- 相关产品:
- 电动车桩运营解决方案 智能井盖解决方案 跨链数据连接服务解决方案
数据管理与服务
数据管理与服务作为阿里云产品六大版块之一,面向不同业务场景,阿里云提供数据存储、分析、应用等全链路能力,满足企业客户全方位的数据处理需求,实现计算和存储分离、资源解耦、数据移动减化,用以满足行业快速发展的需求和趋势,利用数据重塑其业务。
波克科技股份有限公司通过引入阿里云云原生实时数据仓库AnalyticDB,实现了每日百亿级游戏玩家行为数据的快速分析和处理,大幅降低数据分析成本,相比原有方案,数据处理性能提升10倍以上.网络安全升级支持IPV6.云原生数据仓库 AnalyticDB MySQL版.通过引入Hologres搭建的实时数仓,支撑了百亿级的业务数据复杂多维分析秒级...
来自:
云产品
云数据库ClickHouse
云数据库ClickHouse 是阿里云提供的分布式实时分析型列式数据库服务。具有高性能、开箱即用、企业特性支持。广泛应用于流量分析、广告营销分析、行为分析、人群划分、客户画像、敏捷BI、数据集市、网络监控、分布式服务和链路监控等业务场景。
产品功能湖仓一体实时数据分析 兼容开源,内核优化升级,专家服务支持 冷热数据分层存储 基于热存储使用率和TTL 管理数据,根据策略自动进行数据移动,降低存储成本立即查看 OSS 和 ODPS 外表接入 支持OSS 和ODPS外表,基于外部存储实现低成本数据湖分析和数据导入立即查看 资源队列 支持创建定义多个资源队列,将用户和...
