Openstack迁移DDH
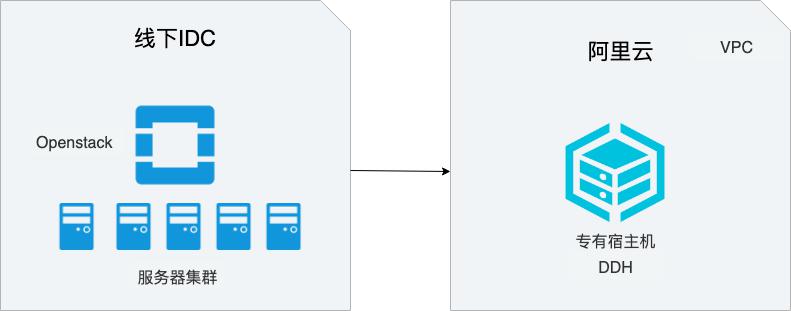
场景描述 在线下IDC中,很多用户使用OpenStack构建云环境,本 文介绍如何将线下IDC中基于OpenStack构建的云服务器 迁移到阿里云专有宿主机(DDH)上,从而实现业务平滑 上云的同时,显著降低成本。 解决问题 1.如何将OpenStack中的云服务器迁移 DDH上。 2.如何使用DDH构建云上环境。 产品列表 专有宿主机DDH 对象存储OSS 服务器迁移中心SMC 专有网络VPC
2.创建实例和镜像(第3章)文档版本:20200312(发布日期)4 Openstack迁移DDH OpenStack简介 本章在搭建好的OpenStack环境中,创建cirros实例,然后需要停止cirros实例,制作实例的快照快照,最后将快照转换成raw格式并下载到本地。3.镜像检查与修改(第4章)在将镜像导入阿里云之前,需要检查raw格式镜像,如有必要做相应...
VMware迁移DDH

场景描述 介绍本地部署或托管在IDC环境的VMware系统迁移 上云至独立宿主机(DDH)的最佳实践。使用DDH在 云端构建由独享物理服务器组成的资源池,同时配合 ECS成熟稳定的虚拟化技术体系,充分利用云上资源 弹性、按使用付费的优势,快速构建高性能、高可靠 和可快速动态伸缩的虚拟化系统,满足安全、合规、 自定义部署、自带许可证(BYOL)等企业级需求。 解决问题 l云端独享高性能、高可靠、高弹性的物理服务器资源池。 l基于成熟云原生虚拟化技术体系,支持ECS自定义部 署,可在DDH环境和多租户环境间迁移。 l支持自带许可证(BYOL)。 产品列表 l访问控制RAM l专有网络VPC l云服务器ECS l对象存储OSS l专有宿主机DDH l资源编排ROS
文档版本:20200218 1 企业上云实践 VMware 迁移 DDH|演示环境说明 演示环境说明 本文档所有产品均使用华东 2区域资源进行演示,实际操作中请留意区域选择。产品或服务 本文示例 备注 OSS 按量付费 bucket 自定义镜像导入存储 RAM 迁移账号 RAM 用户 按量付费 ECS ecs.v5-c1m4.8xlarge ecs.c5.xlarge 按量付费 DDH 超分型 ...
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
su-hadoop schematool-dbType mysql-upgradeSchemaFrom 1.2.0 说明:其中 1.2.0表示从哪个版本开始进行 schema升级,本方案中源 Hive版本为 1.2.2,因此选用 1.2.0作为源版本。执行结果如下图所示:文档版本:20210425 35 自建 Hive数据仓库跨版本迁移到阿里云 Databricks数据洞察 Hive数据迁移 步骤2 配置 hive-env.sh启动...
- 产品推荐
- 这些文档可能帮助您