自建Hadoop迁移到阿里云EMR
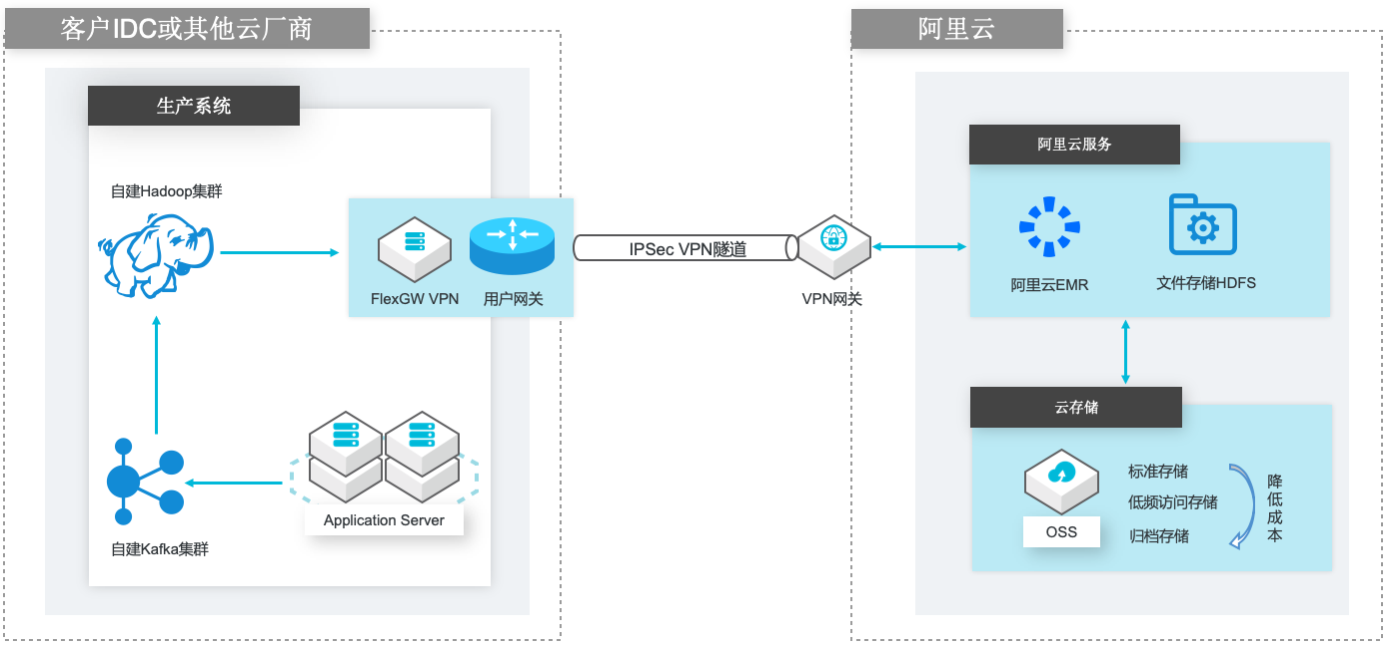
场景描述 场景1:自建Hadoop集群数据(HDFS)迁移到 阿里云EMR集群的HDFS文件系统; 场景2:自建Hadoop集群数据(HDFS)迁移到 计算存储分离架构的阿里云EMR集群,以OSS 和JindoFS作为EMR集群的后端存储。 解决的问题 客户自建Hadoop迁移到阿里云EMR集群的 技术方案; 基于IPSecVPN隧道构建安全和低成本数据 传输链路 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
名词解释 E-MapReduce 阿里云 E-MapReduce(EMR)是构建在阿里云云服务器 ECS 上的开源 Hadoop、Spark、HBase、Hive、Flink生态大数据 PaaS 产品。提供用户在云 上使用开源技术建设数据仓库、离线批处理、在线流式处理、即时查询、机器学 习等场景下的大数据解决方案。详情请查看 ...
