可观测链路 OpenTelemetry 版
针对 PHP、C++、Go、Node.js 等多语言应用,提供端到端全链路追踪、应用监控与告警、链路拓扑、日志关联分析能力,并基于 OpenTelemetry 开源标准,兼容 Jaeger、Zipkin、SkyWalking 等开源项目数据上报。快速发现分布式应用架构下的性能瓶颈,缩短错/慢调用根因定位耗时,提高全栈开发与诊断效率。
多语言类应用统一基于 OpenTelemetry 标准接入,从而对所有接入的应用进行统一的监控告警,提供应用、接口、主机地址等多维度监控能力,并提供开箱即用的默认监控大盘。同时通过调用关系动态发现与渲染全局服务拓扑。针对业务场景的自定义需求,支持根据既有数据源自定义指标监控大盘.多语言应用性能监控及全局可视化.多...
来自:
云产品
函数计算FC
阿里云函数计算(Function Compute)是一个事件驱动的全托管计算服务。通过函数计算,您无需管理服务器等基础设施,只需编写代码并上传。函数计算会为您准备好计算资源,以弹性、可靠的方式运行您的代码。更棒的是,您只需要为代码实际运行消耗的资源付费,代码未运行则不产生费用。
函数计算 GPU 降幅高达 93%,阶梯计费越用越便宜.快速部署 Hello World/To do List应用/Hexo博客.介绍实例类型、免费额度、计费项、单价和计费示例.成本节省 50%,使用函数计算开发 Web 应用更高效!轻量灵活、更易集成、AI开发更简单.玩转AI绘画,函数计算一键部署 Stable Diffusion.AI应用开发:Stable Diffusion API ...
来自:
云产品
应用实时监控服务ARMS
作为云原生可观测平台,应用实时监控服务 ARMS 包含前端监控、应用监控、云拨测等模块。覆盖浏览器、小程序、APP、分布式应用、容器等不同可观测环境与场景。帮助企业实现全栈性能监控与端到端追踪诊断。提高监控效率,压降运维工作量。
针对容器服务ACK、消息队列 Kafka 等主流云服务,提供 Grafana Pro 大盘,帮助运维进行更精细化指标观测.云服务统一接入.可观测监控 Prometheus 版.可观测可视化 Grafana 版.云服务统一监控.针对多数据源进行统一管理,实现端到端的可观测数据统一展现.默认集成阿里云云服务、SQL 数据库、时序数据库、日志数据、链路数据、...
来自:
云产品
实时计算Flink版
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,具备实时应用的作业开发、数据调试、运行与监控、自动调优、智能诊断等全生命周期能力。内核引擎100%兼容Apache Flink,2倍性能提升,拥有FlinkCDC、动态CEP等企业级增值功能,内置丰富上下游连接器,助力企业构建高效、稳定和强大的实时数据应用。
一站式开发管理平台,包括SQL/Java/Scala/Python\\u00A0语言.支持主流\\u00A0Flink\\u00A0版本,包括多版本作业代码比较和回滚.内置统一元数据管理,并可无缝对接外部元数据系统.内置多个领域函数库,并可按需自定义函数.提供20多个Flink\\u00A0SQL常见通用场景的模版.支持线上采样和模拟测试数据管理.基于Session集群实现...