来自:
云产品
EMR HBase on OSS存算分离集群快速恢复
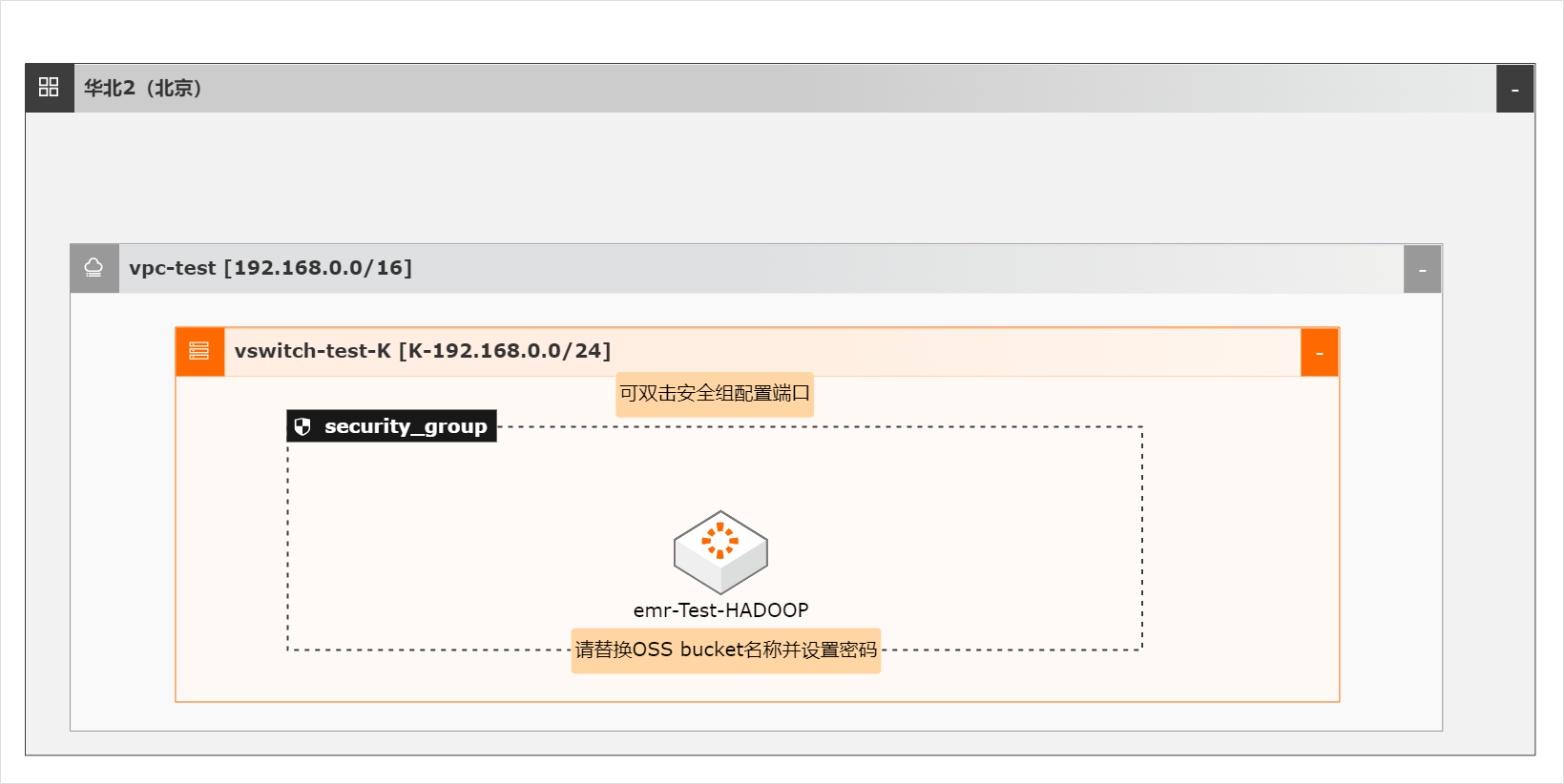
OSS-HDFS服务(JindoFS服务)是一款云原生数据湖存储产品。基于统一的元数据管理能力,在完全兼容HDFS文件系统接口的同时,提供充分的POSIX能力支持,能更好地满足大数据和AI等领域的数据湖计算场景。
基于统一的元数据管理能力,在完全兼容 HDFS文件系统接口的同时,提供充分的 POSIX能力支持,能更好地 满足大数据和 AI 等 领 域 的 数 据 湖 计 算 场 景。详见:https://help.aliyun.com/document_detail/405089.html EMR:开源大数据平台 E-MapReduce(简称“EMR”)是云原生开源大数据平台,向客户提供简单易集成的 ...
MaxCompute湖仓一体方案
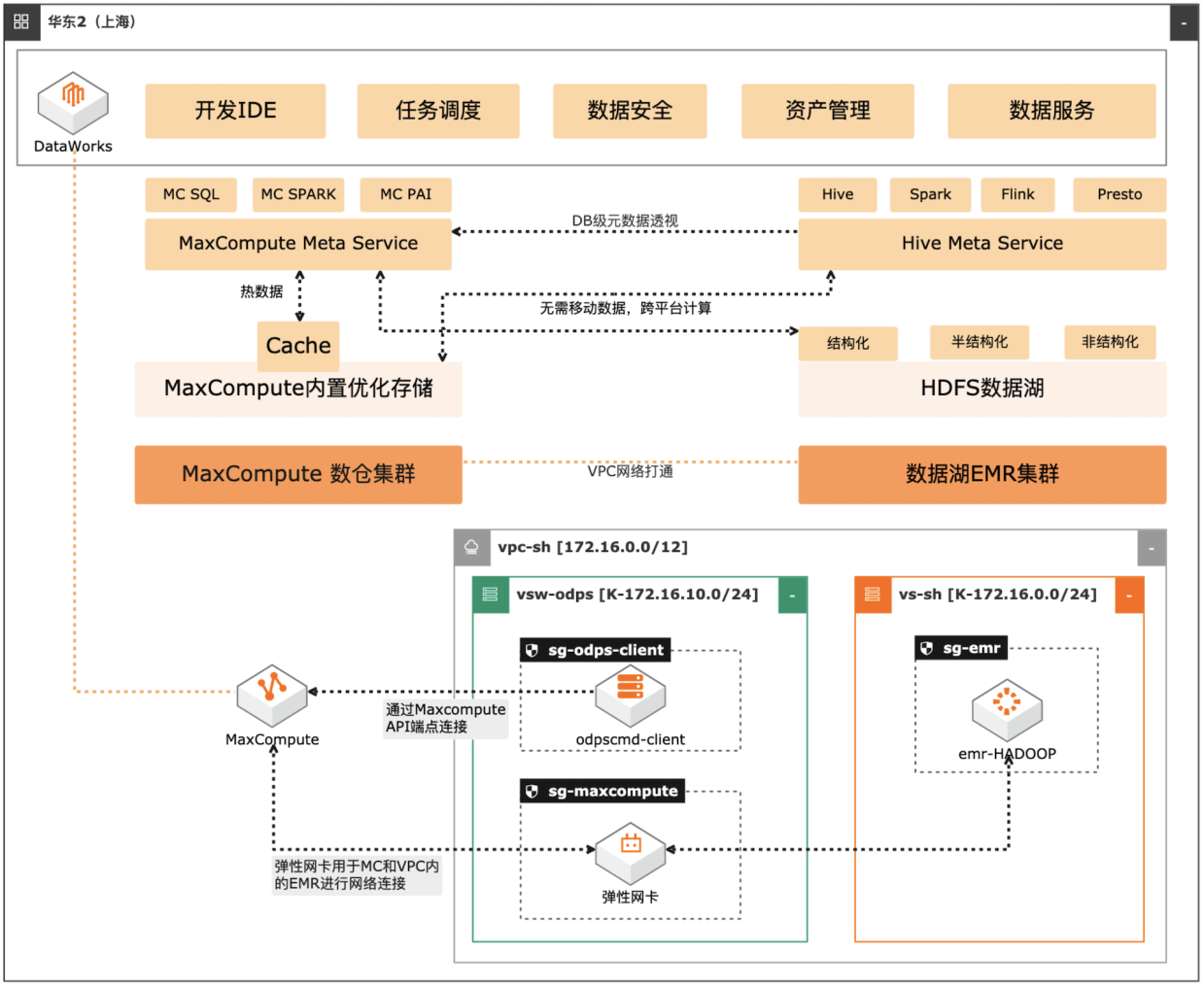
场景描述 自建数据湖与云数仓的融合解决方案,将 MaxCompute与自建的Hive集群做数据打 通,通过存储共享,元数据镜像等方式,解 决传统模式下的存储冗余,计算资源弹性能 力弱的痛点。可大幅度增强系统的资源弹 性,解决业务高峰期计算资源不足的问题。 方案优势 1.业务无侵入性:现有业务无需改造。 2.性能优化:MaxCompute在SQL上做 了大量优化与能力沉淀,可提高SQL 运行性能,降低计算成本。 3.