基于函数计算FC实现物联网音视频处理
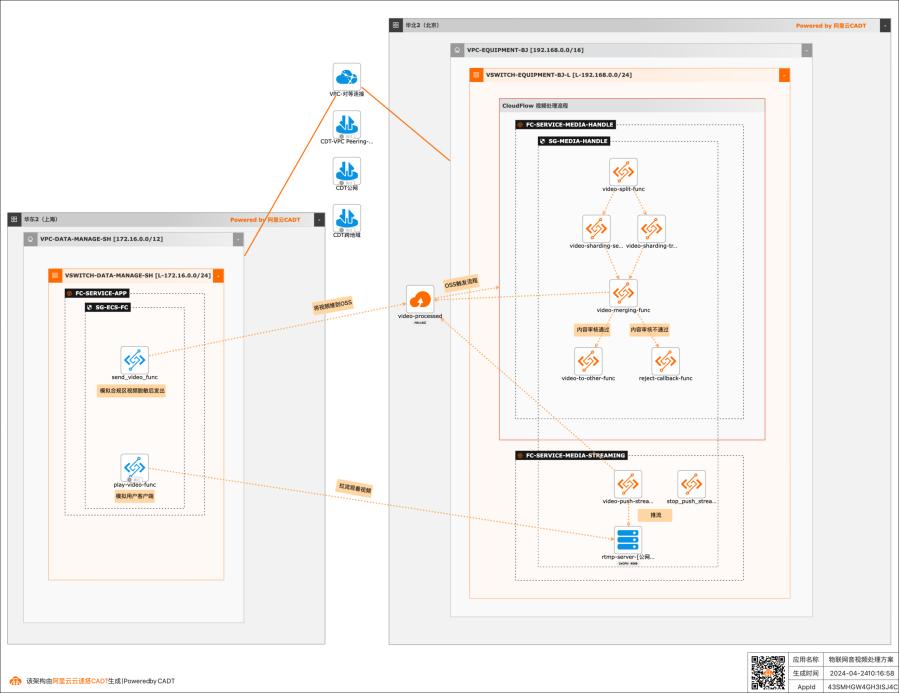
在物联网场景中,智能设备会产生大量的非结构化数据,并且采集量和频率都很高。比如各类摄像头(家用摄像头、车载摄像头、工业监控摄像头等)采集的数据。企业需要对这些非结构化数据做快速的分析和处理,然后应用到下游业务中,所以需要一套高并发、低成本、自动化的方案。该最佳实践就适用于这类场景。
基于函数计算FC实现物联网音视频处理最佳实践 场景描述 业务架构 基于阿里云函数计算FC和云工作流(CloudFlow)实现对物联网智能设备采集的音视频做切片、转解码 等视频处理,回传OSS,然后在客户端拉流观看的 自动化流程。应用场景 在物联网场景中,智能设备会产生大量的非结构化数 据,并且采集量和频率都很高。比如各类...
基于函数计算FC实现企业级权限精准控制Kafka跨实例消息同步
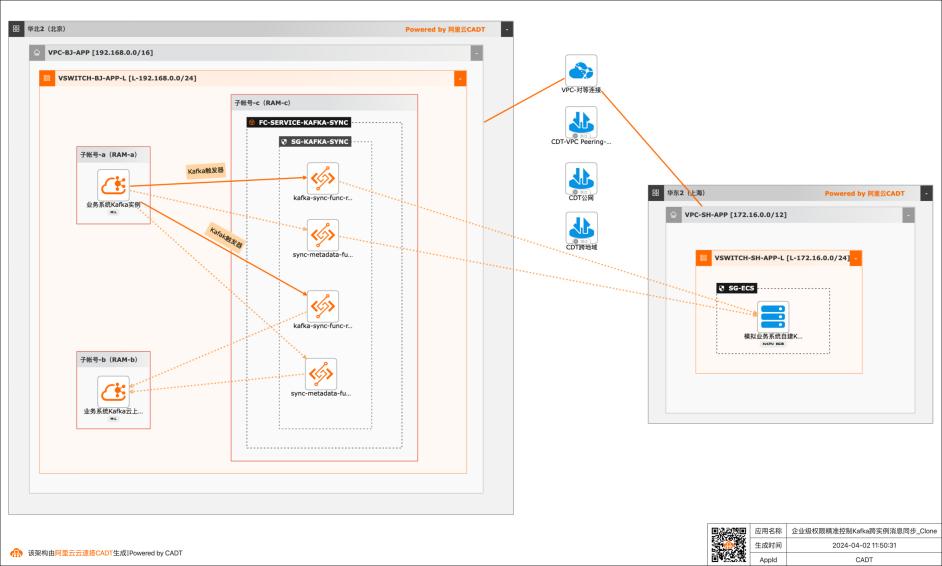
应用场景 在大数据场景,企业的Kafka实例可能存在多种情况,比如使用阿里云Kafka服务,可能是自建开源Kafka,或者是其他云上的云Kafka。不同的业务使用不同类型的Kafka实例,在这个前提下Kafka实例之间可能会需要消息同步的情况: 同帐号容灾场景:比如Kafka实例都是阿里云Kafka,但是Kafka实例会有主备之分,需要将主Kafka实例的消息实时同步到备Kafka。 跨帐号或异地容灾:这类场景比如主Kafka是阿里云Kafka,备Kafka是IDC开源自建Kafka,或者是其他云上的Kafka。 不同业务之间消息同步:因为现在的业务通常不会是信息孤岛,都需要消息互通,所以可能是A业务的Kafka实例消息需要同步到B业务的Kafka实例,并且这两个Kafka实例归属不同的RAM角色,有自己独自的权限控制。 解决问题 解决使用开源组件做消息同步的高成本问题。 解决使用开源组件做消息同步的并发性能、稳定性问题。 解决使用开源组件做消息同步的可靠性问题(重试机制,容错机制,死信队列等)。 大幅提升构建消息同步架构的效率,降低构建复杂度问题。
基于函数计算FC实现企业级权限精准控制Kafka跨实例消息同步最佳实践 场景描述 业务架构 基于阿里云函数计算FC实现同帐号阿里云Kafka实 例之间消息、元数据同步,跨帐号阿里云Kafka实例 之间消息、元数据同步,阿里云Kafka实例和IDC 自建Kafka(其他云Kafka)之间消息、元数据同步。应用场景 在大数据场景,企业的Kafka实例...
