MaxCompute湖仓一体方案
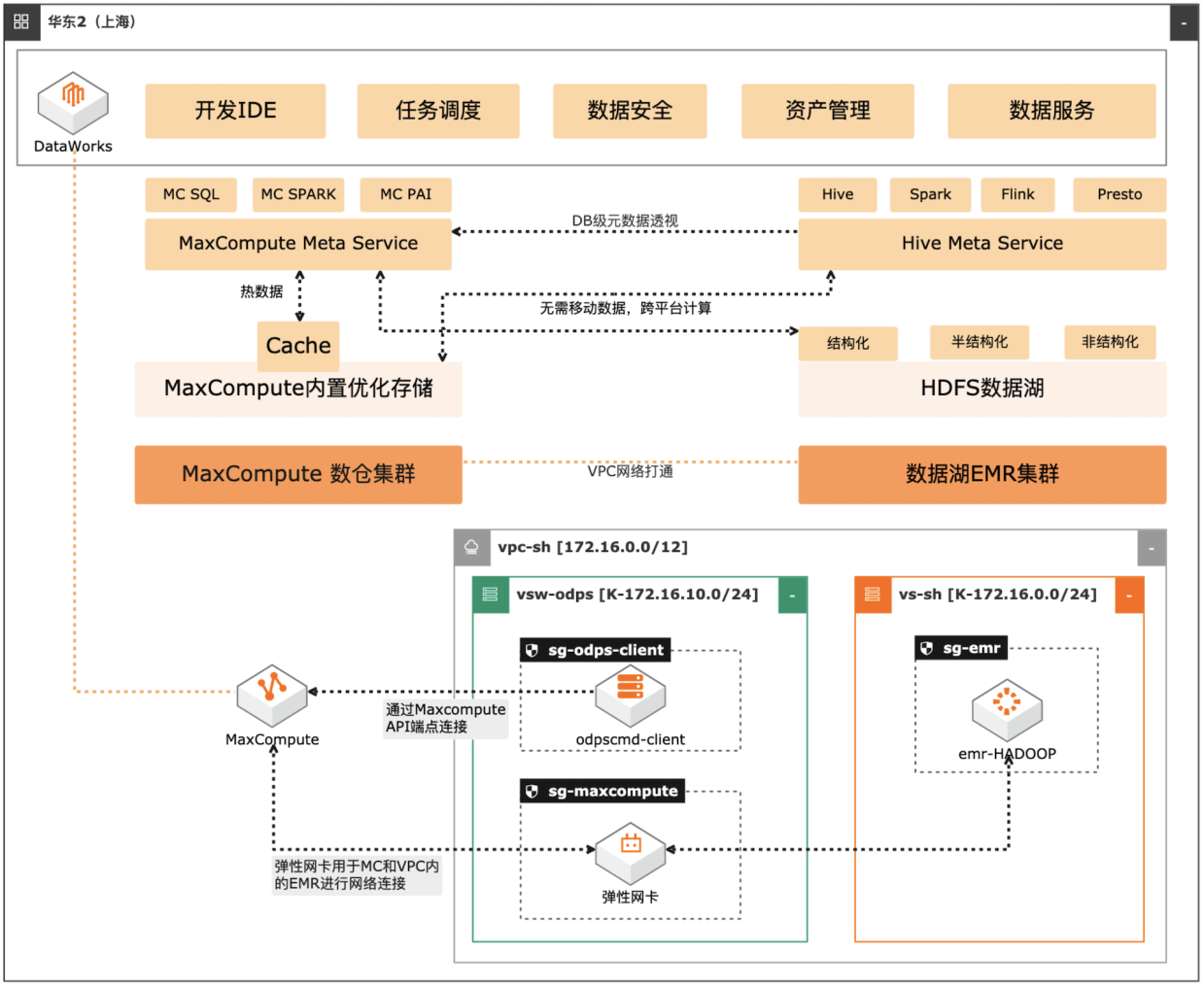
场景描述 自建数据湖与云数仓的融合解决方案,将 MaxCompute与自建的Hive集群做数据打 通,通过存储共享,元数据镜像等方式,解 决传统模式下的存储冗余,计算资源弹性能 力弱的痛点。可大幅度增强系统的资源弹 性,解决业务高峰期计算资源不足的问题。 方案优势 1.业务无侵入性:现有业务无需改造。 2.性能优化:MaxCompute在SQL上做 了大量优化与能力沉淀,可提高SQL 运行性能,降低计算成本。 3.灵活管理:元数据实时同步,无需额外 管理数据同步任务。 4.资源弹性:利用MaxCompute计算池 弹性进行海量数据计算。 解决问题 1.增强业务高峰期的资源弹性。 2.优化自建数据湖的数据治理能力。 3.减少跨平台数据处理的存储冗余。 产品列表 专有网络VPC 云服务器ECS 访问控制RAM 运维编排OOS MaxCompute(原ODPS) 云企业网CEN
2.MaxCompute端创建外部项目,镜像 Hive元数据,可以直接访问 Hive元数据服 务,并将元数据信息映射到 MaxCompute的外部项目(External Project)中 操作流程 1.资源创建:使用阿里云速搭 CADT一键完成业务部署图中的云资源创建,部分暂 时不支持 CADT拉起的资源,需要手动在控制台创建和配置,如 DataWorks工作 空间。2....
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
添加对应的名称 添加描述 选择 VPC名称(与步骤 1中 VPC相同)文档版本:20210425 26 自建 Hive数据仓库跨版本迁移到阿里云 Databricks数据洞察 创建 Databricks数据洞察集群 选择交换机名称(与步骤 1中 VSwitch相同)配置完成,单击下一步。文档版本:20210425 27 自建 Hive数据仓库跨版本迁移到阿里云 Databricks数据...
Dubbo应用上云
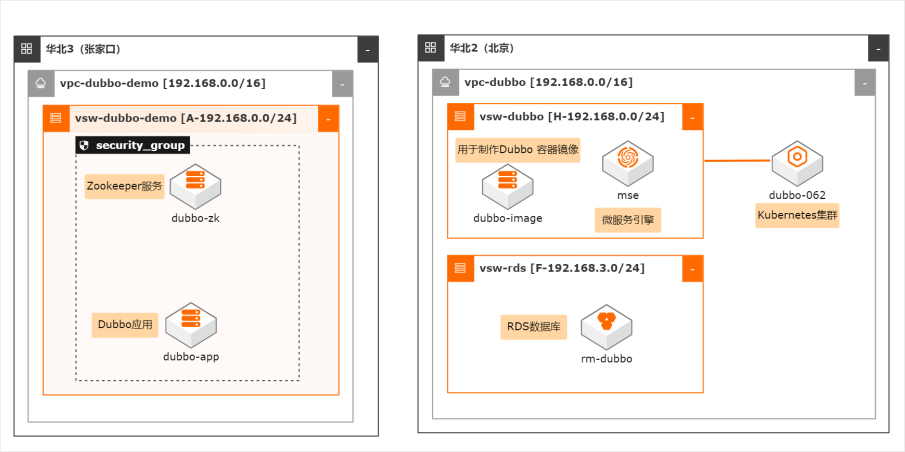
场景描述 本最佳实践适用于企业自建 Dubbo 应用上云, 应 用采用 docker 方式部署, 降低部署成本。同时利 用 MSE 提供 Zookeeper 服务注册管理。 通过阿 里云的 ARMS 和 AHAS 服务提供应用监控和服务 限流管理,简化运维并提供服务的全生命周期管 理。 解决问题 1. 自建 dubbo 应用迁移上阿里云。 2. 应用部署在容器内降低成本。 3. 通过 MSE 提供 ZK 服务,提高稳定性。 4. 通过 ARMS/AHAS 提供监控和服务限流能力 产品列表 容器服务 Kubernetes 版(ACK) 微服务引擎(MSE) 关系数据库服务(RDS) 应用高可用服务(AHAS) 应用实时监控服务(ARMS)
是阿里云提供的一种基础云计算服 务。无需提前采购硬件设备,根据业务需要,随时创建所需数量的云服务器 ECS 实例。在使用过程中,随着业务的扩展,可以随时扩容磁盘、增加带宽。也能随时 释放资源,节省费用。更多信息,请参见:https://www.aliyun.com/product/ecs MSE:微服务引擎(MSE)是开源注册、配置中心的全托管平台...