灵活管理:元数据实时同步,无需额外 管理数据同步任务。 4.资源弹性:利用MaxCompute计算池 弹性进行海量数据计算。 解决问题 1.增强业务高峰期的资源弹性。 2.优化自建数据湖的数据治理能力。 3.减少跨平台数据处理的存储冗余。 产品列表 专有网络VPC 云服务器ECS 访问控制RAM 运维编排OOS MaxCompute(原ODPS) 云企业网CEN
提供用户在云上 使用开源技术建设数据仓库、离线批处理、在线流式处理、即时查询、机器学习等 场 景 下 的 大 数 据 解 决 方 案。更 多 信 息,请 参 见:https://www.aliyun.com/product/emapreduce 文档版本:20220402 III MaxCompute湖仓一体方案 目录 目录 文档版本信息.I 法律声明.II 产品介绍.III 目录.IV 最佳实践...
云消息队列 RocketMQ 版
云消息队列 RocketMQ 版是基于 Apache RocketMQ 构建的分布式消息中间件,广泛用于异步解耦、削峰填谷等场景。可支撑千万级并发、万亿级数据洪峰,更稳定,更安全。
常规数据源 更丰富数据源 本地数据库(局域网)本地部署版用户可以连接本地数据库进行数据分析。查看更多组件 常规图表组件 添加地图组件 ECharts组件.API 请求资源包,更优惠.资源包,更优惠.专享实例,更稳定,更可靠,专家保驾护航.唐家哲,靖鑫,也树.旧商品卡片,建议使用「轻量商品卡片」.消息队列 RabbitMQ 版.完全...
