云原生大数据计算服务MaxCompute
阿里云云原生大数据计算服务MaxCompute是面向分析的企业级云数仓,作为一体化大数据智能计算平台ODPS的大规模批量计算引擎,MaxCompute以 Serverless 架构提供快速、全托管的在线数据仓库服务,使您经济高效的分析处理海量数据,进行敏捷的业务洞察。
【最佳实践】离线数据大数据分析及大屏展示.【最佳实践】MaxCompute湖仓一体方案.2020云栖大会-数据仓库前瞻技术与实践专场回顾.MaxCompute 玩法大全.启用 MaxCompute Spark.启用 MaxCompute 开发者版.【发布会】MaxCompute企业级安全新能力发布.【发布会】Mars科学计算引擎开源发布.【发布会】MaxCompute开发者版发布.TPCx...
来自:
云产品
云消息队列 Kafka 版
云消息队列 Kafka 版是阿里云基于Apache Kafka构建的大数据消息中间件,广泛用于日志收集和分析、数据处理等场景。可提供全托管服务,用户无需部署运维,更专业、更可靠、更安全。
云消息队列 Kafka 版支持连接自建 Filebeat 日志采集,经由 Kafka 流转到后方 ES 服务.Hbase、Spark 数据处理.云消息队列 Kafka 版数据导入 Hbase 等存储,实现低成本存储和计算分析.Flink 实时数仓.云消息队列 Kafka 版支持数据流转到 Flink,实现ETL处理、实时数据分析等业务.支持阿里云主子账号、鉴权与授权机制,提供...
来自:
云产品
云数据库 Cassandra 版
Cassandra是连续9年DB-Engines排名第一的宽表数据库,支持类SQL语法CQL,开发体验类似MySQL,可扩展PB级存储。推出企业版Lindorm for Cassandra云原生多模数据库,采用存储计算分离架构,支持海量数据的低成本存储和按需付费,具备更高性价比和更为丰富的企业级功能。
Presto满足在线交互式需求.Serverless分析引擎Spark&Presto.Ganos时空数据分析.基于Spark RDD构建了统一的时空数据模型,方便建模.综合治理,支持丰富的自研、开源引擎.Dataworks构建数据湖统一开发平台.云数据库Cassandra版支持节点升配及降配:从容应对可预知的业务潮汐。集群可小可大:单节点起配,起配门槛低。可扩展至...
来自:
云产品
云消息队列 RocketMQ 版
云消息队列 RocketMQ 版是基于 Apache RocketMQ 构建的分布式消息中间件,广泛用于异步解耦、削峰填谷等场景。可支撑千万级并发、万亿级数据洪峰,更稳定,更安全。
常规数据源 更丰富数据源 本地数据库(局域网)本地部署版用户可以连接本地数据库进行数据分析。查看更多组件 常规图表组件 添加地图组件 ECharts组件.API 请求资源包,更优惠.资源包,更优惠.专享实例,更稳定,更可靠,专家保驾护航.唐家哲,靖鑫,也树.旧商品卡片,建议使用「轻量商品卡片」.消息队列 RabbitMQ 版.完全...
来自:
云产品
云数据库 SelectDB 版
阿里云数据库 SelectDB 是现代化实时数据仓库 SelectDB 在阿里云上的全托管服务,内核基于业界领先的开源分析型数据库 Apache Doris 研发,由阿里云和飞轮科技联合打造。阿里云数据库 SelectDB 聚焦于满足企业级大数据分析需求,广泛应用于实时报表分析、即席多维分析、日志检索分析、数据联邦与查询加速等场景,致力于为客户提供极致性能、简单易用的数据分析服务。
相关产品云数据库 SelectDB 版本产品日志服务 SLS检索分析服务 Elasticsearch 版在线咨询湖仓一体分析传统的大数据平台解决方案通过组合多套数据湖查询引擎和数据仓库系统,来满足客户复杂多样的大数据分析需求,面临人力及资源成本高、数据开发使用复杂、数据分析实时性差等问题。基于 SelectDB 构建湖仓一体的分析系统,...