基于SpringCloud应用玩转MSE实践
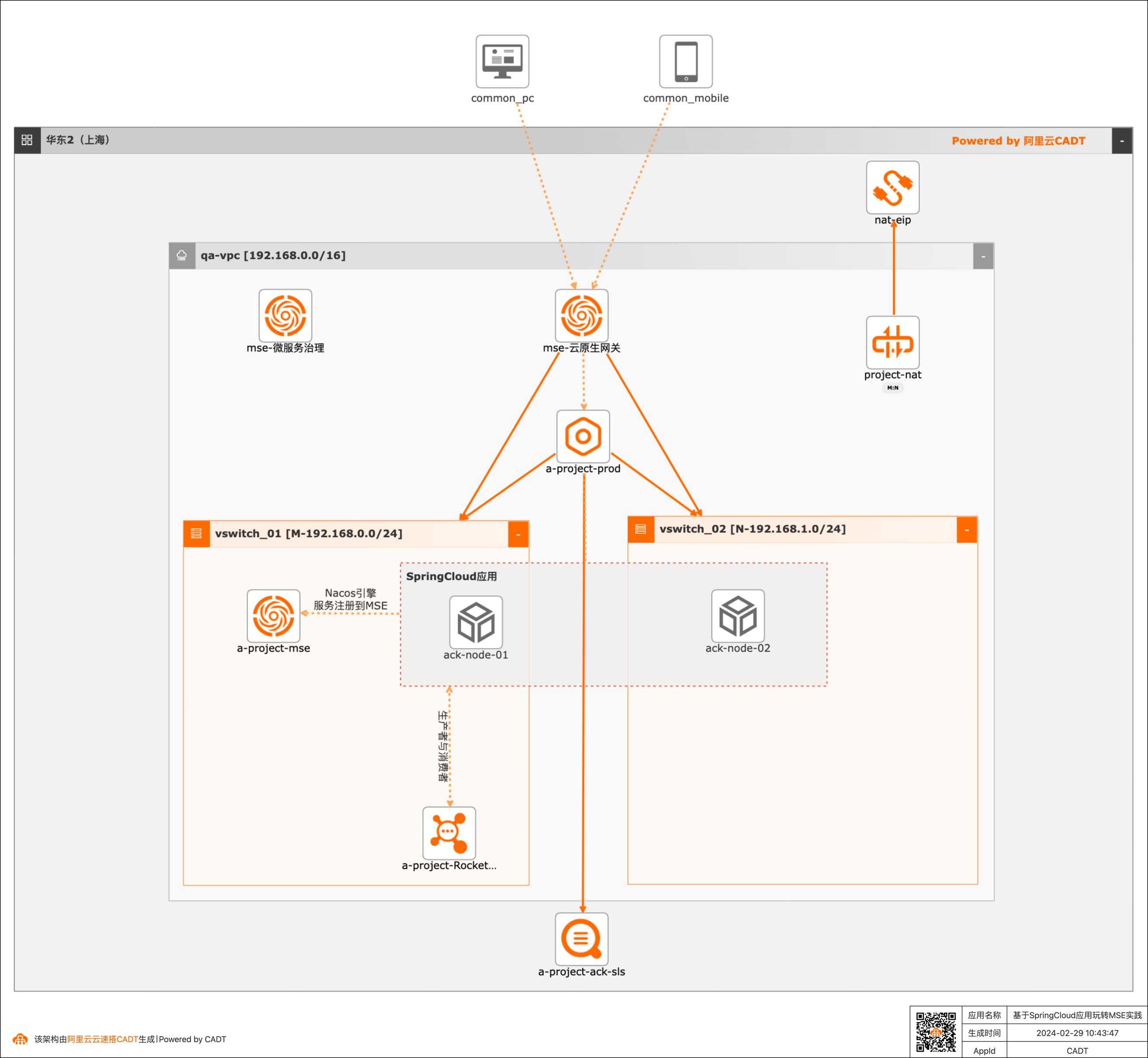
随着业务不断创新,大型的单个应用和服务会被拆分为数个甚至数十个微服务,微服务架构已经被广泛应用。 微服务的好处在于快速迭代,如何在迭代过程中保障线上流量不受损。依赖开源产品缺少无运维工具,常常需要投入较大的运维人力和成本。 本实践提供基于云原生应用产品提供微服务注册配置中心、微服务治理和云原生网关等一系列高性能和高可用的企业级云服务能力。
基于SpringCloud应用玩转MSE实践 业务架构 场景描述 随着业务不断创新,大型的单个应用和服务会被拆分为数 个甚至数十个微服务,微服务架构已经被广泛应用。微服 务的好处在于快速迭代,迭代过程保障线上流量不受损。依赖开源产品缺少专业运维工具,常常需要投入较大的运 维人力和成本。本实践基于云原生应用产品提供微服务...
基于DataWorks的大数据一站式开发及数据治理

概述 基于Dataworks做大数据一站式开发,包含数据实时采集到kafka通过实时计算对数据进行ETL写入HDFS,使用Hive进行数据分析。通过Dataworks进行数据治理,数据地图查看数据信息和血缘关系,数据质量监控异常和报警。 适用场景 日志采集、处理及分析 日志使用Flink实时写入HDFS 日志数据实时ETL 日志HIVE分析 基于dataworks一站式开发 数据治理 方案优势 大数据一站式开发,完善的数据治理能力。 性能优越:高吞吐,高扩展性。 安全稳定:Exactly-Once,故障自动恢复,资源隔离。 简单易用:SQL语言,在线开发,全面支持UDX。 功能强大:支持SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据源计算等Data Lake相关功能 ,以及各种流式及静态数据源关联查询。
自定义 HDFS Sink.47 文档版本:20201020 IV 基于 Dataworks的大数据一站式开发及数据治理 最佳实践概述 最佳实践概述 概述 本实践基于 Dataworks做大数据一站式开发,包含数据实时采集到 kafka通过实时计 算对数据进行 ETL写入 HDFS,使用 Hive进行数据分析。通过 Dataworks进行数据 治理,数据地图查看数据信息和血缘关系...
