善的数据库解决方案,多款数据库产品,满足99%的业务场景,荣获Gartner、信通院等国内外多项认证。轻松满足高可靠、高可用性、高性能等数据库需求;运维工作量大幅减少,让企业一站式享受数据上云及分布式架构的技术红利!
小打卡用户每天在数十万的兴趣圈子中活跃,发布数百万条打卡日记,PolarDB 分布式版的分库分表场景很好地解决了客户需求,降低了响应时间,提高了并发查询能力,利用异构索引表满足了客户多维度查询的需求,最近的全局二级索引解决了异构索引表数据延迟的问题.通过PolarDB+数据传输服务+AnalyticDB MySQL组成HTAP解决方案,...
来自:
云产品
云原生多模数据库Lindorm
云原生多模数据库Lindorm提供各规模、多模型的云原生数据库服务。可兼容HBase/Cassandra、OpenTSDB、Solr、SQL、HDFS等多种开源标准接口。支持海量数据的低成本存储处理和弹性按需付费,是互联网、IoT、车联网、广告、社交等场景首选数据库,也是为阿里核心业务提供支撑的数据库之一。
海量数采测点数据高通量、高并发、低延迟写入,库内高效数据统计、计算、处理等分析任务执行.工业数据云IT&OT融合存储分析.使用Lindorm存储广告营销中的画像特征、用户事件、点击流、广告物料等重要数据,提供高并发、低延迟、灵活可靠的能力,帮助您构建高效的实时竞价、广告定位投放等系统服务.千万并发下,仍可保持单个...
来自:
云产品
云数据库HBase
阿里云云数据库 HBase 版(ApsaraDB for HBase)是基于 Hadoop 且100%兼容HBase协议的高性能、可弹性伸缩、面向列的分布式数据库,轻松支持PB级大数据存储,满足千万级QPS高吞吐随机读写场景。
云数据库 HBase 版是面向大数据领域的一站式NoSQL服务,100%兼容开源HBase并深度扩展,支持海量数据下的实时存储、高并发吞吐、轻SQL分析、全文检索、时序时空查询等能力,是风控、推荐、广告、物联网、车联网、Feeds流、数据大屏等场景首选数据库,是为淘宝、支付宝、菜鸟等众多阿里核心业务提供关键支撑的数据库.Lindorm...
来自:
云产品
混合云自有K8S弹性使用ECI
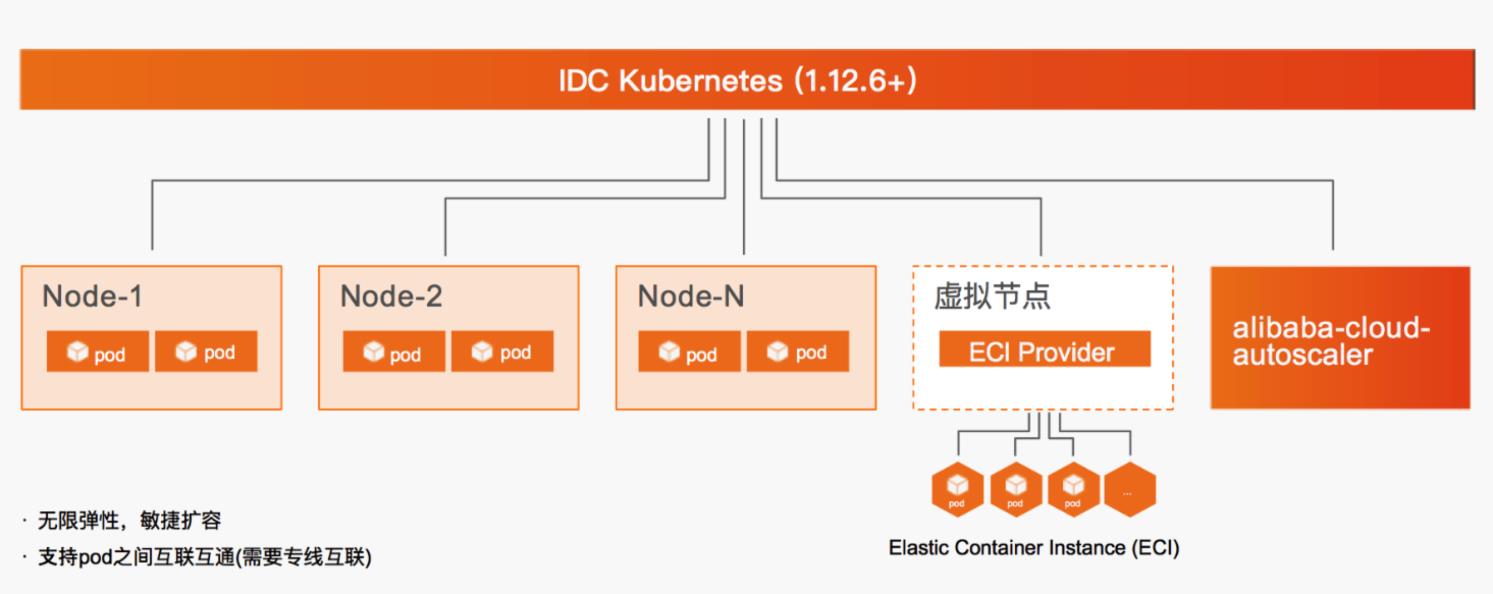
场景描述 本文介绍线下IDC与云端通过专线构建混合云架构,自有K8S利用虚拟节点弹性调用ECI承载业务高峰期资源需求的最佳实践。 解决问题 混合云环境下,自有K8S集群注册至ACK,实现云端纳管。纳管K8S集群部署Virtual Node,使集群具备ECI资源调度能力。在以上环境中部署Web及离线作业应用,并使用ECI资源作为弹性资源池满足业务波峰需求。 产品列表 云服务器ECS 云架构设计工具CADT 专有网络VPC 访问控制RAM 云企业网CEN 弹性容器实例ECI Nat网关NAT 容器镜像服务ACR 负载均衡SLB 容器服务Kubernetes版ACK 弹性公网IPEIP
注:实际当扩展 WordPress Pod实例时,需要使用统一的持久化存储来保证数 据一致性。本例中重点介绍 ECI的资源使用,故此处简化略去。步骤6 完成以上修改后,在 namespace blog下创建 WordPress应用。文档版本:20210520 49 混合云 IDC自有 K8S弹性使用 ECI ECI使用示例 步骤7 创建完成后,点击返回箭头确认应用状态。文档...
