企业上云数据安全
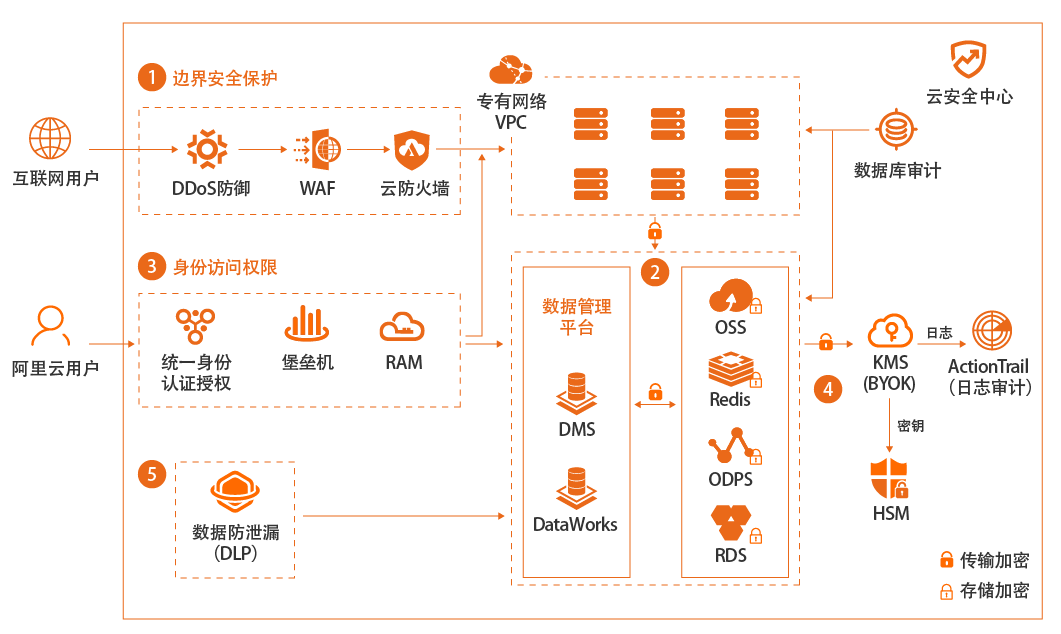
场景描述 企业是否选择上公共云,或者哪些系统或数据上 公共云,对数据安全的关心是重要因素之一。本 最佳实践重点在于介绍狭义的数据加密存储安 全范畴,即首先使用SDDP产品进行敏感数据发 现和分级分类,然后对高级别敏感数据进行按 需、不同类型的全链路加密存储。 解决问题 1.帮助客户发现敏感数据 2.对敏感数据进行分类、分级 3.对不同级别的数据如何选择加密方式 4.具体如何进行加密 产品列表 敏感数据识别SDDP 密钥管理服务KMS 云数据库RDS 对象存储OSS
本最佳实践重点在于介绍狭义的数据加密 存储安全范畴,即首先使用 SDDP产品进行敏 感数据发现和分级分类,然后对高级别敏感数 据进行按需、不同类型的全链路加密存储。解决问题 1.帮助客户发现敏感数据 2.对敏感数据进行分类、分级 3.对不同级别的数据如何选择加密方式 4.具体如何进行加密 产品列表 敏感数据识别 SDDP 密钥...
基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测

本篇最佳实践先创建EMR集群作为数据湖对象,Hive元数据存储在DLF,外表数据存储在OSS。然后使用阿里云数据仓库MaxCompute以创建外部项目的方式与存储在DLF的元数据库映射打通,实现元数据统一。最后通过一个毒蘑菇的训练和预测demo,演示云数仓MaxCompute如何对于存储在EMR数据湖的数据进行加工处理以达到业务预期。
步骤2 查询DLF的表数据,可以正常查询到插入外表项目的测试数据。select*fromdlf_mc002.mushroom_classificationlimit1;基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测 3.4.数据预处理 由于逻辑回归二分类(https://help.aliyun.com/document_detail/42745.html)要求 feature为数值类型,这里我们通过One-HotEncoding...
