数据管理与服务
数据管理与服务作为阿里云产品六大版块之一,面向不同业务场景,阿里云提供数据存储、分析、应用等全链路能力,满足企业客户全方位的数据处理需求,实现计算和存储分离、资源解耦、数据移动减化,用以满足行业快速发展的需求和趋势,利用数据重塑其业务。
云数据库RDS MySQL从入门到高阶.DataWorks全链路数据治理包含智能数据建模、全域数据集成、高效数据开发、主动数据治理、全面数据安全、快速分析服务六大产品能力,覆盖数据的全生命周期。本篇全域数据集成向开发者介绍通过DataWorks数据集成在多表多表、多表到单表、单表到单表等场景下,进行实时或离线同步的技术选型与...
来自:
云产品
数据湖-在线学习场景数据分析

场景描述 本场景以在线教育中一个答题闯关类的应用为 例,使用WebServer来模拟演示这类日志数据 的分析处理。通过Nginx和Pythonflask搭建 WebServer,模拟应用中的关键页面,比如登 录、课程内容等,之后构造若干用户使用的模拟 日志数据,投递到数据湖进行分析后获取应用 PV、UV、课程内容访问排行、平均得分等等。 解决问题 基于数据湖(EMR+OSS)搭建大数据平台。 EMR和OSS使用和配置。 数据统一存储到OSS。 产品列表 E-MapReduce 对象存储OSS 云服务器ECS 访问控制RAM 专有网络VPC
通过Nginx和Pythonflask搭建WebServer,模拟应用中的关 键页面,比如登录、课程内容等,之后构造若干用户使用的模拟日志数据,投递到数 据湖进行分析后获取应用PV、UV、课程内容访问排行、平均得分等等。方案优势 支持超过10亿条元数据规模的数据管理,同时支持高可靠和高可用。 支持元数据实时备份和重建集群快速恢复...
实时数仓Hologres
Hologres(原交互式分析)是一站式实时数据仓库引擎,支持海量数据实时写入、实时更新、实时分析,支持标准SQL(兼容PostgreSQL协议),支持PB级数据多维分析(OLAP)与自助分析(Ad Hoc),支持高并发低延迟的在线数据服务(Serving),与MaxCompute、Flink、DataWorks深度融合,提供离在线一体化全栈数仓解决方案。