自建Hadoop迁移MaxCompute
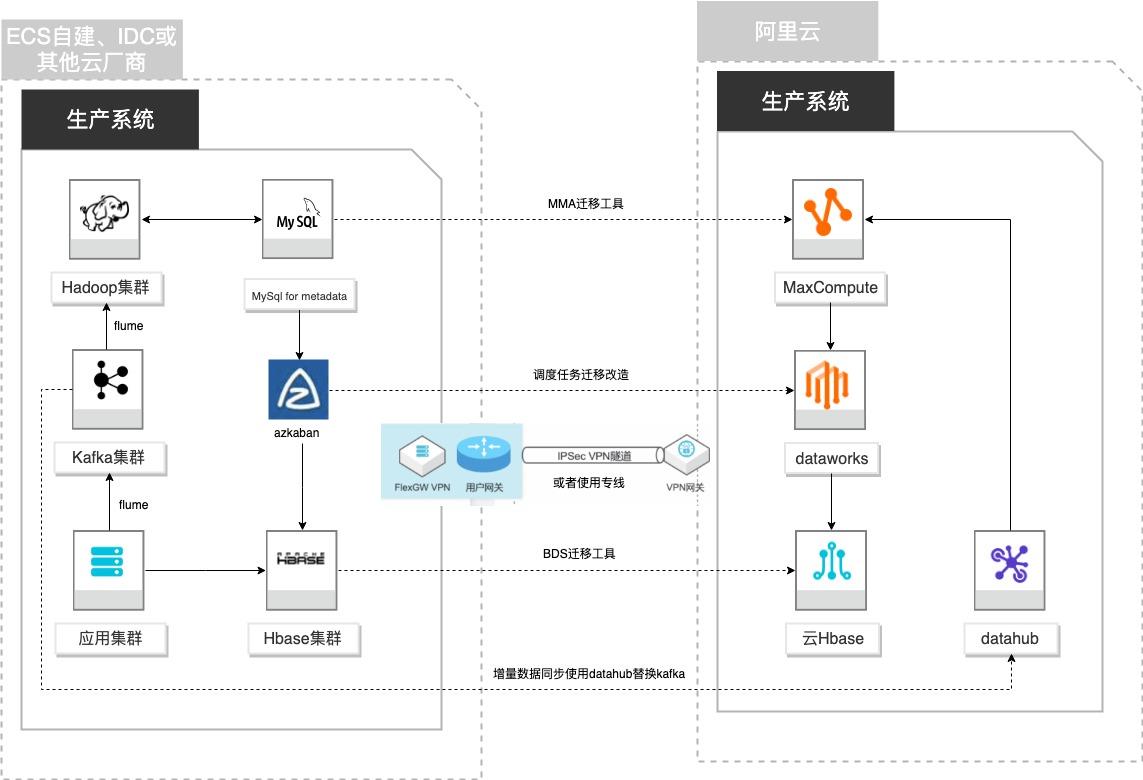
场景描述 客户基于ECS、IDC自建或在友商云平台自建了大数 据集群,为了降低企业大数据计算平台的成本,提高 大数据应用开发效率,更有效保障数据安全,把大数 据集群的数据、作业、调度任务以及业务数据库整体 迁移到MaxCompute和其他云产品。 解决的问题 自建Hadoop集群搬迁到MaxCompute 自建Hbase集群搬迁到云Hbase 自建Kafka或应用数据准实时同步到 MaxCompute 自建Azkaban任务迁移到Dataworks任务 产品列表 MaxCompute,Dataworks、云数据库Hbase版、Datahub、VPC,ECS。
Kafka 的目的是通过 文档版本:20210723 III 自建Hadoop迁移MaxCompute 前言 Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提 供实时的消息。Flume Flume是一种分布式,可靠且可用的服务,用于有效地收集,聚合和移动大量日 志数据。它具有基于流数据流的简单灵活的体系结构。它具有可调整的可靠性...