EMR本地盘实例大规模数据集测试
场景描述 阿里云为了满足大数据场景下的存储需求,在云 上推出了本地盘D1机型,这个系列提供了本地 盘而非云盘作为存储,提高了磁盘的吞吐能力, 发挥Hadoop的就近计算优势。阿里云EMR 产品针对本地盘机型,推出了一整套的自动化运 维方案,帮助用户方便可靠地使用本地盘机型, 不需要关注整个运维过程同时数据的高可靠和 服务的高可用。 解决问题 1.云盘多份冗余数据导致成本高 2.磁盘吞吐量不高 3.节点的高可靠分布问题 4.本地盘与节点的故障监控问题 5.数据迁移时自动决策问题 6.自动故障节点迁移与数据平衡问题 产品列表 EMR(E-MapReduce) 本地盘 VPC
Master节点 通常可以生成 1TB的数据进行基准性能测试,首先进入 hive-testbench目录下执行如 下脚本并加载测试数据 参数说明:数据集规模参数单位为 GB,1000表示生成的数据量为 1TB/tpcdata/tpcds 为表数据生成的目录,目录不存在就自动生成,如果不指定目录,数 据目录就默认生成到/tmp/tpcds目录下 cd hive-testbench#如果...
多媒体数据存储与分发
以搭建一个多媒体数据存储与分发服务为例,搭建一个多媒体数据存储与分发服务。
产品解决方案文档与社区权益中心定价云市场合作伙伴支持与服务了解阿里云备案控制台多媒体数据存储与分发方案介绍方案优势应用场景方案部署方案权益多媒体数据存储与分发视频、图文类多媒体数据量快速增长,内容不断丰富,多媒体数据存储与分发解决方案融合对象存储 OSS、内容分发 CDN、智能媒体管理 IMM 等产品能力,解决...
来自:
解决方案
数据集成 Data Integration
阿里云数据集成 Data Integration是跨异构数据、低成本、弹性扩展的数据采集同步平台,为DataX的商业版,支持ETL,支持50+数据源跨网络离线(全量/增量)同步。
为了加快建设“三型两网、世界一流”发展战略,通过整体电力解决方案,进行数据中台规划与建设,构建电力行业新一代信息基础平台,带动公司IT和数据资源建设、应用及运维向企业级转变.一云多Region数据中台架构.统一运营运维管理.建设电力一朵云,形成“IT资源服务中心”和“数据服务中心”,实现运营“两级协同”,满足...
来自:
云产品
Databricks数据洞察
阿里云Databricks数据洞察是基于Apache Spark的全托管数据分析平台, 内核采用更高效、稳定的商业版Databricks Runtime和Delta Lake。可满足数据分析师、数据工程师和数据科学家在大数据场景下对数据湖分析、实时数仓、离线数仓、BI数据分析、AI机器学习等需求
满足高性能、高稳定性、可弹性的计算需求.Databricks Delta Lake为数据湖分析提供了ACID事务能力,轻松处理包含数十亿文件的PB级表的元数据信息,实现了批流一体的数据处理方式.同时满足数据科学家、数据工程师以及业务分析师的计算需求,提供交互式的协同分析工作平台.计算存储分离,减少数据冗余,实现多引擎间的数据共享...
来自:
云产品
数据管理与服务
数据管理与服务作为阿里云产品六大版块之一,面向不同业务场景,阿里云提供数据存储、分析、应用等全链路能力,满足企业客户全方位的数据处理需求,实现计算和存储分离、资源解耦、数据移动减化,用以满足行业快速发展的需求和趋势,利用数据重塑其业务。
本篇全域数据集成向开发者介绍通过DataWorks数据集成在多表多表、多表到单表、单表到单表等场景下,进行实时或离线同步的技术选型与核心能力,并以MaxCompute与Hologres引擎为例,演示云上数据同步操作步骤最佳实践.全链路数据治理-全域数据集成.2021年10月20日,阿里云正式开源云原生分布式数据库PolarDB-X的源代码,将自...