基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测

本篇最佳实践先创建EMR集群作为数据湖对象,Hive元数据存储在DLF,外表数据存储在OSS。然后使用阿里云数据仓库MaxCompute以创建外部项目的方式与存储在DLF的元数据库映射打通,实现元数据统一。最后通过一个毒蘑菇的训练和预测demo,演示云数仓MaxCompute如何对于存储在EMR数据湖的数据进行加工处理以达到业务预期。
基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测实践 业务架构 场景描述 数据湖和数据仓库是当前大数据技术条件下构建分布式系 统的两种数据架构设计取向,数据湖偏向灵活性,数据仓 库侧重成本、性能、安全、治理等企业级特性。但是数据 湖和数据仓库的边界正在慢慢模糊,数据湖自身的治理能 力、数据仓库延伸到外部...
数据管理与服务
数据管理与服务作为阿里云产品六大版块之一,面向不同业务场景,阿里云提供数据存储、分析、应用等全链路能力,满足企业客户全方位的数据处理需求,实现计算和存储分离、资源解耦、数据移动减化,用以满足行业快速发展的需求和趋势,利用数据重塑其业务。
本书由阿里云及网易数帆、美创科技、CUUG、恒辉信达等开源生态合作伙伴共同出品,从安装部署到运维实践、开发工具,八大章节轻松入门 PolarDB for PostgreSQL 开源数据库.PolarDB for PostgreSQL 从入门到实战.由阿里巴巴多位技术专家精心打磨内容,通过详细的图文介绍,深度剖析实时数仓面临挑战与发展趋势,详细介绍...
来自:
云产品
云消息队列 Kafka 版
云消息队列 Kafka 版是阿里云基于Apache Kafka构建的大数据消息中间件,广泛用于日志收集和分析、数据处理等场景。可提供全托管服务,用户无需部署运维,更专业、更可靠、更安全。
近年来KV存储(HBase)、搜索(ElasticSearch)、流式处理(Storm/Spark Streaming/Samza)、时序数据库(OpenTSDB)等专用系统应运而生,产生了同一份数据集需要被注入到多个专用系统内的需求。利用云消息队列 Kafka 版作为数据中转枢纽,同份数据可以被导入到不同专用系统中.发布/订阅模型,支持同份数据集能同时被消费多...
来自:
云产品
云原生数据湖分析DLA
阿里云云原生数据湖分析是新一代大数据解决方案,采取计算与存储完全分离的架构,支持对象存储(OSS)、RDS(MySQL等)、NoSQL(MongoDB等)数据源的消息实时归档建仓,提供Presto和Spark引擎,满足在线交互式查询、流处理、批处理、机器学习等诉求。内置大量优化+弹性,比开源自建集群最高降低50%+的成本,最快可1分钟级拉起300个计算节点,快速满足业务资源要求。
兼容Presto、Spark.Serverless形态,无需购买任何资源,互联网直接访问,降低运维成本,免去大数据库系统构建烦扰.OSS数据直接分析,构建大规模分析数据集,延迟大约为10分钟.多源数据实时入湖.集群按需快速扩展,1分钟最快弹出300个节点,灵活应对业务变化.海量算力即时扩容.查看全部日志.云原生数据湖分析(DLA)产品退市...
来自:
云产品
Databricks数据洞察
阿里云Databricks数据洞察是基于Apache Spark的全托管数据分析平台, 内核采用更高效、稳定的商业版Databricks Runtime和Delta Lake。可满足数据分析师、数据工程师和数据科学家在大数据场景下对数据湖分析、实时数仓、离线数仓、BI数据分析、AI机器学习等需求
集群之间共享数据库、表的元信息,无需重复创建.100%兼容开源Spark,迁移成本低,性能表现优异.完全兼容Spark生态.在Apache Spark基础上做了大量的性能优化,且针对阿里云OSS做了I/O优化,提供了更快速、更高效的计算引擎.较开源Delta Lake,功能更完备,对核心功能点均有更深度的优化和性能提升.与阿里云RAM集成,可以根据...
来自:
云产品
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
将订正后的转储文件导入到 RDS for MySQL实例中中,我们在 Databricks数 据洞察集群的 Hive元数据库中导入了客户 Hive元数据库的转储文件,创建了一系列 的数据表并插入了数据。在本实践方案中,Hive版本从客户 IDC的 1.2.2变更为阿里云 Databrickes数据洞察 集群的 2.3.5,但是 Databricks 数据洞察集群 Hive 元数据库中的...
- 产品推荐
- 这些文档可能帮助您