来自:
云产品
云原生数据仓库AnalyticDB MySQL数据仓库
阿里云云原生数据仓库AnalyticDB MySQL版(简称AnalyticDB)是融合数据库、大数据技术于一体的云原生企业级数据仓库平台。云原生数据仓库AnalyticDB MySQL版支持数据实时写入和同步更新、实时计算和实时服务,可用于构建企业级报表系统、数据仓库和数据服务引擎。
流量成本的升高,用户更加成熟,迫使客户需进行更加精细化的市场营销,提供更高品质的...边锋&AnalyticDB MySQL:打造一站式大数据分析平台.AnalyticDB MySQL带你学:基于Flink的高吞吐&精确一致性数据入湖.兰姆达 x AnayticDB 降本30%的数据湖最佳实践.一键实现穿衣自由|揭秘淘宝AI试衣间硬核技术:AnalyticDB向量在线召回.
来自:
云产品
SLS多云日志采集、处理及分析
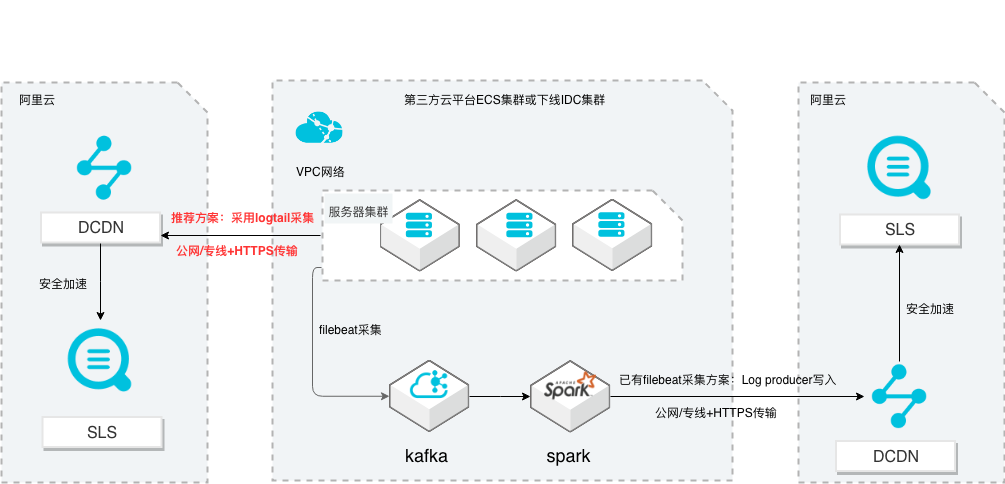
场景描述 从第三方云平台或线下IDC服务器上采集 日志写入到阿里云日志服务,通过日志服务 进行数据分析,帮助提升运维、运营效率, 建立DT 时代海量日志处理能力。 针对未使用其他日志采集服务的用户,推荐 在他云或线下服务器安装logtail采集并使用 Https安全传输;针对已使用其他日志采集 工具并且已有日志服务需要继续服务的情 况,可以通过Log producer SDK写入日志 服务。 解决问题 1.第三方云平台或线下IDC客户需要使用 阿里云日志服务生态的用户。 2.第三方云平台或线下IDC服务器已有完 整日志采集、处理及分析的用户。 产品列表 E-MapReduce 专有网络VPC 云服务器ECS 日志服务LOG DCDN
文档版本:20211203 24 SLS多云日志采集、处理及分析 Logtail日志采集处理分析 注意:查询分析设置的修改操作只会对新写入的数据生效,如果您需要提前对查询分 析设置的某些字段分析统计生效,请使用指定字段查询的自定义方式在日志写入到日 志库之前进行开启统计查询。步骤4 再次启动日志发生器和停止日志发生器。按云...
