Spark on ECI大数据分析

场景描述 方案优势 1.计算引擎弹性扩缩容,兼顾资源弹性与计 算资源成本优化。 2.计算与存储分离架构,结合阿里云原生云 存储产品,海量数据湖优势。 3.Kubernetes原生的调度性能优势,提升在 大规模分析作业时的分析性能优势分。 4.集群资源隔离和按需分配。 解决问题 1.计算资源弹性能力不足,计算资源成本管 控能力欠缺. 2.集群资源调度能力和隔离能力不足。 3.计算与存储无法分离,大数据量分析时出 现数据存储资源瓶颈。 4.Spark submit方式提交分析作业参数支持 有限等缺点。 产品列表 容器服务Kubernetes版(ACK) 弹性容器实例(ECI) 文件存储HDFS 对象存储OSS 专有网络VPC 容器镜像服务ACR
遇到的痛点:计算资源弹性能力不足,计算资源成本管控能力欠缺 集群资源调度能力和隔离能力不足 计算与存储无法分离,大数据量分析时出现数据存储资源瓶颈 Spark submit方式提交分析作业参数支持有限等缺点 方案架构和优势 方案架构 文档版本:20200409 V Spark on ECI大数据分析 最佳实践概述 方案优势ˉ计算引擎弹性扩...
云数据库 SelectDB 版
阿里云数据库 SelectDB 是现代化实时数据仓库 SelectDB 在阿里云上的全托管服务,内核基于业界领先的开源分析型数据库 Apache Doris 研发,由阿里云和飞轮科技联合打造。阿里云数据库 SelectDB 聚焦于满足企业级大数据分析需求,广泛应用于实时报表分析、即席多维分析、日志检索分析、数据联邦与查询加速等场景,致力于为客户提供极致性能、简单易用的数据分析服务。