FastGPU极速AI训练/推理
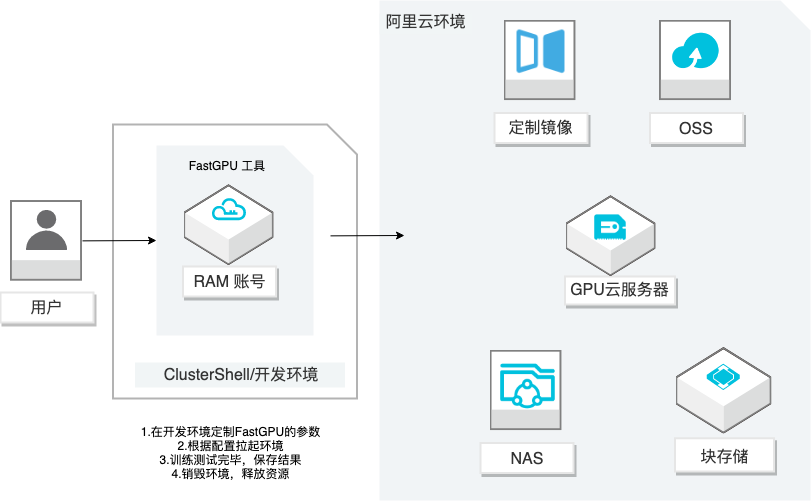
利用 FastGPU工具一键构建阿里云上的AI训练/推理环境,并使用AIACC加速工具进行加速。
FastGPU作为衔接⽤户线下⼈⼯智能算法和线上海量阿⾥云 GPU计算资源的关键⼀环,⽅ 便⽤户将⼈⼯智能算法计算⼀键构建在阿⾥云的 IAAS资源上,⽆需关⼼IAAS层相关的计 算、存储、⽹络等繁琐的部署操作,做到简单适配、⼀键部署,随处运⾏的效果。为⽤户提 供了省时、经济、便捷的基于阿⾥云 IAAS资源的⼈⼯智能即刻构建⽅案...
组建多可用区多地域的混合云

场景描述 无特定行业属性,对云下有IDC的用户,上云建 立多地域多可用区高稳定性的业务架构,组建混 合云用户都可适用。物理专线是打通IDC到云上 内网通道的最高质量和稳定性最好方式,但成本 较高,交付周期长。 解决问题 云下用户IDC应对业务突增弹性扩容能力 不足; 云下用户IDC业务需要多地域冗余; 云上阿里云业务需要多地域冗余; 云上阿里云业务需要多可用区冗余. 产品列表 VPC,CEN,高速通道(专线),SLB,ECS
开通云服务器 ECS、日志服务、函数计算等服务。说明:本文操作演示中不包含相关服务的开通操作,请您自行完成。文档版本:20210805 1 组建多可用区多地域的混合云最佳实践 创建北京区域 ECS 1.创建多地域 VPC,VSW,SLB和 CEN 1.1.使用云速搭 CADT快速创建资源 登录云速搭 CADT控制台。...
企业上云workshop
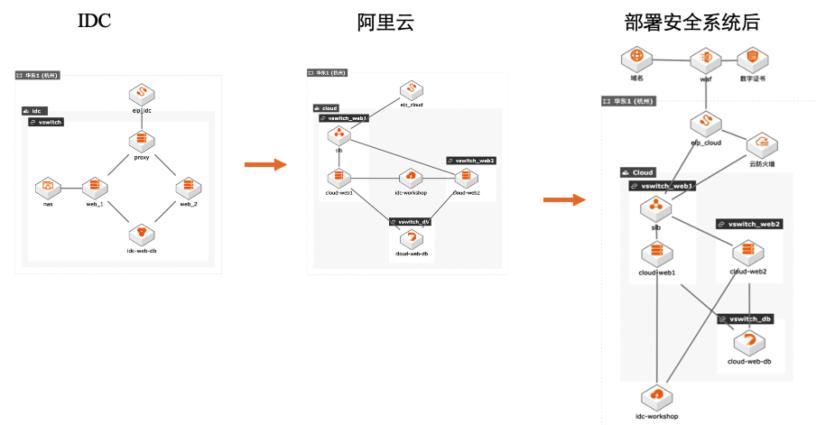
本文模拟了如下场景: 1. 线下 IDC 环境中部署了一个业务系统,业务是利用 wordpress 系统提供网站服务。 2. 本文详细介绍了如何将以上线下系统搬迁到云上, 包括如何在云上构建以上业务系统,如何迁移线下 系统到云上,如何割接。 3. 最后介绍了迁移上云后,如何部署安全系统。 解决问题 IDC 业务系统搬迁上云 云上构建业务系统 部署安全系统
兼容 POSIX 文件接口,可支持数千台计算节点共享访问,可以挂载到弹性 计算 ECS、神龙裸金属、容器服务 ACK、弹性容器 ECI、批量计算 BCS、高性能 计算 EHPC,AI训练 PAI等计算业务上提供高性能的共享存储,用户无需修改应 用程序,即可无缝迁移业务系统上云。更多信息,请参见云文件存储 NAS简介 ...
来自:
最佳实践
相关产品:专有网络 VPC,云服务器ECS,云数据库RDS MySQL 版,对象存储 OSS,负载均衡 SLB,弹性公网IP,文件存储NAS,云数据库PolarDB,Web应用防火墙,云防火墙,SSL证书,云速搭
基于Flink的资讯场景实时数仓
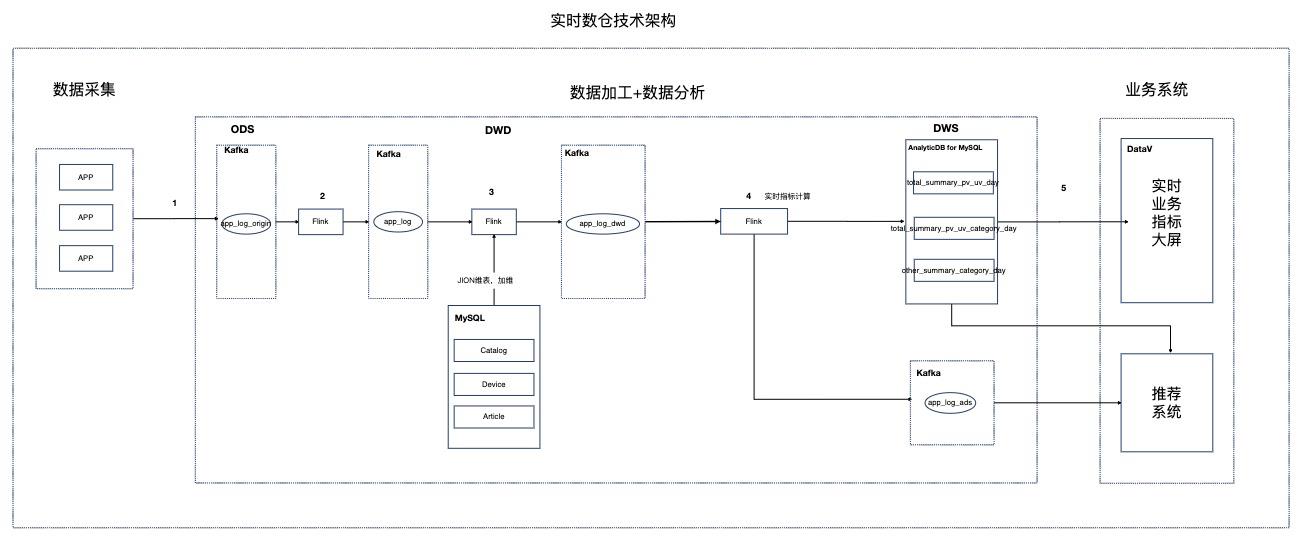
场景描述 本实践针对资讯聚合类业务场景,Step by Step介绍 如何搭建实时数仓。 解决问题 1.如何搭建实时数仓。 2.通过实时计算Flink实现实时ETL和数据流。 3.通过实时计算Flink实现实时数据分析。 4.通过实时计算Flink实现事件触发。 产品列表 实时计算 专有网络VPC 云数据库RDSMySQL版 分析型数据库MySQL版 消息队列Kafka 对象存储OSS NAT网关 DataV数据可视化
基于 Flink的资讯场景实时数仓 最佳实践 业务架构 场景描述 产品列表 本实践针对资讯聚合类业务场景,Step by Step介绍 实时计算 如何搭建实时数仓。专有网络 VPC 云数据库 RDS MySQL版 分析型数据库 MySQL版 解决问题 消息队列 Kafka 对象存储 OSS 1.如何搭建实时数仓。NAT网关 2.通过实时计算 Flink实现实时 ETL和数据流...