来自:
云产品
自建Hive数仓迁移到阿里云EMR
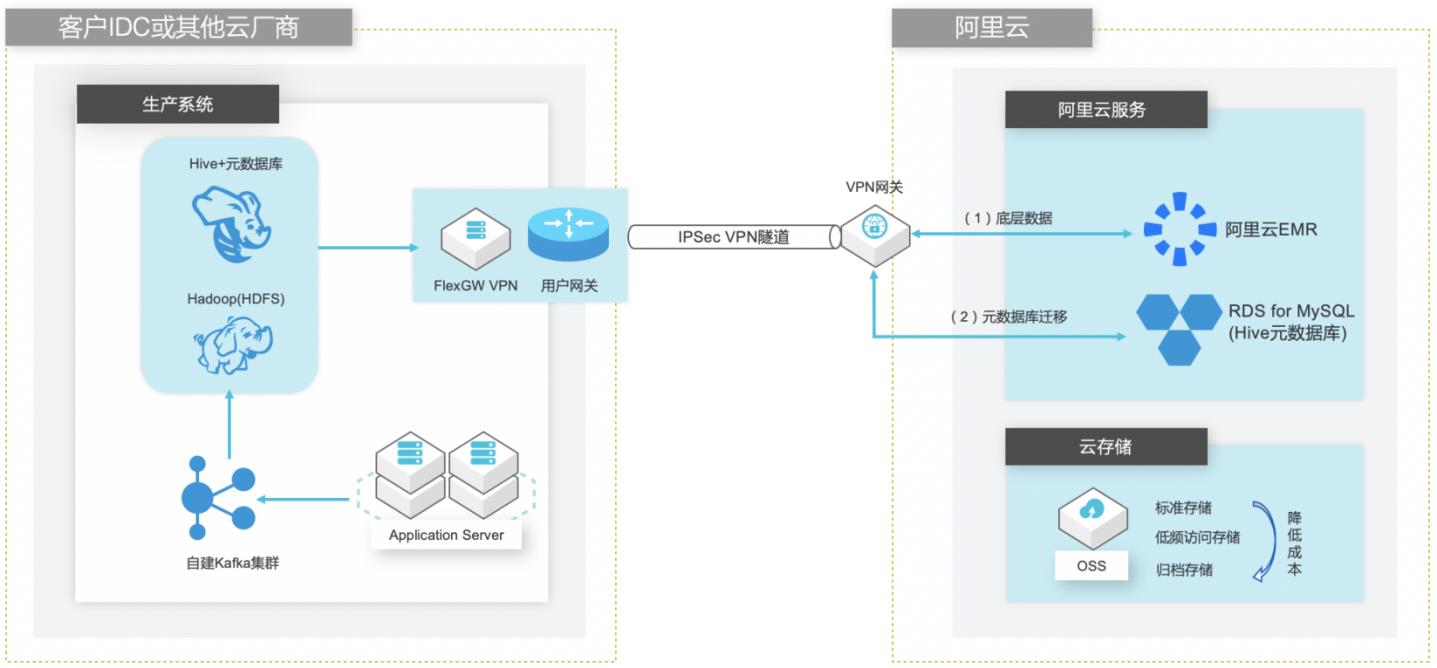
场景描述 客户在IDC或者公有云环境自建Hadoop集群构 建数据仓库和分析系统,购买阿里云EMR集群之 后,涉及到将数据仓库和Hive元数据的数据库迁 移上云。目前主流Hive数据仓库迁移场景为1.x 版本迁移到阿里云EMR(Hive2.x版本),涉及到 数据订正更新步骤。 解决的问题 Hive数据仓库的数据迁移方案 Hive元数据库的迁移方案 Hive跨版本迁移后的数据订正 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
自建 Hive数据仓库跨版本迁移到阿里云 EMR 场景描述 解决的问题 客户在IDC或者公有云环境自建Hadoop集群构建 Hive数据仓库的数据迁移方案 数据仓库和分析系统,购买阿里云 EMR集群之后,Hive元数据库的迁移方案 涉及到将数据仓库和Hive元数据的数据库迁移上 Hive跨版本迁移后的数据订正 云。目前主流 Hive数据仓库迁移场景...
微服务中心解决方案
注册中心和配置中心是 Dubbo 和 Spring Cloud 微服务架构中的重要组件,往往采用 ZooKeeper/Nacos/Eureka/Apollo 等开源方案进行自建,但因其依赖复杂,往往给客户带来的较高的建设和运维成本,同时,在 Hbase、Spark或Kafka 等大数据的环境下,会依赖 ZooKeeper 进行分布式系统的协调,此时,基于云上的托管服务,可以极大的降低运维复杂度,并提高应用可用性。
本方案基于多源异构大数据的汇聚共享和交通专题库的建立,并在数据的基础上通过交通算法、AI、视觉分析、交通仿真等智能引擎评估业务状态,为公路管理者提供规程化、模式化的方案.蔡伟杰,靖鑫,也树.在提供注册和配置中心托管的基础上,还提供了微服务治理能力,例如离群实例摘除功能,用于保护应用免受单点异常的困扰,金丝...