来自:
云产品
基于DataWorks的大数据一站式开发及数据治理

概述 基于Dataworks做大数据一站式开发,包含数据实时采集到kafka通过实时计算对数据进行ETL写入HDFS,使用Hive进行数据分析。通过Dataworks进行数据治理,数据地图查看数据信息和血缘关系,数据质量监控异常和报警。 适用场景 日志采集、处理及分析 日志使用Flink实时写入HDFS 日志数据实时ETL 日志HIVE分析 基于dataworks一站式开发 数据治理 方案优势 大数据一站式开发,完善的数据治理能力。 性能优越:高吞吐,高扩展性。 安全稳定:Exactly-Once,故障自动恢复,资源隔离。 简单易用:SQL语言,在线开发,全面支持UDX。 功能强大:支持SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据源计算等Data Lake相关功能 ,以及各种流式及静态数据源关联查询。
自定义 HDFS Sink.47 文档版本:20201020 IV 基于 Dataworks的大数据一站式开发及数据治理 最佳实践概述 最佳实践概述 概述 本实践基于 Dataworks做大数据一站式开发,包含数据实时采集到 kafka通过实时计 算对数据进行 ETL写入 HDFS,使用 Hive进行数据分析。通过 Dataworks进行数据 治理,数据地图查看数据信息和血缘关系...
数据传输解决方案
数据传输解决方案支持关系型数据库、NoSQL、大数据(OLAP)等数据源间的数据传输。 它是一种集数据迁移、数据订阅及数据实时同步于一体的数据传输服务。数据传输致力于在公共云、混合云场景下,解决远距离、毫秒级异步数据传输难题。