来自:
云产品
EMR集群安全认证和授权管理
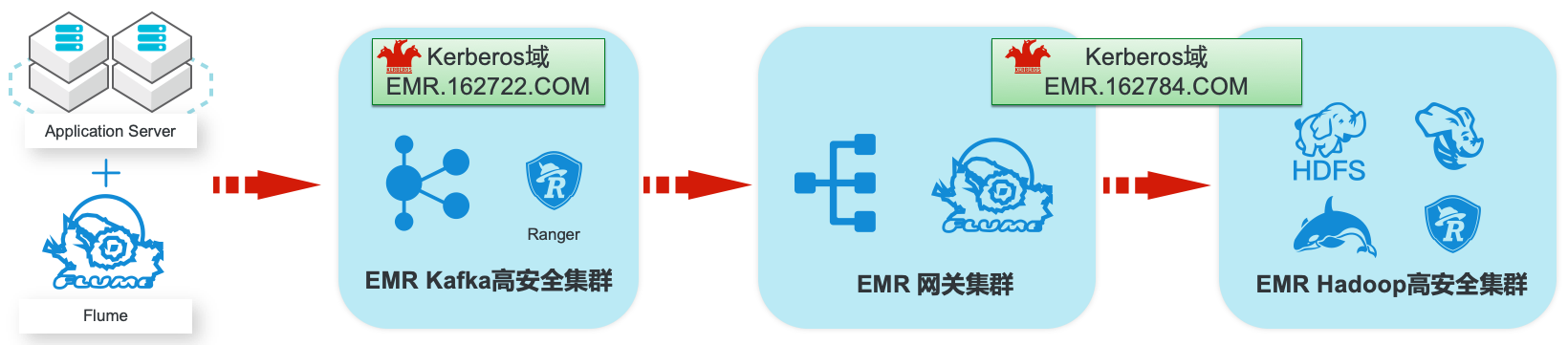
场景描述 阿里云EMR服务Kafka和Hadoop安全集群使 用Kerberos进行用户安全认证,通过Apache Ranger服务进行访问授权管理。本最佳实践中以 Apache Web服务器日志为例,演示基于Kafka 和Hadoop的生态组件构建日志大数据仓库,并 介绍在整个数据流程中,如何通过Kerberos和 Ranger进行认证和授权的相关配置。 解决问题 1.创建基于Kerberos的EMR Kafka和 Hadoop集群。 2.EMR服务的Kafka和Hadoop集群中 Kerberos相关配置和使用方法。 3.Ranger中添加Kafka、HDFS、Hive和 Hbase服务和访问策略。 4.Flume中和Kafka、HDFS相关的安全配 置。 产品列表:E-MapReduce、专有网络VPC、云服务器ECS、云数据库RDS版
数据 Masking类型如下表所示,并应用到列:Select Masking Option 说明 应用到列 用“x”屏蔽所有字母字符,并用“n”屏 status Redact 蔽所有数字字符 accesstime Partial mask:show last 4 部分屏蔽:仅显示最后 4个字符 ipaddr Partial mask:show first 4 部分屏蔽:仅显示最初 4个字符 request Hash 将所有字符替换为...
自建Hive数仓迁移到阿里云EMR
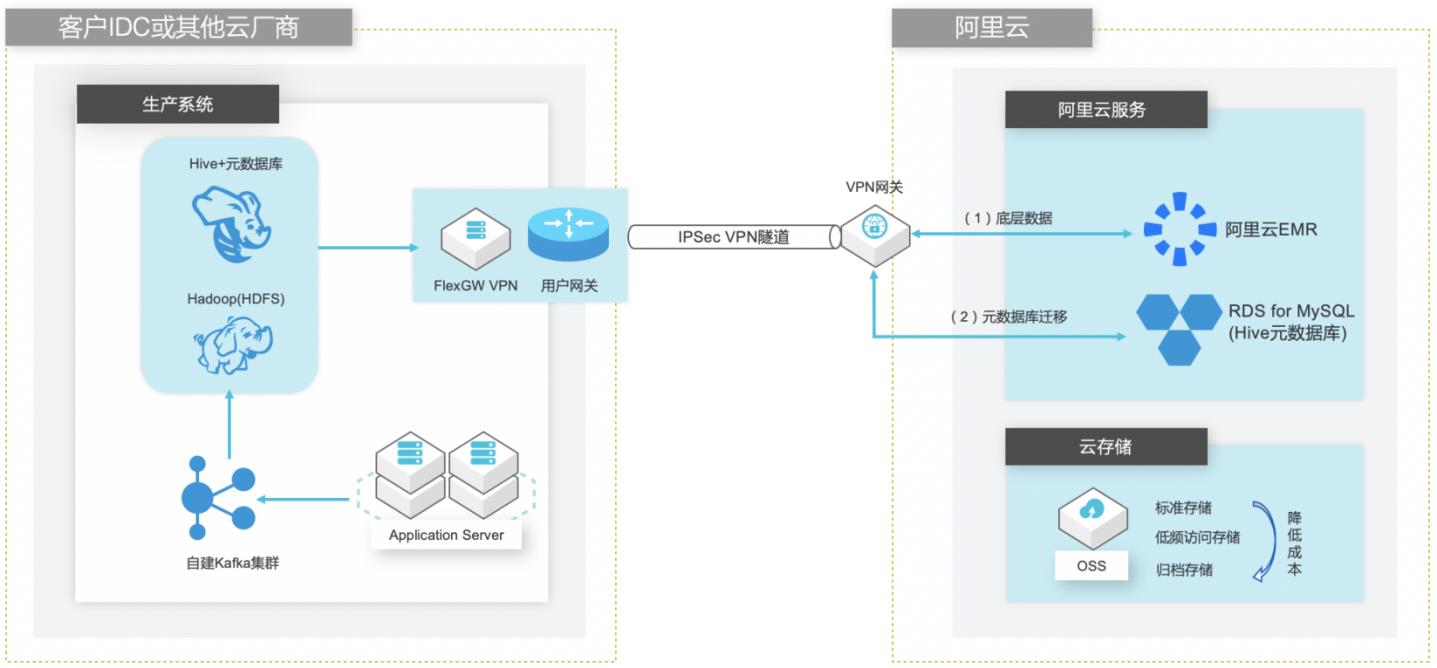
场景描述 客户在IDC或者公有云环境自建Hadoop集群构 建数据仓库和分析系统,购买阿里云EMR集群之 后,涉及到将数据仓库和Hive元数据的数据库迁 移上云。目前主流Hive数据仓库迁移场景为1.x 版本迁移到阿里云EMR(Hive2.x版本),涉及到 数据订正更新步骤。 解决的问题 Hive数据仓库的数据迁移方案 Hive元数据库的迁移方案 Hive跨版本迁移后的数据订正 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
11217 CTAS statements throws error,when the table is stored as ORC File format and select clause has NULL/VOID type column.(CTAS不指定列的具体类型会报错)文档版本:20210721 39 自建Hive数据仓库跨版本迁移到阿里云 EMR 注意事项 HIVE-12574 windowing function returns incorrect result when the window size...