大数据近实时数据投递MaxCompute
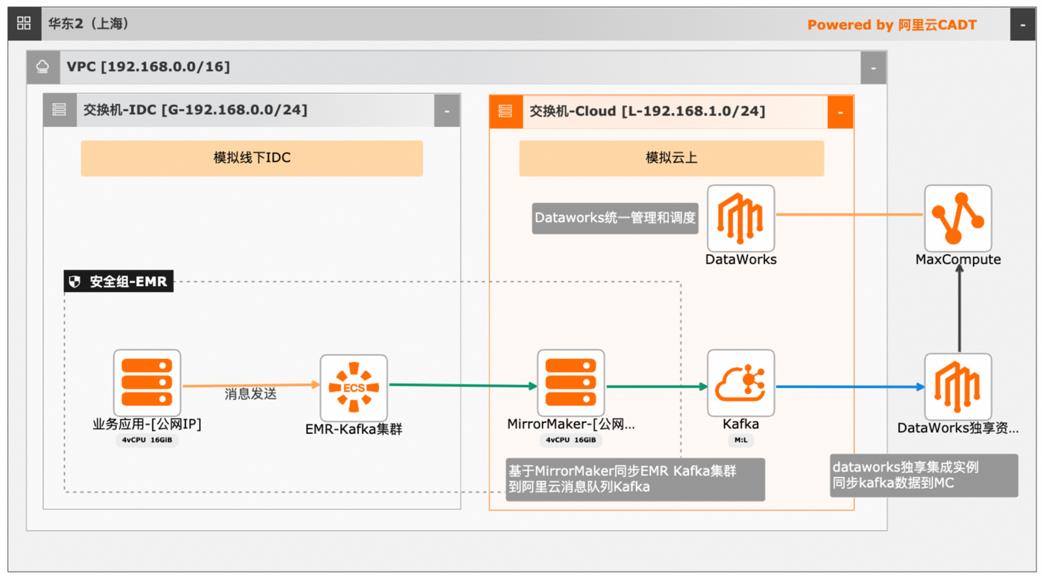
本文介绍离线大数据场景使MaxCompute构建云 上近实时数仓,打通云下数据上云链路,解决数据复杂类型支持和动态分区问题,满足高级数据处理需求的最佳实践。 l混合云环境下,现有业务系统零改造,打通数据上云链路。 l使用UDF实现复杂数据类型转换和数据动态分区。 l使用DataWorks配置周期调度业务流程,数据自动入仓。 l借助MaxCompute优化计算引擎,实现降本增效。 产品列表 云服务器ECS 专有网络VPC 访问控制RAM 数据总线DataHub E-MapReduceEMR DataWorks 大数据计算服务MaxCompute
名词解释 云服务器 ECS:Elastic Compute Service,简称 ECS,是一种简单高效、处 理能力可弹性伸缩的计算服务。详见:https://www.aliyun.com/product/ecs 专有网络 VPC:Virtual Private Cloud,简称 VPC,是基于阿里云创建的自定义 私有网络,不同的专有网络之间二层逻辑隔离。您可以在自己创建的专有网络 内创建和管理...
云速搭部署高可用虚拟 IP HaVIP

通过云速搭部署一个高可用虚拟 IP,并挂载到两个 ECS 实例节点上,HAVIP 将自动与两个 ECS 关联,并接受通过 ARP 协议宣告 来绑定某个 ECS 的网卡。
文档版本:20211201 20 云速搭部署高可用虚拟 IP HaVIP 云速搭部署高可用虚拟 IP HaVIP 步骤6 重置后登录 VNC 步骤7 在 VNC中用 root用户密码登录 OS 步骤8 安装 apache 服务,keepalived服务。yum install-y httpd yum install-y keepalived 步骤9 配置/etc/keepalived/keepalived.conf 文件,配置后如下图所示:文档版本...
CDH迁移升级CDP最佳实践
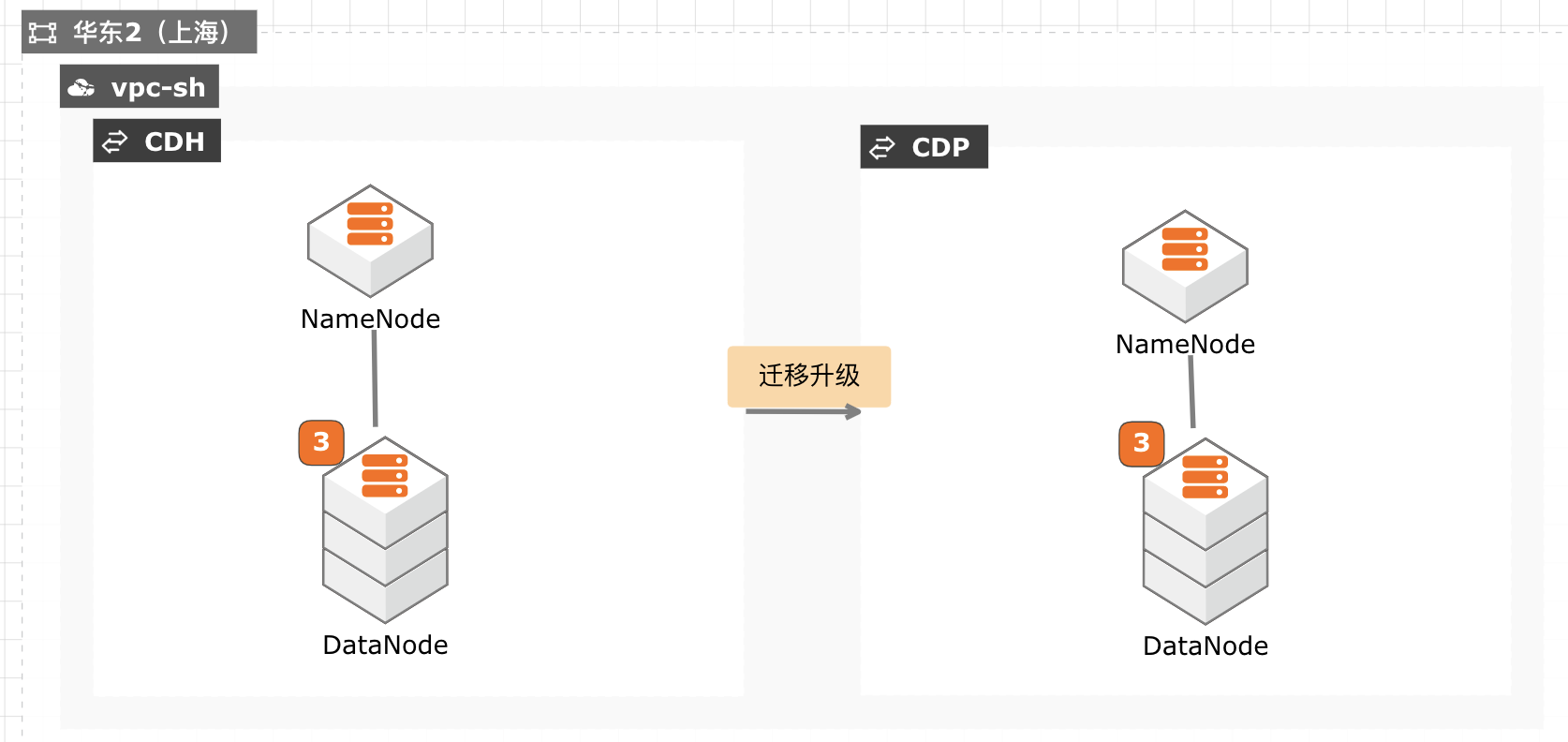
当前 CDH 免费版停止下载,终止服务,针对需要企业版服务能力并且CDH 升级过程对业务影响较小的客户,通过安装新的 CDP 集群,将现有数据拷贝至新集群,然后将新集群切换为生产集群,升级过程没有数据丢失风险,停机时间较短,适合大部分互联网客户升级使用。
容量调度器的特性和配置与公平调度器的特性和配置不同,导致调度器迁移的限制。这些限制有时可以通过手动配置、微调或一些试错来克服,但在许多情况下没有解决 方法。这不是一个完整的列表。它仅包含最常导致问题的调度程序迁移限制。3.3.4.1.不能在同一级别上创建静态和动态叶队列 如果您在 capacity-scheduler.xml 文件中...