EMR集群安全认证和授权管理
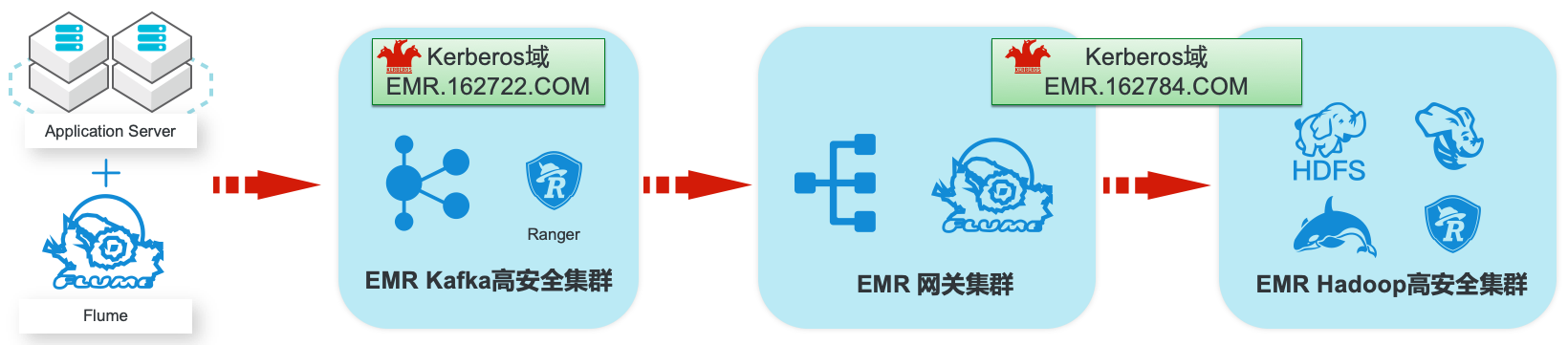
场景描述 阿里云EMR服务Kafka和Hadoop安全集群使 用Kerberos进行用户安全认证,通过Apache Ranger服务进行访问授权管理。本最佳实践中以 Apache Web服务器日志为例,演示基于Kafka 和Hadoop的生态组件构建日志大数据仓库,并 介绍在整个数据流程中,如何通过Kerberos和 Ranger进行认证和授权的相关配置。 解决问题 1.创建基于Kerberos的EMR Kafka和 Hadoop集群。 2.EMR服务的Kafka和Hadoop集群中 Kerberos相关配置和使用方法。 3.Ranger中添加Kafka、HDFS、Hive和 Hbase服务和访问策略。 4.Flume中和Kafka、HDFS相关的安全配 置。 产品列表:E-MapReduce、专有网络VPC、云服务器ECS、云数据库RDS版
EMR集群安全认证和授权管理 最佳实践 业务架构 场景描述 解决问题 阿里云 EMR服务 Kafka和 Hadoop安全集群使用 1.创建基于 Kerberos的 EMR Kafka和 Kerberos进行用户安全认证,通过 Apache Ranger Hadoop集群。服务进行访问授权管理。本最佳实践中以 Apache 2.EMR服务的 Kafka和 Hadoop集群中 Web服务器日志为例,演示基于 ...
基于DataWorks的大数据一站式开发及数据治理

概述 基于Dataworks做大数据一站式开发,包含数据实时采集到kafka通过实时计算对数据进行ETL写入HDFS,使用Hive进行数据分析。通过Dataworks进行数据治理,数据地图查看数据信息和血缘关系,数据质量监控异常和报警。 适用场景 日志采集、处理及分析 日志使用Flink实时写入HDFS 日志数据实时ETL 日志HIVE分析 基于dataworks一站式开发 数据治理 方案优势 大数据一站式开发,完善的数据治理能力。 性能优越:高吞吐,高扩展性。 安全稳定:Exactly-Once,故障自动恢复,资源隔离。 简单易用:SQL语言,在线开发,全面支持UDX。 功能强大:支持SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据源计算等Data Lake相关功能 ,以及各种流式及静态数据源关联查询。
详情请查看 www.aliyun.com/product/bigdata/product/sc EMR:阿里云 E-MapReduce(EMR)是构建在阿里云云服务器 ECS 上的开源 Hadoop、Spark、HBase、Hive、Flink 生态大数据 PaaS 产品。提供用户在云上 使用开源技术建设数据仓库、离线批处理、在线流式处理、即时查询、机器学习等 场景下的大数据解决方案。详情请查看 ...