Spring Cloud Netflix应用迁移EDAS
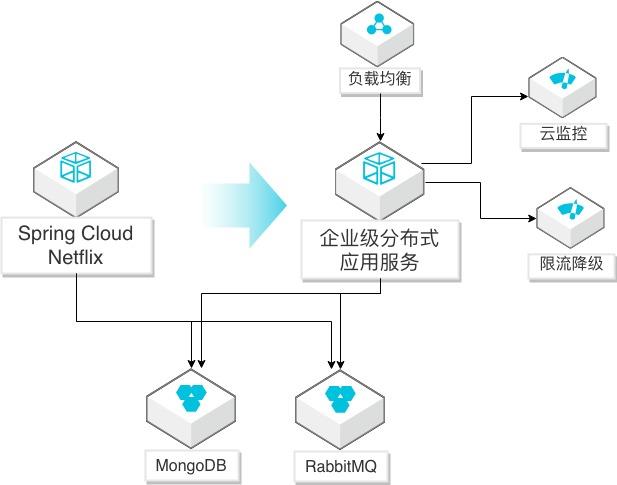
场景描述 Spring Cloud Netflix微服务应用迁移到EDAS 服务(SpringCloud Alibaba云版本)的方法, 迁移后充分利用阿里云监控、调用链、限流降级 等能力,优化应用生命周期管理。 解决问题 1.帮助自建SpringCloudNetflix微服务应用 通过简单修改迁移到阿里云企业级分布式 应用服务(EDAS)平台。 2.迁移到EDAS后,简化应用的运维,提升监 控、调用链探测、限流降级等管理能力,提 高对应用的全生命周期管理。 产品列表 企业级分布式应用服务(EDAS) 负载均衡(SLB) 专有网络(VPC) 云服务器(ECS)
如果应用状态不正常,可以单击应用名称,选择实例部署信息页签,单击对应实例操 作列下的日志,查看部署日志。查看日志的页面如下图所示:选择下面日志,查看具体日志报错信息。步骤13 修改 ECS白名单。1.为了确保各个微服务之间的网络连接,请打开 4000到 9000端口的通讯信息。单 击需要设定白名单的 ECS。文档版本:...
自建Hadoop迁移MaxCompute
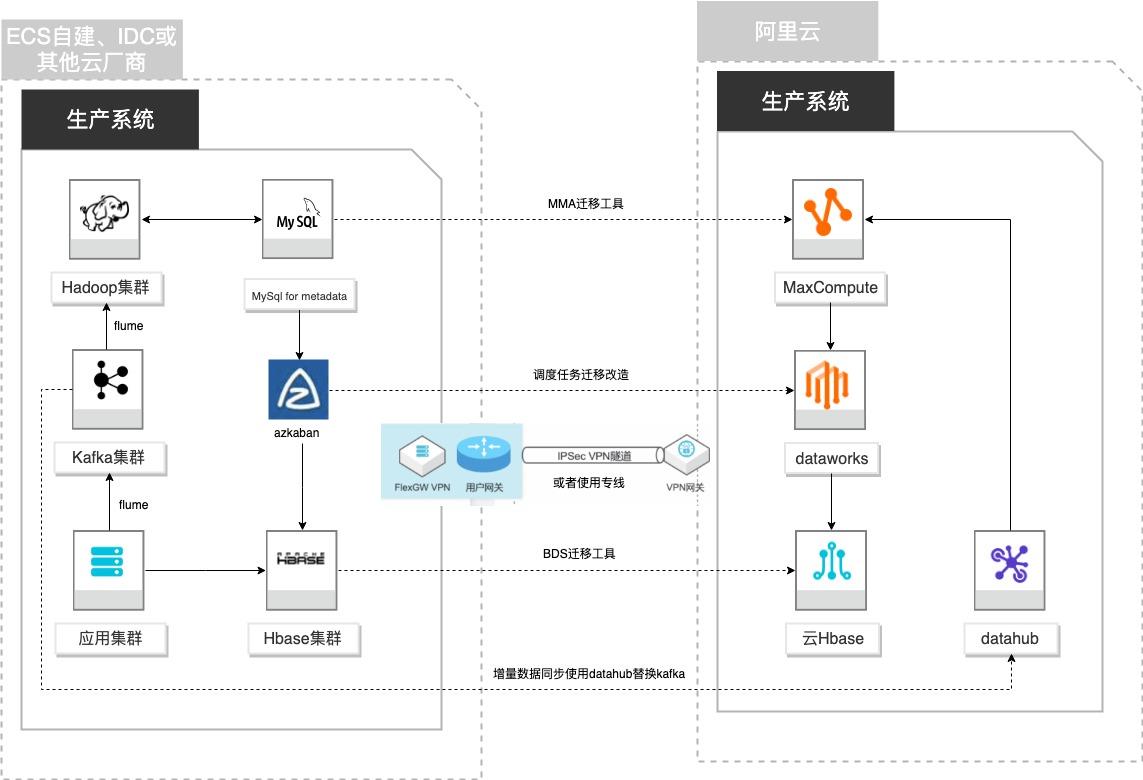
