自建Hive数仓迁移到阿里云EMR
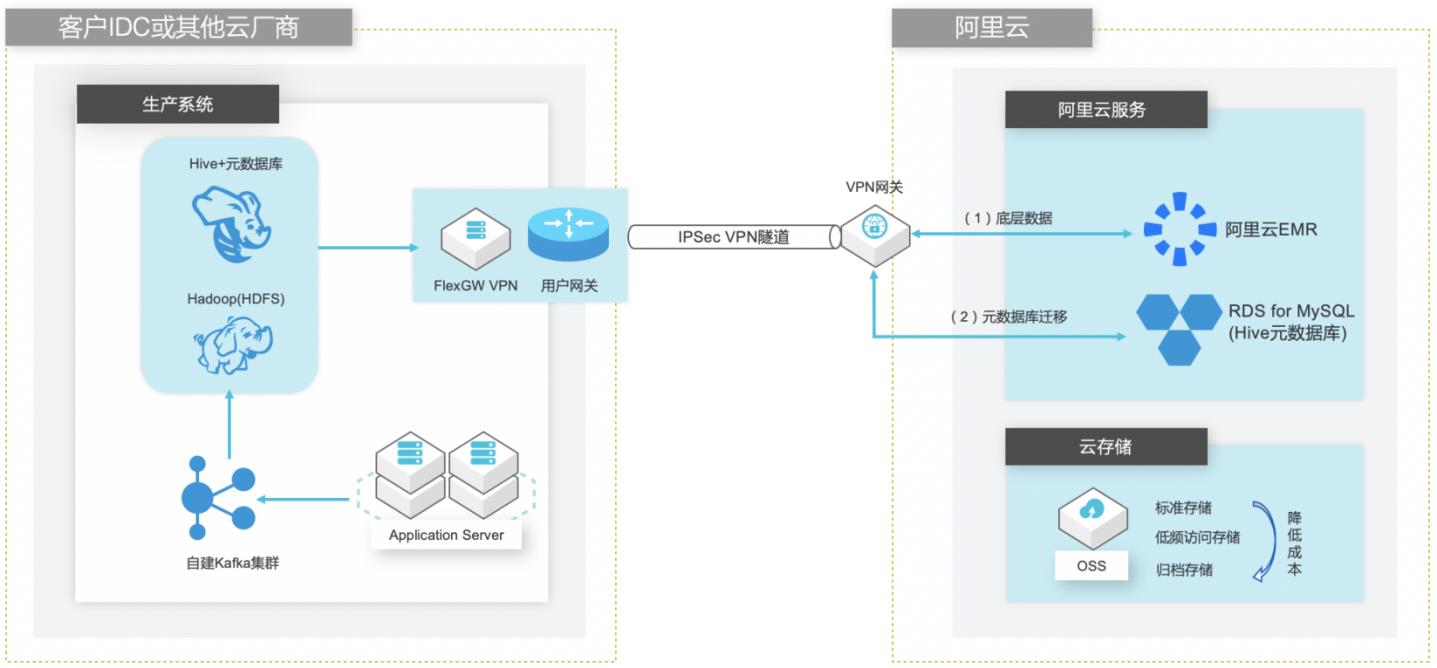
场景描述 客户在IDC或者公有云环境自建Hadoop集群构 建数据仓库和分析系统,购买阿里云EMR集群之 后,涉及到将数据仓库和Hive元数据的数据库迁 移上云。目前主流Hive数据仓库迁移场景为1.x 版本迁移到阿里云EMR(Hive2.x版本),涉及到 数据订正更新步骤。 解决的问题 Hive数据仓库的数据迁移方案 Hive元数据库的迁移方案 Hive跨版本迁移后的数据订正 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
自建 Hive数据仓库跨版本迁移到阿里云 EMR 场景描述 解决的问题 客户在IDC或者公有云环境自建Hadoop集群构建 Hive数据仓库的数据迁移方案 数据仓库和分析系统,购买阿里云 EMR集群之后,Hive元数据库的迁移方案 涉及到将数据仓库和Hive元数据的数据库迁移上 Hive跨版本迁移后的数据订正 云。目前主流 Hive数据仓库迁移场景...
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
Hive版本从 1.2.2变更为 2.3.5,因此这里我们需要依次执行下面几个 升级脚本:upgrade-1.2.0-to-2.0.0.mysql.sql upgrade-2.0.0-to-2.1.0.mysql.sql upgrade-2.1.0-to-2.2.0.mysql.sql upgrade-2.2.0-to-2.3.0.mysql.sql 步骤3 执行升级脚本更新 Hive元数据库的表结构,红色字体为 RDSforMySQL实例的内网连 接地址。...
云数据库 SelectDB 版
阿里云数据库 SelectDB 是现代化实时数据仓库 SelectDB 在阿里云上的全托管服务,内核基于业界领先的开源分析型数据库 Apache Doris 研发,由阿里云和飞轮科技联合打造。阿里云数据库 SelectDB 聚焦于满足企业级大数据分析需求,广泛应用于实时报表分析、即席多维分析、日志检索分析、数据联邦与查询加速等场景,致力于为客户提供极致性能、简单易用的数据分析服务。
极简易用解决易用性问题支持丰富易用的数据导入方式,帮助客户快速完成数据接入。兼容 MySQL 连接协议和语法,无缝对接数十款数据库和大数据生态产品,降低用户学习成本。提供可视化开发工具,简化数据开发过程。产品功能弹性伸缩按需进行弹性扩缩容,扩缩容过程分钟级完成、无需停服。数据湖分析 支持丰富的数据湖类型,如...