从RDS向后端数据汇总,获得全局业务的实时统计、BI报表和分析.数据传输DTS.云数据库MySQL.云服务器ECS.其业务系统的数据变化,以订阅消息的方式,快速向下游分发.数据传输DTS.云数据库MySQL.借助DTS异构数据库迁移的能力,银泰百货实施了去O上云.数据传输DTS.云数据库PolarDB-X.云数据库MySQL.UC浏览器实现了异地多活的架构...
来自:
解决方案
湖仓一体架构EMR元数据迁移DLF
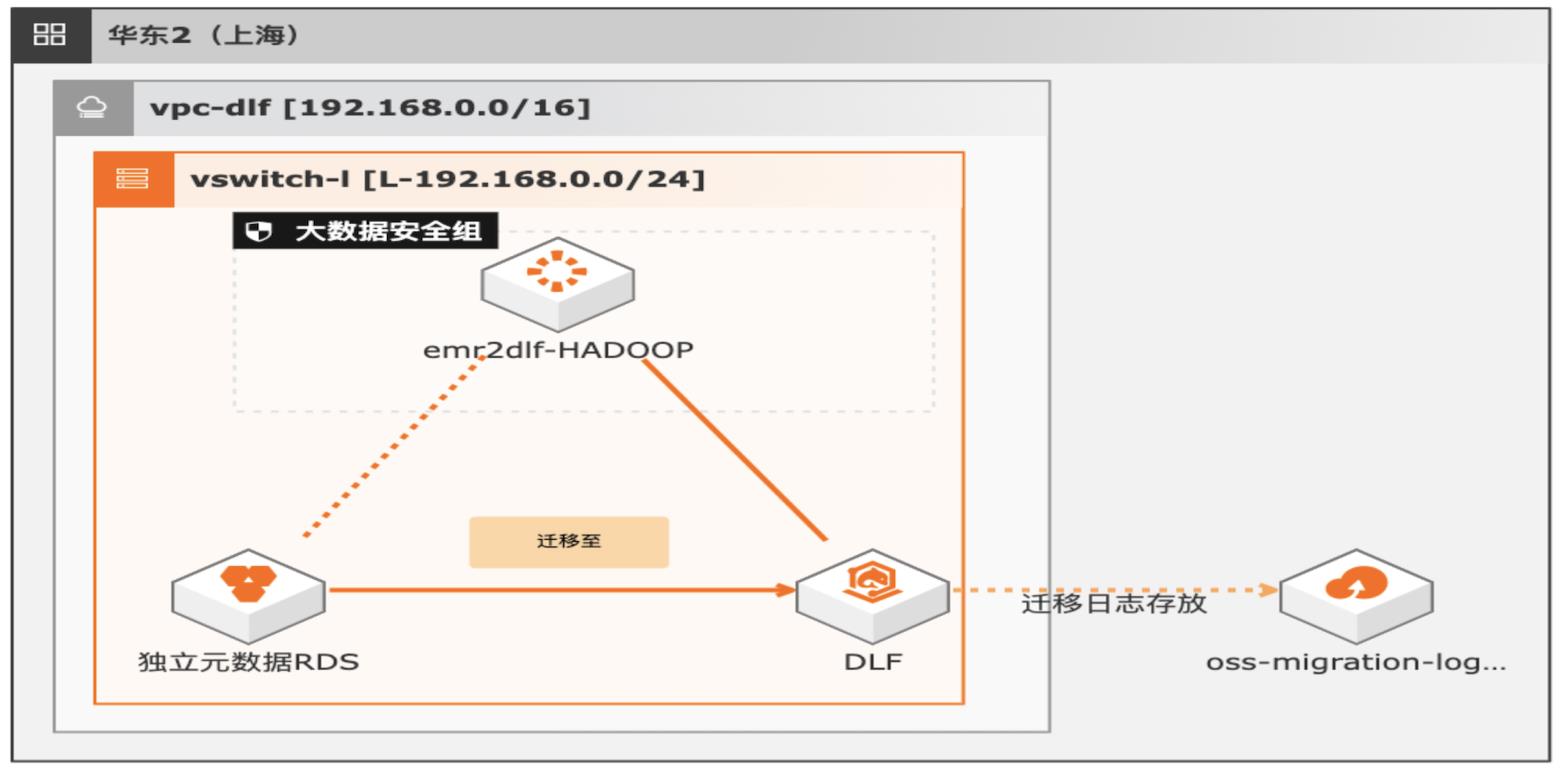
通过EMR+DLF数据湖方案,可以为企业提供数据湖内的统一的元数据管理,统一的权限管理,支持多源数据入湖以及一站式数据探索的能力。本方案支持已有EMR集群元数据库使用RDS或内置MySQL数据库迁移DLF,通过统一的元数据管理,多种数据源入湖,搭建高效的数据湖解决方案。
湖仓一体架构 EMR元数据迁移 DLF最佳实践 业务架构 场景描述 解决的问题 通过 EMR+DLF数据湖方案,可以为企业提供数据 EMR元数据迁移至 DLF 湖内的统一的元数据管理,统一的权限管理,支持多 元数据迁移验证 源数据入湖以及一站式数据探索的能力。本方案支 数据一致性校验 持已有 EMR集群元数据库使用 RDS或内置 MySQL ...
异地双活场景下的数据双向同步
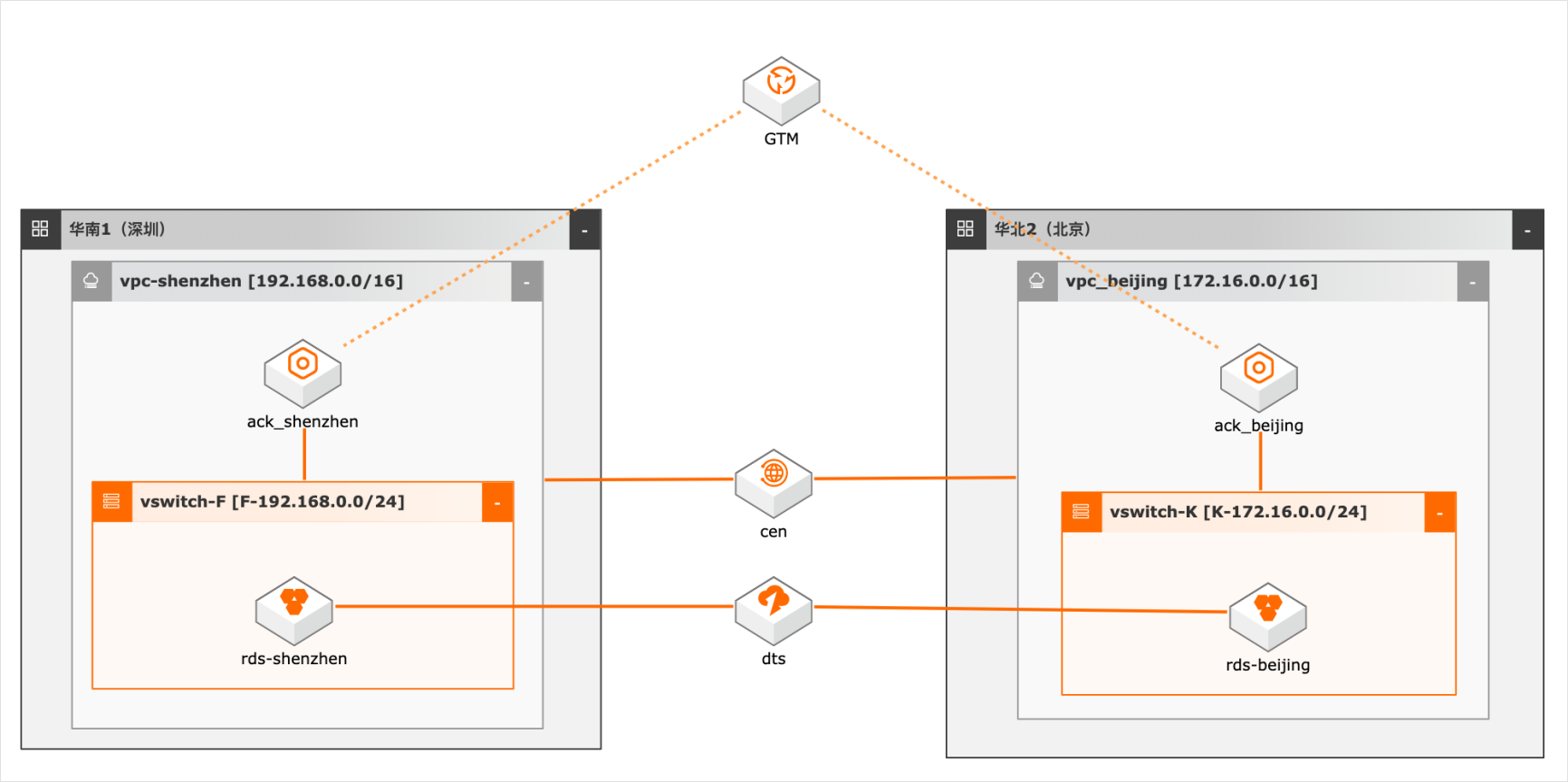
概述 随着客户业务规模的扩大,对系统高可用性要求越来越高,越来越多用户采用异地双活/多活架构,多活架构往往涉及业务侧做单元化改造,本方案仅模拟用户已做单元化改造后的数据双向同步,数据库采用双主架构,本地写本地读,同时又保证双库的数据一致性,为业务增加可用性和灵活性。 