SLS多云日志采集、处理及分析
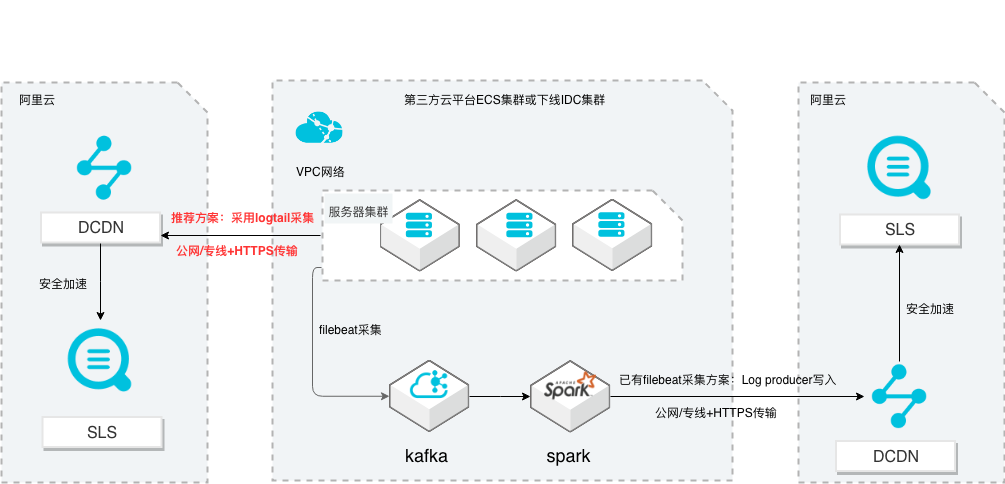
场景描述 从第三方云平台或线下IDC服务器上采集 日志写入到阿里云日志服务,通过日志服务 进行数据分析,帮助提升运维、运营效率, 建立DT 时代海量日志处理能力。 针对未使用其他日志采集服务的用户,推荐 在他云或线下服务器安装logtail采集并使用 Https安全传输;针对已使用其他日志采集 工具并且已有日志服务需要继续服务的情 况,可以通过Log producer SDK写入日志 服务。 解决问题 1.第三方云平台或线下IDC客户需要使用 阿里云日志服务生态的用户。 2.第三方云平台或线下IDC服务器已有完 整日志采集、处理及分析的用户。 产品列表 E-MapReduce 专有网络VPC 云服务器ECS 日志服务LOG DCDN
按照 2.5节的方式分别在日志机器组的两台 ECS实例开启日志发生器,等待数分钟 后停止 文档版本:20211203 76 SLS多云日志采集、处理及分析 日志服务器集群公网日志数据传递到日志服务 步骤15 查看日志库日志 回到日志服务控制台,选择创建的日志库 test20191009,可以看到日志机器组的日 志已经传递到日志服务:文档版本:...
自建Hadoop迁移MaxCompute
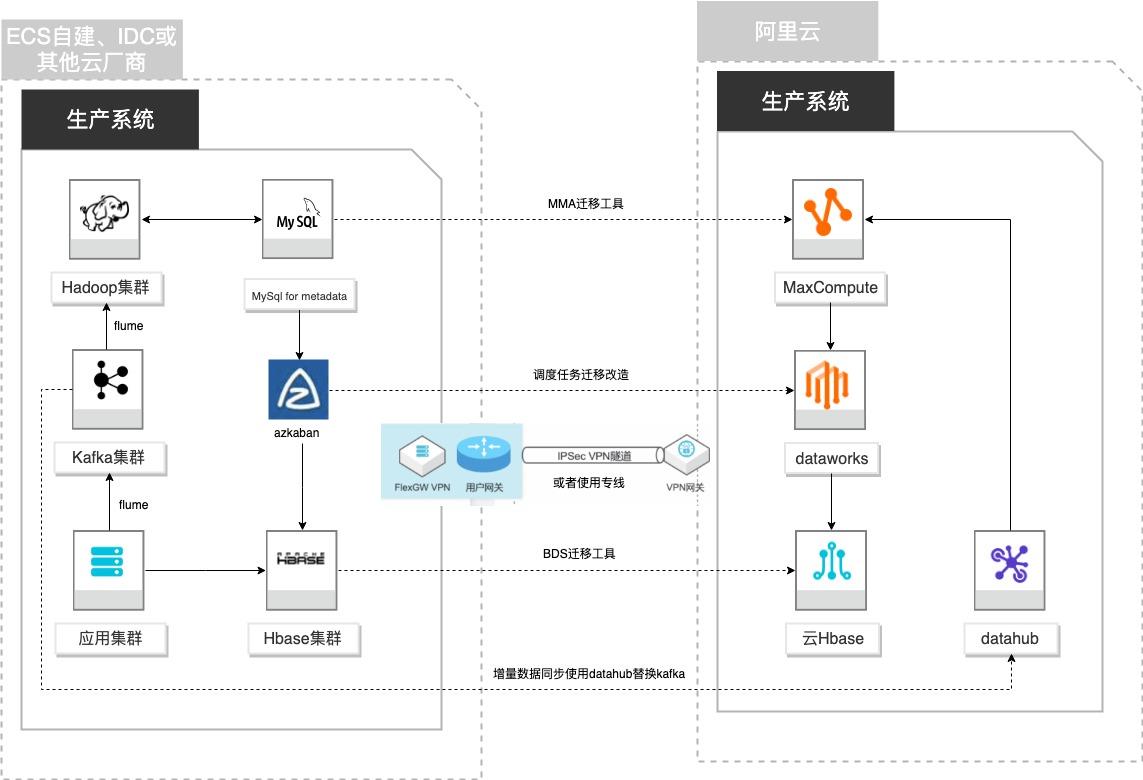
场景描述 客户基于ECS、IDC自建或在友商云平台自建了大数 据集群,为了降低企业大数据计算平台的成本,提高 大数据应用开发效率,更有效保障数据安全,把大数 据集群的数据、作业、调度任务以及业务数据库整体 迁移到MaxCompute和其他云产品。 解决的问题 自建Hadoop集群搬迁到MaxCompute 自建Hbase集群搬迁到云Hbase 自建Kafka或应用数据准实时同步到 MaxCompute 自建Azkaban任务迁移到Dataworks任务 产品列表 MaxCompute,Dataworks、云数据库Hbase版、Datahub、VPC,ECS。
自建 Hadoop迁移 MaxCompute 场景描述 解决的问题 客户基于ECS、IDC自建或友商自建了大数据集群,自建Hadoop集群搬迁到 MaxCompute 为了降低企业大数据计算平台的成本,提高大数 自建Hbase集群搬迁到云 Hbase 据应用开发效率,更有效保障数据安全,把大数据 自建 Kafka 或服务器数据实时同步到 集群的数据、作业、调度任务...
