表格存储Tablestore
表格存储Tablestore是阿里云自研的面向海量结构化数据存储的Serverless分布式数据库,它可提供低成本、高性能的存储方案,同时也可提供稳定与极致的数据服务。
批计算支持MaxCompute以及EMR Hadoop/Spark/Hive等各类开源组件访问。实时计算支持阿里云流计算、函数计算等.接入数据集成,支持全量、增量数据通道.无缝对接数据湖OSS.支持数据实时投递数据湖OSS,按照列存方式存储。更高效支持海量数据计算.完善的大数据计算体系.支持多种大数据计算框架,打通在线存储、离线计算和实时...
来自:
云产品
云原生数据仓库AnalyticDB MySQL数据仓库
阿里云云原生数据仓库AnalyticDB MySQL版(简称AnalyticDB)是融合数据库、大数据技术于一体的云原生企业级数据仓库平台。云原生数据仓库AnalyticDB MySQL版支持数据实时写入和同步更新、实时计算和实时服务,可用于构建企业级报表系统、数据仓库和数据服务引擎。
将RDS和PolarDB的多个数据库实例一键配置DTS同步链路.数据库数据接入.配置SLS数据同步链路,将日志数据快速接入.日志数据接入.PolarDB MySQL数据免费接入、多表增量更新物化视图、UDF、Multi-cluster自动弹性等功能上新,欢迎体验!PolarDB MySQL数据免费接入、多表增量更新物化视图、UDF、Multi-cluster自动弹性等功能上新...
来自:
云产品
基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测

本篇最佳实践先创建EMR集群作为数据湖对象,Hive元数据存储在DLF,外表数据存储在OSS。然后使用阿里云数据仓库MaxCompute以创建外部项目的方式与存储在DLF的元数据库映射打通,实现元数据统一。最后通过一个毒蘑菇的训练和预测demo,演示云数仓MaxCompute如何对于存储在EMR数据湖的数据进行加工处理以达到业务预期。
可用区M 支持导入已保 有资源 IPv4网段 192.168.0.0/24 安全组:系统默认配置,自动创建 基于模版新建 名称:project-emr 可选服务:如果更换地域 付费类型:按量付费 OSS-HDFS、Hadoop-Common、或者可用区,业务场景:新版数据湖 Hive、Spark3、Tez、YARM 注意规格 元数据:DLF统一元数据 EMR 集群存储根路径:勾选:挂载...
大数据近实时数据投递MaxCompute
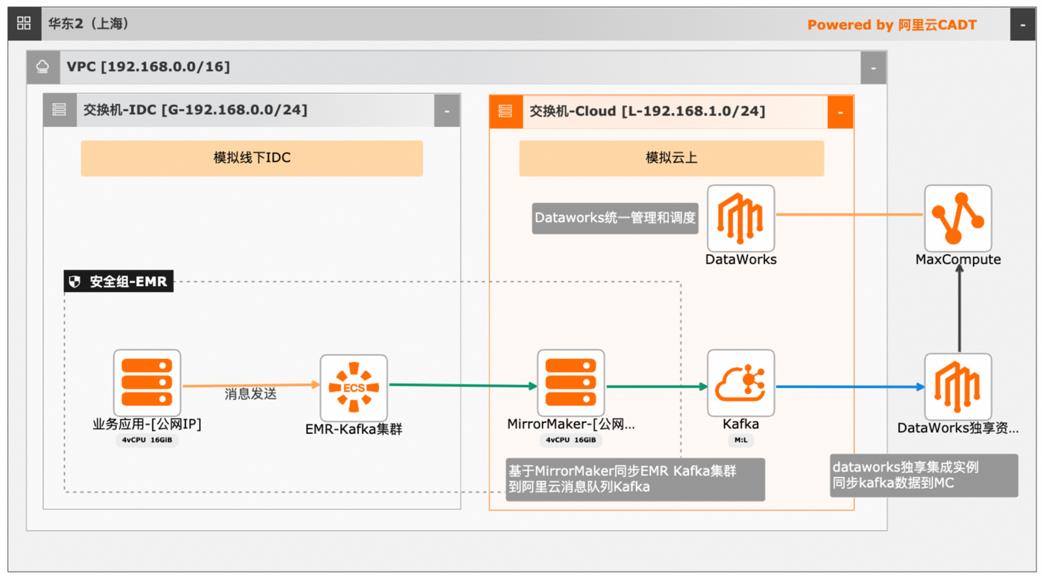
本文介绍离线大数据场景使MaxCompute构建云 上近实时数仓,打通云下数据上云链路,解决数据复杂类型支持和动态分区问题,满足高级数据处理需求的最佳实践。 l混合云环境下,现有业务系统零改造,打通数据上云链路。 l使用UDF实现复杂数据类型转换和数据动态分区。 l使用DataWorks配置周期调度业务流程,数据自动入仓。 l借助MaxCompute优化计算引擎,实现降本增效。 产品列表 云服务器ECS 专有网络VPC 访问控制RAM 数据总线DataHub E-MapReduceEMR DataWorks 大数据计算服务MaxCompute
详见:https://www.aliyun.com/product/ram 文档版本:20240419 III 大数据近实时数据投递 MaxCompute 前言 E-MapReduce EMR:是构建在阿里云云服务器 ECS 上的开源 Hadoop、Spark、HBase、Hive、Flink 生态大数据 PaaS 产品。提供用户在云上使用开 源技术建设数据仓库、离线批处理、在线流式处理、即时查询、机器学习等场 ...
中小企业自建Hadoop集群上云解决方案
中小企业自建 Hadoop 集群上云解决方案,助力自建 Hadoop 用户快速构建云上半托管开源大数据平台,在保持原组件使用习惯延续的同时,充分利用云上服务特点,更加便捷地迭代企业大数据平台架构,聚焦业务价值开发。
提供高性能、稳定版本 Hadoop、Spark、Hive、Flink、Kafka、Hbase、Presto、Impala、Hudi、ClickHouse 等开源大数据组件,可根据场景灵活搭配使用。采用 JindoFS+OSS,在保证数据可靠性的基础上,性能大幅提升.便捷运维,成本节约.分钟级创建集群,支持对集群、节点和服务进行监控和运维操作,大幅提升运维工作效率,让数据...
来自:
解决方案
E-MapReduce Serverless Spark 版
E-MapReduce Serverless Spark 是阿里云 E-MapReduce 基于 Spark 提供的一款全托管、一站式的数据计算平台。它为用户提供任务开发、调试、发布、调度和运维等全方位的产品化服务,显著简化了大数据计算的工作流程,使用户能更专注于数据分析和价值提炼。
开源大数据平台 E-MapReduce E-MapReduce Serverless Spark 版 E-MapReduce(以下简称:"EMR")Serverless Spark 版是开源大数据平台 E-MapReduce 基于 Spark 提供的一款全托管、一站式的数据计算平台。它为用户提供任务开发、调试、发布、调度和运维等全方位的产品化服务,显著简化了大数据计算的工作流程,使用户能更...
来自:
云产品
- 产品推荐
- 这些文档可能帮助您