大数据系统基准性能测试最佳实践
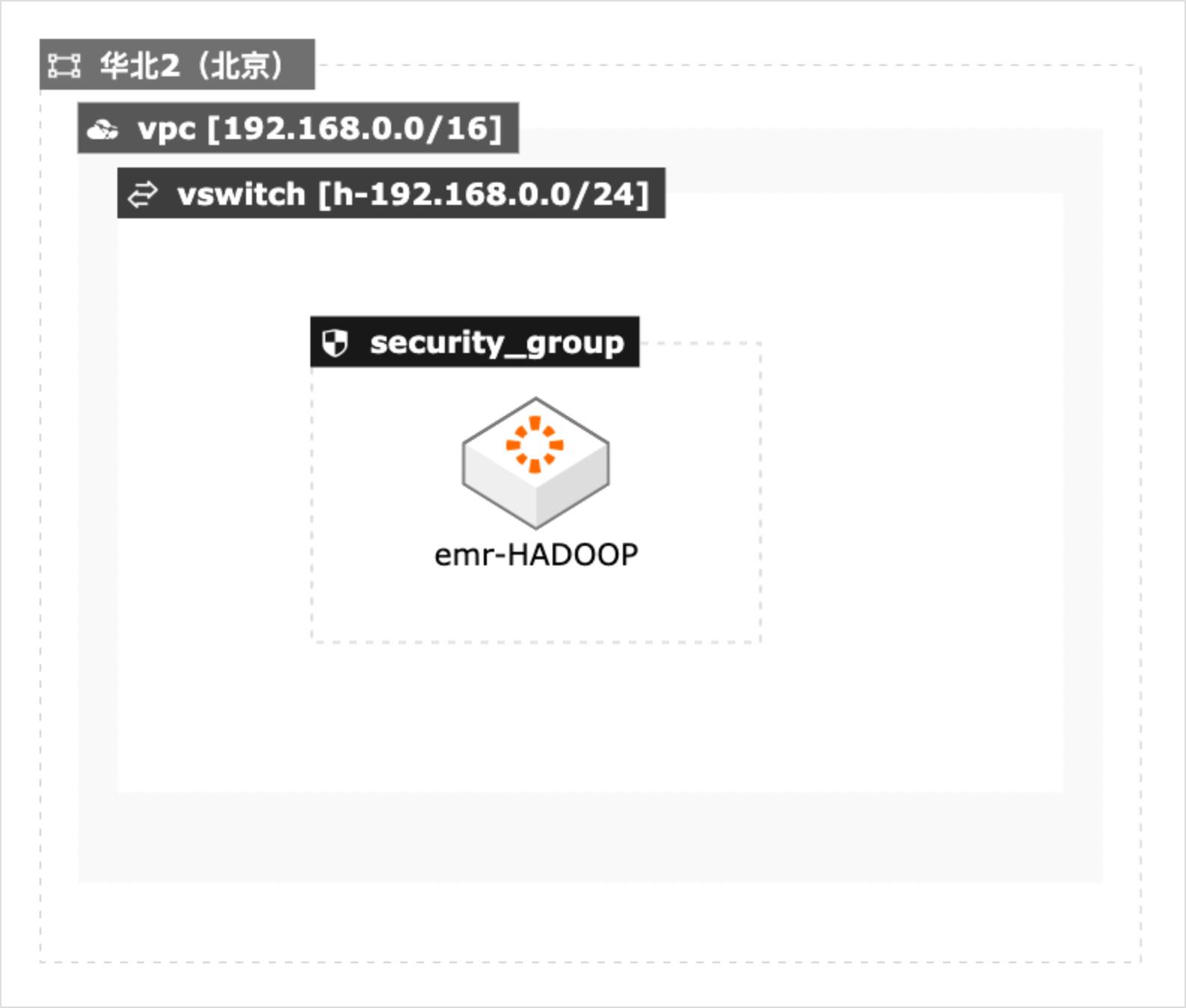
本方案适用于在阿里云上进行大数据基准性能测试的场景,包括 Teragen和Terasort测试,TestDFSIO测试。本文采用CADT工具结合阿里云的E-MapReduce服务快速构建测试集群,并提供了Teragen和Terasort测试,TestDFSIO测试的测试脚本,便于迅速开展测试。
✓ 完善集群的监控和告警体系,覆盖硬件和 Hadoop服务。弹性 ✓ 计算存储分离:解耦了计算与存储之间的绑定关系,实现了资源的弹性利用。✓ 自定义集群环境:您可以通过引导操作和集群脚本灵活配置集群环境,将第三方优化和集 群管理工具部署到 EMR环境。✓ 自主运维:您可以登录 Master节点,查看集群日志和部署环境,优化...
