基于弹性供应组构建大数据分析集群
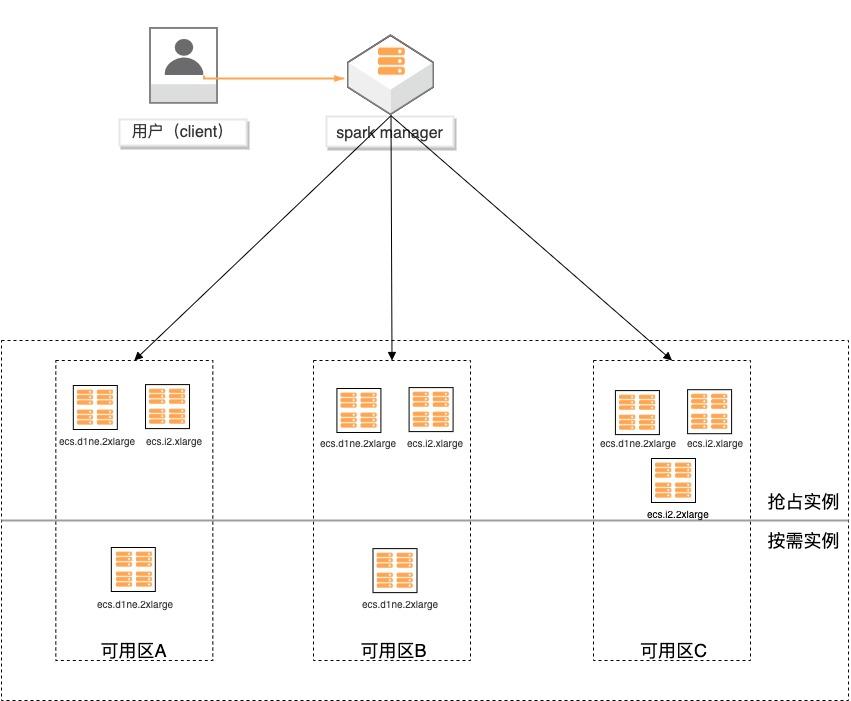
场景描述 基于弹性供应组(APG)搭建spark计算集 群,提供一键开启跨售卖方式、跨可用区、 跨实例规格的计算集群交付模式的实践。 方案优势 1.超低成本:跨售卖方式提供计算实 例,按秒计费,可全部使用spot实例 交付,最高可省90%成本。 2.稳定可靠:跨可用域、跨实例规格, 降低spot被集体释放的风险;自动托 管,分钟级巡检,动态保证集群的算 力。 3.快速交付:单次可在5分钟内交付 2000个实例。 4.多策略组合:可分别指定spot和按量 实例的交付策略,以及差额补足的策 略,包括成本最低、打散和折中。 解决问题 1.大规模计算集群成本高。 2.创建ECS实例方式单一,无法跨计费 方式、可用区及规格等核心参数。 3.当可用区资源紧张,无法自动保证基于 spot类型的稳定算力。 产品列表 专有网络VPC 云服务器ECS
本文采用 spark standalone集群模式演示基于弹性供应组构建大数据分析集群,spark standalone集群如下图所示:鉴于大数据集群对 IO高性能的要求,采用阿里云云服务器 ECS本地盘实例:D系列 和 I系列来作为 spark集群节点。1.2.集群计算能力规划 基于降成本的需要,您可以使用弹性供应组同时开出抢占式实例和按量付费实例,...
基于Flink+ClickHouse构建实时游戏数据分析
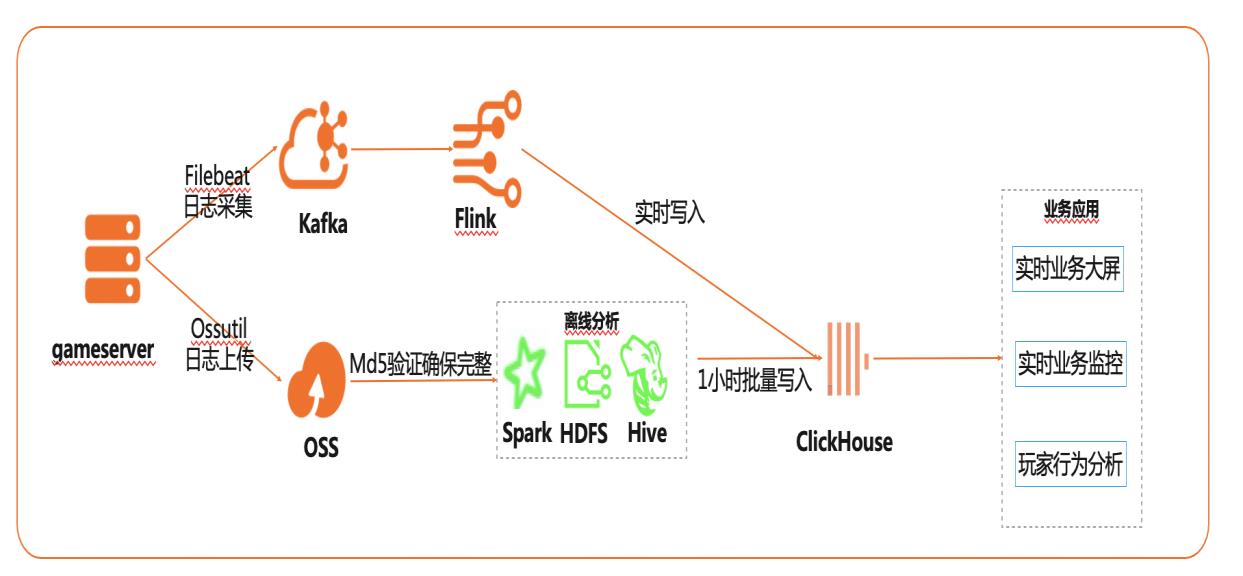
在互联网、游戏行业中,常常需要对用户行为日志进行分析,通过数据挖掘,来更好地支持业务运营,比如用户轨迹,热力图,登录行为分析,实时业务大屏等。当业务数据量达到千亿规模时,常常导致分析不实时,平均响应时间长达10分钟,影响业务的正常运营和发展。 本实践介绍如何快速收集海量用户行为数据,实现秒级响应的实时用户行为分析,并通过实时流计算Flink/Blink、云数据库ClickHouse等技术进行深入挖掘和分析,得到用户特征和画像,实现个性化系统推荐服务。 通过云数据库ClickHouse替换原有Presto数仓,对比开源Presto性能提升20倍。 利用云数据库ClickHouse极致分析性能,千亿级数据分析从10分钟缩短到30秒。 云数据库ClickHouse批量写入效率高,支持业务高峰每小时230亿的用户数据写入。 云数据库ClickHouse开箱即用,免运维,全球多Region部署,快速支持新游戏开服。 Flink+ClickHouse+QuickBI
核心模块 游戏服(gameserver):基于 Spring-boot模拟的游戏服务器,提供 Restful API模 拟用户行为数据的生成(一种:生成的用户行为数据直接写到 Kafka,另一种:生 成的用户数据写入到日志文件),扮演消息生产者角色,代码下载:https://code.aliyun.com/best-practice/game-server-188.git 日志采集(Filebeat):它...