适用场景 数据库双向同步 数据库全局ID不冲突 双活架构的数据库建设问题 技术架构 本实践方案基于如下图所示的技术架构和主要流程编写操作步骤: 方案优势 DTS双向同步,采用独立模块避免数据同步占用系统资源。 奇偶ID涉及,避免数据冲突。 DTS多种处理冲突的方式供业务选择。 安全:原生的多租户系统,以项目进行隔离,所有计算任务在安全沙箱中运行。
随着客户业务规模的扩大,对系统高可用性要求越 数据库双向同步 来越高,越来越多用户采用异地双活/多活架构,多 数据库全局 ID不冲突 活架构往往涉及业务侧做单元化改造,本方案仅模 双活架构的数据库建设问题 拟用户已做单元化改造后的数据双向同步,数据库 采用双主架构,本地写本地读,同时又保证双库的数 据一致性,为...
云原生数据湖分析DLA
阿里云云原生数据湖分析是新一代大数据解决方案,采取计算与存储完全分离的架构,支持对象存储(OSS)、RDS(MySQL等)、NoSQL(MongoDB等)数据源的消息实时归档建仓,提供Presto和Spark引擎,满足在线交互式查询、流处理、批处理、机器学习等诉求。内置大量优化+弹性,比开源自建集群最高降低50%+的成本,最快可1分钟级拉起300个计算节点,快速满足业务资源要求。
拥有优越弹性,支持元数据发现,支持多源一键数据实时入湖分析等功能,直接使用SQL即可分析OSS等数十种源数据.多项企业级能力,涵盖各类业务需求.GUI工具丰富.支持Microstrategy、MySQL Workbench、DBeaver等多种MySQL GUI管理工具.多种可视化工具支持.与QuickBI、Tableau、DataV等BI工具集成度高、兼容性好.兼容标准SQL....