告警方式:用户可以设置阈值告警规则,随时随地接收告警电话、短信或邮件,及时掌握数仓运行的异常状态,快速响应处理解决,避免或减少负面影响。常见问题产品选型计费应用场景Q:相比 Apache Doris 的单集群,SelectDB 的多计算集群有什么优势?A:一个 SelectDB 实例可包含多个计算集群,每个集群包含一组 BE 节点,类似...
来自:
云产品
MRACC加速倚天ECS实例Flink集群性能
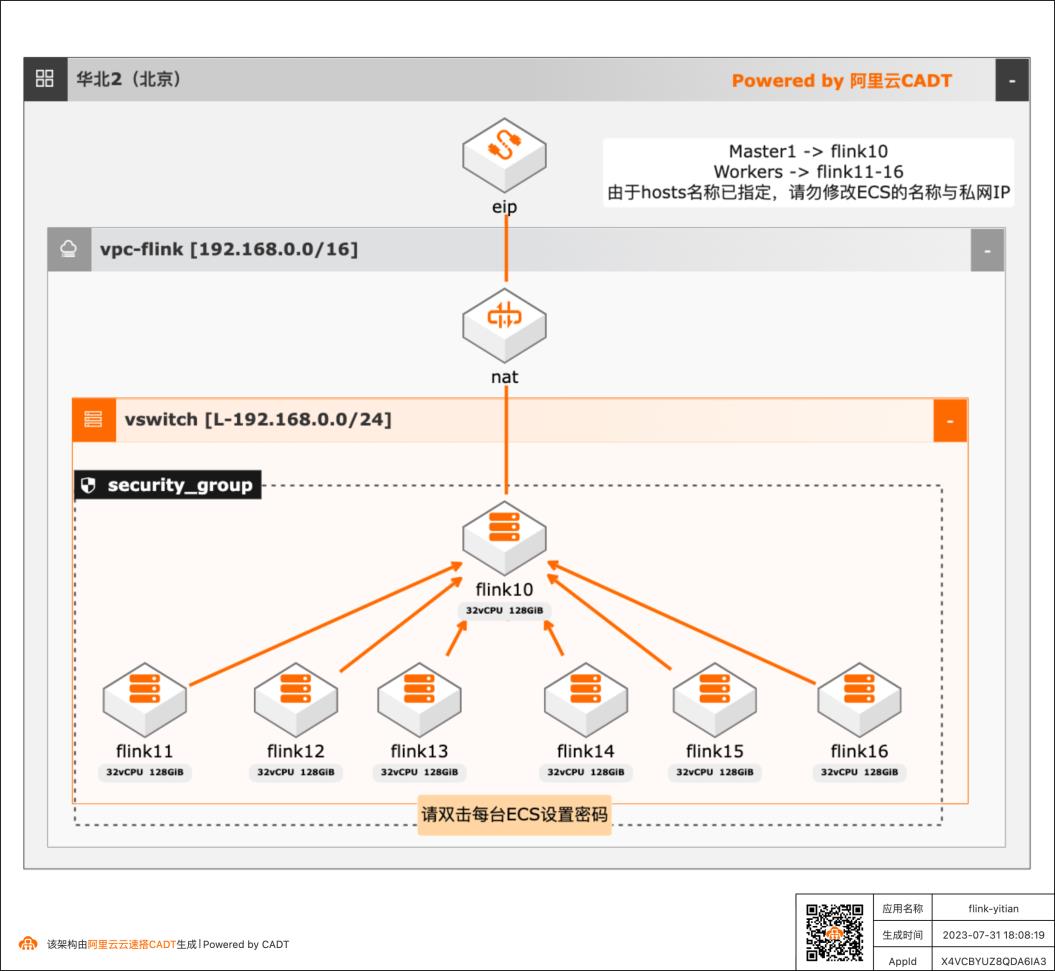
希望了解Flink集群on倚天的部署架构。 通过神龙大数据加速引擎 Mracc 提升Flink集群性能。 希望实测了解倚天ECS实例运行Flink集群的性能 架构设计:利用阿里云官方架构设计模版,在此基础上二次定制(调整规格、资源数量、配置调整)。 快速完成PoC和生产环境的设计和部署
tail-f/opt/fastmr/nexmark/nexmark.out 文档版本:20230801 18 MRACC加速倚天 ECS实例 Spark集群性能 部署基础环境 步骤3 通过日志文件查看压测数据生成进度 测试一共会跑 22个查询,大概需要 50分钟左右,若日志显示了 q22的Nexmark结 果,则表示测试已完成,可以查看每个核心的查询吞吐量,单位为 K QPS/Cores。...
CDH迁移升级CDP最佳实践
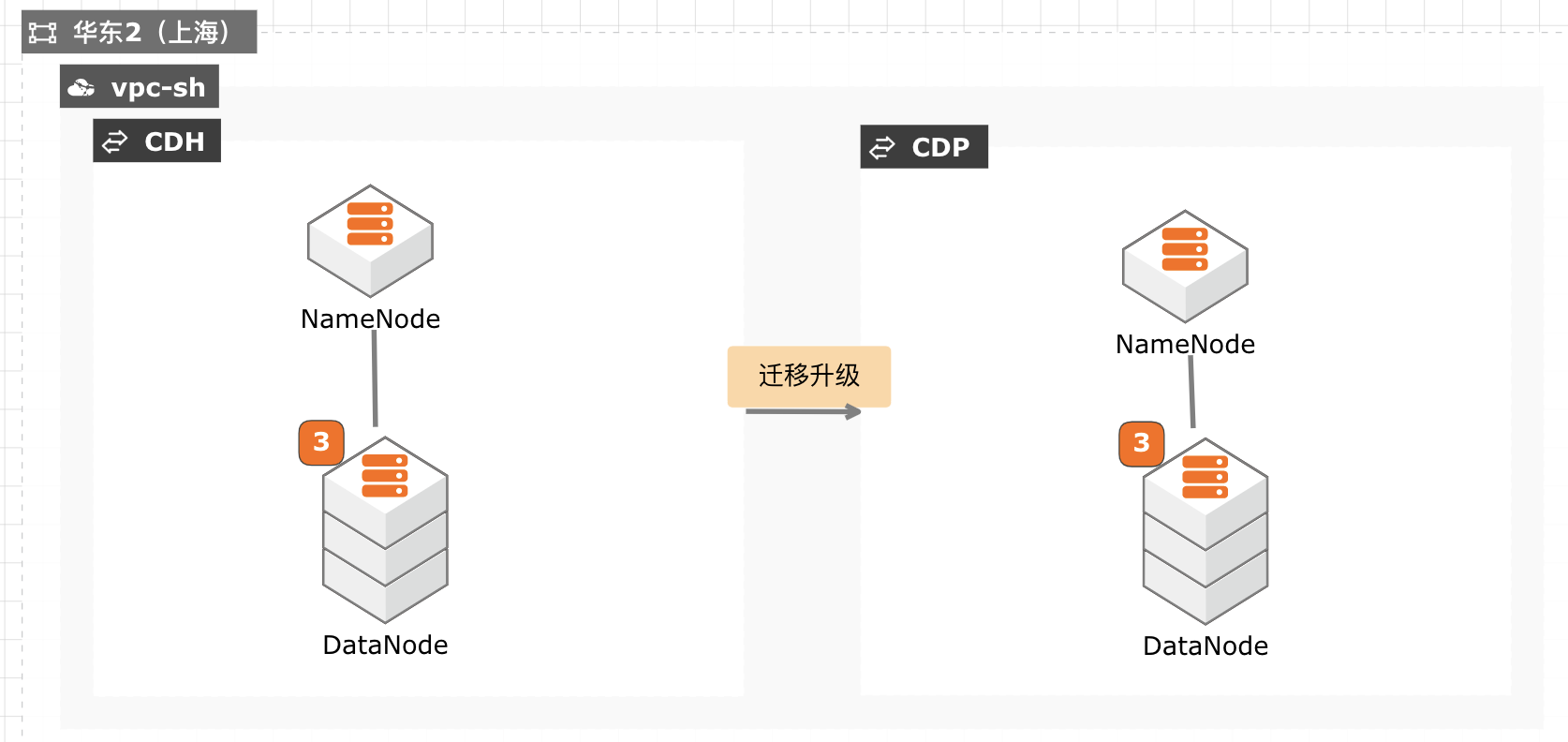
当前 CDH 免费版停止下载,终止服务,针对需要企业版服务能力并且CDH 升级过程对业务影响较小的客户,通过安装新的 CDP 集群,将现有数据拷贝至新集群,然后将新集群切换为生产集群,升级过程没有数据丢失风险,停机时间较短,适合大部分互联网客户升级使用。
