云原生数据湖分析DLA
阿里云云原生数据湖分析是新一代大数据解决方案,采取计算与存储完全分离的架构,支持对象存储(OSS)、RDS(MySQL等)、NoSQL(MongoDB等)数据源的消息实时归档建仓,提供Presto和Spark引擎,满足在线交互式查询、流处理、批处理、机器学习等诉求。内置大量优化+弹性,比开源自建集群最高降低50%+的成本,最快可1分钟级拉起300个计算节点,快速满足业务资源要求。
数据湖分析采用Serverless形态,无基础设施和管理成本,互联网直接访问,开箱即用,按需付费,不需要长期持有分析成本,升级期间对业务影响小,产品迭代敏捷快速.Presto引擎.Presto引擎是数据湖分析基于Presto打造的交互式分析引擎,接入MySQL协议,可使用任何兼容MySQL协议的工具来进行数据分析,适合Adhoc查询、BI分析、...
来自:
云产品
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
自建 Hive数据仓库跨版本迁移到阿里云 Databricks数据洞察 业务架构 场景描述 客户在 IDC或者公有云环境自建 Hadoop集群 构建数据仓库和分析系统,购买阿里云 Databricks数据洞察集群之后,涉及到数仓数 据和元数据的迁移以及 Hive版本的订正更新。方案优势 1.全托管 Spark集群免运维,节省人力成 本。2.Databricks数据洞察...
Databricks数据洞察
阿里云Databricks数据洞察是基于Apache Spark的全托管数据分析平台, 内核采用更高效、稳定的商业版Databricks Runtime和Delta Lake。可满足数据分析师、数据工程师和数据科学家在大数据场景下对数据湖分析、实时数仓、离线数仓、BI数据分析、AI机器学习等需求
多种用户角色共享数据,交互式协同合作.交互式协同工作.可以协同工作的工作空间,交互式的作业执行方式,支持Spark、PySpark、Spark R和Spark SQL类型的作业,分析结果可视化展示.集群之间共享数据库、表的元信息,无需重复创建.100%兼容开源Spark,迁移成本低,性能表现优异.完全兼容Spark生态.在Apache Spark基础上做了...
来自:
云产品
游戏数据运营融合分析
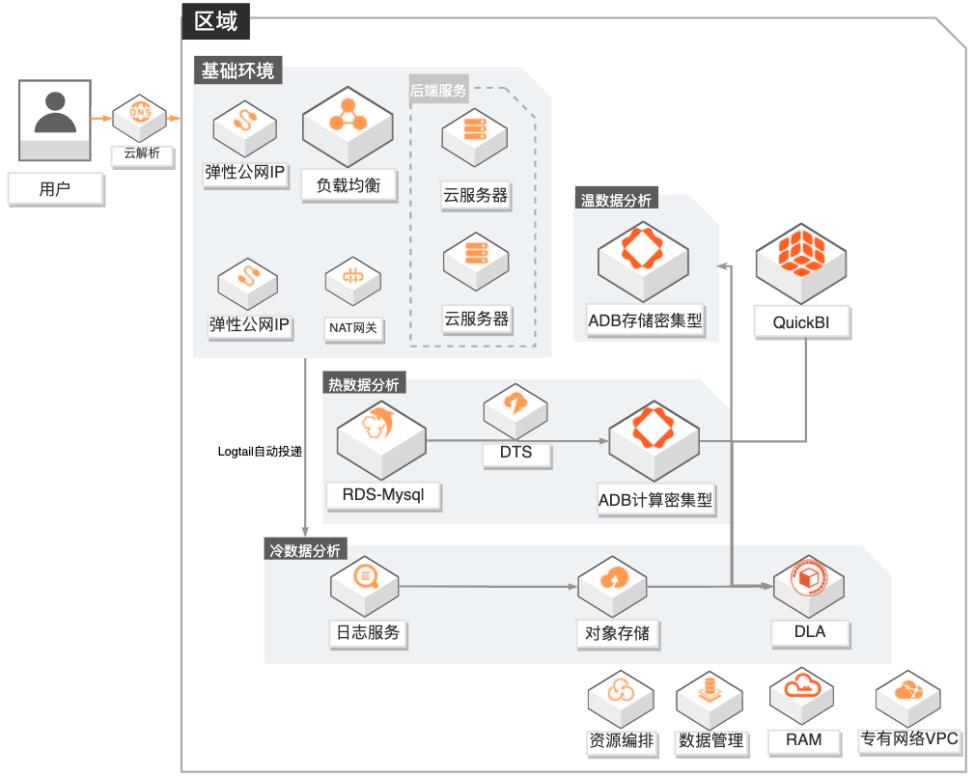