数据管理与服务
数据管理与服务作为阿里云产品六大版块之一,面向不同业务场景,阿里云提供数据存储、分析、应用等全链路能力,满足企业客户全方位的数据处理需求,实现计算和存储分离、资源解耦、数据移动减化,用以满足行业快速发展的需求和趋势,利用数据重塑其业务。
波克科技股份有限公司通过引入阿里云云原生实时数据仓库AnalyticDB,实现了每日百亿级游戏玩家行为数据的快速分析和处理,大幅降低数据分析成本,相比原有方案,数据处理性能提升10倍以上.网络安全升级支持IPV6.云原生数据仓库 AnalyticDB MySQL版.通过引入Hologres搭建的实时数仓,支撑了百亿级的业务数据复杂多维分析秒级...
来自:
云产品
自建Hadoop迁移MaxCompute
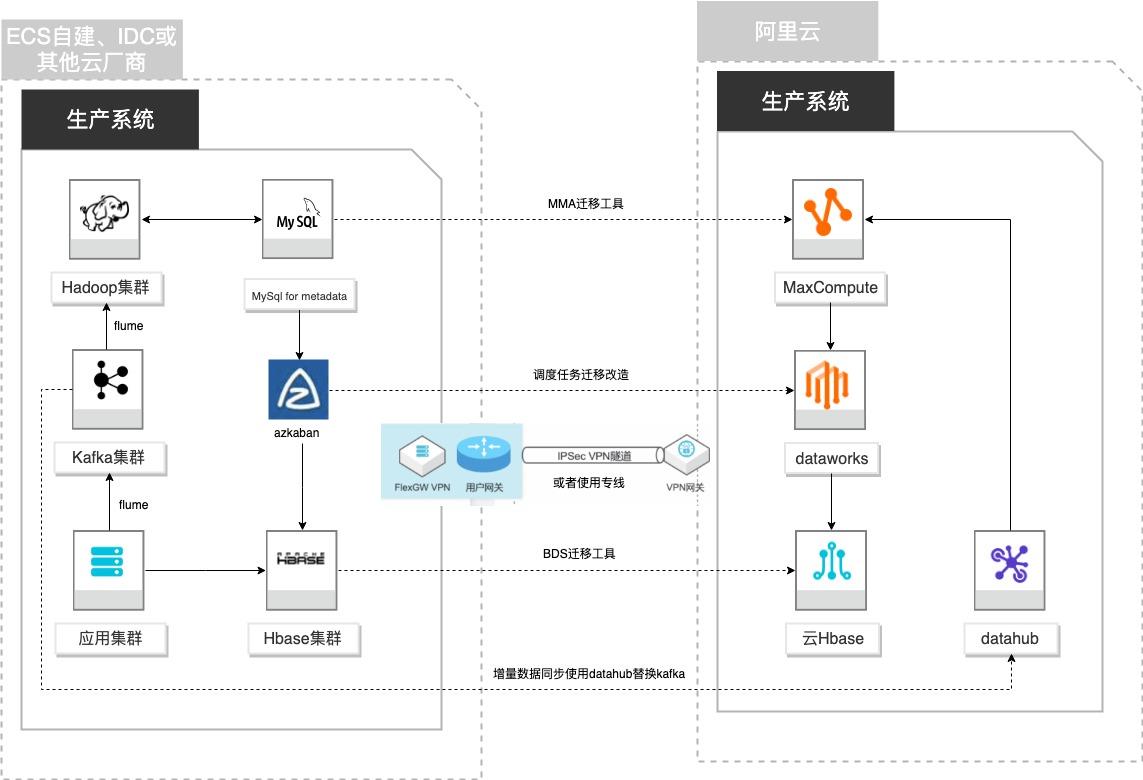
场景描述 客户基于ECS、IDC自建或在友商云平台自建了大数 据集群,为了降低企业大数据计算平台的成本,提高 大数据应用开发效率,更有效保障数据安全,把大数 据集群的数据、作业、调度任务以及业务数据库整体 迁移到MaxCompute和其他云产品。 解决的问题 自建Hadoop集群搬迁到MaxCompute 自建Hbase集群搬迁到云Hbase 自建Kafka或应用数据准实时同步到 MaxCompute 自建Azkaban任务迁移到Dataworks任务 产品列表 MaxCompute,Dataworks、云数据库Hbase版、Datahub、VPC,ECS。
将表 datahub_dataconnector_apache_logs 数 据 灌 入 odps_apache_logs 本实践方案中 Hive数据仓库中的原始表 apache_logs有一个分区字段 ds(日期值),每天生成一个分区。在使用 MMA工具迁移到 MaxCompute表 odps_apache_logs的 过程中,保留了该分区字段,因此在 MaxCompute上可以看到该表有一个分区字段:Datahub ...