场景描述 客户基于ECS、IDC自建或在友商云平台自建了大数 据集群,为了降低企业大数据计算平台的成本,提高 大数据应用开发效率,更有效保障数据安全,把大数 据集群的数据、作业、调度任务以及业务数据库整体 迁移到MaxCompute和其他云产品。 解决的问题 自建Hadoop集群搬迁到MaxCompute 自建Hbase集群搬迁到云Hbase 自建Kafka或应用数据准实时同步到 MaxCompute 自建Azkaban任务迁移到Dataworks任务 产品列表 MaxCompute,Dataworks、云数据库Hbase版、Datahub、VPC,ECS。
Kafka迁移到 Datahub 步骤5 预览数据 文档版本:20210723 48 自建Hadoop迁移MaxCompute Azkaban定时任务迁移和改造 6.Azkaban定时任务迁移和改造 本实践方案中,自建 Hadoop集群的数据的流向如下所示:日志发生器→Kafka队列→HDFS文件系统→Azkaba任务 01执行→Hive表 apache_logs→Azkaba任务 99执行→Hbase表 job99_ip_...
SLS数据入湖Kafka最佳实践
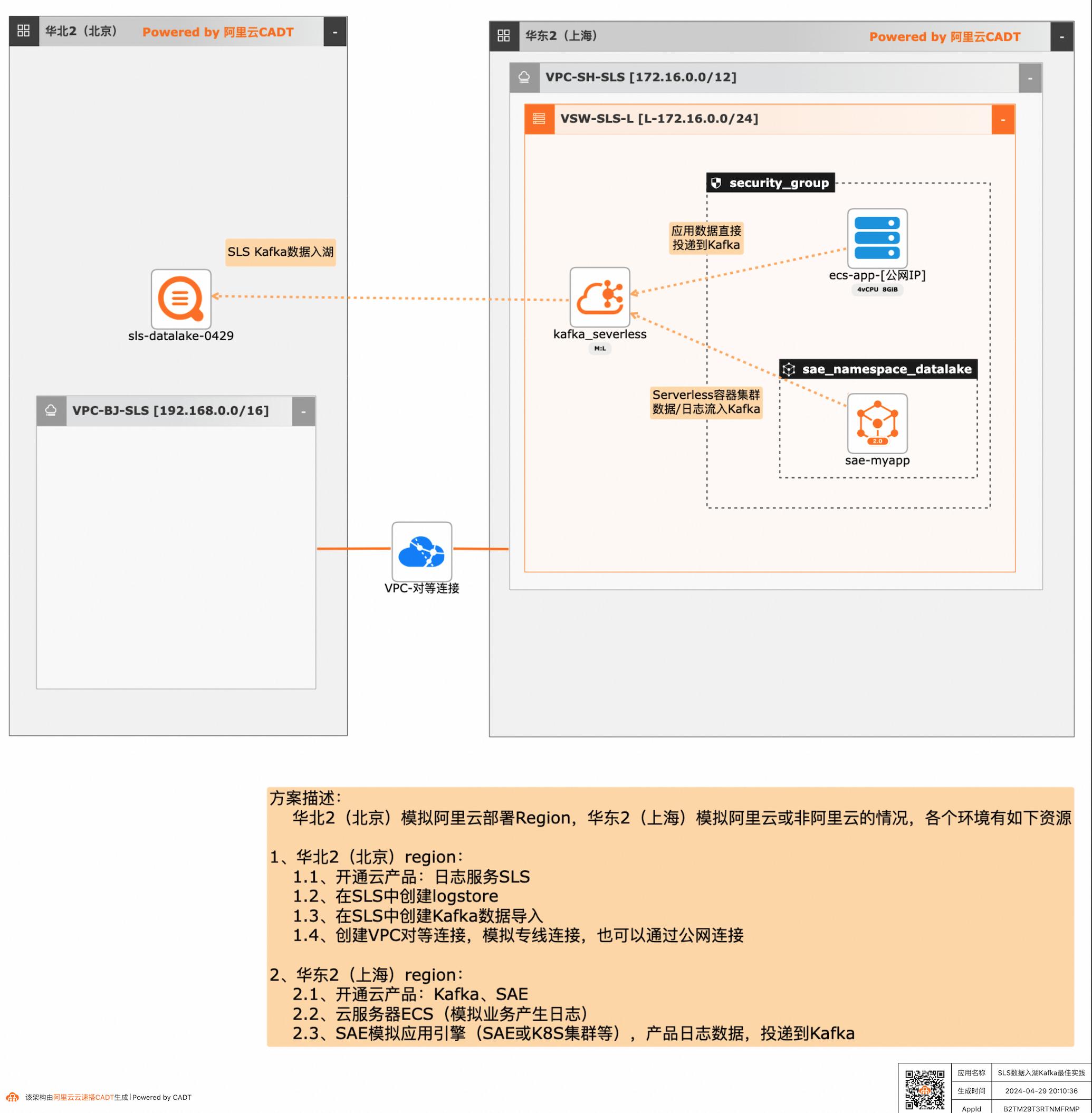
应用和数据分散在多云或混合云,在面对多云/混合云这样大的趋势下,数据无法进行统一的聚合、分析处理和导出等,本方案给出了在多云/混合云场景下,构建通过标准的Kafka协议和托管服务,SLS可以连接Kafka数据入湖导入,然后进行统一的海量数据的集中存储、智能转储、聚合分析查询等。