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
与社区版 Spark和 Delta Lake相比,在功能和性能 上都有明显的优势。经济 文档版本:20210425 V 自建 Hive数据仓库跨版本迁移到阿里云 Databricks数据洞察 最佳实践概述 您可以按需创建 Databricks数据洞察集群,即离线作业运行结束就可以释放集群,同时支持按负载和时间的弹性伸缩。协同分析 Databricks数据洞察 Notebook...
SLS多云日志采集、处理及分析
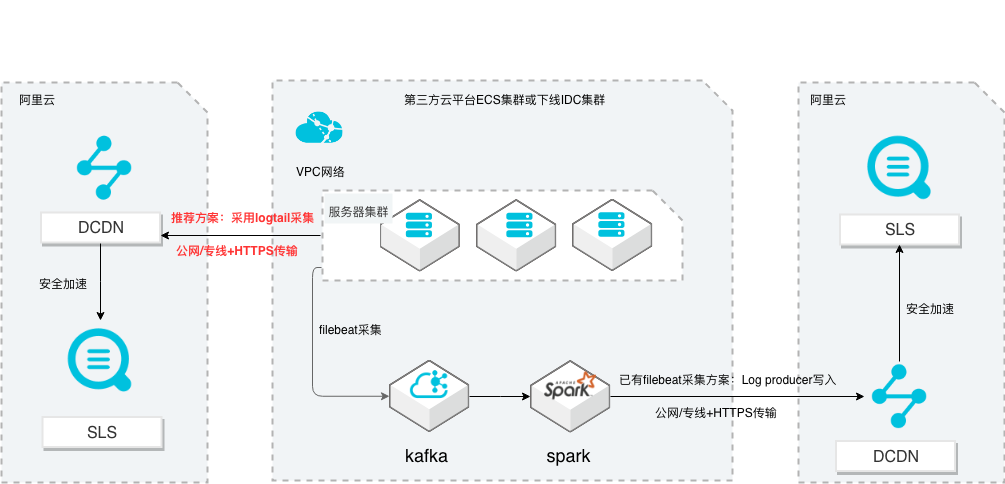
场景描述 从第三方云平台或线下IDC服务器上采集 日志写入到阿里云日志服务,通过日志服务 进行数据分析,帮助提升运维、运营效率, 建立DT 时代海量日志处理能力。 针对未使用其他日志采集服务的用户,推荐 在他云或线下服务器安装logtail采集并使用 Https安全传输;针对已使用其他日志采集 工具并且已有日志服务需要继续服务的情 况,可以通过Log producer SDK写入日志 服务。 解决问题 1.第三方云平台或线下IDC客户需要使用 阿里云日志服务生态的用户。 2.第三方云平台或线下IDC服务器已有完 整日志采集、处理及分析的用户。 产品列表 E-MapReduce 专有网络VPC 云服务器ECS 日志服务LOG DCDN
E-MapReduce:阿里云 E-MapReduce(EMR)是构建在阿里云云服务器 ECS 上 的开源 Hadoop、Spark、Hive、Flink 生态大数据 PaaS 产品。提供用户在云上 使用开源技术建设数据仓库、离线批处理、在线流式处理、即时查询、机器学习 等场景下的大数据解决方案。更多信息,请参见专有 E-MapReduce简介...