来自:
云产品
EMR本地盘实例大规模数据集测试
场景描述 阿里云为了满足大数据场景下的存储需求,在云 上推出了本地盘D1机型,这个系列提供了本地 盘而非云盘作为存储,提高了磁盘的吞吐能力, 发挥Hadoop的就近计算优势。阿里云EMR 产品针对本地盘机型,推出了一整套的自动化运 维方案,帮助用户方便可靠地使用本地盘机型, 不需要关注整个运维过程同时数据的高可靠和 服务的高可用。 解决问题 1.云盘多份冗余数据导致成本高 2.磁盘吞吐量不高 3.节点的高可靠分布问题 4.本地盘与节点的故障监控问题 5.数据迁移时自动决策问题 6.自动故障节点迁移与数据平衡问题 产品列表 EMR(E-MapReduce) 本地盘 VPC
EMR:E-MapReduce(EMR)是构建在阿里云云服务器 ECS上的开源 Hadoop、Spark、Hive、Flink 生态大数据产品,提供用户在云上使用开源技术建设数据仓 库、离线批处理、在线学习、即时查询、机器学习等场景下的大数据解决方案。PT测试:Power Test(PT)功耗测试,TPC-DS用于大数据性能测试的方法。大数据实例本地盘:阿里云为了...
数据湖-在线学习场景数据分析

场景描述 本场景以在线教育中一个答题闯关类的应用为 例,使用WebServer来模拟演示这类日志数据 的分析处理。通过Nginx和Pythonflask搭建 WebServer,模拟应用中的关键页面,比如登 录、课程内容等,之后构造若干用户使用的模拟 日志数据,投递到数据湖进行分析后获取应用 PV、UV、课程内容访问排行、平均得分等等。 解决问题 基于数据湖(EMR+OSS)搭建大数据平台。 EMR和OSS使用和配置。 数据统一存储到OSS。 产品列表 E-MapReduce 对象存储OSS 云服务器ECS 访问控制RAM 专有网络VPC
借助EMR 可以简单快速的构建一个基于 Hadoop,Spark,Hive等大数据产品的计算集群,而且可以按需使用,其所有 Job完 文档版本:20200331 5数据湖-在线学习场景数据分析 数据湖 成之后,销毁集群,因为所有的数据都保存在OSS。此外,对于Hadoop集群上的任务,不同类型的任务对于机器配置的要求不同,比如 推荐和算法业务可能...
SLS多云日志采集、处理及分析
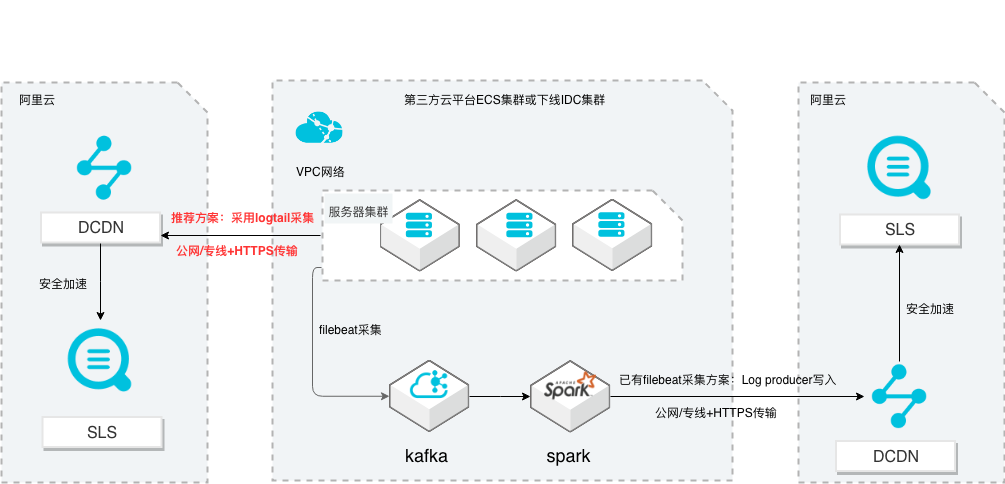
场景描述 从第三方云平台或线下IDC服务器上采集 日志写入到阿里云日志服务,通过日志服务 进行数据分析,帮助提升运维、运营效率, 建立DT 时代海量日志处理能力。 针对未使用其他日志采集服务的用户,推荐 在他云或线下服务器安装logtail采集并使用 Https安全传输;针对已使用其他日志采集 工具并且已有日志服务需要继续服务的情 况,可以通过Log producer SDK写入日志 服务。 解决问题 1.第三方云平台或线下IDC客户需要使用 阿里云日志服务生态的用户。 2.第三方云平台或线下IDC服务器已有完 整日志采集、处理及分析的用户。 产品列表 E-MapReduce 专有网络VPC 云服务器ECS 日志服务LOG DCDN
E-MapReduce:阿里云 E-MapReduce(EMR)是构建在阿里云云服务器 ECS 上 的开源 Hadoop、Spark、Hive、Flink 生态大数据 PaaS 产品。提供用户在云上 使用开源技术建设数据仓库、离线批处理、在线流式处理、即时查询、机器学习 等场景下的大数据解决方案。更多信息,请参见专有 E-MapReduce简介...