来自:
解决方案
MRACC加速倚天ECS实例Flink集群性能
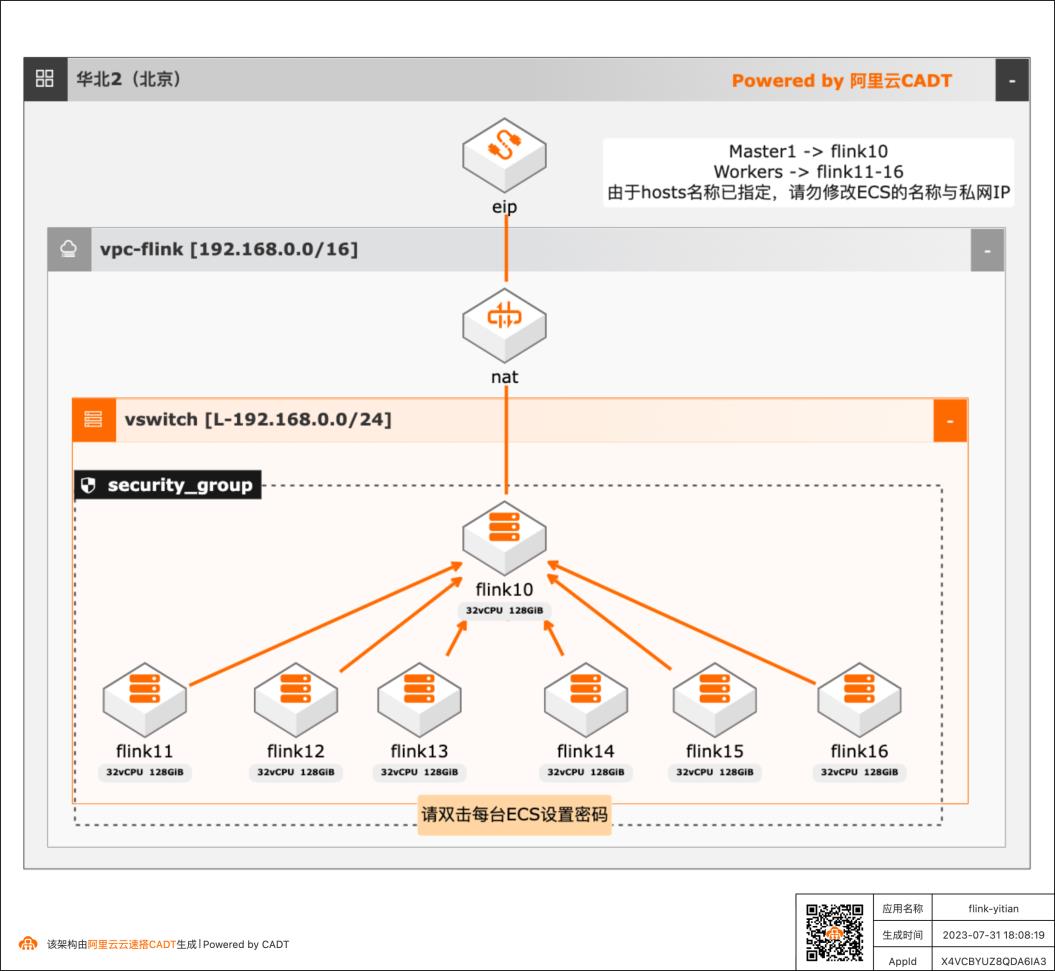
希望了解Flink集群on倚天的部署架构。 通过神龙大数据加速引擎 Mracc 提升Flink集群性能。 希望实测了解倚天ECS实例运行Flink集群的性能 架构设计:利用阿里云官方架构设计模版,在此基础上二次定制(调整规格、资源数量、配置调整)。 快速完成PoC和生产环境的设计和部署
cd/opt/fastmr/nexmark nohup sh test.sh&步骤2 通过日志文件查看压测脚本执行情况 tail-f/opt/fastmr/nexmark/nexmark.out 文档版本:20230801 18 MRACC加速倚天 ECS实例 Spark集群性能 部署基础环境 步骤3 通过日志文件查看压测数据生成进度 测试一共会跑 22个查询,大概需要 50分钟左右,若日志显示了 q22的Nexmark结 果...