云上高并发系统改造
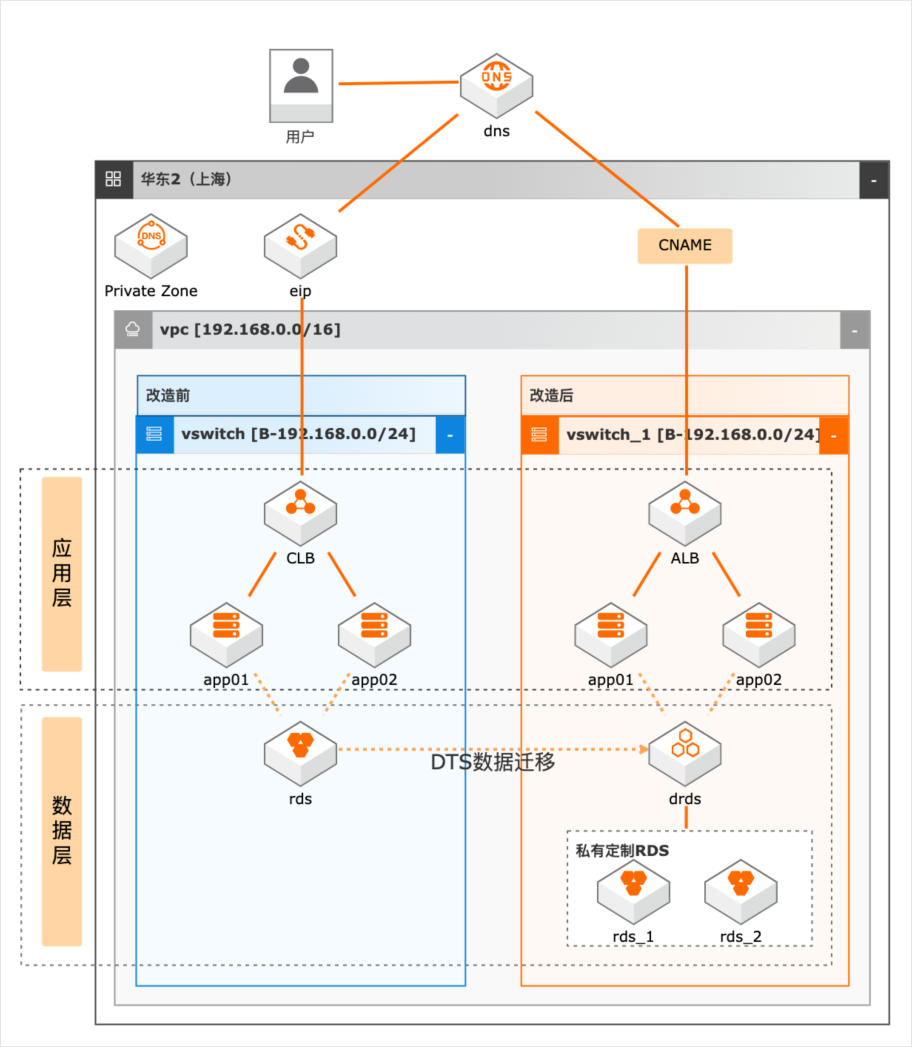
场景描述 随着业务的发展,系统并发压力越来越大,如何 进行系统改造以满足高并发场景的业务需求成 为了一个技术难题。本实践抽象于客户的实际场 景,提供高并发下系统改造的理论指导和部分实 操演示。主要适用于以下场景: 1.系统并发压力大,需要进行系统应用改造。 2.数据层并发压力大,需进行分库分表改造。 3.数据库数据量巨大,亟待分库分表解决查询 和写入瓶颈的场景。 方案优势/解决问题 1.在水平扩展阶段,我们除了通过SLB做负载 均衡外,我们可以通过SLB下挂nginx的方 式,增加负载均衡侧的可扩展性 2.在数据库拆分阶段,在做好数据规划后,我 们借助DTS进行数据迁移,通过DRDS将 RDS MySQL的数据拆分到多个分库和分 表中。 产品列表 专用网络VPC 负载均衡SLB 云服务器ECS 数据库RDSMySQL 数据传输服务DTS PrivateZone 分布式关系型数据库DRDS
DRDS 将拆分键值通过拆分函数计算得到一个计算结果,然后根据这个结果将数 据分拆到 RDS 实例上。5.3.2.主要数据表拆分原则和技巧 1.为业务服务。拆分首要是尽可能找到数据所归属的业务逻辑实体,并确定大部分(或核心的)SQL 操作或者具备一定并发的 SQL 都是围绕这个实体进行,然 后可使用该实体对应的字段作为拆分键;2....