确认订单阶段会列出架构中所有的产品及其价格,需要用户确认无误后勾选接受《云 速搭服务条款》,此时下一步:支付并创建才会高亮,可以单击进行实际的资源购买 和部署。文档版本:20240428 12SLS数据入湖Kafka最佳实践 部署基础环境 步骤14 进入部署页面,过程中可切换到产品控制台查看资源创建情况,资源创建完成预 计...
基于函数计算FC实现阿里云Kafka消息轻量级ETL处理
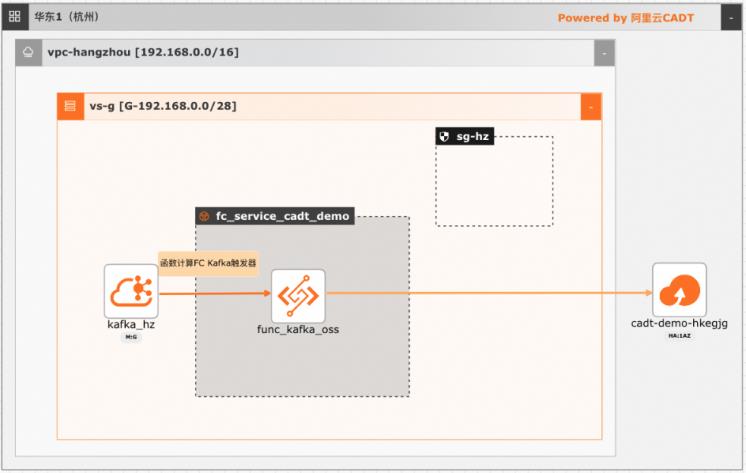
在大数据ETL场景,Kafka是数据的流转中心,Kafka中的数据一般是原始数据,可能存在多种数据混杂的情况,需要进一步做数据清洗后才能进行下一步的处理或者保存。利用函数计算FC,可以快速高效的搭建数据处理链路,用户只需要关注数据处理的逻辑,数据的触发,弹性伸缩,运维监控等阿里云函数计算都已经做了集成,函数计算FC也支持多种下游,OSS/数据库/消息队列/ES等都可以自定义的对接
利用函数计算 FC,可以快速高效的搭建数据处理链路,用户只需要 关注数据处理的逻辑,数据的触发,弹性伸缩,运维监控等阿里云函数计算都已经做了集成,函 产品列表 数计算 FC也支持多种下游,OSS/数据库/消息队 列/ES等都可以自定义的对接。专有网络 VPC 阿里云交换机 解决问题 阿里云安全组•快速搭建起数据处理全链路 ...