开源Flink迁移实时计算Flink全托管版最佳实践
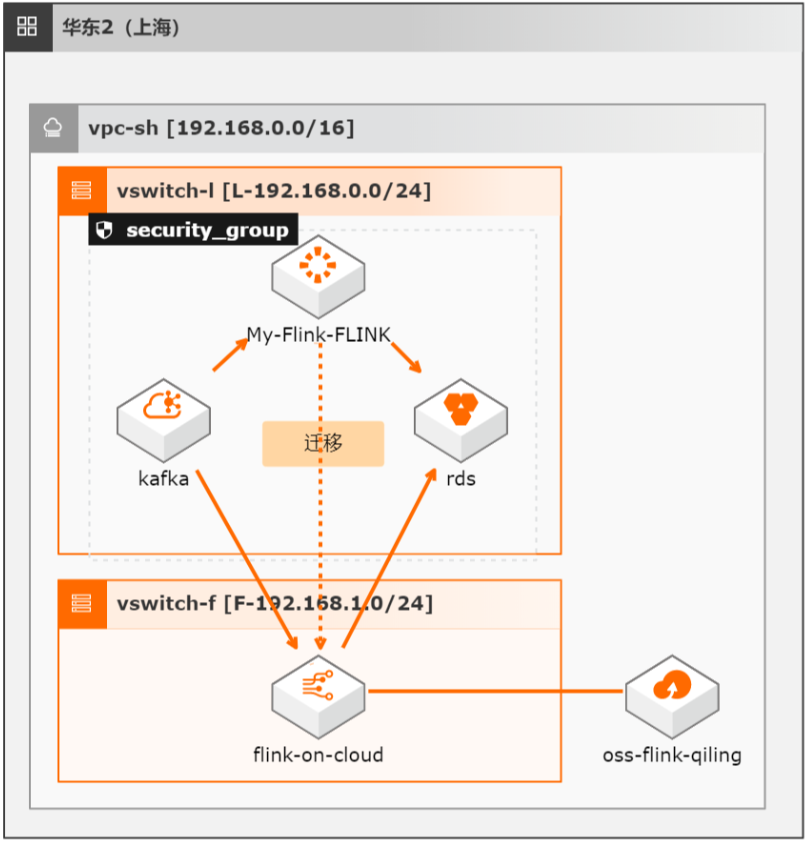
本方案介绍如何将自建开源Flink集群的流式任务(包含Datastream、Table/SQL、PyFlink任务)迁移至阿里云实时计算全托管版。
参见:https://www.aliyun.com/product/kafka E-MapReduce(简称“EMR”):是云原生开源大数据平台,向客户提供简单易集成 的 Hadoop、Hive、Spark、Flink、Presto、Clickhouse、Delta、Hudi等开源大数 据计算和存储引擎。EMR计算资源可以根据业务的需要调整。EMR可以部署在 阿里云公有云的 ECS和 ACK、专有云平台。参见:...
EMR集群安全认证和授权管理
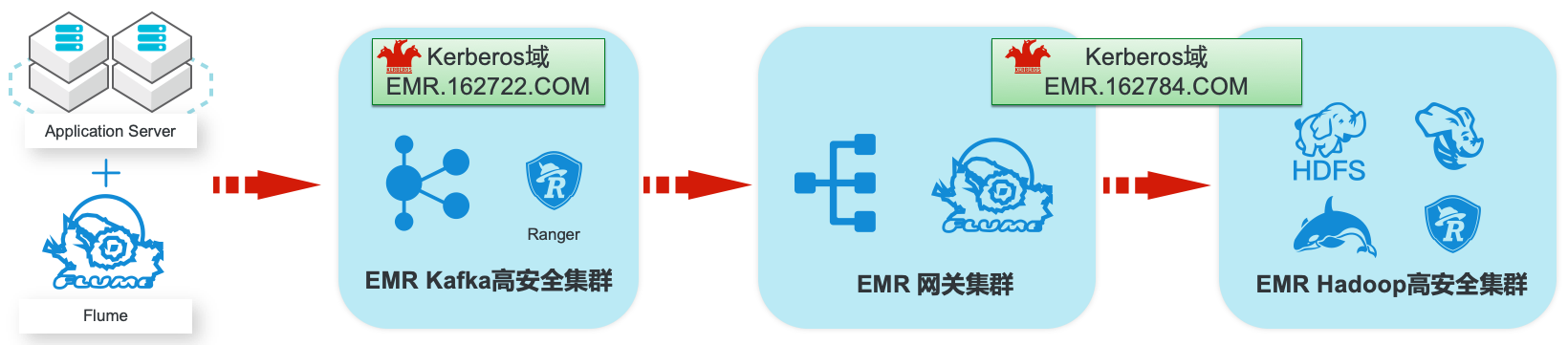
场景描述 阿里云EMR服务Kafka和Hadoop安全集群使 用Kerberos进行用户安全认证,通过Apache Ranger服务进行访问授权管理。本最佳实践中以 Apache Web服务器日志为例,演示基于Kafka 和Hadoop的生态组件构建日志大数据仓库,并 介绍在整个数据流程中,如何通过Kerberos和 Ranger进行认证和授权的相关配置。 解决问题 1.创建基于Kerberos的EMR Kafka和 Hadoop集群。 2.EMR服务的Kafka和Hadoop集群中 Kerberos相关配置和使用方法。 3.Ranger中添加Kafka、HDFS、Hive和 Hbase服务和访问策略。 4.Flume中和Kafka、HDFS相关的安全配 置。 产品列表:E-MapReduce、专有网络VPC、云服务器ECS、云数据库RDS版
步骤5 基础配置:数据库连接,替换为 RDS实例内网连接地址和 Hive元数据库名称,内网连接地址和 数据库名称请参见 3.1.创建并配置 RDS for MySQL实例用于 Hive元数据库。文档版本:20200330 58 EMR集群安全认证和授权管理 EMR Hadoop安全集群和网关集群 在高级设置中,添加 knox用户,选择需要的 RAM子用户并设置密码:文档...