来自:
云产品
利用低成本链路完成业务数据迁移上云
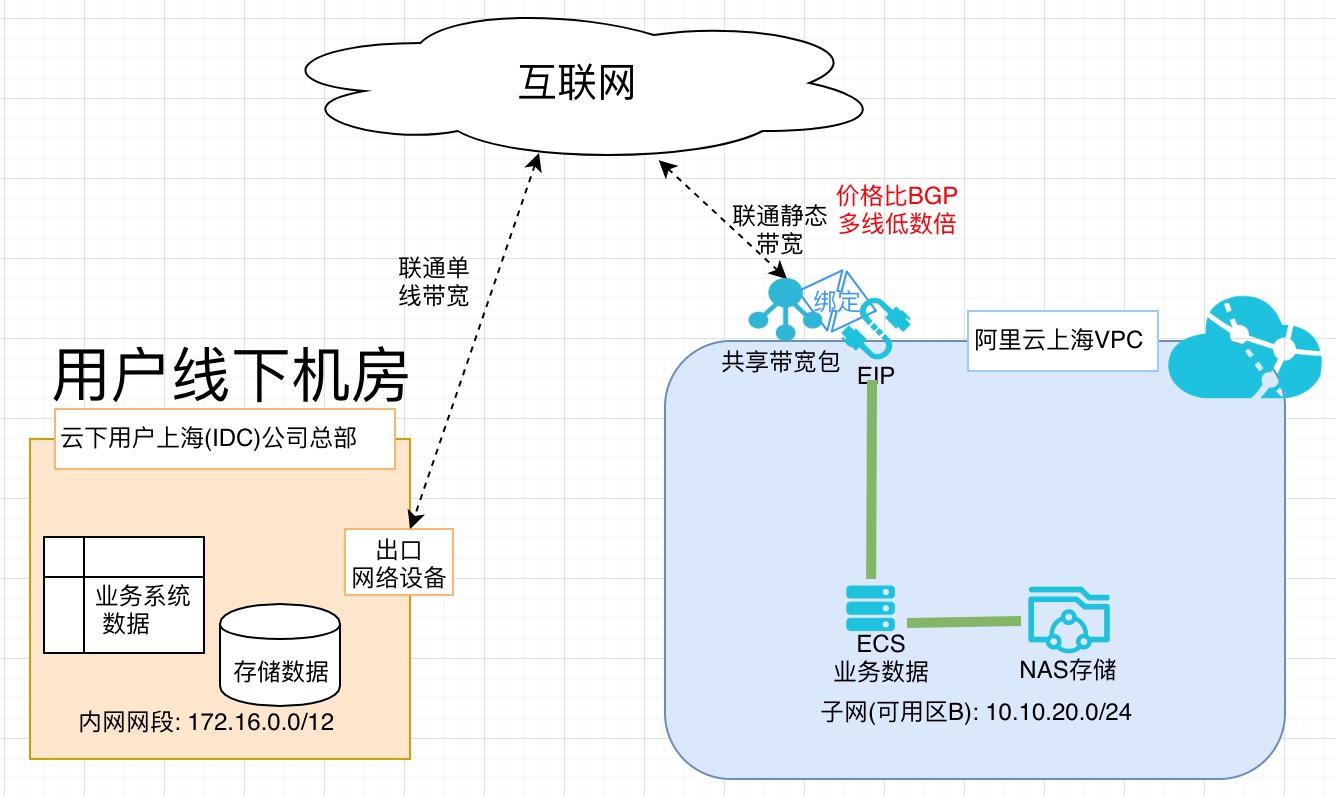
场景描述 随着云计算被越来越多的客户所接受,除业务系 统上云外,很多客户已经把业务数据搬迁上云。 业务数据量一般都比较大,迁移上云需要大量的 网络带宽,BGP费用比较高。阿里云对用户开 放所需地域购买静态单线共享带宽包的权限(移 动/联通/电信均可),可用为迁移数据有效降低 成本。 解决问题 1.业务数据上云网络成本高 产品列表 专有网络VPC 云服务器ECS 网络存储NAS 共享带宽包
利用低成本链路完成业务数据上云 最佳实践 部署架构图 场景描述 随着云计算被越来越多的客户所接受,除业务系 统上云外,很多客户已经把业务数据搬迁上云。业务数据量一般都比较大,迁移上云需要大量的 网络带宽,BGP费用比较高。阿里云对用户开 放所需地域购买静态单线共享带宽包的权限(移 动/联通/电信均可),可用为...