云数据库产品总览(瑶池)
阿里云提供完善的数据库解决方案,多款数据库产品,满足99%的业务场景,荣获Gartner、信通院等国内外多项认证。轻松满足高可靠、高可用性、高性能等数据库需求;运维工作量大幅减少,让企业一站式享受数据上云及分布式架构的技术红利!
将重分析类SQL从RDS切换到ADB高性能库,亿级数据实时秒级拉取,可支持单表记录数百亿级.ADB支持TB-PB级数据分析,并支持垂直、水平平滑扩展,升配和增加节点对业务影响小.引入DLA,利用SLS+OSS+DLA+ADB组合打通数据全生命周期运营分析.覆盖国内外大中小企业,遍布电商新零售、游戏、教育直播、金融、软件服务等多种行业....
来自:
云产品
大数据系统基准性能测试最佳实践
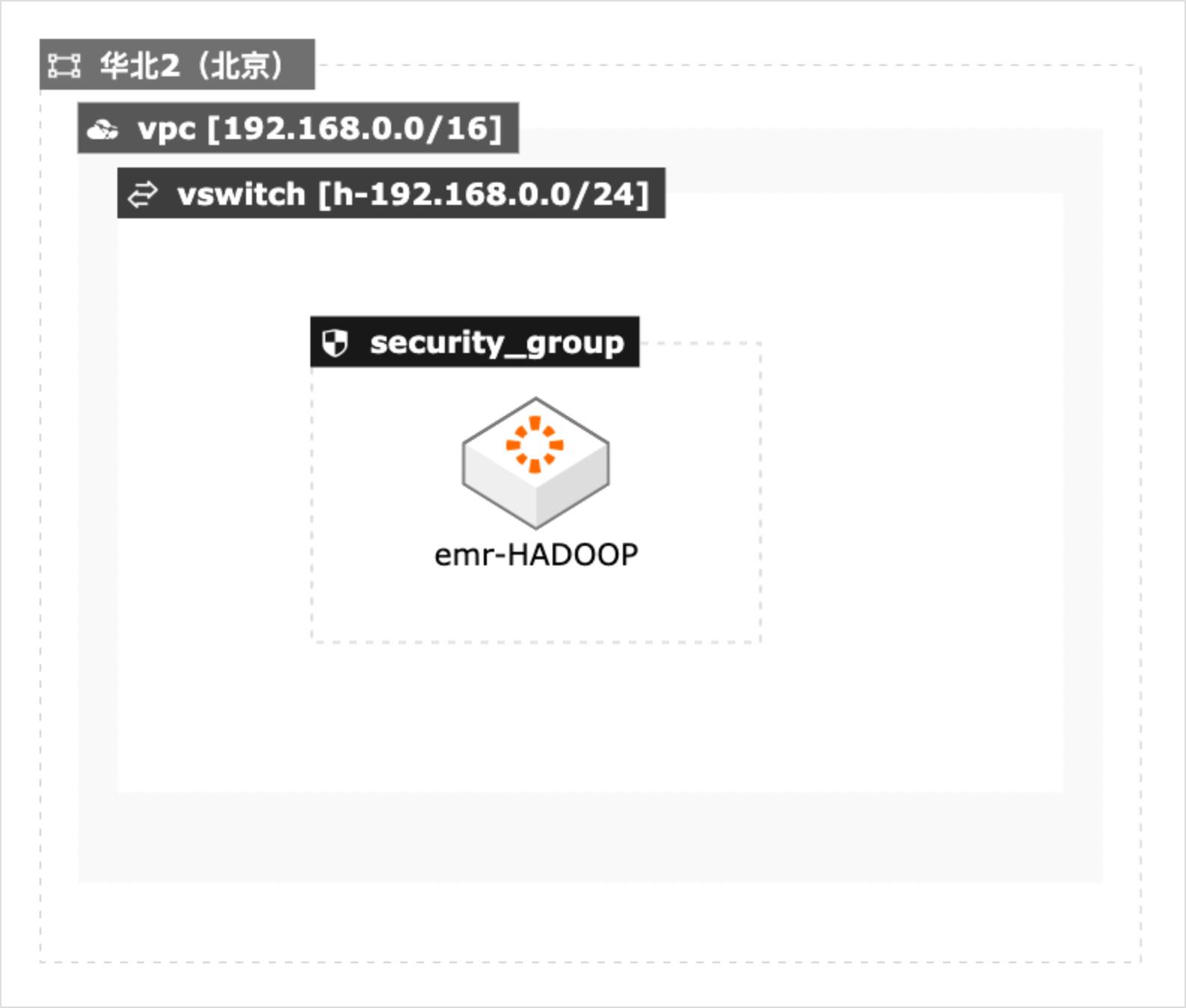
本方案适用于在阿里云上进行大数据基准性能测试的场景,包括 Teragen和Terasort测试,TestDFSIO测试。本文采用CADT工具结合阿里云的E-MapReduce服务快速构建测试集群,并提供了Teragen和Terasort测试,TestDFSIO测试的测试脚本,便于迅速开展测试。
应用范围 使用阿里云 E-MapReduce服务进行基准性能测试 名词解释 E-MapReduce:(简称 EMR),是运行在阿里云平台上的一种大数据处理的系统 解决方案。EMR构建于云服务器 ECS上,基于开源的 Apache Hadoop和 Apache Spark,让您可以方便地使用 Hadoop和 Spark生态系统中的其他周边系统分析和 处理数据。EMR还可以与阿里云...
实时数仓Hologres
Hologres(原交互式分析)是一站式实时数据仓库引擎,支持海量数据实时写入、实时更新、实时分析,支持标准SQL(兼容PostgreSQL协议),支持PB级数据多维分析(OLAP)与自助分析(Ad Hoc),支持高并发低延迟的在线数据服务(Serving),与MaxCompute、Flink、DataWorks深度融合,提供离在线一体化全栈数仓解决方案。
支持GIS空间数据分析.DataWorks开发集成.与DataWorks深度集成,提供图形化、智能化、一站式的数仓搭建和交互式分析服务工具,支持数据资产、数据血缘、数据实时同步、数据服务等企业级能力.达摩院Proxima向量检索.与机器学习平台PAI紧密结合,内置达摩院Proxima向量检索插件,支持在线实时特征存储、实时召回、向量检索.谢...