放置规则 公平调度程序放置规 描述 转换详情 则 create="false"或 禁用或启用在 YARN 中动态创建 权重模式:完全支持此标志,除了嵌 者"true"队列。无法在以下放置规则策略中 套规则,您只能在其中定义单个“创 指定此选项:建”标志。因此,不能设置“真/假”和“假/真”。reject 相对模式:部分支持。必须选择受管 ...
自建Hive数仓迁移到阿里云EMR
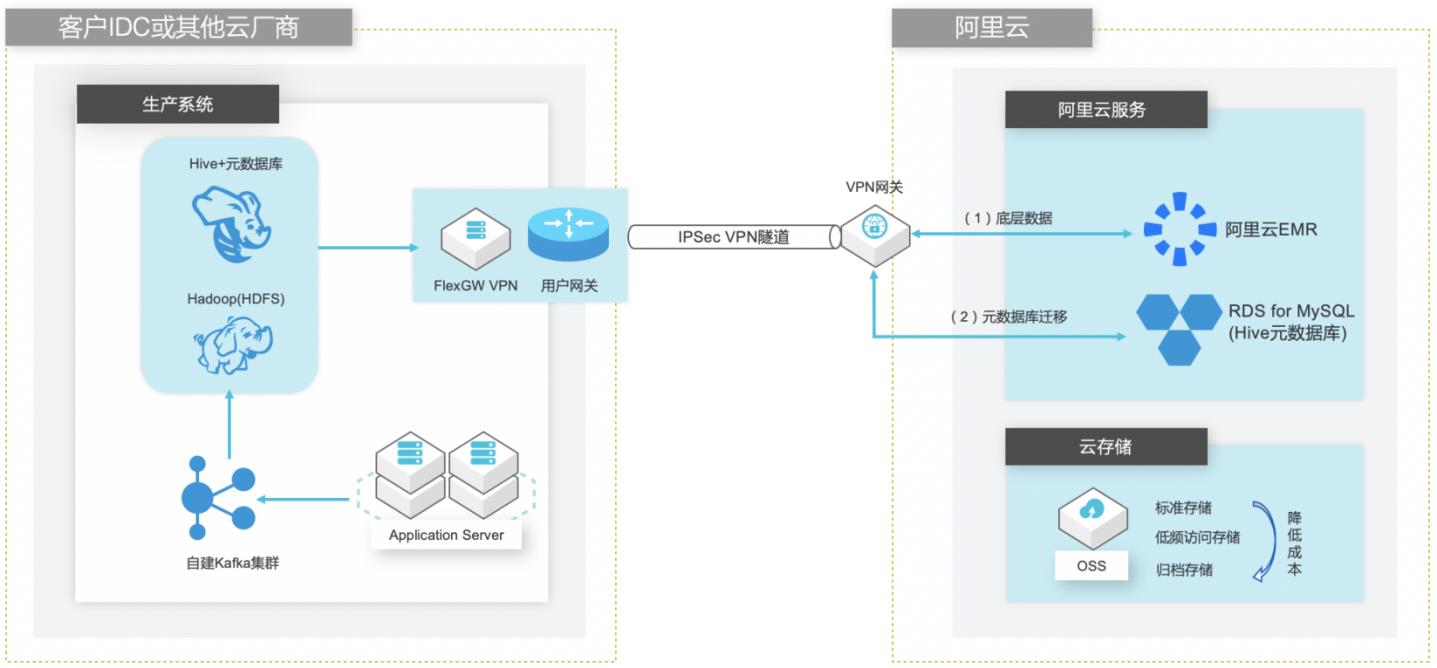
场景描述 客户在IDC或者公有云环境自建Hadoop集群构 建数据仓库和分析系统,购买阿里云EMR集群之 后,涉及到将数据仓库和Hive元数据的数据库迁 移上云。目前主流Hive数据仓库迁移场景为1.x 版本迁移到阿里云EMR(Hive2.x版本),涉及到 数据订正更新步骤。 解决的问题 Hive数据仓库的数据迁移方案 Hive元数据库的迁移方案 Hive跨版本迁移后的数据订正 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
深度整合 E-MapReduce 与阿里云其它产品(例如,OSS、MNS、RDS 和 MaxCompute 等)进行了深度整合,支持以这些产品作为 Hadoop/Spark计算引擎的输入源或者 文档版本:20210721 1 自建Hive数据仓库跨版本迁移到阿里云 EMR 最佳实践概述 输出目的地。安全 E-MapReduce整合了阿里云 RAM资源权限管理系统,通过主子账号对服务...
基于弹性供应组构建大数据分析集群
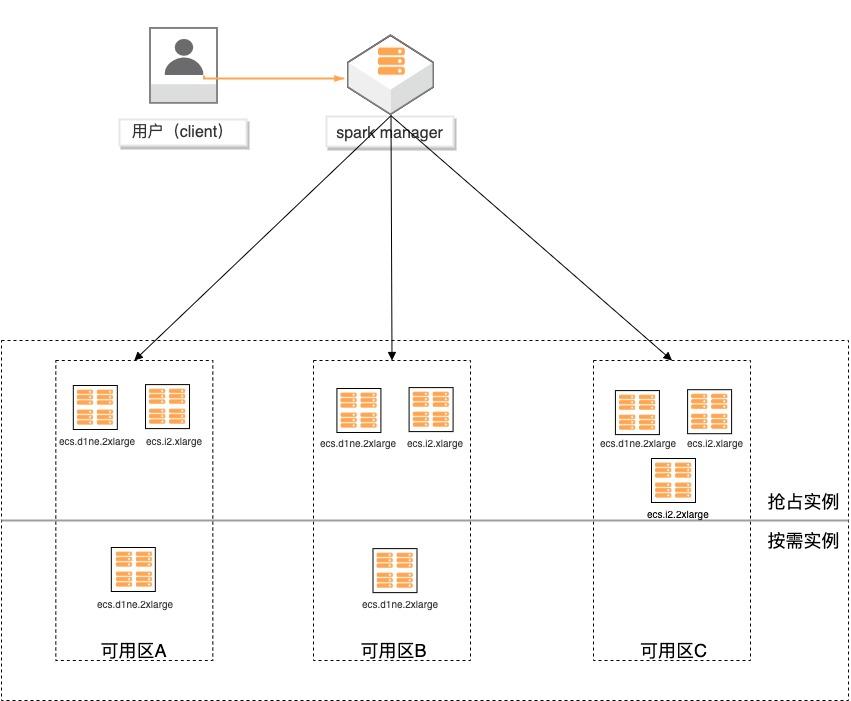
场景描述 基于弹性供应组(APG)搭建spark计算集 群,提供一键开启跨售卖方式、跨可用区、 跨实例规格的计算集群交付模式的实践。 方案优势 1.超低成本:跨售卖方式提供计算实 例,按秒计费,可全部使用spot实例 交付,最高可省90%成本。 2.