Function Compute构建高弹性大数据采集系统
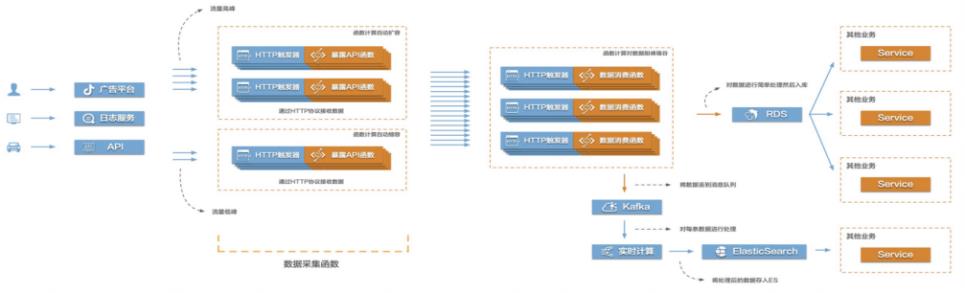
当前互联网很多场景都存在需要将大量的数据信息采集起来然后传输到后端的各类系统服务中,对数据进行处理、分析,形成业务闭环。比如游戏行业中的游戏发行、游戏运营,产互行业中的数字营销,物联网、车联网行业中的硬件、车辆信息上报等等。这些场景普遍存在数据采集量大、数据传输需要稳定且吞吐量大的特点,给整个数据采集传输系统带来很大的挑战。在这个场景中,有三个关键的环节,数据采集、数据传输、数据处理。该最佳实践主要涉
第一个函数调用第二个函数 目前两个函数都创建好了,下面的工作就是由第一个函数接收到数据后拉起第二个函 数发送消息给 Kafka。我们只需要对第一个函数做些许改动即可。步骤1 进入函数计算控制台,找到我们创建的服务下的 fun01这个函数,需要在函数详情页在 线编辑 Python代码,代码修改如下:#-*-coding:utf-8-*-import ...
开源Flink迁移实时计算Flink全托管版最佳实践
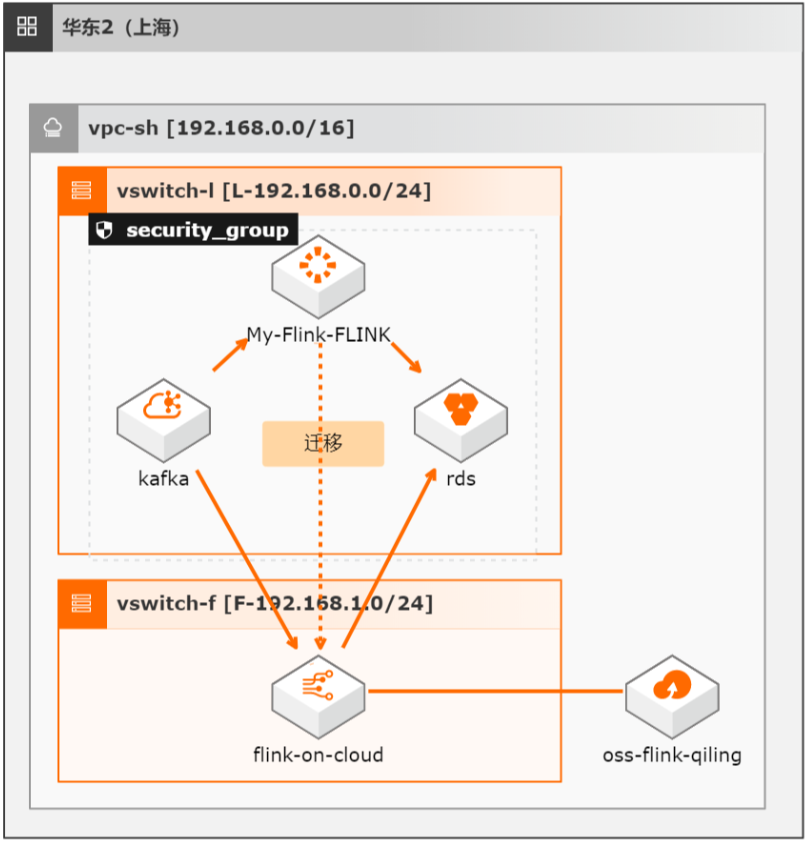
本方案介绍如何将自建开源Flink集群的流式任务(包含Datastream、Table/SQL、PyFlink任务)迁移至阿里云实时计算全托管版。
文档版本:20211222 12 开源 Flink迁移实时计算Flink全托管版 基础环境搭建 步骤2 在 Flink SQL中添加以下作业,注意修改 properties.bootstrap.servers为前面创建 的 kafka的接入点。CREATE TEMPORARY TABLE data_in(id VARCHAR,order_value FLOAT)WITH('connector'='datagen','rows-per-second'='100','fields.id.length'...
- 产品推荐
- 这些文档可能帮助您