MaxCompute湖仓一体方案
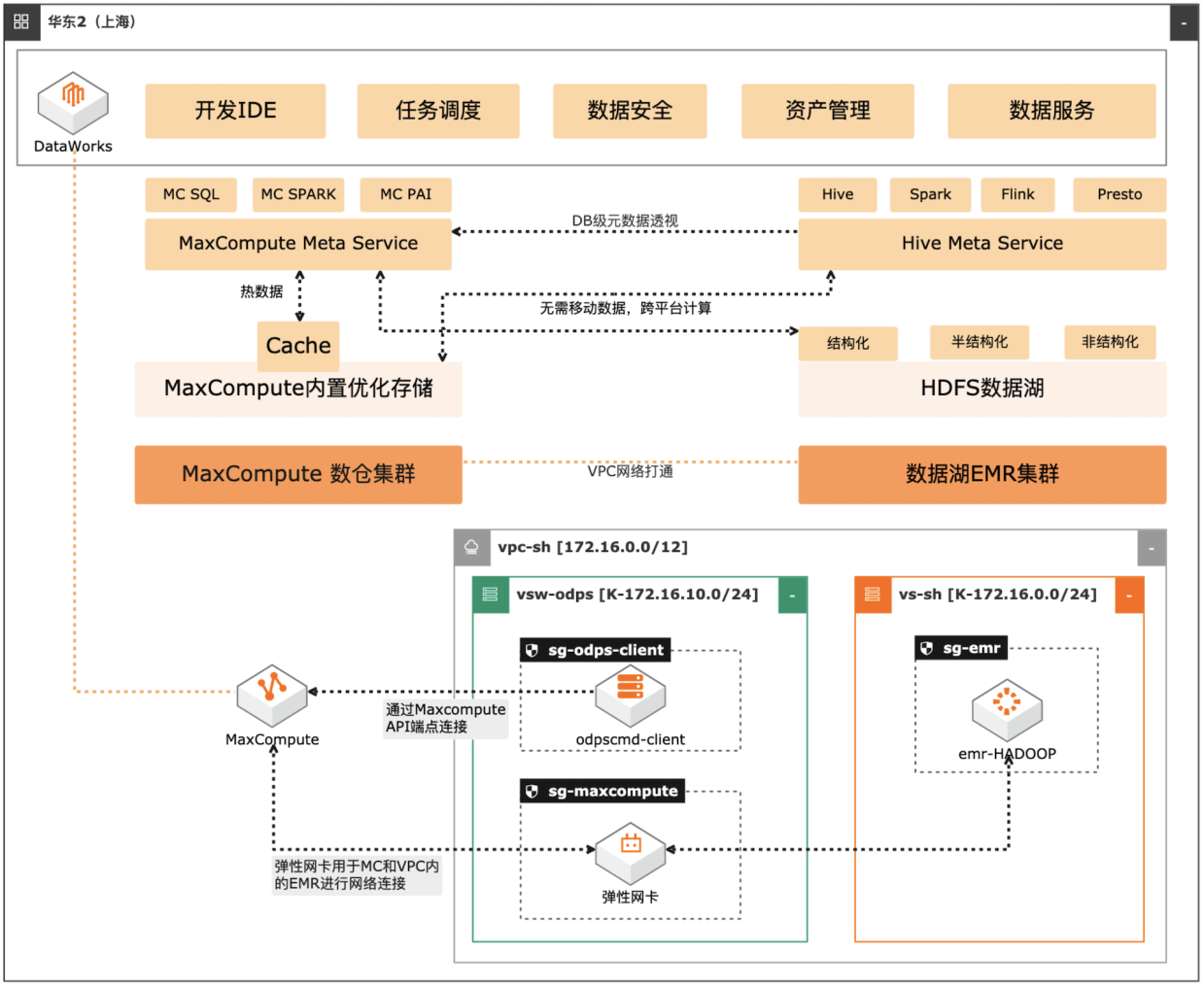
场景描述 自建数据湖与云数仓的融合解决方案,将 MaxCompute与自建的Hive集群做数据打 通,通过存储共享,元数据镜像等方式,解 决传统模式下的存储冗余,计算资源弹性能 力弱的痛点。可大幅度增强系统的资源弹 性,解决业务高峰期计算资源不足的问题。 方案优势 1.业务无侵入性:现有业务无需改造。 2.性能优化:MaxCompute在SQL上做 了大量优化与能力沉淀,可提高SQL 运行性能,降低计算成本。 3.灵活管理:元数据实时同步,无需额外 管理数据同步任务。 4.资源弹性:利用MaxCompute计算池 弹性进行海量数据计算。 解决问题 1.增强业务高峰期的资源弹性。 2.优化自建数据湖的数据治理能力。 3.减少跨平台数据处理的存储冗余。 产品列表 专有网络VPC 云服务器ECS 访问控制RAM 运维编排OOS MaxCompute(原ODPS) 云企业网CEN
EMR:阿里云 E-MapReduce(EMR)是构建在阿里云云服务器 ECS 上的开源 Hadoop、Spark、HBase、Hive、Flink 生态大数据 PaaS 产品。提供用户在云上 使用开源技术建设数据仓库、离线批处理、在线流式处理、即时查询、机器学习等 场 景 下 的 大 数 据 解 决 方 案。更 多 信 息,请 参 见:...