网络安全升级支持IPv6

场景描述 关键信息基础设施支持IPv6已经上升到国家战 略,公共云基础设施为云上客户系统支持IPv6 提供了完整的解决方案及产品。本最佳实践是在 现有WAF和高防IP作为网络安全架构基础上, 如何升级支持IPv6,同时满足云上和线下IDC 需求,满足合规要求。 解决问题 1.网络支持IPv6 2.支持V4和V6双栈 3.满足监管合规要求 产品列表 Web应用防火墙WAF DDoS高防IP DDoS防护包
文档版本:20210830 3 网络安全升级支持 IPv6 搭建 IPv4基础业务系统 步骤4 执行以下命令,进行安装部署 apache2 httpd服务,作为 webserver应用。yum install-y httpd cat/var/www/html/index.html Hostname:`hostname` EOF service httpd start 1.3. 配置 SLB 步骤1 登录 SLB控制台。...
互联网业务全球化互通组网
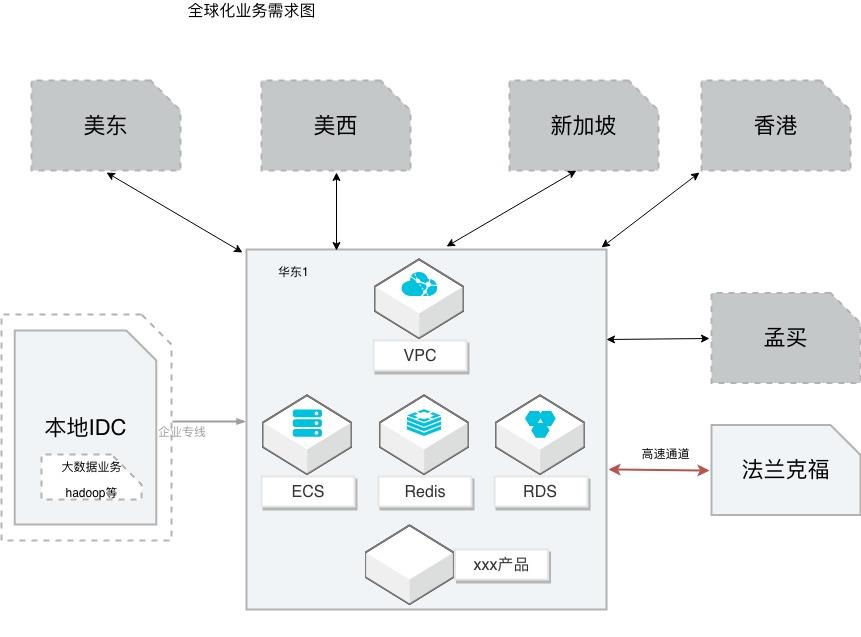
场景描述 本方案适用从事全球化业务的客户,希望借助全球 互通的网络,实现多地域的互通。 同时在全球互联的网络下,搭建应用多地部署。如果 业务中涉及到高速通道,提供高速通道迁移云企业网 的操作演练;涉及到跨账号多VPC下的数据迁移和 同步,本方案提供详细的操作步骤,帮助客户快速完 成演练。 解决问题 借助云企业网解决网络互通 高速通道到云企业网的平滑迁移 RDS的数据互通,特别是跨账号多VPC的数据同步 应用的快速部署 产品列表 云企业网(CEN)、云服务器(ECS)、数据库(RDS)、 数据库(Redis)、数据传输(DTS)、负载均衡(SLB) 块存储、专有网络(VPC)
文档版本:20191217 91 互联网业务全球化互通组网最佳实践 应用全球多地部署 步骤3 在后端服务器配置向导页,选择默认服务器组,并单击继续添加。文档版本:20191217 92 互联网业务全球化互通组网最佳实践 应用全球多地部署 选择创建的 ECS 实例(可用区 D\可用区 E)并单击添加到待添加篮,单击添加。填写端口和权重,本示例...