自建Hive数仓迁移到阿里云EMR
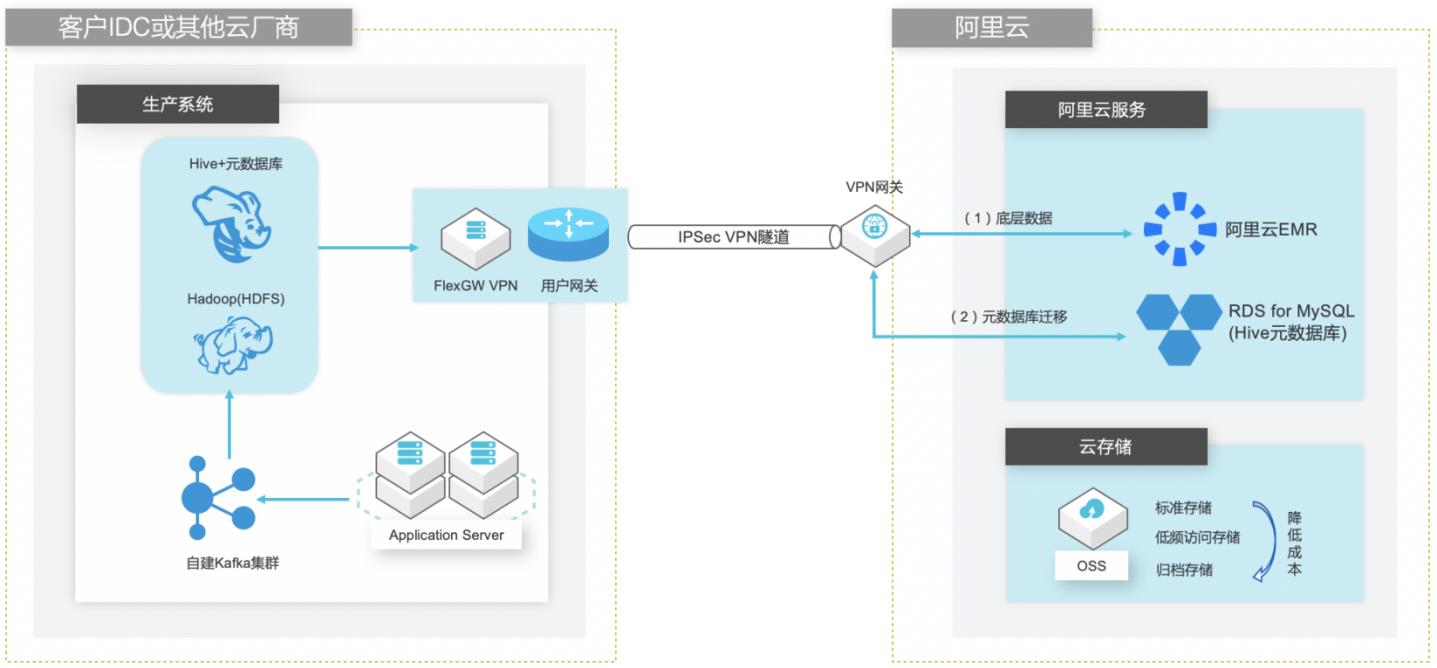
场景描述 客户在IDC或者公有云环境自建Hadoop集群构 建数据仓库和分析系统,购买阿里云EMR集群之 后,涉及到将数据仓库和Hive元数据的数据库迁 移上云。目前主流Hive数据仓库迁移场景为1.x 版本迁移到阿里云EMR(Hive2.x版本),涉及到 数据订正更新步骤。 解决的问题 Hive数据仓库的数据迁移方案 Hive元数据库的迁移方案 Hive跨版本迁移后的数据订正 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
深度整合 E-MapReduce 与阿里云其它产品(例如,OSS、MNS、RDS 和 MaxCompute 等)进行了深度整合,支持以这些产品作为 Hadoop/Spark计算引擎的输入源或者 文档版本:20210721 1 自建Hive数据仓库跨版本迁移到阿里云 EMR 最佳实践概述 输出目的地。安全 E-MapReduce整合了阿里云 RAM资源权限管理系统,通过主子账号对服务...
云消息队列 Kafka 版
云消息队列 Kafka 版是阿里云基于Apache Kafka构建的大数据消息中间件,广泛用于日志收集和分析、数据处理等场景。可提供全托管服务,用户无需部署运维,更专业、更可靠、更安全。
Kafka 性能高效,采集日志时业务无感知以及Hadoop/ODPS 等离线仓库存储和 Storm/Spark 等实时在线分析对接的特性决定它非常适合作为\\.构建应用系统和分析系统的桥梁,并将它们之间的关联解耦;应用与分析解耦.支持实时在线分析系统和类似于Hadoop之类的离线分析系统;在线/离线分析系统.云消息队列 MQ.应用实时监控服务 ...
来自:
云产品
大数据workshop

大数据workshop
技术选型 阿里云框架 开源框架 ➢ 数据采集传输 DataHub、DTS Flume、Kafka、Canal、MaxWell ➢ 数据存储 RDS、MaxCompute MySQL、Hadoop、HBase ➢ 数据计算 实时计算 Flink版 Spark、Flink ➢ 数据可视化 DataV、QuickBI Tableau、Echarts、Kibana 2.2.4.系统架构设计 下图为所设计的系统架构设计,主要包括数据源(两类...