大数据近实时数据投递MaxCompute
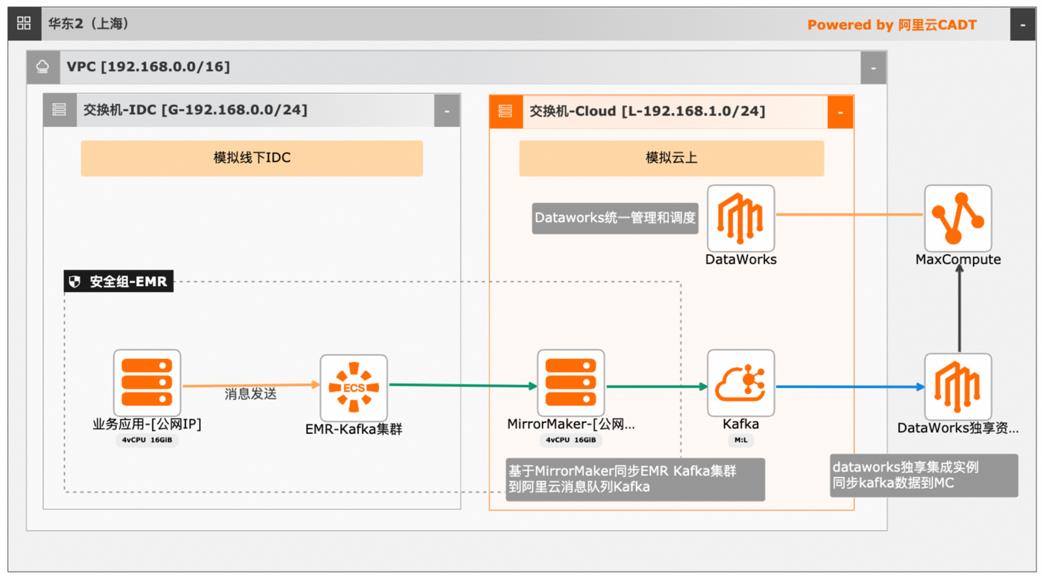
本文介绍离线大数据场景使MaxCompute构建云 上近实时数仓,打通云下数据上云链路,解决数据复杂类型支持和动态分区问题,满足高级数据处理需求的最佳实践。 l混合云环境下,现有业务系统零改造,打通数据上云链路。 l使用UDF实现复杂数据类型转换和数据动态分区。 l使用DataWorks配置周期调度业务流程,数据自动入仓。 l借助MaxCompute优化计算引擎,实现降本增效。 产品列表 云服务器ECS 专有网络VPC 访问控制RAM 数据总线DataHub E-MapReduceEMR DataWorks 大数据计算服务MaxCompute
MaxCompute已与数据集成、DataWorks、QuickBI、机器学习 PAI、ADB、推荐引擎、移动数据分析等大数据产 品打通,可快速集成使用,轻松应对各种大数据应用场景。本文以线下现有业务大数据离线数仓建设为背景,介绍如何在现有业务应用系统零 改造的前提下,从 Kafka集群切入,打通数据上云链路,解决数据复杂类型支持和 动态...
基于DataWorks的大数据一站式开发及数据治理

概述 基于Dataworks做大数据一站式开发,包含数据实时采集到kafka通过实时计算对数据进行ETL写入HDFS,使用Hive进行数据分析。通过Dataworks进行数据治理,数据地图查看数据信息和血缘关系,数据质量监控异常和报警。 适用场景 日志采集、处理及分析 日志使用Flink实时写入HDFS 日志数据实时ETL 日志HIVE分析 基于dataworks一站式开发 数据治理 方案优势 大数据一站式开发,完善的数据治理能力。 性能优越:高吞吐,高扩展性。 安全稳定:Exactly-Once,故障自动恢复,资源隔离。 简单易用:SQL语言,在线开发,全面支持UDX。 功能强大:支持SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据源计算等Data Lake相关功能 ,以及各种流式及静态数据源关联查询。
kafka通过实时计算对数 据进行 ETL写入 HDFS,使用 Hive进行数据分析。通过 DataWorks进行数据治理,数据地图查看数据信息和血缘关系,数据质量监控异常和报警。名词解释 HDFS:Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件上的分 布式文件系统,它和现有的分布式文件系统有很多共同点。但同时,它和其他的分 ...