基于函数计算FC实现企业级权限精准控制Kafka跨实例消息同步
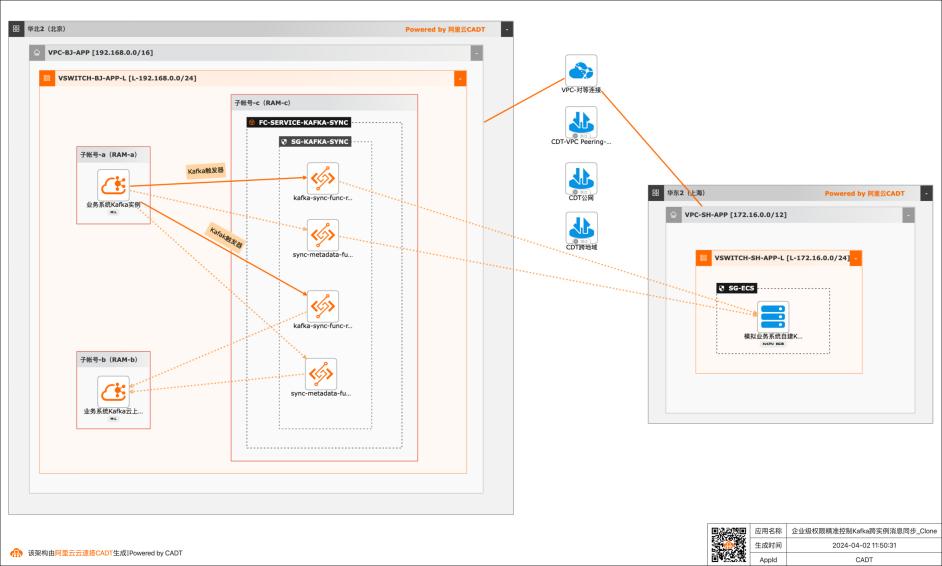
应用场景 在大数据场景,企业的Kafka实例可能存在多种情况,比如使用阿里云Kafka服务,可能是自建开源Kafka,或者是其他云上的云Kafka。不同的业务使用不同类型的Kafka实例,在这个前提下Kafka实例之间可能会需要消息同步的情况: 同帐号容灾场景:比如Kafka实例都是阿里云Kafka,但是Kafka实例会有主备之分,需要将主Kafka实例的消息实时同步到备Kafka。 跨帐号或异地容灾:这类场景比如主Kafka是阿里云Kafka,备Kafka是IDC开源自建Kafka,或者是其他云上的Kafka。 不同业务之间消息同步:因为现在的业务通常不会是信息孤岛,都需要消息互通,所以可能是A业务的Kafka实例消息需要同步到B业务的Kafka实例,并且这两个Kafka实例归属不同的RAM角色,有自己独自的权限控制。 解决问题 解决使用开源组件做消息同步的高成本问题。 解决使用开源组件做消息同步的并发性能、稳定性问题。 解决使用开源组件做消息同步的可靠性问题(重试机制,容错机制,死信队列等)。 大幅提升构建消息同步架构的效率,降低构建复杂度问题。
步骤30确认订单阶段会列出架构中所有的产品及其当天价格,需要用户确认无误后勾选接受《云速搭服务条款》,此时下一步:支付并创建才会高亮,可以单击进行实际的资源购 买和部署。文档版本:20240330 23基于函数计算FC实现企业级权限精准控制Kafka跨实例消息同步 部署基础环境 步骤31资源开始进行下单购买,请耐心等待资源...