来自:
最佳实践
相关产品:块存储,云服务器ECS,云数据库RDS MySQL 版,对象存储 OSS,弹性公网IP,数据传输,DataWorks,大数据计算服务 MaxCompute,DataV数据可视化,实时计算,数据总线,Quick BI,Hologres
多账号下企业分账
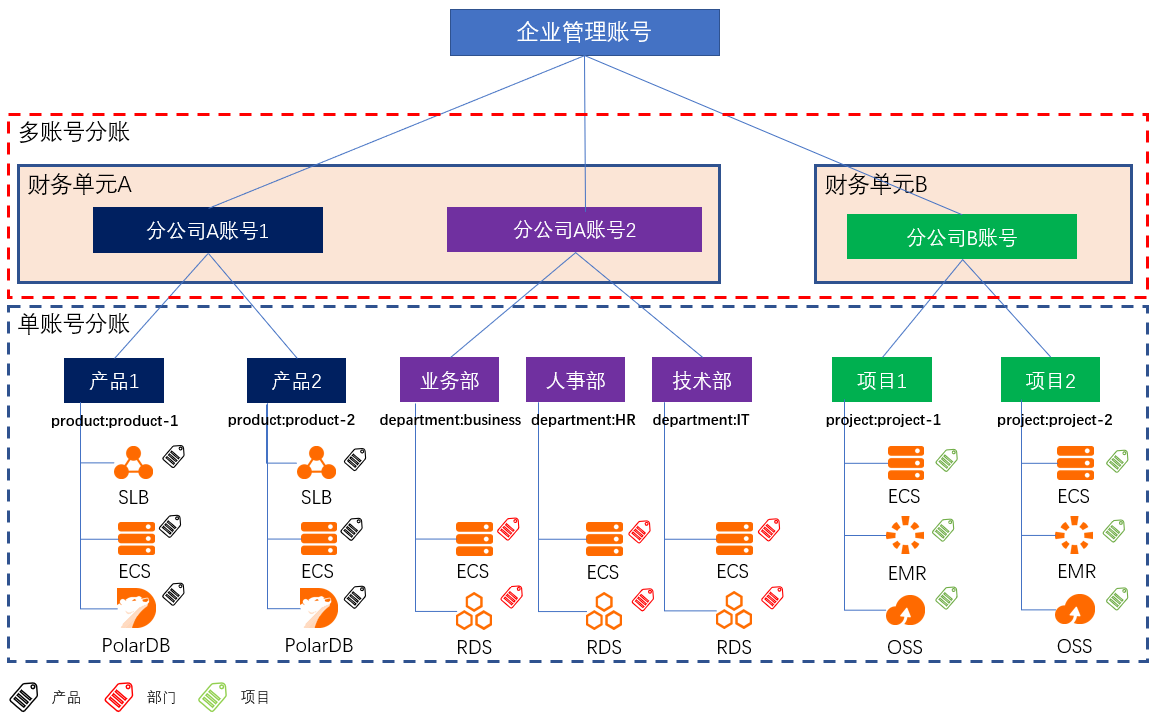
场景描述 财务分账,是根据企业的成本中心,将云上资源的成本划分到给各个项目组/业务部门;助力企业快速梳理云上成本结构,搭建复杂组织架构下的成本关系,便捷地进行财务和云上成本的管理。 大型企业或集团公司,由于组织架构复杂,业务复杂等原因,通常拥有多个阿里云账号来管理规模庞大的云上资源。针对云上资源,如何建立有效的分账方案,是财务关注的重要问题。 解决问题 解决CIO/CTO最关心的云上IT治理,IT成本核算等问题。 弄清楚企业内各部门成本及云上IT成本结构。 让CIO/CTO准确地掌握云上资源成本情况,清楚业务与成本的关系。 让采购/运维轻松搞定每月的IT成本汇报。
详 见:https://www.aliyun.com/product/oss 云原生关系型数据库 PolarDB:PolarDB是阿里巴巴自主研发的下一代云原生关 系型数据库,目前兼容三种数据库引擎:MySQL、PostgreSQL、高度兼容 Oracle 语法。计算能力最高可扩展至 1000核以上,存储容量最高可达 100T。详见:https://www.aliyun.com/product/polardb 阿里云关系...