RAPIDS加速机器学习
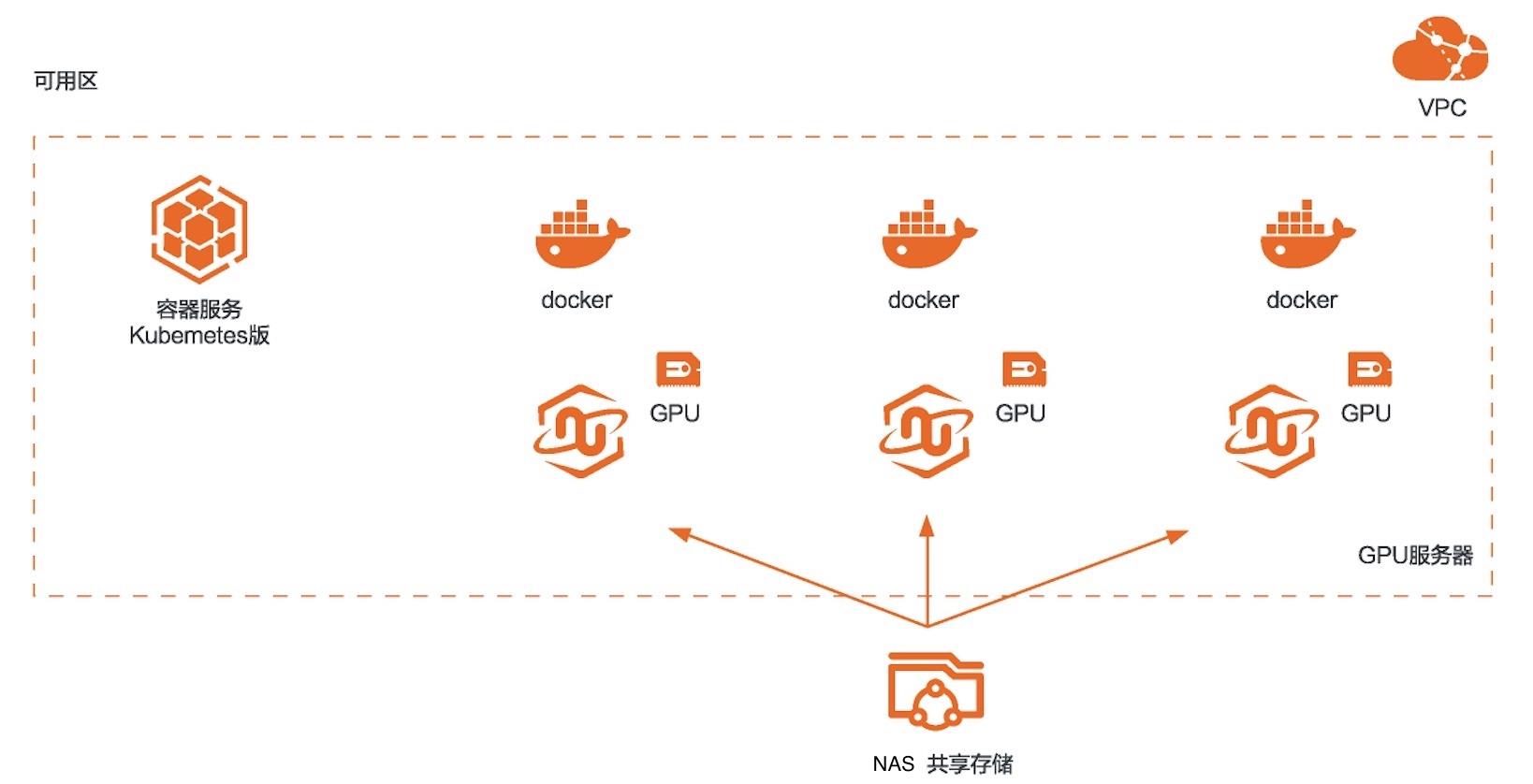
场景描述 本方案适用于使用RAPIDS加速库+GPU 云服务器来对机器学习任务或者数据科学 任务进行加速的场景。相比CPU,利用 GPU+RAPIDS在某些场景下可以取得非常 明显的加速效果。 解决问题 1.搭建RAPIDS加速机器学习环境 2.使用容器服务Kubernetes版部署 RAPIDS环境 3.使用NAS存储计算数据 产品列表 容器服务Kubernetes版 GPU云服务器 文件存储NAS
示例效果如下:•相关函数介绍 函数功能 函数名称 下载文件 def download_file_from_url(url,filename):解压文件 def decompress_file(filename,path):获取当前机器的 def get_gpu_nums():GPU个数 管理 GPU内存 def initialize_rmm_pool():def initialize_rmm_no_pool():def run_dask_task(func,*kwargs):提交 DASK任务 def...
数据湖-在线学习场景数据分析

场景描述 本场景以在线教育中一个答题闯关类的应用为 例,使用WebServer来模拟演示这类日志数据 的分析处理。通过Nginx和Pythonflask搭建 WebServer,模拟应用中的关键页面,比如登 录、课程内容等,之后构造若干用户使用的模拟 日志数据,投递到数据湖进行分析后获取应用 PV、UV、课程内容访问排行、平均得分等等。 解决问题 基于数据湖(EMR+OSS)搭建大数据平台。 EMR和OSS使用和配置。 数据统一存储到OSS。 产品列表 E-MapReduce 对象存储OSS 云服务器ECS 访问控制RAM 专有网络VPC
应用场景 步骤1 首先在webserver上安装java#安装jdk sudoyum-yinstalljava-11-openjdk*#配置环境变量 cat>>/etc/profile:/root/ssh登录到EMRHadoop 集群的Master节点,执行命令:cd hadoopfs-mkdirjfs:/datalake/lib/hadoopfs-putnginx_url_parse-1.0.jarjfs:/datalake/lib/步骤4 进入Hive交互环境,新建函数nginx_url_...