自建Hive数仓迁移到阿里云EMR
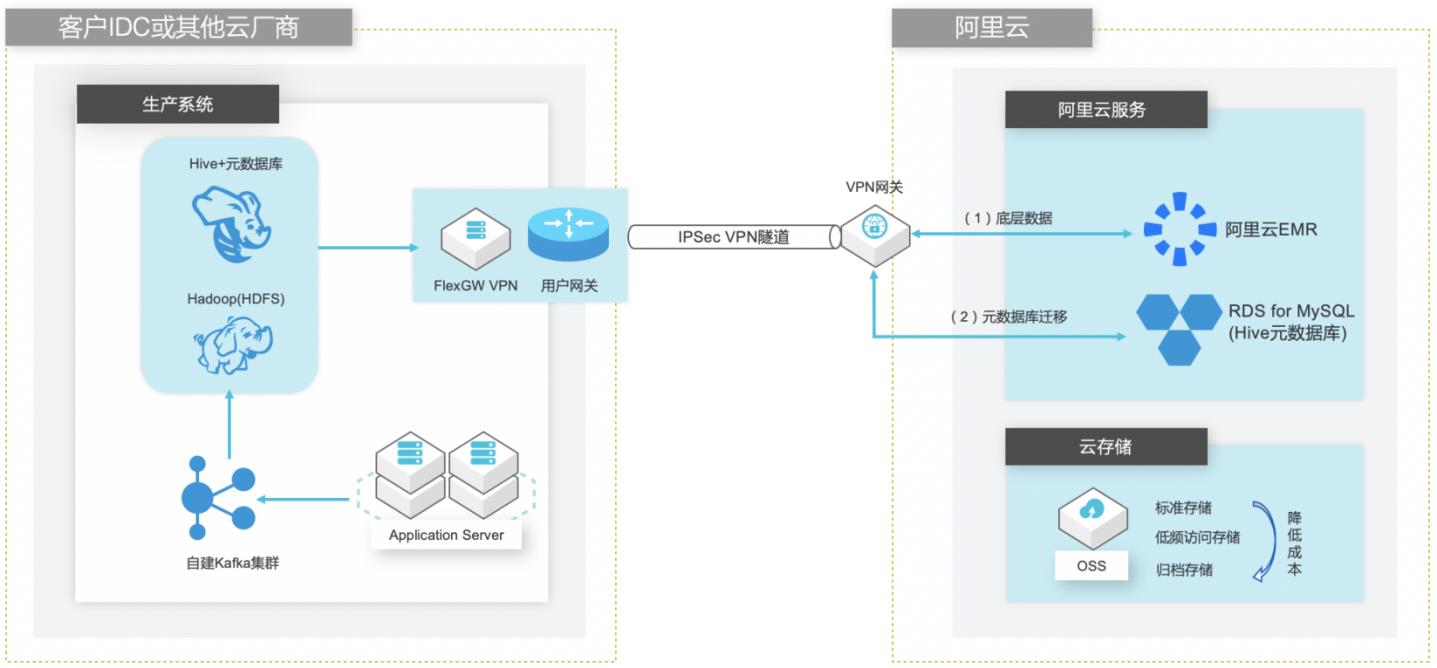
场景描述 客户在IDC或者公有云环境自建Hadoop集群构 建数据仓库和分析系统,购买阿里云EMR集群之 后,涉及到将数据仓库和Hive元数据的数据库迁 移上云。目前主流Hive数据仓库迁移场景为1.x 版本迁移到阿里云EMR(Hive2.x版本),涉及到 数据订正更新步骤。 解决的问题 Hive数据仓库的数据迁移方案 Hive元数据库的迁移方案 Hive跨版本迁移后的数据订正 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
步骤2 部署完成后,重启 Hive MetaStore和 HiveServer2 步骤3 由于在创建 EMR集群时我们指定了 RDS for MySQL实例的数据库作为 Hive的元数 据库,但是此时元数据库还未创建,因此在 EMR控制台可以看到 Hive MetaStore服 务异常停止。文档版本:20210721 25 自建Hive数据仓库跨版本迁移到阿里云 EMR 创建 EMR集群 通过查看 ...
RAPIDS加速图像搜索
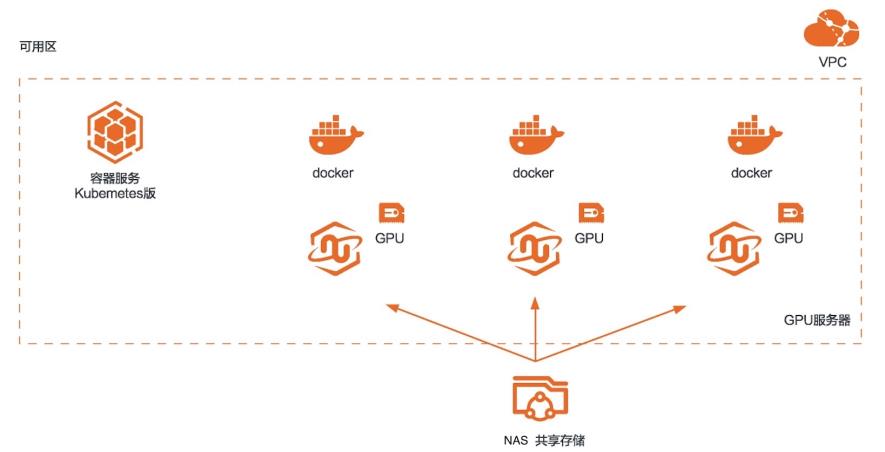
场景描述 本方案适用于使用RAPIDS加速平台 +GPU云服务器来对图像搜索任务进行加 速的场景。相比CPU,利用GPU+ RAPIDS在图像搜索场景下可以取得非常 明显的加速效果。 解决问题 1.搭建RAPIDS加速图像搜索环境 2.使用容器服务Kubernetes版部署图 像搜索环境 3.使用NAS存储计算数据 产品列表 容器服务Kubernetes版 GPU云服务器 文件存储NAS
服务器公网地址在 ECS的管理页面的获取,如下图所示。步骤7 登录后,进入如下页面:26 RAPIDS加速图像搜索 单机部署图搜应用 步骤8 双击文件列表中的 cuml_knn.ipynb,打开 demo。5.3.图像搜索示例程序介绍 示例程序是一个图像搜索的程序。图像识别和搜索,图像搜索任务可以实现以图搜 图,在不同行业应用和业务场景中帮助...
EMR集群安全认证和授权管理
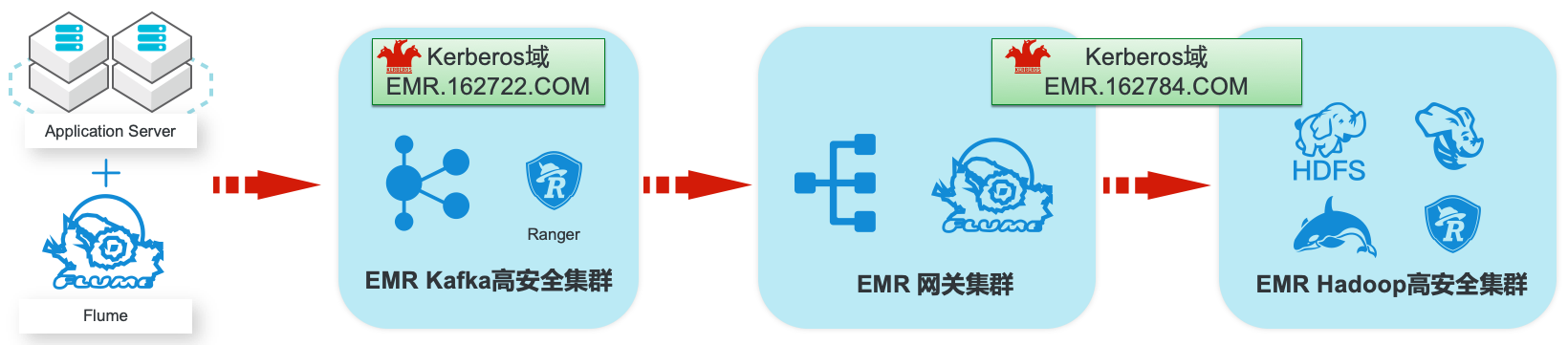
场景描述 阿里云EMR服务Kafka和Hadoop安全集群使 用Kerberos进行用户安全认证,通过Apache Ranger服务进行访问授权管理。本最佳实践中以 Apache Web服务器日志为例,演示基于Kafka 和Hadoop的生态组件构建日志大数据仓库,并 介绍在整个数据流程中,如何通过Kerberos和 Ranger进行认证和授权的相关配置。 解决问题 1.创建基于Kerberos的EMR Kafka和 Hadoop集群。 2.EMR服务的Kafka和Hadoop集群中 Kerberos相关配置和使用方法。 3.Ranger中添加Kafka、HDFS、Hive和 Hbase服务和访问策略。 4.Flume中和Kafka、HDFS相关的安全配 置。 产品列表:E-MapReduce、专有网络VPC、云服务器ECS、云数据库RDS版
Knox作为阿里云 EMR集群的默认服务进行安装,安装后,使用者可以指定阿里 云 RAM子用户作为认证用户,在公网直接访问 Yarn、HDFS、SparkHistory等服 务的 Web UI。1.2.授权(Authorization)授权是任何计算环境的基本安全要求之一。其目标是确保只有适当的人员或流程才能 访问、查看、使用、控制或更改特定的资源、服务或...