基于DataWorks的大数据一站式开发及数据治理

概述 基于Dataworks做大数据一站式开发,包含数据实时采集到kafka通过实时计算对数据进行ETL写入HDFS,使用Hive进行数据分析。通过Dataworks进行数据治理,数据地图查看数据信息和血缘关系,数据质量监控异常和报警。 适用场景 日志采集、处理及分析 日志使用Flink实时写入HDFS 日志数据实时ETL 日志HIVE分析 基于dataworks一站式开发 数据治理 方案优势 大数据一站式开发,完善的数据治理能力。 性能优越:高吞吐,高扩展性。 安全稳定:Exactly-Once,故障自动恢复,资源隔离。 简单易用:SQL语言,在线开发,全面支持UDX。 功能强大:支持SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据源计算等Data Lake相关功能 ,以及各种流式及静态数据源关联查询。
详情请查看 www.aliyun.com/product/bigdata/product/sc EMR:阿里云 E-MapReduce(EMR)是构建在阿里云云服务器 ECS 上的开源 Hadoop、Spark、HBase、Hive、Flink 生态大数据 PaaS 产品。提供用户在云上 使用开源技术建设数据仓库、离线批处理、在线流式处理、即时查询、机器学习等 场景下的大数据解决方案。详情请查看 ...
大数据近实时数据投递MaxCompute
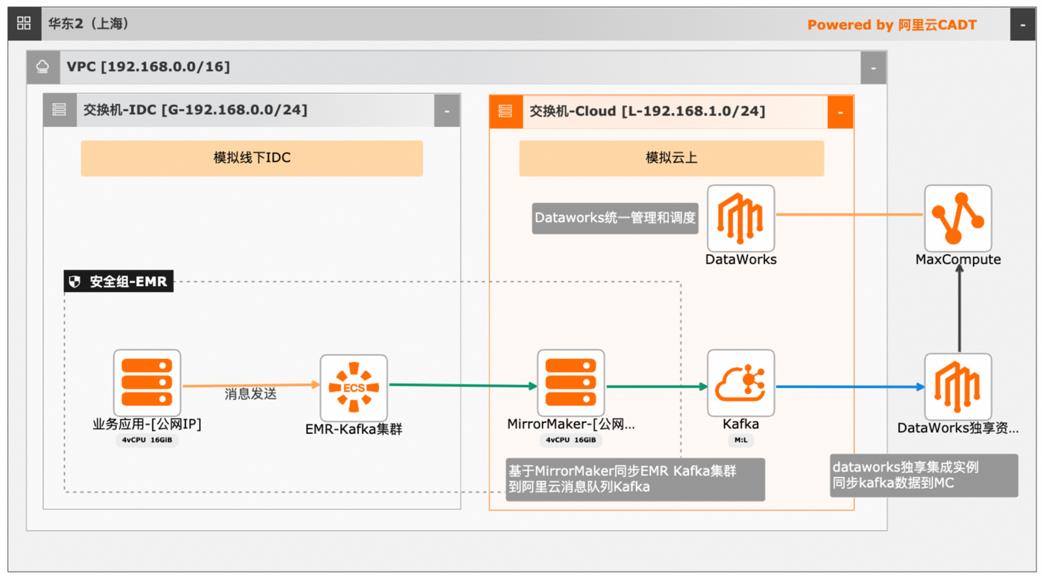
本文介绍离线大数据场景使MaxCompute构建云 上近实时数仓,打通云下数据上云链路,解决数据复杂类型支持和动态分区问题,满足高级数据处理需求的最佳实践。 l混合云环境下,现有业务系统零改造,打通数据上云链路。 l使用UDF实现复杂数据类型转换和数据动态分区。 l使用DataWorks配置周期调度业务流程,数据自动入仓。 l借助MaxCompute优化计算引擎,实现降本增效。 产品列表 云服务器ECS 专有网络VPC 访问控制RAM 数据总线DataHub E-MapReduceEMR DataWorks 大数据计算服务MaxCompute
详见:https://www.aliyun.com/product/ram 文档版本:20240419 III 大数据近实时数据投递 MaxCompute 前言 E-MapReduce EMR:是构建在阿里云云服务器 ECS 上的开源 Hadoop、Spark、HBase、Hive、Flink 生态大数据 PaaS 产品。提供用户在云上使用开 源技术建设数据仓库、离线批处理、在线流式处理、即时查询、机器学习等场 ...