场景描述 1.游戏行业有结构化和非结构化数据融合分 析需求的客户。 2.游戏行业有数据实时分析需求的客户,无法 接受T+1延迟。 3.对数据成本有一定诉求的客户,希望物尽其 用尽量优化成本。 4.其他行业有类似需求的客户。 方案优势/解决问题 1.秒级实时分析:依托ADB计算密集型实例, 秒级监控DAU等数据,为广告投放效果提 供有力的在线决策支撑。 2.高效数据融合分析:打通结构化和非结构化 数据,支撑产品体验分析;广告买量投放效 果实时(分钟级)分析,渠道的评估更准确。 3.低成本:DLA融合冷数据分析+ADB存储密 集型温数据分析+ADB计算密集型热数据分 析,在满足各种分析场景需求的同时,有效 地降低的客户的总体使用成本。 4.学习成本低:DLA和ADB兼容标准SQL语 法,无需额外学习其他技术。 产品列表 专有网络VPC、负载均衡SLB、NAT网关、弹性公网IP 云服务器ECS、日志服务SLS、对象存储OSS 数据库RDSMySQL、数据传输服务DTS、数据管理DMS 分析型数据库MySQL版ADS 数据湖分析DLA、QuickBI
更多信息,请参见:help.aliyun.com/document_detail/93776.html Data Lake Analytics(简称 DLA):Data Lake Analytics是 Serverless化的交互 式联邦查询服务。无需 ETL,使用标准 SQL即可分析与集成对象存储(OSS)、数据库(PostgreSQL/MySQL等)、NoSQL(TableStore等)数据源的数据。更多 信息,请参见:help.aliyun....
云数据库 SelectDB 版
阿里云数据库 SelectDB 是现代化实时数据仓库 SelectDB 在阿里云上的全托管服务,内核基于业界领先的开源分析型数据库 Apache Doris 研发,由阿里云和飞轮科技联合打造。阿里云数据库 SelectDB 聚焦于满足企业级大数据分析需求,广泛应用于实时报表分析、即席多维分析、日志检索分析、数据联邦与查询加速等场景,致力于为客户提供极致性能、简单易用的数据分析服务。
秒级交互式分析提供丰富的即席分析函数(如留存分析函数、画像分析函数等)、正交位图处理等能力,大幅简化即席多维分析的开发过程,同时实现秒级交互式的数据分析体验。相关产品云数据库 SelectDB 版本产品实时计算Flink版云消息队列 Kafka 版大数据开发治理平台 DataWorks在线咨询日志检索分析面对庞大的日志数量,日志...
来自:
云产品
云数据库MongoDB版
阿里云云数据库MongoDB版是完全兼容MongoDB协议、高度兼容DynamoDB协议的在线文档型数据库服务。支持单节点、双节点、副本集和分片集群四种部署架构,能够满足不同的业务场景需要。
例如与阿里云原生数据湖分析服务DLA的Serverless Spark对接,满足在线交互式查询、批处理、机器学习等诉求.Serverless Spark对接MongoDB快速入门.云上云下数据互通,大数据Spark系统对接应用.数据生态:数据自由流转,应用更灵活.提供CPU利用率、IOPS、连接数、磁盘空间等实例信息实时监控及报警,随时随地了解实例动态....