Function Compute构建高弹性大数据采集系统
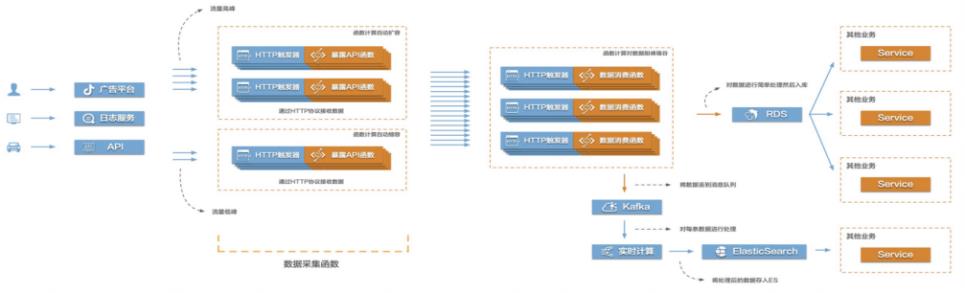
当前互联网很多场景都存在需要将大量的数据信息采集起来然后传输到后端的各类系统服务中,对数据进行处理、分析,形成业务闭环。比如游戏行业中的游戏发行、游戏运营,产互行业中的数字营销,物联网、车联网行业中的硬件、车辆信息上报等等。这些场景普遍存在数据采集量大、数据传输需要稳定且吞吐量大的特点,给整个数据采集传输系统带来很大的挑战。在这个场景中,有三个关键的环节,数据采集、数据传输、数据处理。该最佳实践主要涉
(https://common-buy.aliyun.com)步骤2 从左侧导航栏选择创建场景>创建 PTS场景,在创建 PTS场景页面,完成以下配 置:填写场景名称,这里是 dataCollector 打开场景配置页签,填写 API 名称为 fun01 文档版本:20210806(发布日期)51 Function Compute构建高弹性大数据采集系统 性能压测 单击 GET,进入如下页面:请求...
基于Flink+ClickHouse构建实时游戏数据分析
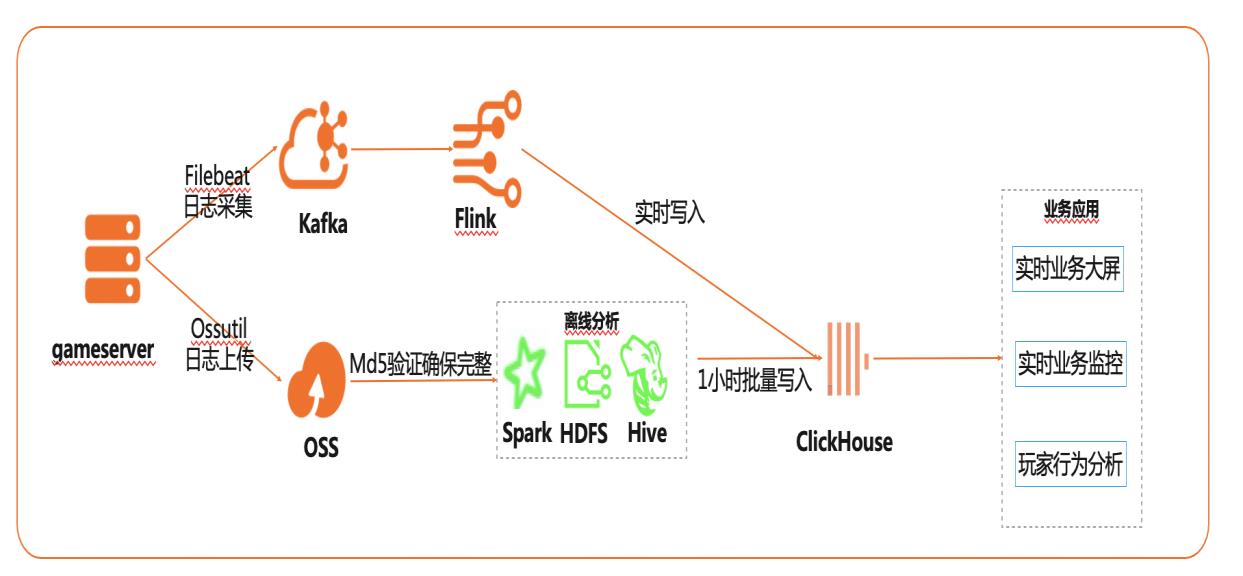
在互联网、游戏行业中,常常需要对用户行为日志进行分析,通过数据挖掘,来更好地支持业务运营,比如用户轨迹,热力图,登录行为分析,实时业务大屏等。当业务数据量达到千亿规模时,常常导致分析不实时,平均响应时间长达10分钟,影响业务的正常运营和发展。 本实践介绍如何快速收集海量用户行为数据,实现秒级响应的实时用户行为分析,并通过实时流计算Flink/Blink、云数据库ClickHouse等技术进行深入挖掘和分析,得到用户特征和画像,实现个性化系统推荐服务。 通过云数据库ClickHouse替换原有Presto数仓,对比开源Presto性能提升20倍。 利用云数据库ClickHouse极致分析性能,千亿级数据分析从10分钟缩短到30秒。 云数据库ClickHouse批量写入效率高,支持业务高峰每小时230亿的用户数据写入。 云数据库ClickHouse开箱即用,免运维,全球多Region部署,快速支持新游戏开服。 Flink+ClickHouse+QuickBI
步骤3 选择按量付费模式,其他参数本实验采用默认配置,确认地域、可用区、VPC都与 game-server服务器配置相同即可。步骤4 在确认订单页面,确认各项信息,确认无误,勾选相关服务协议,并单击立即开通。文档版本:20201224 26 基于 Flink+ClickHouse构建实时游戏数据分析 基础环境部署 步骤5 返回云数据库 ClickHouse集群...