多账号下企业分账
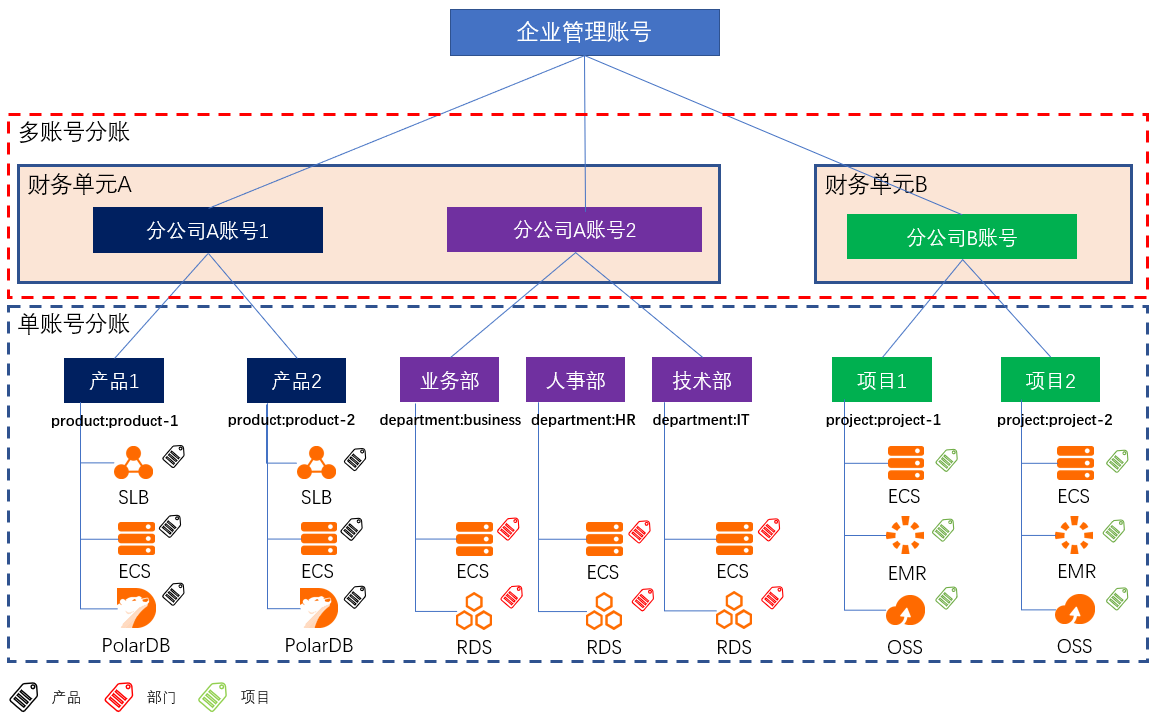
场景描述 财务分账,是根据企业的成本中心,将云上资源的成本划分到给各个项目组/业务部门;助力企业快速梳理云上成本结构,搭建复杂组织架构下的成本关系,便捷地进行财务和云上成本的管理。 大型企业或集团公司,由于组织架构复杂,业务复杂等原因,通常拥有多个阿里云账号来管理规模庞大的云上资源。针对云上资源,如何建立有效的分账方案,是财务关注的重要问题。 解决问题 解决CIO/CTO最关心的云上IT治理,IT成本核算等问题。 弄清楚企业内各部门成本及云上IT成本结构。 让CIO/CTO准确地掌握云上资源成本情况,清楚业务与成本的关系。 让采购/运维轻松搞定每月的IT成本汇报。
详见:https://www.aliyun.com/product/slb EMR:阿里云 E-MapReduce(EMR)是构建在阿里云云服务器 ECS 上的开源 Hadoop、Spark、HBase、Hive、Flink 生态大数据 PaaS 产品。提供用户在云上 使用开源技术建设数据仓库、离线批处理、在线流式处理、即时查询、机器学习等 场景下的大数据解决方案。详见:...
自建Hadoop迁移MaxCompute
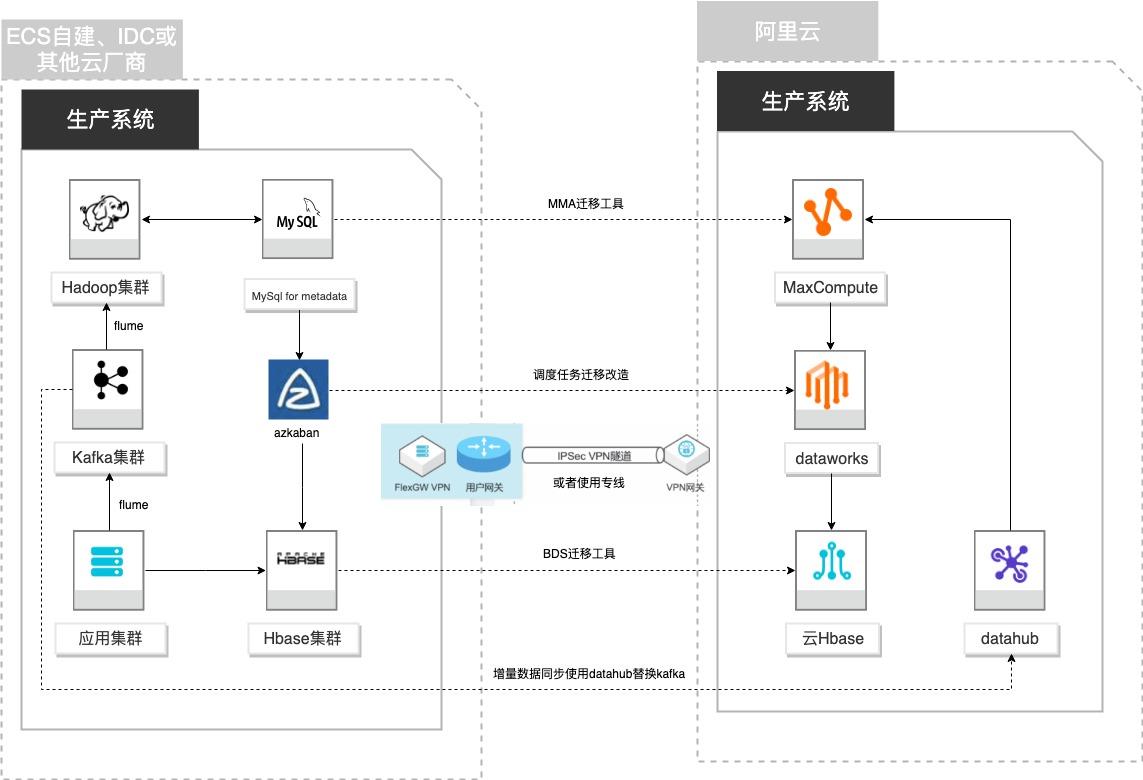
场景描述 客户基于ECS、IDC自建或在友商云平台自建了大数 据集群,为了降低企业大数据计算平台的成本,提高 大数据应用开发效率,更有效保障数据安全,把大数 据集群的数据、作业、调度任务以及业务数据库整体 迁移到MaxCompute和其他云产品。 解决的问题 自建Hadoop集群搬迁到MaxCompute 自建Hbase集群搬迁到云Hbase 自建Kafka或应用数据准实时同步到 MaxCompute 自建Azkaban任务迁移到Dataworks任务 产品列表 MaxCompute,Dataworks、云数据库Hbase版、Datahub、VPC,ECS。
VPN网关 VPN网关是一款基于 Internet的网络连接服务,通过加密通道的方式实现企业数 据中心、企业办公网络或 Internet终端与阿里云专有网络(VPC)安全可靠的连 接。VPN 网关提供 IPSec-VPN 连接和 SSL-VPN 连接。详情请查看 https://www.aliyun.com/product/vpn IPSec VPN 基于路由的 IPSec-VPN,不仅可以更方便的配置和...
