短信服务
阿里云短信服务(Short Message Service-SMS)支持国际和国内短信验证码、短信通知和营销推广短信,国内短信支持三网合一专属通道,支持发送助手及API/SDK接口,按成功收费,免运维,秒级触达,服务范围覆盖全球200多个国家和地区。
设置多个发送队列,确保短 信发送请求被实时接收及处理.查看详情文档.强大的高并发处理.基于阿里云账户及RAM授权 体系,对发送API进行鉴权确 保只有您才可调用自己的API.创建RAM用户文档.API高安全调用.提供群发助手免运维支持5种 编程语言API对接,如Java、PHP、Python、Node.js及C#.设置发送方式文档.免运维简单集成.可...
来自:
云产品
阿里云云原生可观测套件
阿里云云原生可观测套件围绕Prometheus服务、Grafana服务和链路追踪服务,通过标准的PromQL和SQL提供数据大盘展示、告警和数据探索能力。
《JAVA 应用排查全景图》.详细阐述云原生架构定义,完整展示云原生架构应用所需的演进路径与设计规则,帮助企业更好地理解与应用云原生架构,助力企业数字化转型升级.《云原生架构白皮书》.图片56*56(不可与icon共存).图片logo.icon名称(不可与图片logo共存).icon名称.不填写不展示.包含前端监控、应用监控、云拨测,覆盖...
来自:
云产品
应用实时监控服务ARMS
作为云原生可观测平台,应用实时监控服务 ARMS 包含前端监控、应用监控、云拨测等模块。覆盖浏览器、小程序、APP、分布式应用、容器等不同可观测环境与场景。帮助企业实现全栈性能监控与端到端追踪诊断。提高监控效率,压降运维工作量。
真实用户体验分析.API 请求支持与后端服务打通,可追踪分析对应前端请求-后端服务的调用链,通过前端+后端服务分析定位网络请求性能瓶颈.ARMS 前端监控.ARMS 云拨测.ARMS 应用监控.用户体验优化.针对 Java、PHP、Node.js等多语言、分布式、微服务应用进行性能监控与链路追踪.针对不同部署环境(ECS、Serverless、容器)、...
来自:
云产品
可观测监控 Prometheus 版
覆盖业务自定义监控/应用组件监控/云服务监控/容器监控/系统监控等场景。默认集成Grafana看板与智能告警,全面优化系统可用性与查询能力,用户无需关注系统可用性与Exporter集成。帮助企业快速搭建一站式指标可观测体系。
更多产品与服务.阿里云可观测监控 Prometheus 版与开源自建对比.阿里云全托管.自行购买相关资源并部署系统.资源购买&系统搭建.日常自行运维.支持采集存储组件多副本,可水平扩展,可用性高.单进程,无法水平扩展,可用性低.一键接入常见云服务,覆盖数据库、中间件等主流应用组件,以及 Java/Go 等主流编程语言构建的应用,...
来自:
云产品
企业上云workshop
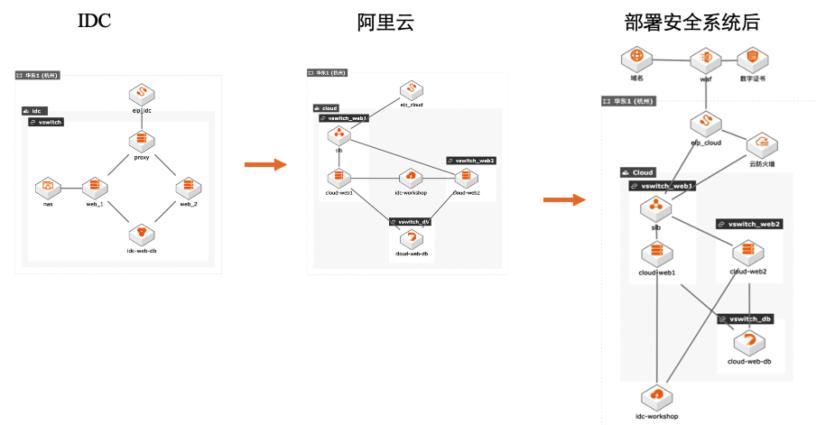
本文模拟了如下场景: 1. 线下 IDC 环境中部署了一个业务系统,业务是利用 wordpress 系统提供网站服务。 2. 本文详细介绍了如何将以上线下系统搬迁到云上, 包括如何在云上构建以上业务系统,如何迁移线下 系统到云上,如何割接。 3. 最后介绍了迁移上云后,如何部署安全系统。 解决问题 IDC 业务系统搬迁上云 云上构建业务系统 部署安全系统
更新域名解析,完成应用割接 在域名解析服务中,将 ws001.lustre.site 解析地址指向 SLB实例的 EIP即完成了服 务的割接上线。同时将本地 host中对域名的解析删除。12.5.验证数据反向同步生效 为保障割接可回滚,配置了云端数据库向 IDC数据库的同步。割接完成后,可发布一 篇新的博客,并通过本地 host重新解析域名至 IDC ...