某货运物流公司其大数据部门一直在探索建设新一代数仓,但一直没有取得很大突破,无法让数据发挥更大价值。通过Hologres建立的新一代实时数仓,替换原有ES、HBase等架构,解决千万级订单数据实时分析慢和上百万货运司机物流实时调度难的问题.减少了维度退化的设计,支持千万订单数据实时多维分析,提升业务查询灵活性和开发...
来自:
云产品
SLS数据入湖Kafka最佳实践
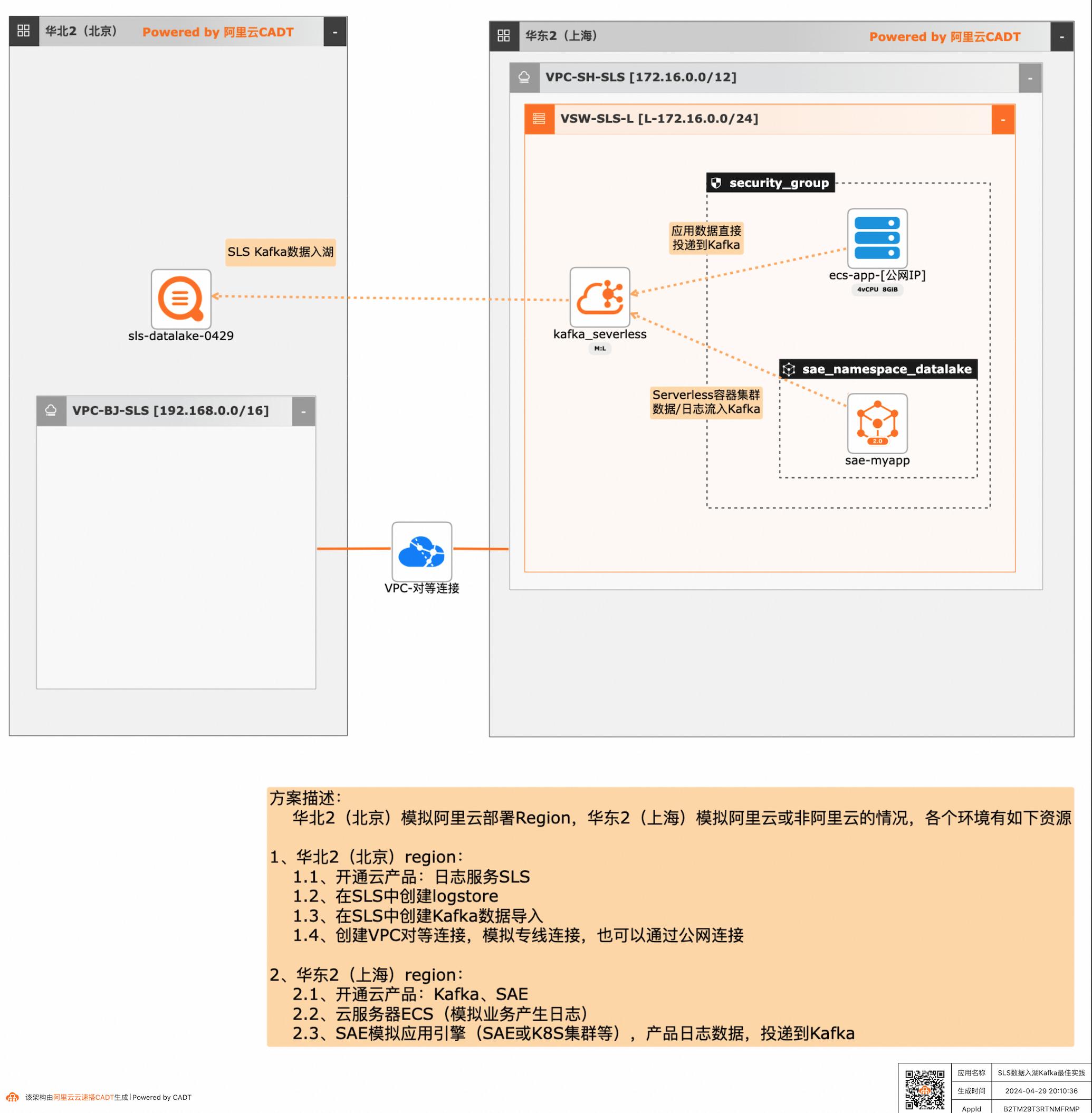
应用和数据分散在多云或混合云,在面对多云/混合云这样大的趋势下,数据无法进行统一的聚合、分析处理和导出等,本方案给出了在多云/混合云场景下,构建通过标准的Kafka协议和托管服务,SLS可以连接Kafka数据入湖导入,然后进行统一的海量数据的集中存储、智能转储、聚合分析查询等。
SLS 数据入湖 Kafka 最佳实践 业务架构 场景描述 应用和数据分散在多云或混合云,在面对多云/混合云这样大的趋势下,数据无法进行统一的 聚合、分析处理和导出等,本方案给出了在多 云/混合云场景下,构建通过标准的Kafka协议 和托管服务,SLS可以连接Kafka数据入湖导 入,然后进行统一的海量数据的集中存储、智 能转储、...
Spark on ECI大数据分析

场景描述 方案优势 1.计算引擎弹性扩缩容,兼顾资源弹性与计 算资源成本优化。 2.计算与存储分离架构,结合阿里云原生云 存储产品,海量数据湖优势。 3.Kubernetes原生的调度性能优势,提升在 大规模分析作业时的分析性能优势分。 4.集群资源隔离和按需分配。 解决问题 1.计算资源弹性能力不足,计算资源成本管 控能力欠缺. 2.集群资源调度能力和隔离能力不足。 3.计算与存储无法分离,大数据量分析时出 现数据存储资源瓶颈。 4.Spark submit方式提交分析作业参数支持 有限等缺点。 产品列表 容器服务Kubernetes版(ACK) 弹性容器实例(ECI) 文件存储HDFS 对象存储OSS 专有网络VPC 容器镜像服务ACR
应用范围 需要使用 Spark on Kubernetes解决方案的用户 对 Spark大数据分析平台计算资源成本控制考虑的用户 需要有灵活可扩展计算平台资源弹性及管控的用户 名词解释 文件存储 HDFS:阿里云文件存储 HDFS是面向阿里云 ECS实例及容器服务等计 算资源的文件存储服务,允许用户像在 Hadoop分布式文件系统中管理和访问数 据,...