稳定可靠:跨可用域、跨实例规格, 降低spot被集体释放的风险;自动托 管,分钟级巡检,动态保证集群的算 力。 3.快速交付:单次可在5分钟内交付 2000个实例。 4.多策略组合:可分别指定spot和按量 实例的交付策略,以及差额补足的策 略,包括成本最低、打散和折中。 解决问题 1.大规模计算集群成本高。 2.创建ECS实例方式单一,无法跨计费 方式、可用区及规格等核心参数。 3.当可用区资源紧张,无法自动保证基于 spot类型的稳定算力。 产品列表 专有网络VPC 云服务器ECS
文档版本:20200619 21 基于弹性供应组构建大数据集群分析 Spark集群搭建 类别 配置项 说明 访问规则 入方向 spark master需要开放 7077、8080和 18080 端口。2.返回创建 ECS页面,选择刚创建的安全组。文档版本:20200619 22 基于弹性供应组构建大数据集群分析 Spark集群搭建 配置完成,单击下一步:系统配置。步骤5 在...
EMR本地盘实例大规模数据集测试
场景描述 阿里云为了满足大数据场景下的存储需求,在云 上推出了本地盘D1机型,这个系列提供了本地 盘而非云盘作为存储,提高了磁盘的吞吐能力, 发挥Hadoop的就近计算优势。阿里云EMR 产品针对本地盘机型,推出了一整套的自动化运 维方案,帮助用户方便可靠地使用本地盘机型, 不需要关注整个运维过程同时数据的高可靠和 服务的高可用。 解决问题 1.云盘多份冗余数据导致成本高 2.磁盘吞吐量不高 3.节点的高可靠分布问题 4.本地盘与节点的故障监控问题 5.数据迁移时自动决策问题 6.自动故障节点迁移与数据平衡问题 产品列表 EMR(E-MapReduce) 本地盘 VPC