企业构建统一CMDB数据源
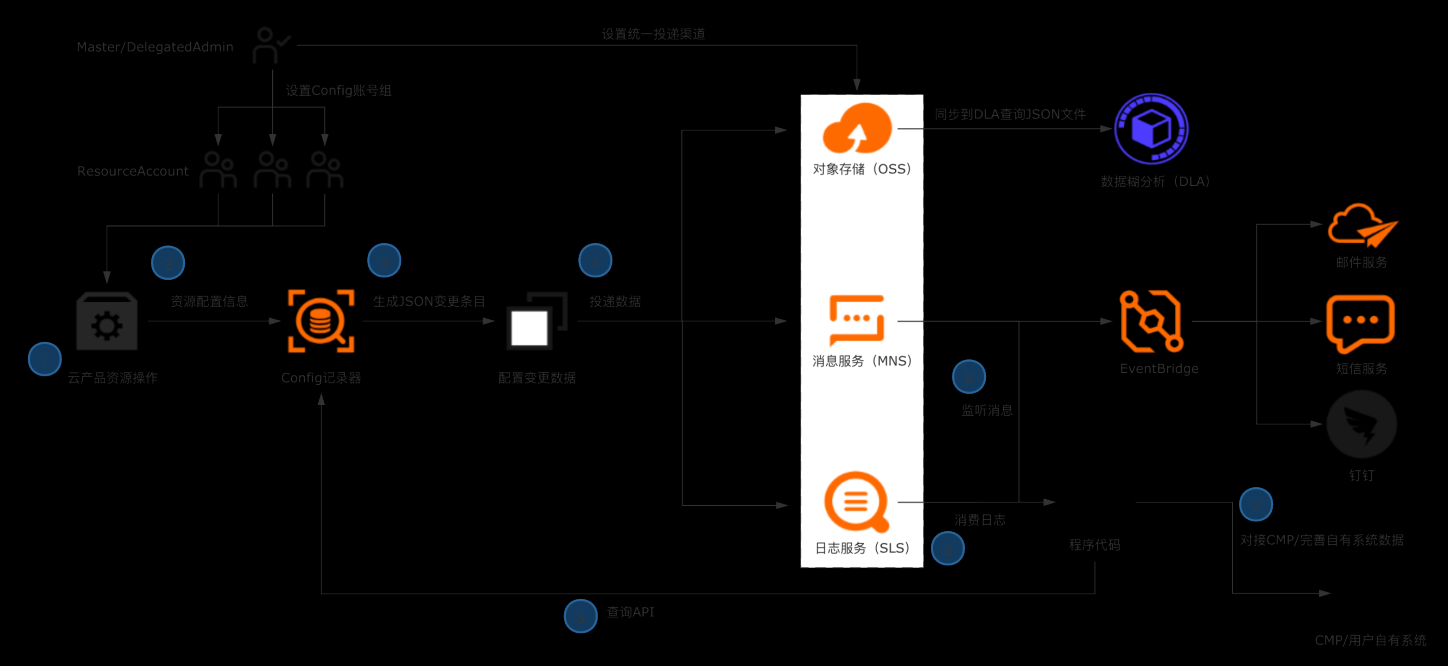
典型场景 l 企业/ISV构建多云CMDB平台,对接数十款产品的API,拉取、清洗、格式化、存储配置数据是复杂且高成本的工作。 l 企业日常的资源管理,需依赖资源配置历史、资源关系数据进行故障溯源和影响评估。 解决方案 l 企业管理账号设置Config配置数据投递,将所有账号的资源配置快照和历史归集到统一地址留存。 l 使用OSS做长期归档,使用SLS做实时分析和监听。获取全量资源数据并及时感知云上资源的变更。 l 将数据集成到自有CMDB平台 客户价值 l 基于配置审计简单便捷的持续收集云上资源配置数据,在自建CMDB过程中节省大量人力和时间成本。 l 跨账号统一收集数据,实现中心化的资源配置管理。 l 实现资源配置数据的持续收集和监听,及时感知云上资源的增删改,洞察异常变更。
获取ECS网络信息 本章节,我们以ECS资源的网络配置数据为例,使用 python脚本模拟将资源配置数 据导入企业自有系统。用到了配置审计的 API,在使用前需要导入阿里云 SDK 核心库:aliyun-python-sdk-core:在多账号情况下,列出主账号下指定账号 组的所有资源数据:在多账号情况下,查询指定资源的详细数据 注意:上述两个...
- 产品推荐
- 这些文档可能帮助您