通过ES兼容接口方式使用Kibana访问SLS数据
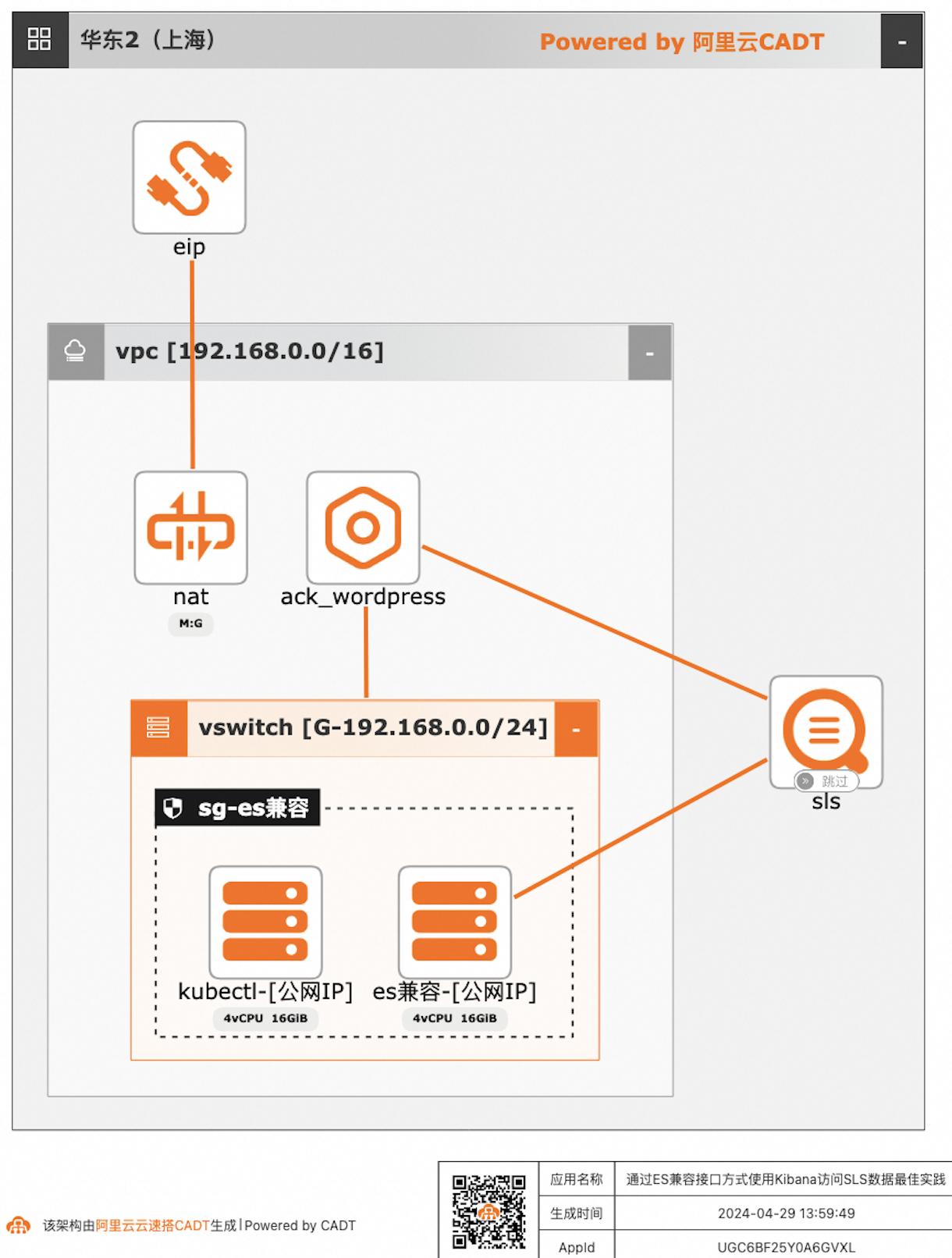
自建ELK日志系统的客户迁移到阿里云日志服务SLS后,对SLS查询分析语法不太熟悉的客户,可以继续沿用原有的查询分析习惯,在不改变使用方式习惯的情况下,通过Elasticsearch兼容接口的方式使用Kibana访问SLS。
通过ES兼容接口方式使用Kibana访问SLS数据最佳实践 业务架构 场景描述 日志服务SLS提供Elasticsearch兼容接口,支 持客户将日志采集到日志服务后,仍可以继续沿 用Elasticsearch的查询方案,即通过使用 Kibana访问日志服务的Elasticsearch兼容接 口,实现查询SLS数据。应用场景 自建ELK日志系统的客户迁移到阿里云日志服 务...