testbench.settings的不同参数用于不同条件的测试,例如合并小文件、使用索引、join优化、使用 spark作为计算引擎,这里不再赘述。本实践采用并行模式、使用 tez作为测试引擎进行测试:注释掉 security模式相关的 两行配置并且添加后面六行配置以便适合 hive-testbench进行大规模数据集测试(比 如 1TB规模的数据集),然后...
表格存储Tablestore
表格存储Tablestore是阿里云自研的面向海量结构化数据存储的Serverless分布式数据库,它可提供低成本、高性能的存储方案,同时也可提供稳定与极致的数据服务。
与Maxcompute、Spark、Flink等计算引擎集成,与Kafka、数据集成等链路组件无缝打通.易集成生态丰富.查看各个计费项各个区域定价.了解产品付费模式与计费规则.了解表格存储计费案例.了解表格存储常见计费问题.提供Serverless服务体验,零运维,低成本.单表10PB级数据量、万亿条记录数以及千万级别的TPS能力。自动负载均衡及...
来自:
云产品
云原生多模数据库Lindorm
云原生多模数据库Lindorm提供各规模、多模型的云原生数据库服务。可兼容HBase/Cassandra、OpenTSDB、Solr、SQL、HDFS等多种开源标准接口。支持海量数据的低成本存储处理和弹性按需付费,是互联网、IoT、车联网、广告、社交等场景首选数据库,也是为阿里核心业务提供支撑的数据库之一。
通过BDS/DTS等链路服务,可以实现Lindorm与常见存储系统(HBase、MySQL、SLS等)之间的在线实时同步和历史全量搬迁.Lindorm提供统一标准的数据接口及数据格式的按需转换,支持Spark、Flink、DLA、Hive等开放计算引擎进行数据的实时交互分析和批量复杂分析.支持与QuickBI、DataV对接,轻松实现数据的可视化访问和分析.可轻松与...