来自:
云产品
数据库异地灾备
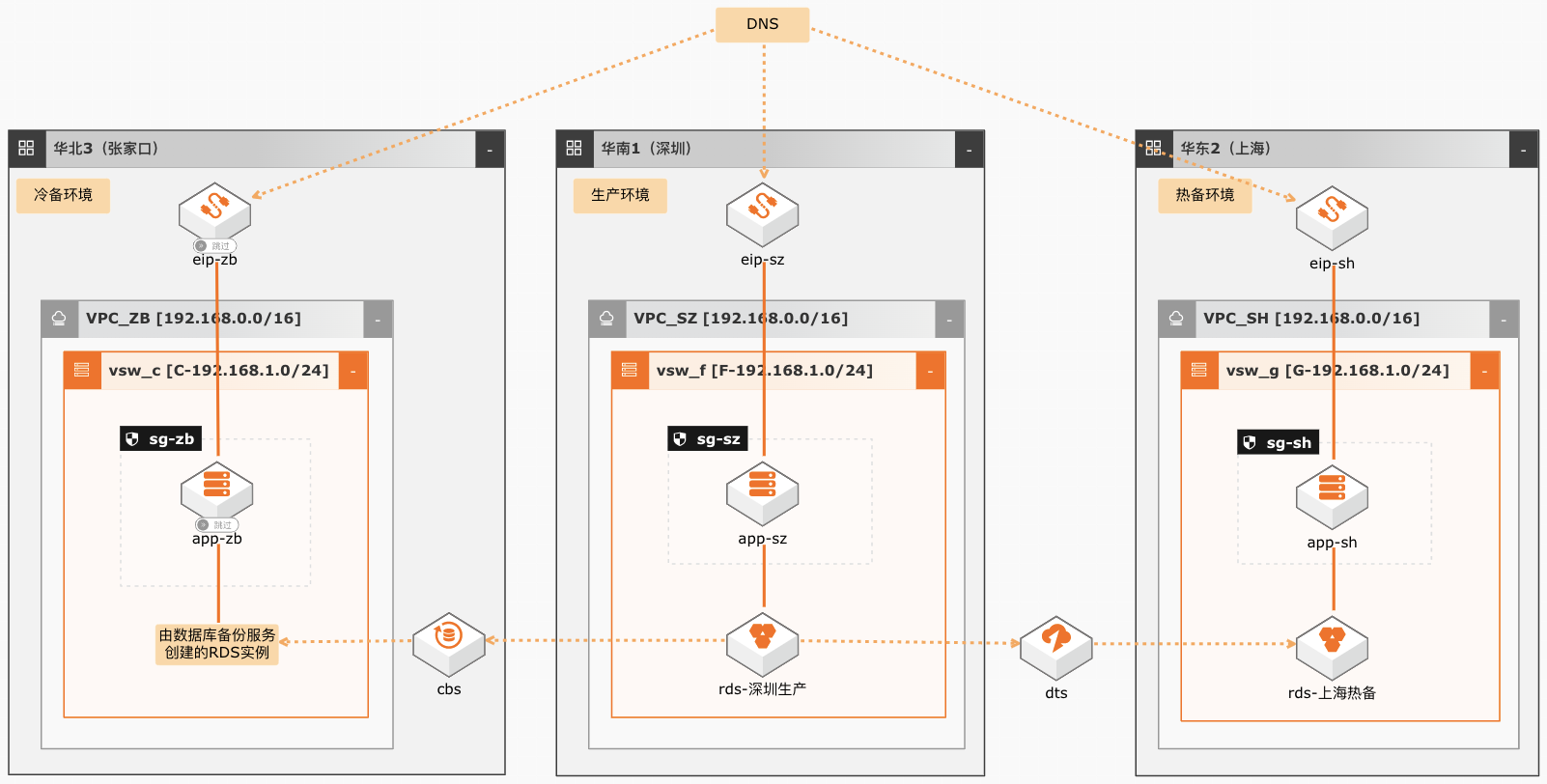
场景描述 适用于不满足于单地域,对数据可靠性 (RPO)和服务可用性(RTO)要求更高 的,希望防范断电、断网等机房故障,抵 御地震、台风等自然灾害,具备异地容灾 备份恢复能力的客户业务场景。 解决问题 1.实时备份,RPO达到秒级 2.表级恢复,故障恢复时间大大缩短 3.长期归档,自动管理备份生命周期 4.异地灾备,构建数据库灾备中心 产品列表 专有网络VPC 云服务器ECS 弹性公网IP(EIP) 负载均衡SLB 云数据库RDSMySQL 数据库备份服务DBS 对象存储服务OSS 数据湖分析服务DLA 数据管理服务DMS 数据传输服务DTS
无服务器(Serverless)化的云上交互式查询分析服务。无需 ETL,就可通过此服务在云上通过标准 JDBC 直接对阿里云 OSS、TableStore、RDS等不同数据源里存储的数据轻松进行查询 和分析。DLA 无缝集成各类商业分析工具,提供便捷的数据可视化。详见:https://www.aliyun.com/product/datalakeanalytics DMS:数据管理服务...