RAPIDS加速机器学习
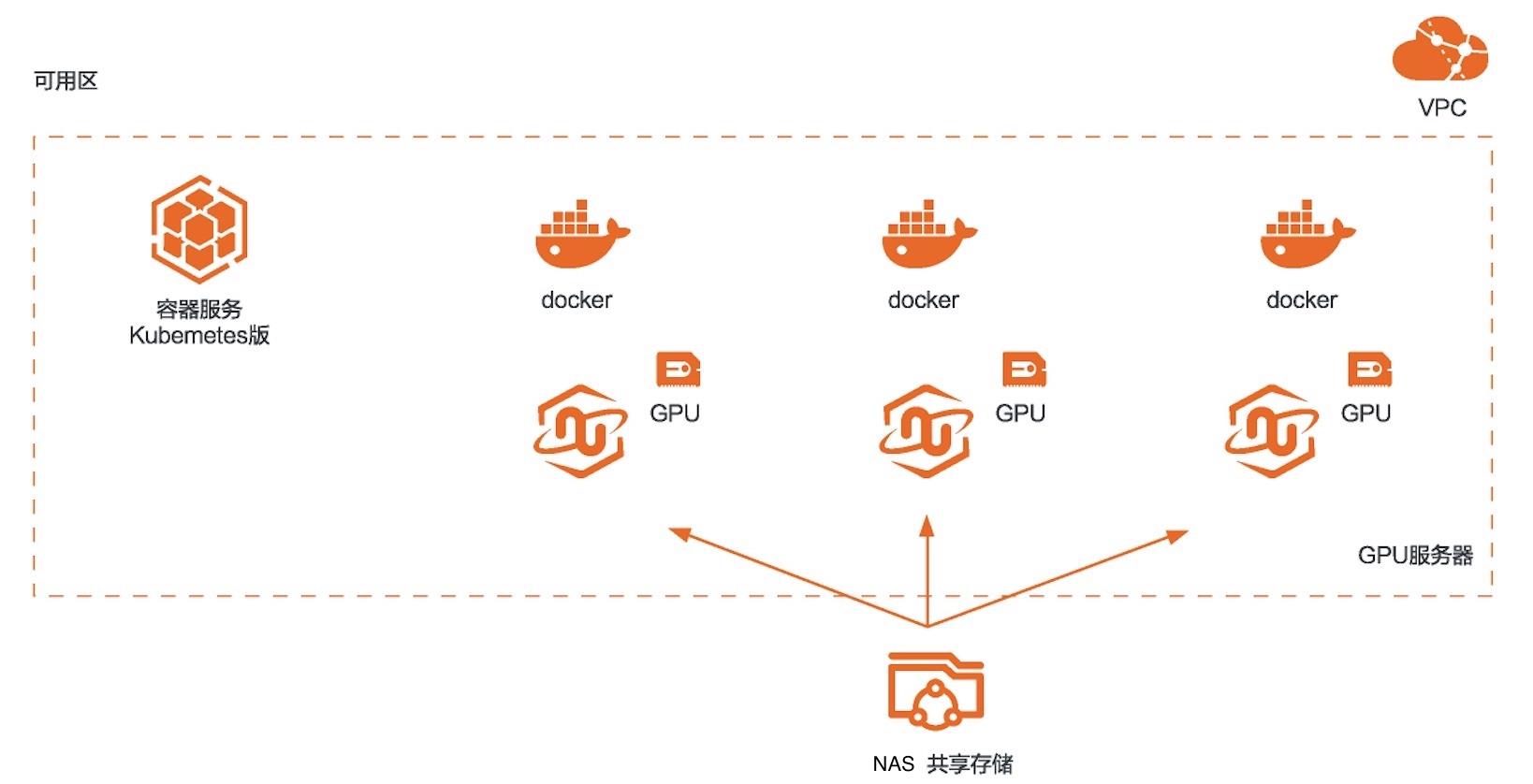
场景描述 本方案适用于使用RAPIDS加速库+GPU 云服务器来对机器学习任务或者数据科学 任务进行加速的场景。相比CPU,利用 GPU+RAPIDS在某些场景下可以取得非常 明显的加速效果。 解决问题 1.搭建RAPIDS加速机器学习环境 2.使用容器服务Kubernetes版部署 RAPIDS环境 3.使用NAS存储计算数据 产品列表 容器服务Kubernetes版 GPU云服务器 文件存储NAS
服务器公网地址在 ECS的管理页面的获取,如下图所示。登录后,进入如下页面:24 文档版本信息:20191209 RAPIDS加速机器学习 使 用容器服 务 A CK部署 RAPIDS环境 步骤5 双击文件列表中的 xgboost_E2E.ipynb,打开 demo。5.1.3.RAPIDS示例程序介绍 示例程序是一个抵押贷款回归的任务。登录成功后,可以看到代码包括以下内容...
自建Hadoop迁移MaxCompute
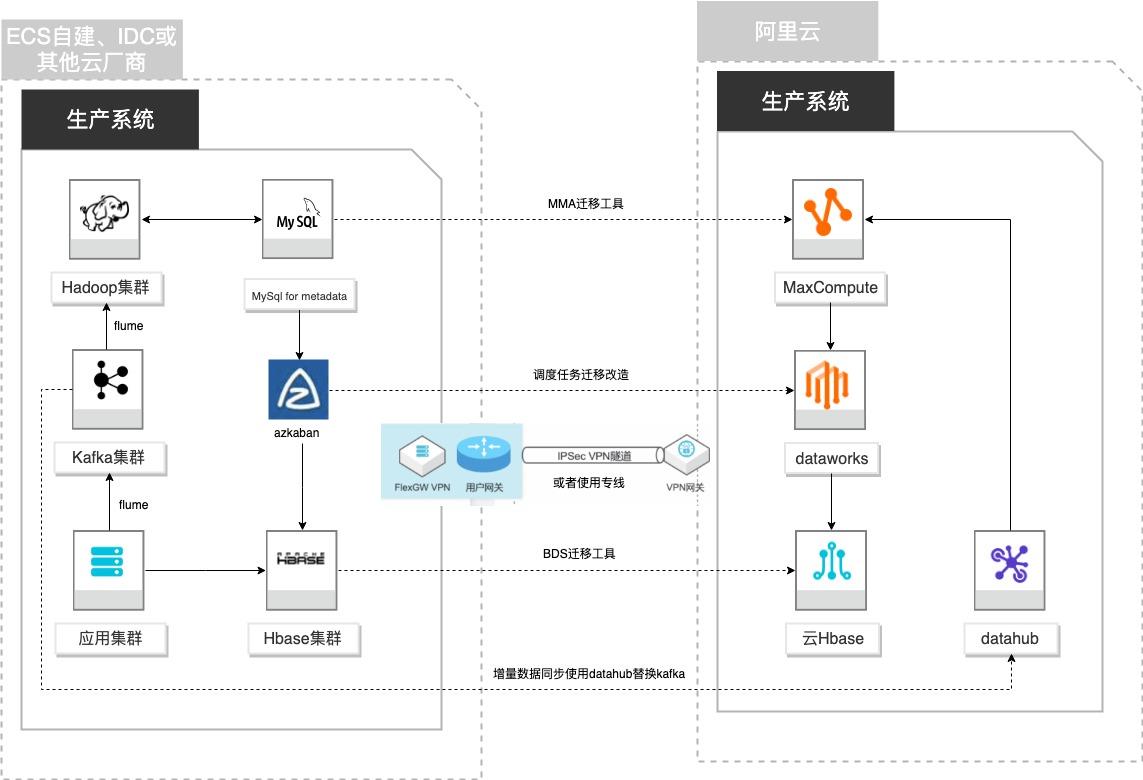
场景描述 客户基于ECS、IDC自建或在友商云平台自建了大数 据集群,为了降低企业大数据计算平台的成本,提高 大数据应用开发效率,更有效保障数据安全,把大数 据集群的数据、作业、调度任务以及业务数据库整体 迁移到MaxCompute和其他云产品。 解决的问题 自建Hadoop集群搬迁到MaxCompute 自建Hbase集群搬迁到云Hbase 自建Kafka或应用数据准实时同步到 MaxCompute 自建Azkaban任务迁移到Dataworks任务 产品列表 MaxCompute,Dataworks、云数据库Hbase版、Datahub、VPC,ECS。
配置项 说明 大数据计算服务 maxcompute_instance MaxCompute 支付方式 后付费 规格类型 标准版 DataWorks 类别 配置项 说明 Dataworks workspace20210722 支付方式 基础版 DataHub 类别 配置项 说明 项目名称 log_records_project 项目描述 接收来自业务服务器的日志信息 Hbase 类别 配置项 说明 文档版本:20210723 9 自...