开源Flink迁移实时计算Flink全托管版最佳实践
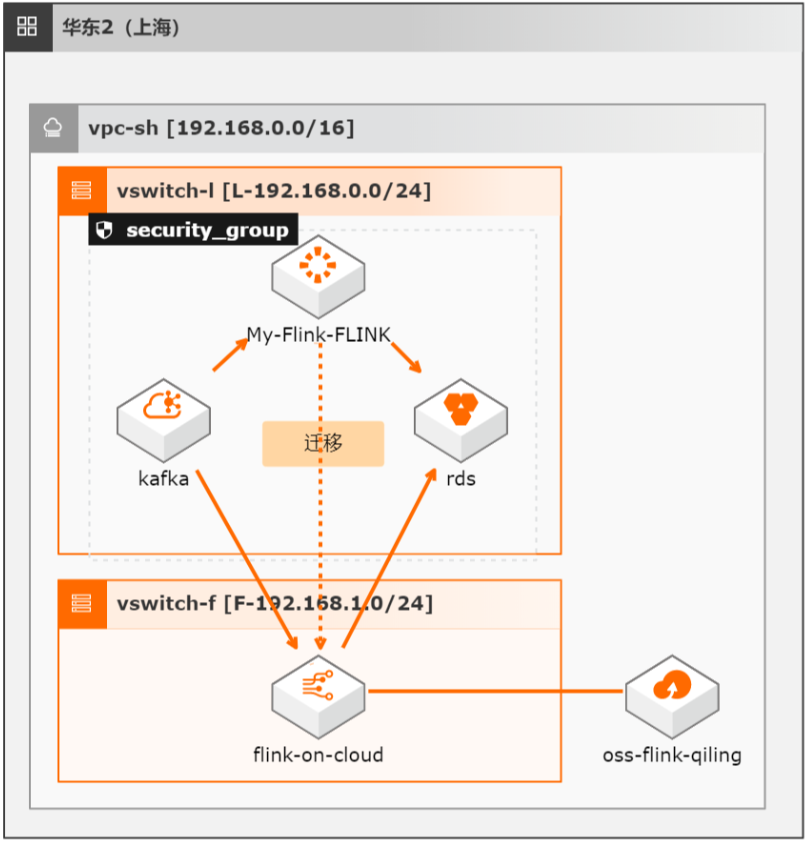
本方案介绍如何将自建开源Flink集群的流式任务(包含Datastream、Table/SQL、PyFlink任务)迁移至阿里云实时计算全托管版。
比如聚合任务按小时、天维度计算的聚合值,清洗任务加工的按天分区表等,在数据对比时就可以根据对应的时间周期来进对比,比如小时周期的任务实际已完整处理多个小时数据 后,就可以对比处理过的小时数 据,而天维度的聚合值,一般就需要等待新任务处理完完整的一天数 据后才能对比。2、数据规模 中小数据规模:建议进行全量...
EMR本地盘实例大规模数据集测试
场景描述 阿里云为了满足大数据场景下的存储需求,在云 上推出了本地盘D1机型,这个系列提供了本地 盘而非云盘作为存储,提高了磁盘的吞吐能力, 发挥Hadoop的就近计算优势。阿里云EMR 产品针对本地盘机型,推出了一整套的自动化运 维方案,帮助用户方便可靠地使用本地盘机型, 不需要关注整个运维过程同时数据的高可靠和 服务的高可用。 解决问题 1.云盘多份冗余数据导致成本高 2.磁盘吞吐量不高 3.节点的高可靠分布问题 4.本地盘与节点的故障监控问题 5.数据迁移时自动决策问题 6.自动故障节点迁移与数据平衡问题 产品列表 EMR(E-MapReduce) 本地盘 VPC
应用范围 需要使用阿里云 EMR+本地盘进行大数据业务前进行性能测试的用户 线下自建大数据集群用户需要迁移到阿里云云上 EMR+本地盘进行大数据分析性 能对比测试的用户 名词解释 VPC:Virtual Private Cloud,简称 VPC。基于阿里云创建的自定义私有网络,不 同的专有网络之间二层逻辑隔离,可以在自己创建的专有网络内创建和...
互联网电商行业离线大数据分析

电商网站销售数据通过大数据分析后将业务指标数据在大屏幕上展示,如销售指标、客户指标、销售排名、订单地区分布等。大屏上销售数据可视化动态展示,效果震撼,触控大屏支持用户自助查询数据,极大地增强数据的可读性。
互联网电商行业离线大数据分析 最佳实践 业务架构 场景描述 本实践介绍了使用阿里云MaxCompute、数据库(RDS)、DataWorks等产品实现电商网站离线数据分 析,分析后的业务指标数据实时在大屏展示。通过完整 的实践Demo为例,提供从电商网站搭建,数据从RDS 同步到MaxCompute、再到DataWorks进行数据分析,最后在大屏上展示...