ECS 数据备份与保护
随着企业核心业务规模不断扩大,需要根据业务需求对生产环境中的关键数据进行定期备份。
产品解决方案文档与社区权益中心定价云市场合作伙伴支持与服务了解阿里云备案控制台ECS 数据备份与保护方案介绍方案优势应用场景方案部署ECS 数据备份与保护随着企业核心业务规模不断扩大,需要根据业务需求对生产环境中的关键数据进行定期备份,在发生误操作、病毒感染、或攻击等情况时,能够快速从已有的快照恢复到某个...
来自:
解决方案
基于弹性供应组构建大数据分析集群
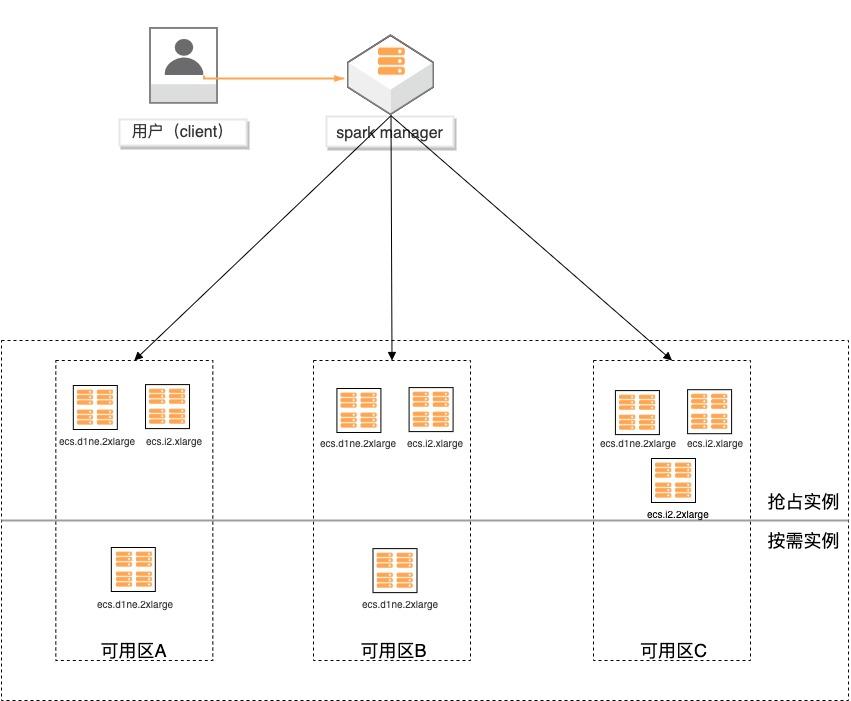
场景描述 基于弹性供应组(APG)搭建spark计算集 群,提供一键开启跨售卖方式、跨可用区、 跨实例规格的计算集群交付模式的实践。 方案优势 1.超低成本:跨售卖方式提供计算实 例,按秒计费,可全部使用spot实例 交付,最高可省90%成本。 2.稳定可靠:跨可用域、跨实例规格, 降低spot被集体释放的风险;自动托 管,分钟级巡检,动态保证集群的算 力。 3.快速交付:单次可在5分钟内交付 2000个实例。 4.多策略组合:可分别指定spot和按量 实例的交付策略,以及差额补足的策 略,包括成本最低、打散和折中。 解决问题 1.大规模计算集群成本高。 2.创建ECS实例方式单一,无法跨计费 方式、可用区及规格等核心参数。 3.当可用区资源紧张,无法自动保证基于 spot类型的稳定算力。 产品列表 专有网络VPC 云服务器ECS
本文采用 spark standalone集群模式演示基于弹性供应组构建大数据分析集群,spark standalone集群如下图所示:鉴于大数据集群对 IO高性能的要求,采用阿里云云服务器 ECS本地盘实例:D系列 和 I系列来作为 spark集群节点。1.2.集群计算能力规划 基于降成本的需要,您可以使用弹性供应组同时开出抢占式实例和按量付费实例,...