基于ECI+FaaS构建游戏战斗结算服
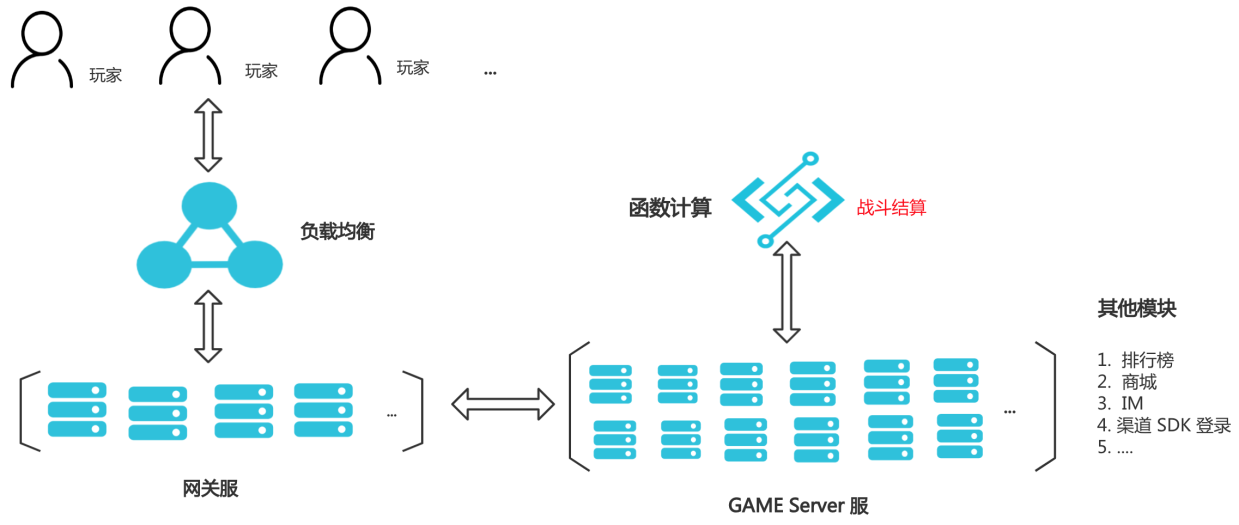
在游戏行业的很多SLG游戏作品中,为了防止客户端作弊,在每局战斗之后,在客户端预判玩家胜利的情况下,需要服务端来进行战斗数据的结算,从而确定玩家是不是真正的胜利。战斗结算是强CPU密集型,结算系统每日需要大量的计算力,尤其是开服或者活动期间忽然涌入的大量玩家,导致需要的计算量瞬间几倍增长,同时需要结算系统保持稳定的延时来保证玩家的用户体验。 1. ECI支持500台实例30S弹出,快速解决业务模块扩容压力。FaaS毫秒级伸缩扩容,化解算力瓶颈,平滑解决暴增调用请求。 2. 降低成本:ECI每天弹性运行8小时,与6代同规格包月相比节省成本40%+,FaaS按需付费,即开即用,节省预留资源消耗。 3. 免运维:FaaS和ECI都是全托管免运维的服务,客户专注业务开发即可。 4. 模块公共化:减轻游戏逻辑服的压力,结算需求复用到类似需求的游戏。
产品列表 阿里云最佳实践分享群 最佳实践频道 容器 Kubernetes ACK 容器实例 ECI 容器镜像仓库 ACR 函数计算 FC 访问控制 RAM 如二维码过期,专有网络 VPC 请搜索群号:31852400 云服务器 ECS 云服务器 ECS(产品名称)文档模板(手册名称)/文档版本信息 阿里云 基于 ECI+FaaS 构建游戏战斗结算服 最佳实践 文档版本:...
新零售商超基于Serverless服务化改造
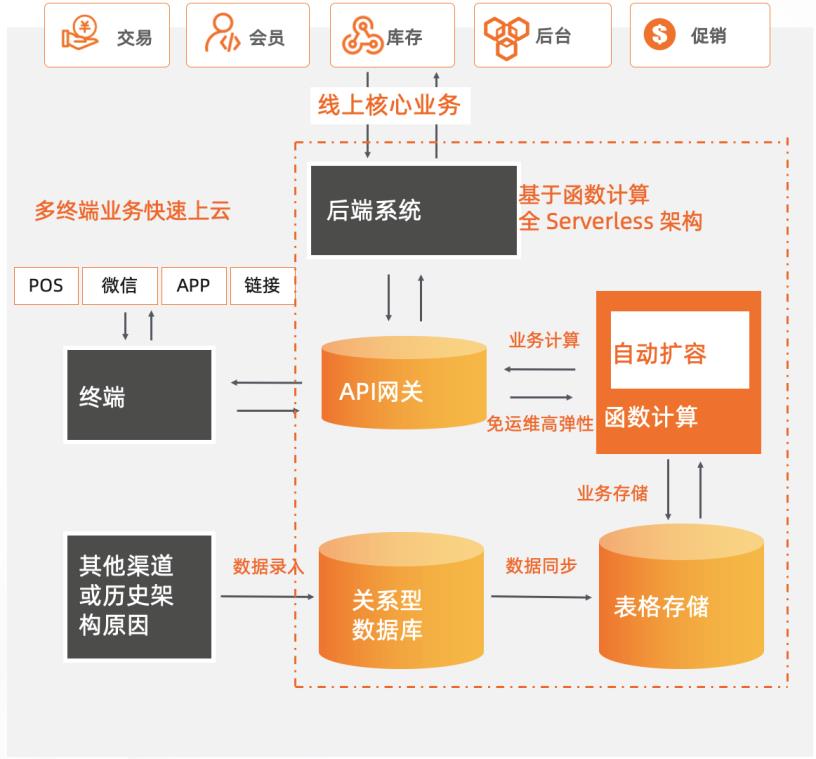
某零售商超行业龙头企业,主要业务涵盖购物中心、大卖场、综合超市、标准超市、精品超市、便利店、无人值守智慧商店等零售业态,涉及全渠道零售、仓储物流、餐饮、消费服务、数据服务、金融业务、跨境贸易等领域。为了持续支持业务高速且稳定地发展,其在快速上云后,将核心业务改造为全Serverless架构的中台模式,采用函数计算 + API网关 + 表格存储OTS 作为计算网络存储核心,弹性支撑日常和大促峰谷所需资源,轻松支撑618/双11/双12大促。 核心价值 l 全 Serverless 架构:FC + API 网关 + OTS Serverless 解决方案。 l 弹性高可用:毫秒级弹性扩容、充足的资源池水位、跨可用区高可用。 l 敏捷开发免运维:函数式极简编程可专注于业务创新,无采购和部署成本、提供监控报警等完备的可观测能力。
是阿里巴巴经济体核心基础设施之一,提供稳定与极致的数据服 务。详见:https://www.aliyun.com/product/ots DTS:支持关系型数据库、NoSQL、大数据(OLAP)等数据源,集数据迁移、订阅 及实时同步功能于一体,能够解决公共云、混合云场景下,远距离、毫秒级异步数 据传输难题。其底层基础设施采用阿里双 11异地多活架构,为...