游戏数据运营融合分析
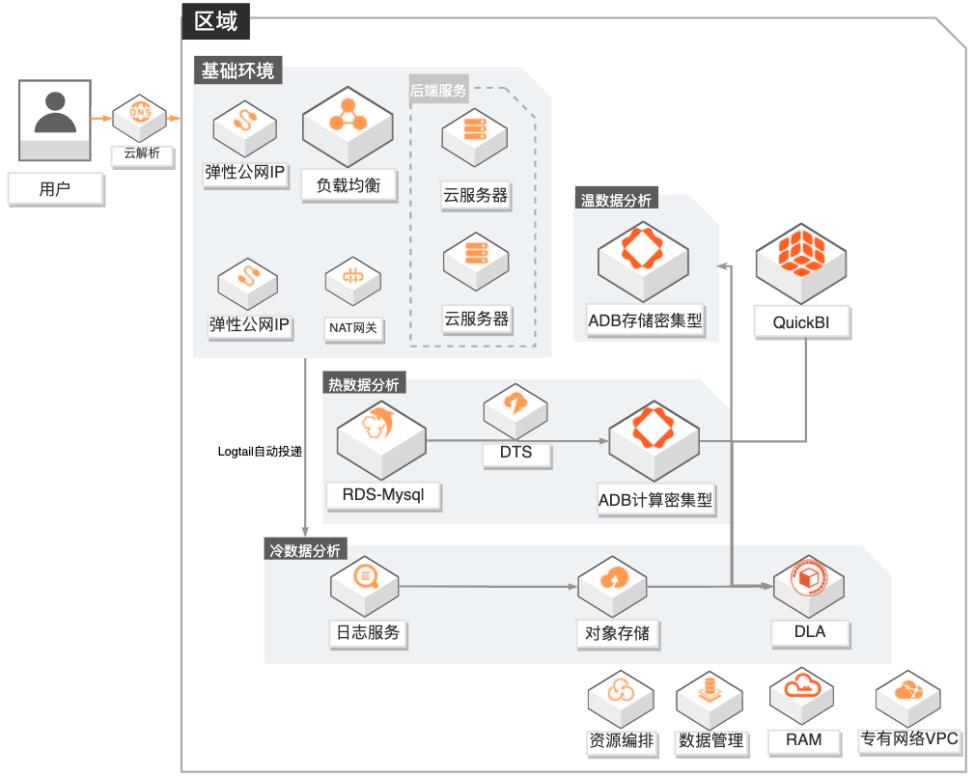
场景描述 1.游戏行业有结构化和非结构化数据融合分 析需求的客户。 2.游戏行业有数据实时分析需求的客户,无法 接受T+1延迟。 3.对数据成本有一定诉求的客户,希望物尽其 用尽量优化成本。 4.其他行业有类似需求的客户。 方案优势/解决问题 1.秒级实时分析:依托ADB计算密集型实例, 秒级监控DAU等数据,为广告投放效果提 供有力的在线决策支撑。 2.高效数据融合分析:打通结构化和非结构化 数据,支撑产品体验分析;广告买量投放效 果实时(分钟级)分析,渠道的评估更准确。 3.低成本:DLA融合冷数据分析+ADB存储密 集型温数据分析+ADB计算密集型热数据分 析,在满足各种分析场景需求的同时,有效 地降低的客户的总体使用成本。 4.学习成本低:DLA和ADB兼容标准SQL语 法,无需额外学习其他技术。 产品列表 专有网络VPC、负载均衡SLB、NAT网关、弹性公网IP 云服务器ECS、日志服务SLS、对象存储OSS 数据库RDSMySQL、数据传输服务DTS、数据管理DMS 分析型数据库MySQL版ADS 数据湖分析DLA、QuickBI
文档版本:20210224 101 游戏数据运营融合分析 数据分析及展示 步骤2 创建 quickBI数据集,对近一个小时每分钟活跃用户数进行分析。文档版本:20210224 102 游戏数据运营融合分析 数据分析及展示 文档版本:20210224 103 游戏数据运营融合分析 数据分析及展示 步骤3 新建仪表板,展现分析结果。文档版本:20210224 104 游戏...
- 产品推荐
- 这些文档可能帮助您