金融专属大数据workshop

实践目标 学习搭建一个实时数据仓库,掌握数据采集、存储、计算、输出、展示等整个业务流程。 整个实时数据仓库系统全部基于阿里云产品进行架构搭建,用户可以掌握并学会运用各个服务组件及各个组件之间如何联动。 理解阿里云原生实时离线一体数仓解决方案架构以及掌握交付落地的实践使用方法。 前置知识要求 熟练掌握SQL语法 对大数据体系系统知识有一定的了解
技术选型 阿里云框架 开源框架 数据采集传输 DataHub、DTS Flume、Kafka、Canal、MaxWell 数据存储 RDS、MaxCompute MySQL、Hadoop、HBase 数据计算 实时计算Flink版 Spark、Flink 数据可视化 DataV、QuickBI Tableau、Echarts、Kibana 2.2.4.系统架构设计 下图为所设计的系统架构设计,主要包括数据源(两类...
来自:
最佳实践
相关产品:块存储,云服务器ECS,云数据库RDS MySQL 版,对象存储 OSS,弹性公网IP,数据传输,DataWorks,大数据计算服务 MaxCompute,DataV数据可视化,实时计算,数据总线,Quick BI,Hologres
E-MapReduce Serverless Spark 版
E-MapReduce Serverless Spark 是阿里云 E-MapReduce 基于 Spark 提供的一款全托管、一站式的数据计算平台。它为用户提供任务开发、调试、发布、调度和运维等全方位的产品化服务,显著简化了大数据计算的工作流程,使用户能更专注于数据分析和价值提炼。
EMR Serverless Spark 还内嵌了先进的版本管理系统,并提供了开发与生产环境的完全隔离,确保符合企业级用户在研发和发布流程方面的严格要求。这些特性共同保障了数据处理的可靠性和效率,同时满足企业级应用的高标准要求.全托管免运维.弹性扩展能力.开放数据湖架构.一站式的数据开发平台.开源大数据平台 EMR.数据湖构建 ...
来自:
云产品
中小企业自建Hadoop集群上云解决方案
中小企业自建 Hadoop 集群上云解决方案,助力自建 Hadoop 用户快速构建云上半托管开源大数据平台,在保持原组件使用习惯延续的同时,充分利用云上服务特点,更加便捷地迭代企业大数据平台架构,聚焦业务价值开发。
提供高性能、稳定版本 Hadoop、Spark、Hive、Flink、Kafka、Hbase、Presto、Impala、Hudi、ClickHouse 等开源大数据组件,可根据场景灵活搭配使用。采用 JindoFS+OSS,在保证数据可靠性的基础上,性能大幅提升.开源生态,性能优化.分钟级创建集群,支持对集群、节点和服务进行监控和运维操作,大幅提升运维工作效率,让数据...
来自:
解决方案
Spark on ECI大数据分析

场景描述 方案优势 1.计算引擎弹性扩缩容,兼顾资源弹性与计 算资源成本优化。 2.计算与存储分离架构,结合阿里云原生云 存储产品,海量数据湖优势。 3.Kubernetes原生的调度性能优势,提升在 大规模分析作业时的分析性能优势分。 4.集群资源隔离和按需分配。 解决问题 1.计算资源弹性能力不足,计算资源成本管 控能力欠缺. 2.集群资源调度能力和隔离能力不足。 3.计算与存储无法分离,大数据量分析时出 现数据存储资源瓶颈。 4.Spark submit方式提交分析作业参数支持 有限等缺点。 产品列表 容器服务Kubernetes版(ACK) 弹性容器实例(ECI) 文件存储HDFS 对象存储OSS 专有网络VPC 容器镜像服务ACR
2.关于 Hadoop的核心配置文件的说明介绍如下图所示:文档版本:20200409 5 Spark on ECI大数据分析 环境准备 3.修改 core-site.xml文件,路径位于 Hadoop目录下的/etc/hadoop/目录下。步骤5 配置环境变量。1.修改/etc/profile文件并保存。2.在配置最后加入相应路径信息。3.执行 source/etc/profile命令以便环境变量配置生效...
- 产品推荐
- 这些文档可能帮助您