基于函数计算FC实现阿里云Kafka消息内容控制MongoDB DML操作
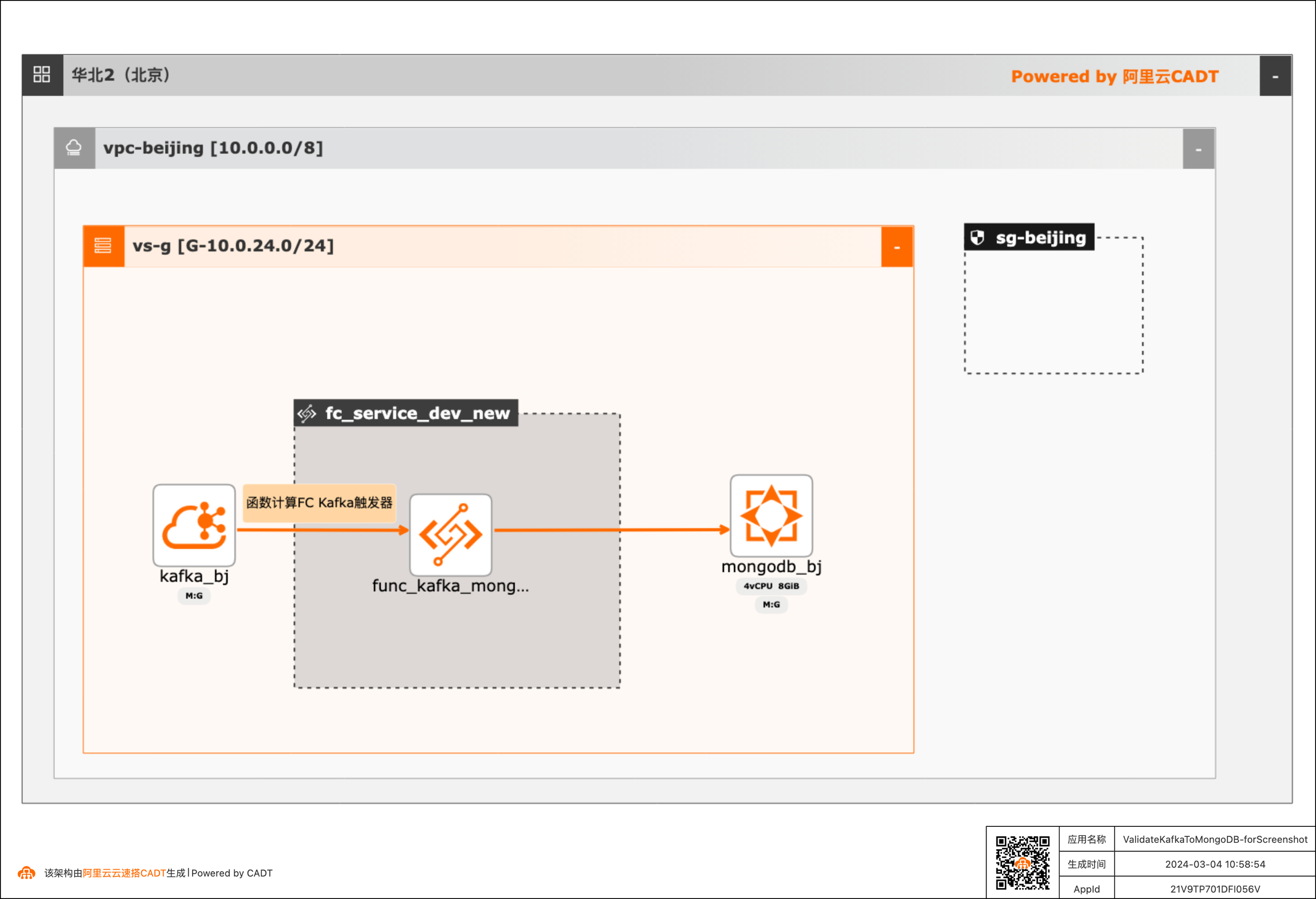
在大数据ETL场景,将Kafka中的消息流转到其他下游服务是很常见的场景,除了常规的消息流转外,很多场景还需要基于消息体内容做判断,然后决定下游服务做何种操作。 该方案实现了通过Kafka中消息Key的内容来判断应该对MongoDB做增、删、改的哪种DML操作。 当Kafka收到消息后,会自动触发函数计算中的函数,接收到消息,对消息内容做判断,然后再操作MongoDB。用户可以对提供的默认函数代码做修改,来满足更复杂的逻辑。 整体方案通过CADT可以一键拉起依赖的产品,并完成了大多数的配置,用户只需要到函数计算和MongoDB控制台做少量配置即可。
确认订单阶段会列出架构中所有的产品及其当天价格,需要用户确认无误后勾选接受《云速搭服务条款》,此时下一步:支付并创建才会高亮,可以单击进行实际的资源购 买和部署。19 文档版本:20240304 基于函数计算 FC 实现阿里云 Kafka 消息内容控制 MongoDB DML 操作 部署基础环境 资源开始进行下单购买,请耐心等待资源创建 ...
云消息队列 ApsaraMQ
云消息队列 ApsaraMQ 是阿里云自主研发的消息队列服务系列产品的总称,旨在为开发者和企业的不同业务场景提供强大、可靠、低成本、高弹性且易于管理的消息服务。云消息队列 ApsaraMQ 全系列产品提供 Serverless 化的消息服务,按实际使用量付费,自适应弹性,跨可用区容灾,帮助客户降低使用和维护成本,专注业务创新。
云消息队列 RabbitMQ 版是一款兼容 AMQP 0-9-1 协议,解决开源稳定性痛点的消息队列产品,同时具备按量后付费的售卖模式开箱即用、无需评估容量等优势.云消息队列 RabbitMQ 版.移动互联网、物联网、互动直播原生支持,万物互联,端与云双向通信,支撑千万级设备同时在线.云消息队列 MQTT 版.消息服务是一款易集成、高并发、...