E-MapReduce
阿里云E-MapReduce(简称EMR)是阿里云云原生数据湖的核心计算引擎,全面支持Hadoop、Spark、HBase、Hive、Flink等大数据组件,为客户提供企业级开源大数据平台服务。通过有效弹性伸缩和数据分层存储机制,相较于传统HDFS固定集群方式,可节省50%以上的费用,同时支持创建抢占式实例,相比按量付费的购买方式,可节省50%~80%的费用。
开源的分布式SQL查询引擎,适用于交互式查询分析.开源OLAP分析引擎,主要特性:列式存储、MPP架构、支持SQL、实时的数据更新、支持索引等.一种数据湖的存储格式,提供更新数据和删除数据的能力以及消费变化数据的能力.开源MPP架构的OLAP分析引擎,支持亚秒级的数据查询和多表Join.丰富的组件支持,可以根据需要进行组件的...
来自:
云产品
实时数仓Hologres
Hologres(原交互式分析)是一站式实时数据仓库引擎,支持海量数据实时写入、实时更新、实时分析,支持标准SQL(兼容PostgreSQL协议),支持PB级数据多维分析(OLAP)与自助分析(Ad Hoc),支持高并发低延迟的在线数据服务(Serving),与MaxCompute、Flink、DataWorks深度融合,提供离在线一体化全栈数仓解决方案。
支持数据湖场景,支持JSON等半结构化数据,OSS、DLF简易入仓.总有一款适合你的业务.32核新用户首月888元.32核新用户首月888元.32核新用户首月888元.实时数仓20讲.15000CU时计算包原价5313元,限时新购仅需59元.15000CU时计算包原价5313元,限时新购仅需59元.<查看全部产品.Hologres是一站式实时数据仓库引擎,支持海量数据...
来自:
云产品
云原生大数据计算服务MaxCompute
阿里云云原生大数据计算服务MaxCompute是面向分析的企业级云数仓,作为一体化大数据智能计算平台ODPS的大规模批量计算引擎,MaxCompute以 Serverless 架构提供快速、全托管的在线数据仓库服务,使您经济高效的分析处理海量数据,进行敏捷的业务洞察。
集成对数据湖(OSS或Hadoop HDFS)的访问分析,支持外表映射、Spark直接访问方式开展数据湖分析;在一套数仓服务和用户接口下,实现湖与仓的关联分析.支持流式采集和近实时分析.支持流式数据实时写入并在数据仓库中开展分析;与云上主要流式服务深度集成,轻松接入各种来源流式数据;高性能秒级弹性并发查询,满足近实时...
来自:
云产品
云数据库 Cassandra 版
Cassandra是连续9年DB-Engines排名第一的宽表数据库,支持类SQL语法CQL,开发体验类似MySQL,可扩展PB级存储。推出企业版Lindorm for Cassandra云原生多模数据库,采用存储计算分离架构,支持海量数据的低成本存储和按需付费,具备更高性价比和更为丰富的企业级功能。
Presto满足在线交互式需求.Serverless分析引擎Spark&Presto.基于Spark RDD构建了统一的时空数据模型,方便建模.Ganos时空数据分析.综合治理,支持丰富的自研、开源引擎.Dataworks构建数据湖统一开发平台.云数据库Cassandra版支持节点升配及降配:从容应对可预知的业务潮汐。集群可小可大:单节点起配,起配门槛低。可扩展至...
来自:
云产品
- 产品推荐
- 这些文档可能帮助您