EMR本地盘实例大规模数据集测试
场景描述 阿里云为了满足大数据场景下的存储需求,在云 上推出了本地盘D1机型,这个系列提供了本地 盘而非云盘作为存储,提高了磁盘的吞吐能力, 发挥Hadoop的就近计算优势。阿里云EMR 产品针对本地盘机型,推出了一整套的自动化运 维方案,帮助用户方便可靠地使用本地盘机型, 不需要关注整个运维过程同时数据的高可靠和 服务的高可用。 解决问题 1.云盘多份冗余数据导致成本高 2.磁盘吞吐量不高 3.节点的高可靠分布问题 4.本地盘与节点的故障监控问题 5.数据迁移时自动决策问题 6.自动故障节点迁移与数据平衡问题 产品列表 EMR(E-MapReduce) 本地盘 VPC
应用范围 需要使用阿里云 EMR+本地盘进行大数据业务前进行性能测试的用户 线下自建大数据集群用户需要迁移到阿里云云上 EMR+本地盘进行大数据分析性 能对比测试的用户 名词解释 VPC:Virtual Private Cloud,简称 VPC。基于阿里云创建的自定义私有网络,不 同的专有网络之间二层逻辑隔离,可以在自己创建的专有网络内创建和...
互联网电商行业离线大数据分析

电商网站销售数据通过大数据分析后将业务指标数据在大屏幕上展示,如销售指标、客户指标、销售排名、订单地区分布等。大屏上销售数据可视化动态展示,效果震撼,触控大屏支持用户自助查询数据,极大地增强数据的可读性。
作为阿里巴巴数据中台的建设者,互联网电商行业离线大数据分析 最佳实践概述 DataWorks从2009年起不断沉淀阿里巴巴大数据建设方法论,同时与数万名政务/金融/零售/互联网/能源/制造等客户携手,助力产业数字化升级。 云原生大数据计算服务 MaxCompute:是面向分析的企业级 SaaS 模式云数据仓库,以 Serverless 架构提供...
Function Compute构建高弹性大数据采集系统
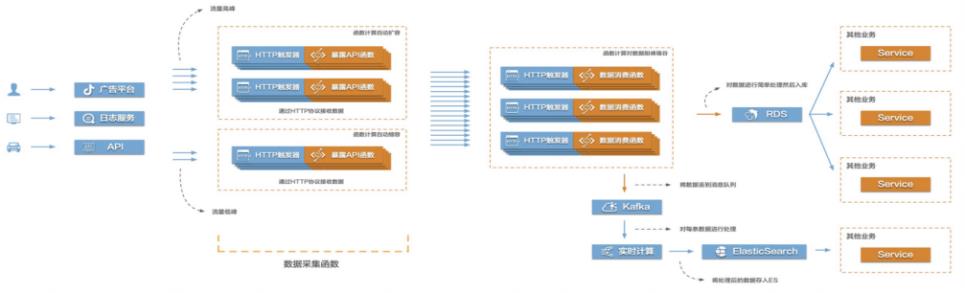
当前互联网很多场景都存在需要将大量的数据信息采集起来然后传输到后端的各类系统服务中,对数据进行处理、分析,形成业务闭环。比如游戏行业中的游戏发行、游戏运营,产互行业中的数字营销,物联网、车联网行业中的硬件、车辆信息上报等等。这些场景普遍存在数据采集量大、数据传输需要稳定且吞吐量大的特点,给整个数据采集传输系统带来很大的挑战。在这个场景中,有三个关键的环节,数据采集、数据传输、数据处理。该最佳实践主要涉
Function Compute构建高弹性大数据采集系统 最佳实践 业务架构 场景描述 当前互联网很多场景都存在需要将大量的数据 信息采集起来然后传输到后端的各类系统服务 中,对数据进行处理、分析,形成业务闭环。比 如游戏行业中的游戏发行、游戏运营,产互行业 中的数字营销,物联网、车联网行业中的硬件、车辆信息上报等等。这些...