湖仓一体架构EMR元数据迁移DLF
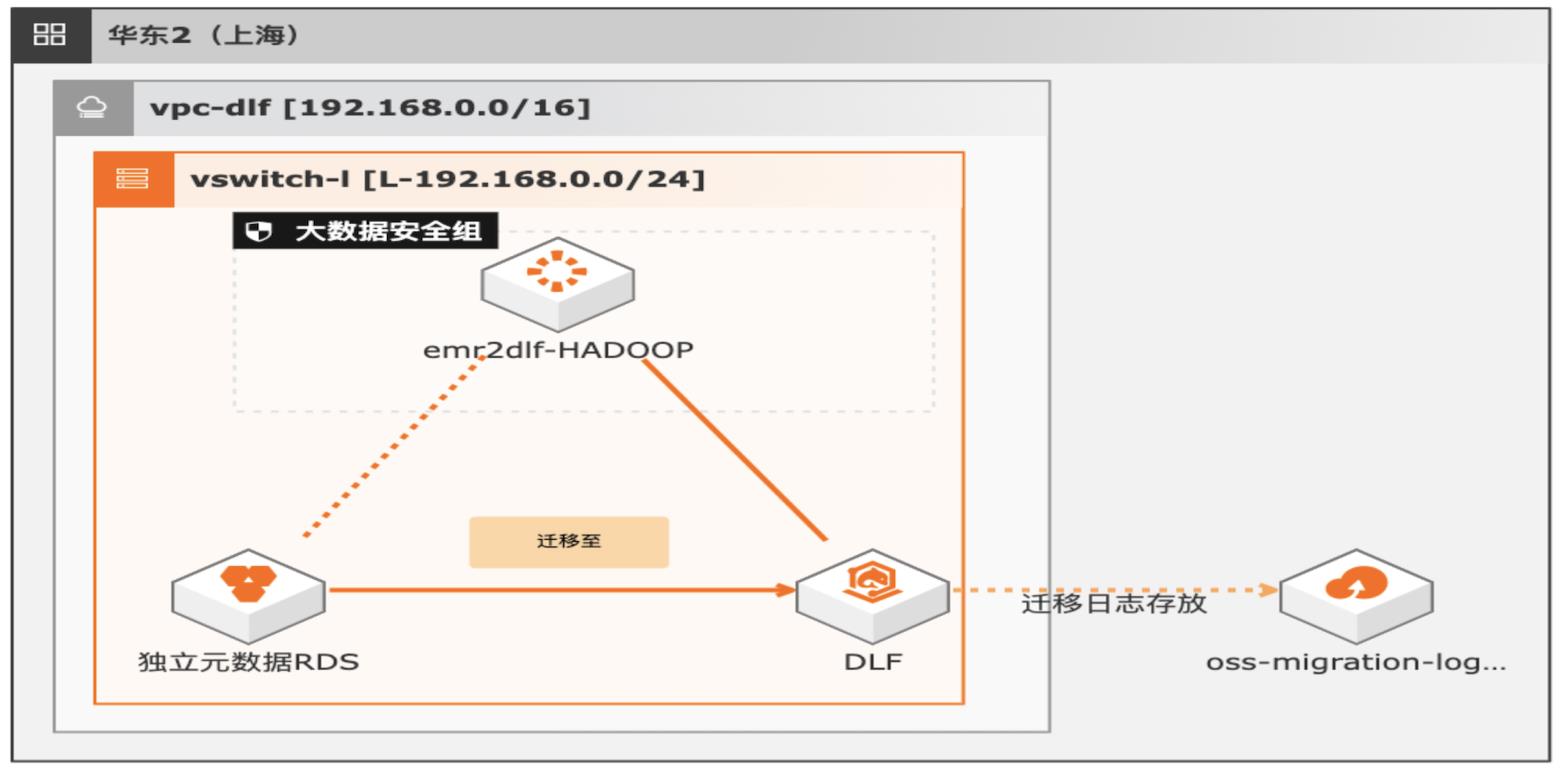
通过EMR+DLF数据湖方案,可以为企业提供数据湖内的统一的元数据管理,统一的权限管理,支持多源数据入湖以及一站式数据探索的能力。本方案支持已有EMR集群元数据库使用RDS或内置MySQL数据库迁移DLF,通过统一的元数据管理,多种数据源入湖,搭建高效的数据湖解决方案。
EMR是云原生开源大数据平台,向客户提 供简单易集成的 Hadoop、Hive、Spark、Flink、Presto、ClickHouse、Delta、Hudi 等开源大数据计算和存储引擎。EMR计算资源可以根据业务的需要调整。EMR可 以 部 署 在 阿 里 云 公 有 云 的 ECS 和 ACK、专 有 云 平 台。(https://www.aliyun.com/product/emapreduce)。数据湖构建 ...