E-MapReduce Serverless Spark 版
E-MapReduce Serverless Spark 是阿里云 E-MapReduce 基于 Spark 提供的一款全托管、一站式的数据计算平台。它为用户提供任务开发、调试、发布、调度和运维等全方位的产品化服务,显著简化了大数据计算的工作流程,使用户能更专注于数据分析和价值提炼。
内置 Spark Native Engine,相对开源版本性能提升200%;内置 Celeborn(Remote Shuffle Service),支持 PB 级 Shuffle 数据,计算资源总成本最高下降 30%\\u00A0.云原生极速计算引擎.支持计算存储分离,计算可弹性伸缩、存储可按量付费;对接 OSS-HDFS,完全兼容 HDFS 的云上存储,无缝平滑迁移上云;中心化的 DLF 元数据,...
来自:
云产品
Spark on ECI大数据分析

场景描述 方案优势 1.计算引擎弹性扩缩容,兼顾资源弹性与计 算资源成本优化。 2.计算与存储分离架构,结合阿里云原生云 存储产品,海量数据湖优势。 3.Kubernetes原生的调度性能优势,提升在 大规模分析作业时的分析性能优势分。 4.集群资源隔离和按需分配。 解决问题 1.计算资源弹性能力不足,计算资源成本管 控能力欠缺. 2.集群资源调度能力和隔离能力不足。 3.计算与存储无法分离,大数据量分析时出 现数据存储资源瓶颈。 4.Spark submit方式提交分析作业参数支持 有限等缺点。 产品列表 容器服务Kubernetes版(ACK) 弹性容器实例(ECI) 文件存储HDFS 对象存储OSS 专有网络VPC 容器镜像服务ACR
文档版本:20200409 16 Spark on ECI大数据分析 应用开发 文档版本:20200409 17 Spark on ECI大数据分析 Spark on Kubernetes实践方案对比 3.Spark on Kubernetes实践方案对比 本章中,我们首先通过 Spark on 阿里云容器服务 Kubernetes版(ACK)并结合 Kubernetes原生的技术说明来解释 Spark on Kubernetes架构相比传统的...
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
需要有灵活可扩展的计算平台、弹性可伸缩集群资源及灵活管控的用户 名词解释 Databricks数据洞察:是基于 Apache Spark的全托管大数据分析平台,产品内核 引擎使用 Databricks Runtime,并针对阿里云平台进行优化,使用 Notebook交互 式数据分析,Python库便捷安装,使用 Delta表存储比其他使用 Spark查询性能 有 5-10倍的...
- 产品推荐
- 这些文档可能帮助您