来自:
云产品
自建Hive数仓迁移到阿里云EMR
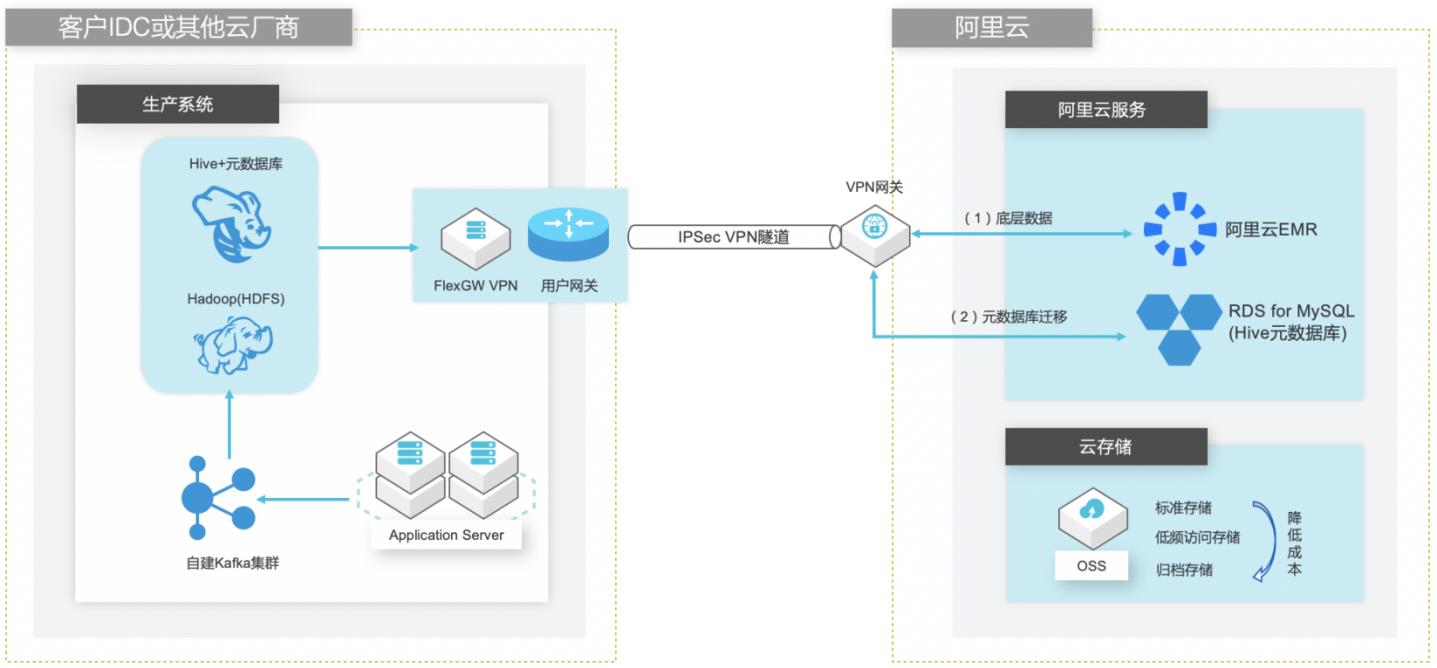
场景描述 客户在IDC或者公有云环境自建Hadoop集群构 建数据仓库和分析系统,购买阿里云EMR集群之 后,涉及到将数据仓库和Hive元数据的数据库迁 移上云。目前主流Hive数据仓库迁移场景为1.x 版本迁移到阿里云EMR(Hive2.x版本),涉及到 数据订正更新步骤。 解决的问题 Hive数据仓库的数据迁移方案 Hive元数据库的迁移方案 Hive跨版本迁移后的数据订正 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
自建 Hive数据仓库跨版本迁移到阿里云 EMR 场景描述 解决的问题 客户在IDC或者公有云环境自建Hadoop集群构建 Hive数据仓库的数据迁移方案 数据仓库和分析系统,购买阿里云 EMR集群之后,Hive元数据库的迁移方案 涉及到将数据仓库和Hive元数据的数据库迁移上 Hive跨版本迁移后的数据订正 云。目前主流 Hive数据仓库迁移场景...
- 产品推荐
- 这些文档可能帮助您