来自:
云产品
数据湖-在线学习场景数据分析

场景描述 本场景以在线教育中一个答题闯关类的应用为 例,使用WebServer来模拟演示这类日志数据 的分析处理。通过Nginx和Pythonflask搭建 WebServer,模拟应用中的关键页面,比如登 录、课程内容等,之后构造若干用户使用的模拟 日志数据,投递到数据湖进行分析后获取应用 PV、UV、课程内容访问排行、平均得分等等。 解决问题 基于数据湖(EMR+OSS)搭建大数据平台。 EMR和OSS使用和配置。 数据统一存储到OSS。 产品列表 E-MapReduce 对象存储OSS 云服务器ECS 访问控制RAM 专有网络VPC
支持Hadoop,Hive,Spark,Flink,Presto,HBase,Impala,Druid等引擎高 性能的运行在数据湖之上。文档版本:20200331 1数据湖-在线学习场景数据分析 最佳实践概述 支持Fuse/Posix 文件接口。 支持混合云的方案,支持云上云下同时读写访问。文档版本:20200331 2数据湖-在线学习场景数据分析 前置条件 前置条件 在...
阿里云大数据&AI
阿里云大数据和AI产品服务。开放数据处理服务ODPS提供强大的数据分析和管理功能;开源大数据产品支持更加灵活地构建大数据平台;AI和机器学习产品提供AI工程平台和智算服务。
支持Hive/Spark/Presto/Flink 等10+计算引擎.丰富的开源引擎.独有的JindoFS加速能力,大规模集群优于HDFS,让数据分析如同本地一样快速高效.数据湖计算加速.支持Spark/Presto on K8s+Spark Remote Shuffle Service,并经过大规模生产环境实践验证.对象存储OSS.Databricks 数据洞察.推荐搭配使用.云原生数据湖.云原生数据湖....
来自:
云产品
云数据库MongoDB版
阿里云云数据库MongoDB版是完全兼容MongoDB协议、高度兼容DynamoDB协议的在线文档型数据库服务。支持单节点、双节点、副本集和分片集群四种部署架构,能够满足不同的业务场景需要。
最多支持配置1000个白名单规则,直接从访问源进行风险控制.备份存储至对象存储OSS,多层网络防护机制,抵御大多数情况的恶意数据损毁.数据安全:自动备份和一键恢复,多层网络安全防护.数据传输服务(Data Transmission Service,简称DTS).数据库传输平台,支持RDBMS(关系型数据库)、NoSQL、OLAP等多种数据源之间数据进行...
来自:
云产品
基于DataWorks的大数据一站式开发及数据治理

概述 基于Dataworks做大数据一站式开发,包含数据实时采集到kafka通过实时计算对数据进行ETL写入HDFS,使用Hive进行数据分析。通过Dataworks进行数据治理,数据地图查看数据信息和血缘关系,数据质量监控异常和报警。 适用场景 日志采集、处理及分析 日志使用Flink实时写入HDFS 日志数据实时ETL 日志HIVE分析 基于dataworks一站式开发 数据治理 方案优势 大数据一站式开发,完善的数据治理能力。 性能优越:高吞吐,高扩展性。 安全稳定:Exactly-Once,故障自动恢复,资源隔离。 简单易用:SQL语言,在线开发,全面支持UDX。 功能强大:支持SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据源计算等Data Lake相关功能 ,以及各种流式及静态数据源关联查询。
步骤3 选择实时计算和 EMR引擎(在创建工作空间时添加 EMR引擎需配置 AK,也可以先 创建空间,再添加引擎避免无法识别 EMR用户问题)。文档版本:20201020 14 基于 Dataworks的大数据一站式开发及数据治理 基础环境搭建 步骤4 输入实时计算引擎和 EMR相关配置,创建工作空间。步骤5 对于已经创建的项目也可以在工作工具配置...