来自:
云产品
云消息队列 RabbitMQ 版
云消息队列 RabbitMQ 版是阿里云打造的云消息服务,广泛用于海量队列分发、分布式定时任务等场景。支持 AMQP 协议,开箱即用,轻松实现快速上云,更专业、更可靠、更安全。
云消息队列 RabbitMQ 版的定时消息能力开箱即用,无需安装运维插件,只需要在生产者客户端发布消息时,通过 delay 为消息设置一个延时时间即可达到延时的效果.云消息队列 MQ.推荐搭配使使用.分布式定时任务.分布式定时任务.和开源自建对比.更多产品与服务.和开源自建对比.Queue 模式.支持 Queue 队列存储消息,提供多分区,...
来自:
云产品
云消息队列 Kafka 版
云消息队列 Kafka 版是阿里云基于Apache Kafka构建的大数据消息中间件,广泛用于日志收集和分析、数据处理等场景。可提供全托管服务,用户无需部署运维,更专业、更可靠、更安全。
随着业务的快速发展,大搜车遇到了消息量大幅增加、异地消息同步等一系列的问题,需要更稳定可靠的商业版Kafka产品,减少运维工作量,利用云消息队列Kafka对接大数据生态,即开即用,快速扩容,可靠性更高.大搜车:云上多地域高可用消息系统的构建.云消息队列 Kafka 版 V3 系列 Serverless 实例正式发布!云消息队列 Kafka ...
来自:
云产品
云消息队列 RocketMQ 版
云消息队列 RocketMQ 版是基于 Apache RocketMQ 构建的分布式消息中间件,广泛用于异步解耦、削峰填谷等场景。可支撑千万级并发、万亿级数据洪峰,更稳定,更安全。
云消息队列 RocketMQ 版 Serverless 系列资源包重磅上线!存储空间无法自由弹性伸缩,空间不足会导致清理数据;多副本存储成本高.基于集群水位规划机器:·需要预留水位,且缩容复杂;受扩容速度限制,无法支持突发流量弹性.手工命令行操作运维,成本高,风险大;缺少配套可观测监控体系.自行运维保障,需要资深技术人员...
来自:
云产品
Function Compute构建高弹性大数据采集系统
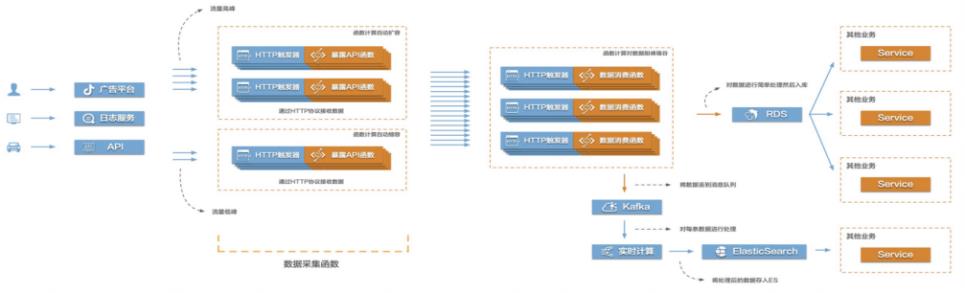
当前互联网很多场景都存在需要将大量的数据信息采集起来然后传输到后端的各类系统服务中,对数据进行处理、分析,形成业务闭环。比如游戏行业中的游戏发行、游戏运营,产互行业中的数字营销,物联网、车联网行业中的硬件、车辆信息上报等等。这些场景普遍存在数据采集量大、数据传输需要稳定且吞吐量大的特点,给整个数据采集传输系统带来很大的挑战。在这个场景中,有三个关键的环节,数据采集、数据传输、数据处理。该最佳实践主要涉
分别打开以下产品的控制台,开通以下服务:ᅳ 专有网络 VPC ᅳ 日志服务 SLS ᅳ 链路追踪 Tracing Analysis ᅳ 云服务器 ECS ᅳ 云数据库 RDS ᅳ 函数计算 FC ᅳ 消息队列 Kafka 版 ᅳ 性能测试 PTS ᅳ 云速搭 CADT 本文使用到的示例代码可以用以下命令下载。git clone https://code.aliyun.com/best-practice/219.git 有...
- 产品推荐
- 这些文档可能帮助您