自建Hive数仓迁移到阿里云EMR
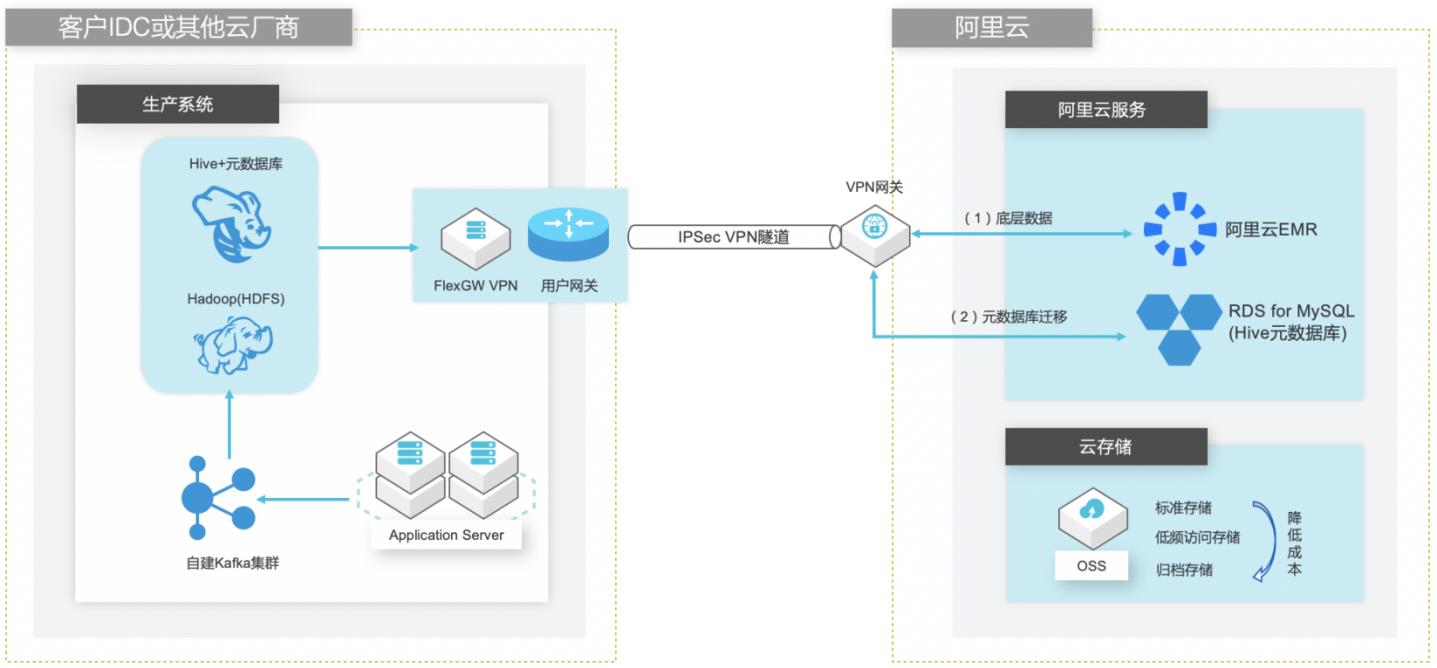
场景描述 客户在IDC或者公有云环境自建Hadoop集群构 建数据仓库和分析系统,购买阿里云EMR集群之 后,涉及到将数据仓库和Hive元数据的数据库迁 移上云。目前主流Hive数据仓库迁移场景为1.x 版本迁移到阿里云EMR(Hive2.x版本),涉及到 数据订正更新步骤。 解决的问题 Hive数据仓库的数据迁移方案 Hive元数据库的迁移方案 Hive跨版本迁移后的数据订正 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
深度整合 E-MapReduce 与阿里云其它产品(例如,OSS、MNS、RDS 和 MaxCompute 等)进行了深度整合,支持以这些产品作为 Hadoop/Spark计算引擎的输入源或者 文档版本:20210721 1 自建Hive数据仓库跨版本迁移到阿里云 EMR 最佳实践概述 输出目的地。安全 E-MapReduce整合了阿里云 RAM资源权限管理系统,通过主子账号对服务...
Openstack迁移DDH
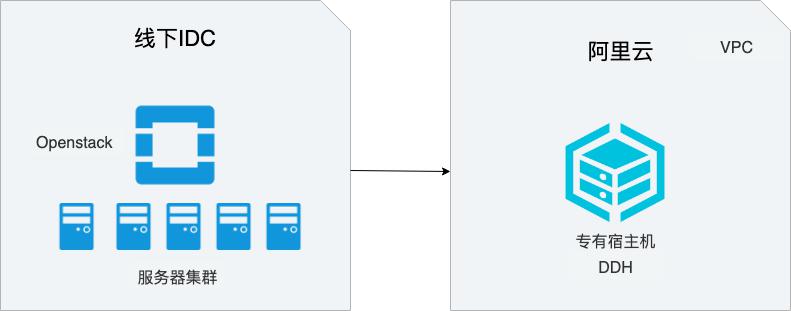
场景描述 在线下IDC中,很多用户使用OpenStack构建云环境,本 文介绍如何将线下IDC中基于OpenStack构建的云服务器 迁移到阿里云专有宿主机(DDH)上,从而实现业务平滑 上云的同时,显著降低成本。 解决问题 1.如何将OpenStack中的云服务器迁移 DDH上。 2.如何使用DDH构建云上环境。 产品列表 专有宿主机DDH 对象存储OSS 服务器迁移中心SMC 专有网络VPC
keys.sh INFO copy_openrc.sh->03_copy_openrc.sh INFO apt_install_mysql.sh->04_apt_install_mysql.sh INFO install_rabbitmq.sh->05_install_rabbitmq.sh INFO install_memcached.sh->06_install_memcached.sh INFO setup_keystone.sh->07_setup_keystone.sh INFO get_auth_token.sh->08_get_auth_token.sh INFO setup_...
通义灵码助力函数计算FC实现函数编写

现在社会软件开发的复杂性不断增加,服务器配置和运维管理更复杂、开发效率变低。函数计算FC采用无服务器计算模式,用户只需要关注业务逻辑的实现,无需关心底层的服务器配置和运维管理,从而大大降低了运维成本和复杂性,而且具有弹性伸缩、快速部署、按需使用按量付费的特点。通义灵码是阿里云出品的一款基于通义大模型的智能编码辅助工具,可以帮助开发者快速编写高质量的代码,为开发者提供了强大的编程辅助功能。两者的结合让开发者可以更高效地编写函数代码,简化部署流程,提高开发效率。
产品列表 钉钉搜索钉群号31852400入群 阿里云函数计算(FC) 通义灵码通义灵码助力函数计算FC 实现函数编写 最佳实践 文档版本:20240513通义灵码助力函数计算FC实现函数编写 文档版本信息 文档版本信息 文档信息 属性 内容 文档名称 通义灵码助力函数计算FC实现函数编写 文档编号 386 文档版本 V1.0 版本日期 2024-05-...
基于函数计算FC镜像部署Stable Diffusion大模型
在现代AI应用中, Stable Diffusion等模型因其强大的功能而受到关注。然而,这些模型对计算资源的高需求和复杂的运维管理成为部署时的挑战。基于函数计算FC的无服务器计算模式为这类模型的部署提供了全新的解决方案。用户只需关注模型的部署和调用逻辑,而无需关心底层的服务器配置、资源分配和扩展性等问题。函数计算FC能够自动处理函数的执行环境,包括冷启动、弹性伸缩等,确保模型能够在大规模的请求下稳定运行。
基于函数计算 FC镜像部署 Stable Diffusion大模型 最佳实践 业务架构 场景描述 在现代 AI应用中,Stable Diffusion等模型因其 强大的功能而受到关注。然而,这些模型对计算资 源的高需求和复杂的运维管理成为部署时的挑战。基于函数计算 FC的无服务器计算模式为这类模型的 部署提供了全新的解决方案。用户只需关注模型的 ...