多账号下企业分账
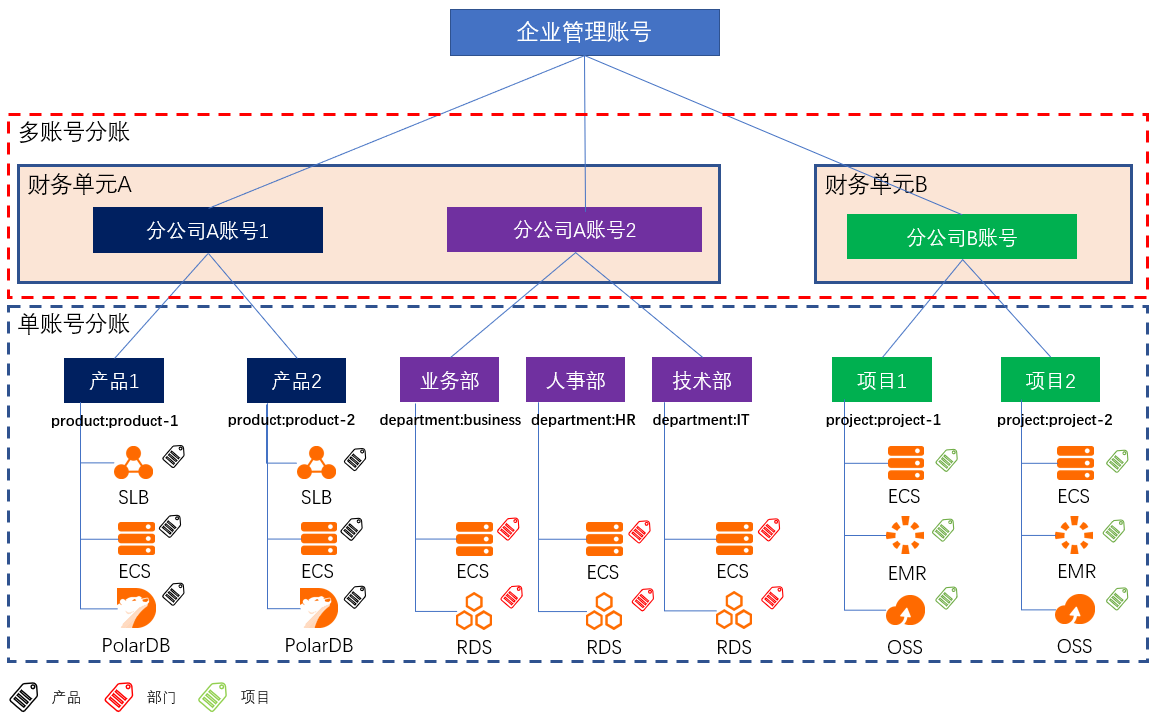
场景描述 财务分账,是根据企业的成本中心,将云上资源的成本划分到给各个项目组/业务部门;助力企业快速梳理云上成本结构,搭建复杂组织架构下的成本关系,便捷地进行财务和云上成本的管理。 大型企业或集团公司,由于组织架构复杂,业务复杂等原因,通常拥有多个阿里云账号来管理规模庞大的云上资源。针对云上资源,如何建立有效的分账方案,是财务关注的重要问题。 解决问题 解决CIO/CTO最关心的云上IT治理,IT成本核算等问题。 弄清楚企业内各部门成本及云上IT成本结构。 让CIO/CTO准确地掌握云上资源成本情况,清楚业务与成本的关系。 让采购/运维轻松搞定每月的IT成本汇报。
云管理团队整体负责云上资源管理 – 如云服务日常生命周期管理、成本管理、合 规管理、安全管理等相关业务。当收到业务部门对云资源的申请后,云管理团队部 署和配置云上资源,通过堡垒机、客户端等方式交付给业务部门使用。从费用的角度,通常也是由云管理团队来全权负责,统一支付。内部账单的精细化 管理并不十分严格。...
云消息队列 RocketMQ 版
云消息队列 RocketMQ 版是基于 Apache RocketMQ 构建的分布式消息中间件,广泛用于异步解耦、削峰填谷等场景。可支撑千万级并发、万亿级数据洪峰,更稳定,更安全。
可对接 Storm/Spark 实时流计算引擎,亦可对接 Hadoop/ODPS 等离线数据仓库系统.云消息队列 MQ.实时计算 Flink 版.推荐搭配使用.天猫双11大促,各个分会场琳琅满目的商品需要实时感知价格变化,大量并发访问数据库导致会场页面响应时间长,集中式缓存因为带宽瓶颈限制商品变更的访问流量,通过 RocketMQ 构建分布式缓存,...
来自:
云产品
- 产品推荐
- 这些文档可能帮助您