来自:
最佳实践
相关产品:专有网络 VPC,云服务器ECS,云数据库RDS MySQL 版,对象存储 OSS,负载均衡 SLB,弹性公网IP,文件存储NAS,云数据库PolarDB,Web应用防火墙,云防火墙,SSL证书,云速搭
数据迁移上云
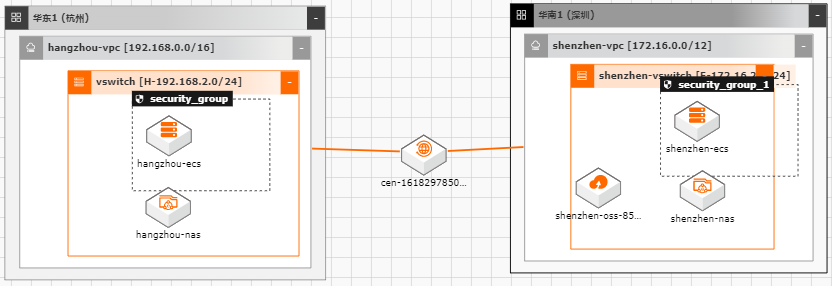
随着越来越多的企业选择将业务系统上云,各种类型的数据如何便捷、平滑的迁移上 云,成了用户上云较为关注的点;业务上云后,因为业务或者其他方面调整等因素, 也存在如跨区域,跨账号等数据迁移的场景。针对以上需求,阿里云上提供了较为丰 富的工具(如ossimport)、服务(在线迁移服务),旨在能够帮助客户便捷进行数据迁 移。 本文通过云架构设计工具CADT来快速创建云上基础资源,并以杭州区域来模拟线 下IDC(或友商),深圳区域模拟阿里云云上资源。通过云上的工具命令、服务来提 供常见数据迁移场景的最佳实践。
本案例以 FTP服务器为例,具体 FTP服 26 文档版本:20201013 数据迁移上云最佳实践 使用阿里云在线迁移服务进行数据迁移 务器搭建过程本文不再赘述。3.2.创建目的地址 步骤1 选择在线迁移服务>数据地址,并选择“OSS”的数据类型,数据所在区域选择“华南 1(深圳)”,然后点击创建数据地址 步骤2 在跳出的创建数据窗口中...
基于DataWorks的大数据一站式开发及数据治理

概述 基于Dataworks做大数据一站式开发,包含数据实时采集到kafka通过实时计算对数据进行ETL写入HDFS,使用Hive进行数据分析。通过Dataworks进行数据治理,数据地图查看数据信息和血缘关系,数据质量监控异常和报警。 适用场景 日志采集、处理及分析 日志使用Flink实时写入HDFS 日志数据实时ETL 日志HIVE分析 基于dataworks一站式开发 数据治理 方案优势 大数据一站式开发,完善的数据治理能力。 性能优越:高吞吐,高扩展性。 安全稳定:Exactly-Once,故障自动恢复,资源隔离。 简单易用:SQL语言,在线开发,全面支持UDX。 功能强大:支持SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据源计算等Data Lake相关功能 ,以及各种流式及静态数据源关联查询。
下载安装之后默认的目录为:/usr/lib/jvm/,查看目录:根据实际情况来配置环境变量,如下示例(注意先查看自己当前的版本替换 java home路径,下面实例的版本可能和你安装的不一致):JAVA_HOME=usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.262.b10-0.el7_8.x86_64 PATH=$PATH:$JAVA_HOME/bin CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$...
实时计算Flink版
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,具备实时应用的作业开发、数据调试、运行与监控、自动调优、智能诊断等全生命周期能力。内核引擎100%兼容Apache Flink,2倍性能提升,拥有FlinkCDC、动态CEP等企业级增值功能,内置丰富上下游连接器,助力企业构建高效、稳定和强大的实时数据应用。
主流媒体如新闻类、短视频类、直播类等输出方式,建立标准化通用化场景,业务管控更快捷.复杂场景标准化.针对内容分享平台业务个性化需求,通过实时计算进行业务精细化运营,增加用户粘性和消费欲望.业务实时输出快.实时计算Flink版.机器学习 PAI.实时数仓 Hologres.查看全部日志.核心性能提升.数据实时入湖入仓.实时风控...
来自:
云产品
- 产品推荐
- 这些文档可能帮助您