基于函数计算FC实现大语言模型部署

在现代AI应用中, Qwen /chatglm2-6b 和Stable Diffusion等模型因其强大的功能而受到关注。然而,这些模型对计算资源的高需求和复杂的运维管理成为部署时的挑战。基于函数计算FC的无服务器计算模式为这类模型的部署提供了全新的解决方案。用户只需关注模型的部署和调用逻辑,而无需关心底层的服务器配置、资源分配和扩展性等问题。函数计算FC能够自动处理函数的执行环境,包括冷启动、弹性伸缩等,确保模型能够在大规模的请求下稳定运行。
基于函数计算 FC实现大语言模型部署最佳实践 业务架构 方式一:魔搭 SwingDeploy模型到 FC 方式二:FC3.0应用模板部署 场景描述 在现代 AI应用中,Qwen/chatglm2-6b等社区模型因其强大的功能而受到关注。然而,这些模型对计算 资源的高需求和复杂的运维管理成为部署时的挑战。基于函数计算 FC的无服务器计算模式为这类模型...
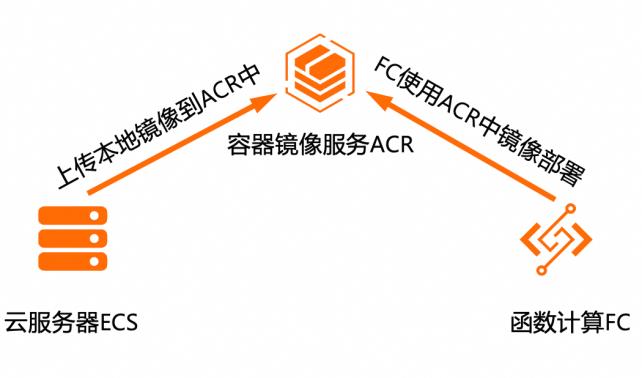
基于函数计算FC实现阿里云Kafka消息轻量级ETL处理
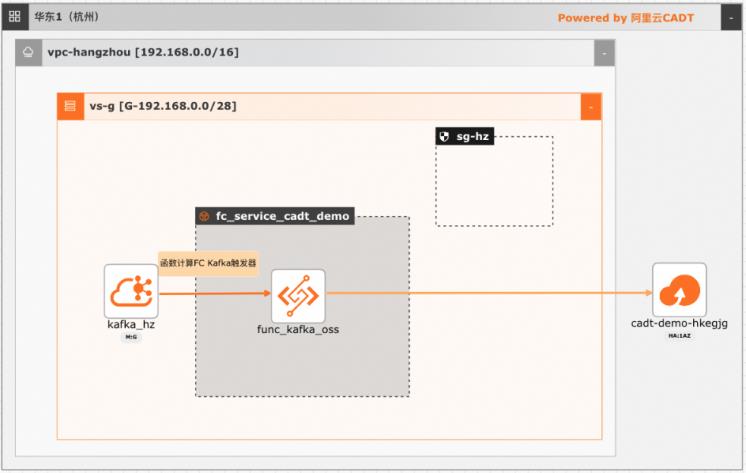
在大数据ETL场景,Kafka是数据的流转中心,Kafka中的数据一般是原始数据,可能存在多种数据混杂的情况,需要进一步做数据清洗后才能进行下一步的处理或者保存。利用函数计算FC,可以快速高效的搭建数据处理链路,用户只需要关注数据处理的逻辑,数据的触发,弹性伸缩,运维监控等阿里云函数计算都已经做了集成,函数计算FC也支持多种下游,OSS/数据库/消息队列/ES等都可以自定义的对接
文档版本:20240408 14 基于函数计算 FC实现阿里云 Kafka消息轻量级 ETL处理 场景验证 资源开始进行下单购买,请耐心等待资源创建 进入部署阶段后,请耐心等待,这里浏览器关闭或者电脑出现异常不会影响部署。文档版本:20240408 15 基于函数计算 FC实现阿里云 Kafka消息轻量级 ETL处理 场景验证 等待资源创建完成,可以...
基于函数计算实现直播流录制-存储-通知
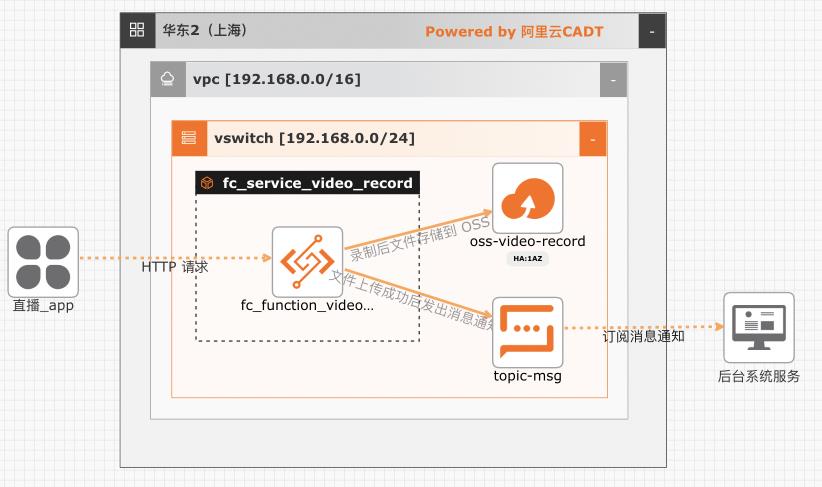
在互娱、教育、电商等行业都会有直播相关的业务,大部分场合都需要对直播相关的业务做安全审核,或者对直播的课程进行录制和转码。该方案实现了一种完全按需拉起、按量弹性、按实际使用付费的录制方案。基于本方案还可以扩展实现直播流截帧、自动化安全审核等能力
阿里云函数计算(FC)•完全按量付费,有效节省使用成本。阿里云对象存储(OSS)•灵活的自定义扩展能力,视频截帧、转码等。阿里云消息服务 MNS(Message Service)云速搭 CADT 最佳实践频道 http://bp.aliyun.com 阿里云最佳实践分享群 钉钉搜索钉群号 31852400入群 函数计算 FC用户交流群 钉钉搜索钉群号 11721331入群 ...
- 产品推荐
- 这些文档可能帮助您