数据湖-在线学习场景数据分析

场景描述 本场景以在线教育中一个答题闯关类的应用为 例,使用WebServer来模拟演示这类日志数据 的分析处理。通过Nginx和Pythonflask搭建 WebServer,模拟应用中的关键页面,比如登 录、课程内容等,之后构造若干用户使用的模拟 日志数据,投递到数据湖进行分析后获取应用 PV、UV、课程内容访问排行、平均得分等等。 解决问题 基于数据湖(EMR+OSS)搭建大数据平台。 EMR和OSS使用和配置。 数据统一存储到OSS。 产品列表 E-MapReduce 对象存储OSS 云服务器ECS 访问控制RAM 专有网络VPC
user_id={user 8 课程_id} 代表id为8的用户查看了3号 题目 步骤2 源代码位于附件中,下载后目录如下图:app153-server目录下为后端程序,整个目录拷贝到APP服务器(即2.1章节中创建 的ECS服务器)的/home下,如下图:文档版本:20200331 33数据湖-在线学习场景数据分析 应用场景 app153-web目录下为前端程序,将目录及目录...
开源Flink迁移实时计算Flink全托管版最佳实践
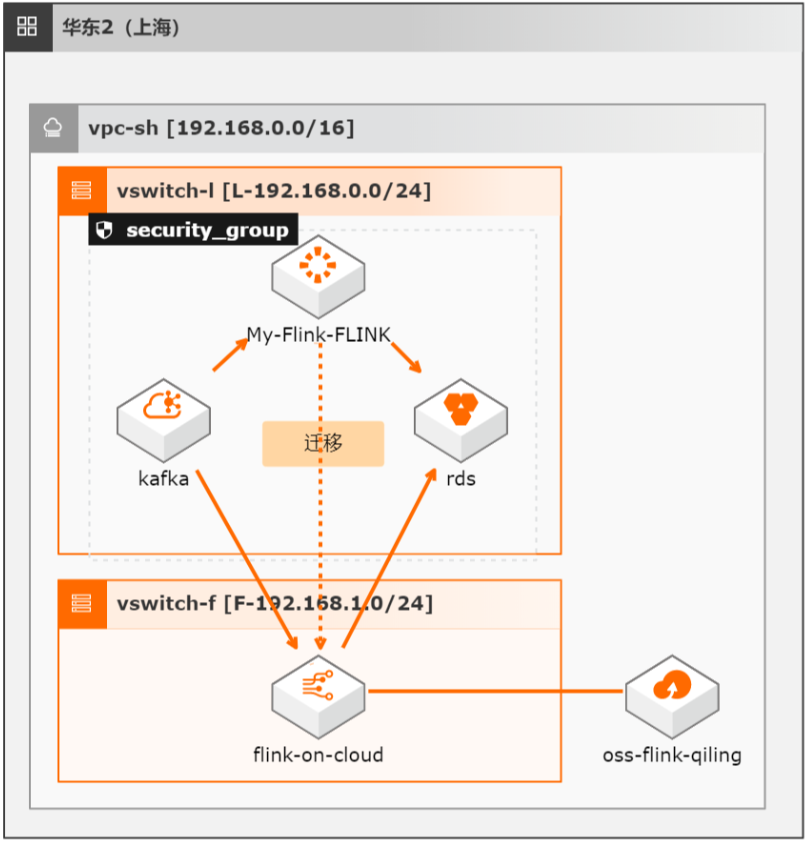
本方案介绍如何将自建开源Flink集群的流式任务(包含Datastream、Table/SQL、PyFlink任务)迁移至阿里云实时计算全托管版。
参见:https://www.aliyun.com/product/rds/mysql 消息队列 Kafka 版:是阿里云基于 Apache Kafka 构建的高吞吐量、高可扩展性 的分布式消息队列服务,广泛用于日志收集、监控数据聚合、流式数据处理、在线 和离线分析等场景,是大数据生态中不可或缺的产品之一,阿里云提供全托管服 务,用户无需部署运维,更专业、更可靠、...
云上日志集中审计
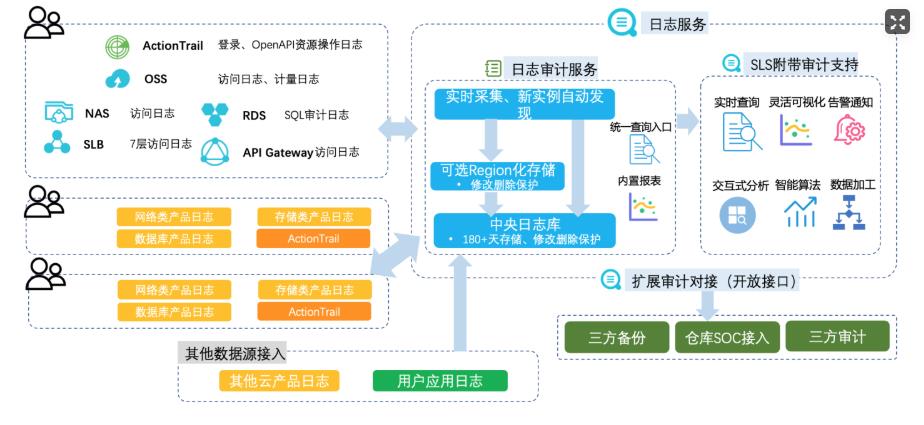
场景描述 云上的各类云产品和客户部署的业务系统会产生各类 日志,企业合规及安全运营等都需要在一个地方能 集中的查看和分析日志;目前各云产品日志大部分 都进了sls,但都是产品独立的project,不方便集中 审计;客户的业务系统日志各种形态都有;多云和混 合云的场景,日志也需要能集中审计。 解决问题 1.所有日志集中到SLS一个中心project下。 2.满足等保合规和内部合规需求。 3.满足运维和安全运营需求。 产品列表 日志服务SLS 专有网络VPC 弹性公网IPEIP 负载均衡SLB 云服务器ECS 云数据库RDS 云防火墙CFW
文档版本:20200630(发布日期)25 云上日志集中审计 WEB服务日志采集 步骤6 logtail配置:APACHE配置字段参数:LogFormat"%h%l%u%t \"%r\"%>s%b \"%{Referer}i\"文档版本:20200630(发布日期)26 云上日志集中审计 WEB服务日志采集 \"%{User-Agent}i\"%D%f%k%p%q%R%T%I%O"customized 如果是其他如 Nginx 等,配 置 参 数 ...
- 产品推荐
- 这些文档可能帮助您