E-MapReduce Serverless Spark 版
E-MapReduce Serverless Spark 是阿里云 E-MapReduce 基于 Spark 提供的一款全托管、一站式的数据计算平台。它为用户提供任务开发、调试、发布、调度和运维等全方位的产品化服务,显著简化了大数据计算的工作流程,使用户能更专注于数据分析和价值提炼。
基于 EMR Serverless Spark 建立数据平台.<开源大数据平台 E-MapReduce.E-MapReduce(以下简称:\\.E-MapReduce Serverless Spark 版.致力于为客户提供优质的产品体验,客户无需构建复杂的基础设施就可以开始作业的开发之旅.基于 Spark Native Engine 提供最高3倍于开源 Spark 的性能体验.基于阿里云 Serverless 底座,提供...
来自:
云产品
无代理ECS数据备份与高效环境搭建
本方案是基于快照提供数据保护和环境搭建的解决方案。可以帮助您实现无代理且有效可靠的数据备份,同时还可以帮助您快速克隆部署开发测试环境。使用基于快照的备份不仅简单有效,在数据备份以及恢复中也能保证稳定可靠,同时基于快照的环境搭建,不仅可以免于从0到1搭建环境,还可以将环境、数据等全部打包克隆到新机器上。
产品解决方案文档与社区权益中心定价云市场合作伙伴支持与服务了解阿里云备案控制台无代理ECS备份与高效环境搭建方案介绍方案优势应用场景方案部署方案权益无代理ECS备份与高效环境搭建本方案是基于快照提供数据保护和环境搭建的解决方案,可以帮助您实现无代理且有效可靠的数据备份,同时还可以帮助您快速克隆部署开发测试...
来自:
解决方案
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
应用范围 需要使用 Spark优化方案的用户 对 Spark大数据分析平台计算性能,成本控制考虑的用户。需要有灵活可扩展的计算平台、弹性可伸缩集群资源及灵活管控的用户 名词解释 Databricks数据洞察:是基于 Apache Spark的全托管大数据分析平台,产品内核 引擎使用 Databricks Runtime,并针对阿里云平台进行优化,使用 ...
企业级云灾备与数据管理
本方案以备份 ECS 文件为例,介绍如何部署一个简单的云灾备环境,以满足常见的数据保护需求。
产品解决方案文档与社区权益中心定价云市场...无缝对接多种数据分析产品,对存储在对象存储 OSS 中的数据直接进行大数据分析,洞察业务价值。同时,数据湖提供多种存储类型的冷热分层转换能力,通过数据全生命周期管理优化存储成本。查看详情技术解决方案咨询我们将根据您提交的需求,安排技术解决方案专家为您服务!立即咨询
来自:
解决方案
多媒体数据存储与分发
以搭建一个多媒体数据存储与分发服务为例,搭建一个多媒体数据存储与分发服务。
安全、智能的存储系统提供用户级别资源隔离机制和多层次安全防护,提供多种数据处理能力,无缝对接大数据分析系统以及可观测平台,满足企业数据分析与管理的需求。灵活的访问加速能力OSS作为存储源站,可无缝集成内容分发网络CDN,提升文件被多次重复下载时的访问体验;支持传输加速服务,优化互联网传输链路和协议栈,并...
来自:
解决方案
云原生数据湖分析DLA
阿里云云原生数据湖分析是新一代大数据解决方案,采取计算与存储完全分离的架构,支持对象存储(OSS)、RDS(MySQL等)、NoSQL(MongoDB等)数据源的消息实时归档建仓,提供Presto和Spark引擎,满足在线交互式查询、流处理、批处理、机器学习等诉求。内置大量优化+弹性,比开源自建集群最高降低50%+的成本,最快可1分钟级拉起300个计算节点,快速满足业务资源要求。
兼容MySQL协议,无需ETL,可使用SQL直接分析OSS等数十种源数据,快速低成本开启大数据分析.云数据库RDS MySQL版.对象存储OSS.推荐搭配产品.Lakehouse实时入湖.异构数据实时分析,为数据驱动提速.直接使用生产库对海量数据分析,不仅会对线上业务产生影响,还可能出现超时,查询失败的现象;但自建数据仓库又需投入大量的软...
来自:
云产品
- 产品推荐
- 这些文档可能帮助您