CDH迁移升级CDP最佳实践
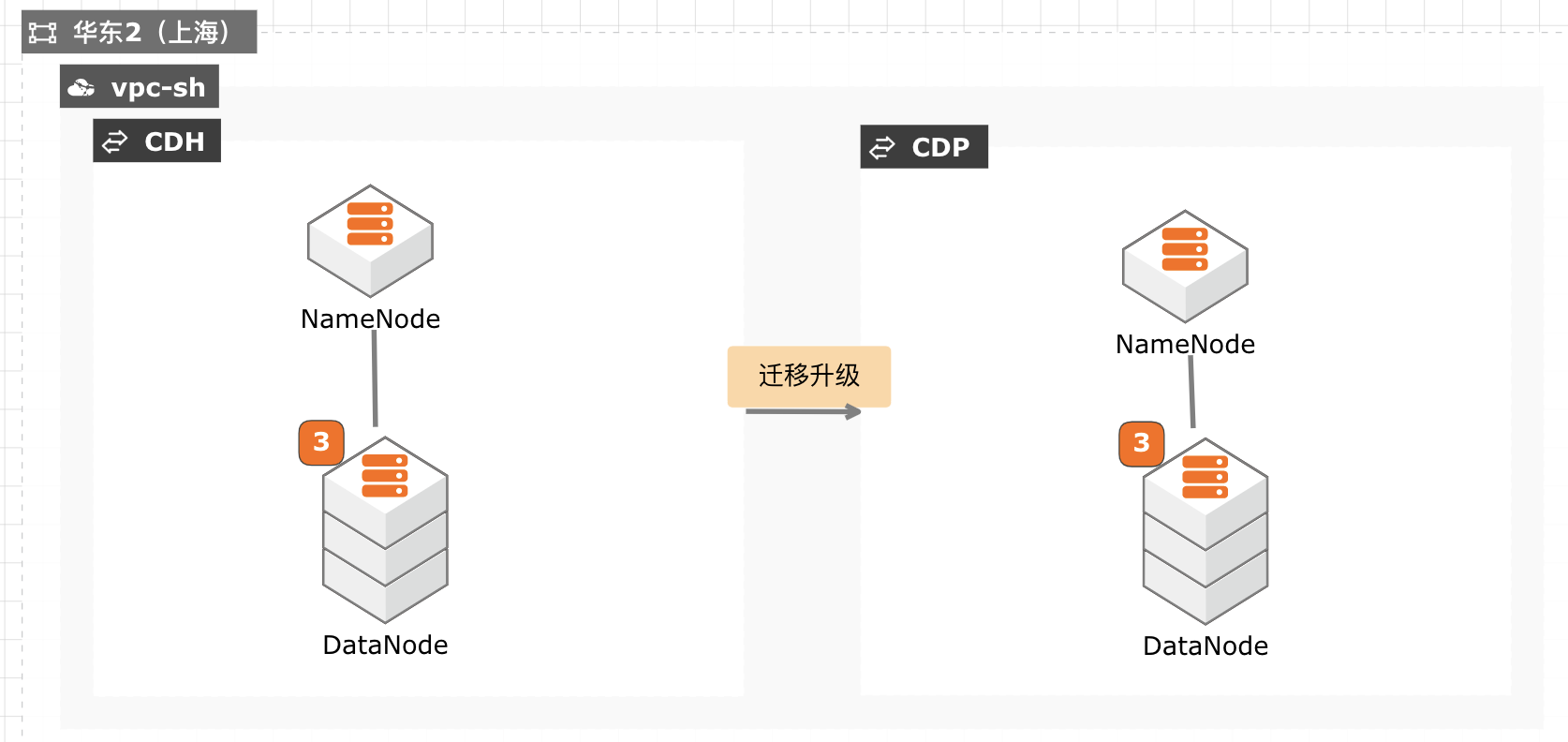
当前 CDH 免费版停止下载,终止服务,针对需要企业版服务能力并且CDH 升级过程对业务影响较小的客户,通过安装新的 CDP 集群,将现有数据拷贝至新集群,然后将新集群切换为生产集群,升级过程没有数据丢失风险,停机时间较短,适合大部分互联网客户升级使用。
Navigator 业务元数据,包括:标签,自定义属性,实体名称和描述,Navigator Managed元数据 Navigator技术元数据,包括:Hive,Impala,Spark,引用到的 HDFS/S3 不能被迁移的 Navigator数据 Navigator审计数据,原来的 Navigator实例会变成“只读”模式,以便查到历史审 计信息 实体元数据,包括:ᅳ hive/spark/impala未...
EMR HBase on OSS存算分离集群快速恢复
OSS-HDFS服务(JindoFS服务)是一款云原生数据湖存储产品。基于统一的元数据管理能力,在完全兼容HDFS文件系统接口的同时,提供充分的POSIX能力支持,能更好地满足大数据和AI等领域的数据湖计算场景。
服务特性 OSS-HDFS服务支持的特性如下:HDFS兼容访问 OSS-HDFS 服务完全兼容 HDFS 接口,同时支持目录层级的操作,您只需集成 JindoSDK,即可为 Apache Hadoop的计算分析应用(例如 MapReduce、Hive、Spark、Flink等)提供了访问 HDFS服务的能力,像使用 Hadoop分布式文件系 统(HDFS)一样管理和访问数据。POSIX能力支持 ...
云原生数据仓库AnalyticDB MySQL数据仓库
阿里云云原生数据仓库AnalyticDB MySQL版(简称AnalyticDB)是融合数据库、大数据技术于一体的云原生企业级数据仓库平台。云原生数据仓库AnalyticDB MySQL版支持数据实时写入和同步更新、实时计算和实时服务,可用于构建企业级报表系统、数据仓库和数据服务引擎。
更多应用场景请查看.AnalyticDB MySQL使用文档.快速上手AnalyticDB MySQL.查看API使用文档.AnalyticDB MySQL技术交流.流量成本的升高,用户更加成熟,迫使客户需进行更加精细化的市场营销,提供更高品质的产品...——打造一站式实时湖仓,可替换CDH/TDH/开源自建/云服务-Spark/Hive/Presto等.AnalyticDB MySQL湖仓版重磅发布.
来自:
云产品
- 产品推荐
- 这些文档可能帮助您