智能数据建设与治理Dataphin
Dataphin遵循阿里巴巴集团多年实战沉淀的大数据建设OneData体系(OneModel、OneID、OneService),集产品、技术、方法论于一体,一站式地为您提供集数据引入、规范定义、智能建模研发、数据萃取、数据资产管理、数据服务等的全链路智能数据构建及管理服务。助您打造属于自己的标准统一、资产化、服务化和闭环自优化的智能数据体系,驱动创新。
适合业务相对稳定,且有小型的数据团队负责数据研发及管理的企业。此版本具备一体化研发及数据治理能力,可帮助企业完成数仓建设,保障质量及安全合规.基础研发版¥8,500/月 起.满足成熟企业对数据中台建设的诉求,通过盘点企业的数据资产,形成统一的规范及标准进行数据资产的治理,构建标准统一、口径一致、质量可靠的...
来自:
云产品
云上高并发系统改造
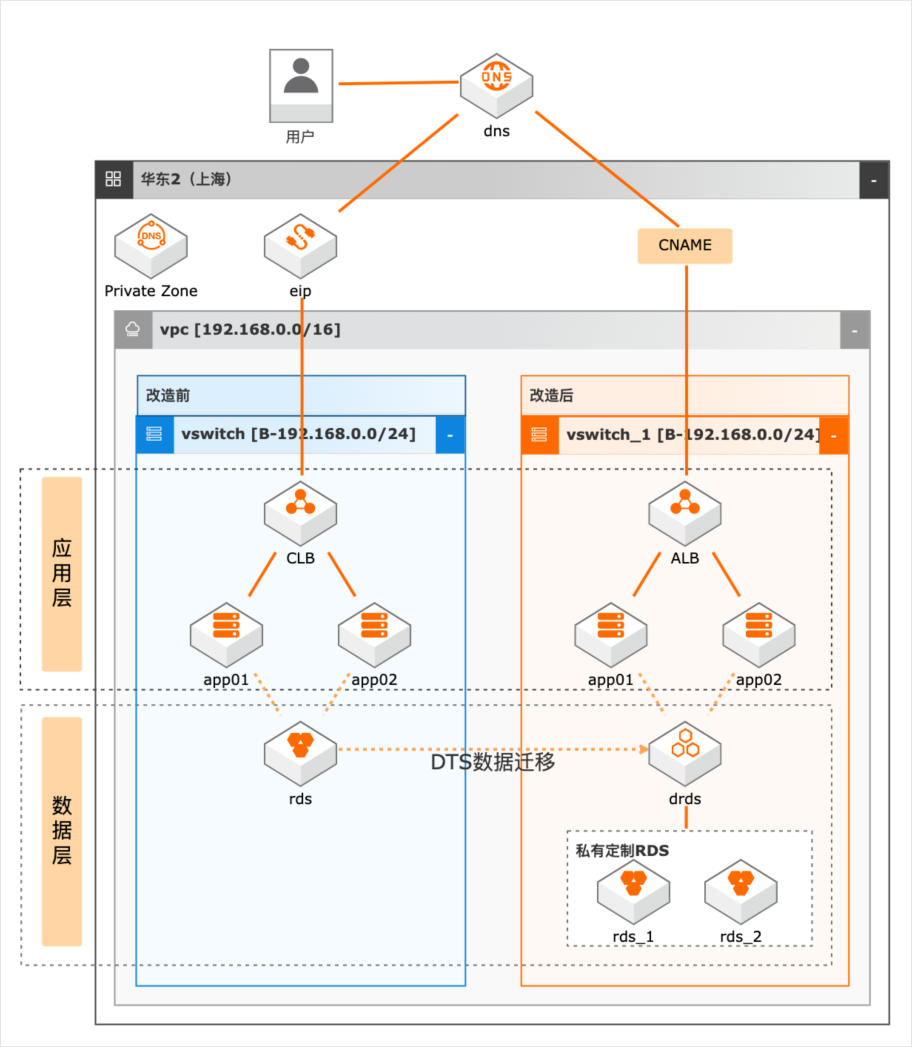
场景描述 随着业务的发展,系统并发压力越来越大,如何 进行系统改造以满足高并发场景的业务需求成 为了一个技术难题。本实践抽象于客户的实际场 景,提供高并发下系统改造的理论指导和部分实 操演示。主要适用于以下场景: 1.系统并发压力大,需要进行系统应用改造。 2.数据层并发压力大,需进行分库分表改造。 3.数据库数据量巨大,亟待分库分表解决查询 和写入瓶颈的场景。 方案优势/解决问题 1.在水平扩展阶段,我们除了通过SLB做负载 均衡外,我们可以通过SLB下挂nginx的方 式,增加负载均衡侧的可扩展性 2.在数据库拆分阶段,在做好数据规划后,我 们借助DTS进行数据迁移,通过DRDS将 RDS MySQL的数据拆分到多个分库和分 表中。 产品列表 专用网络VPC 负载均衡SLB 云服务器ECS 数据库RDSMySQL 数据传输服务DTS PrivateZone 分布式关系型数据库DRDS
尽可能避免跨库查询:关联查询的数据尽量分散到同一个分片中,跨库查询对系 统性能损耗很大。避免跨分表联表查询的方式有:a)剥离出高频访问的表,与核心表 1:1关系的,进行反范式设计,将核心表加 宽 b)如果与核心表是 N:1关系的,将高频访问字段冗余到核心表中 c)低频访问数据,业务功能设计上,避免一页展示大而全,...
基于Flink+ClickHouse构建实时游戏数据分析
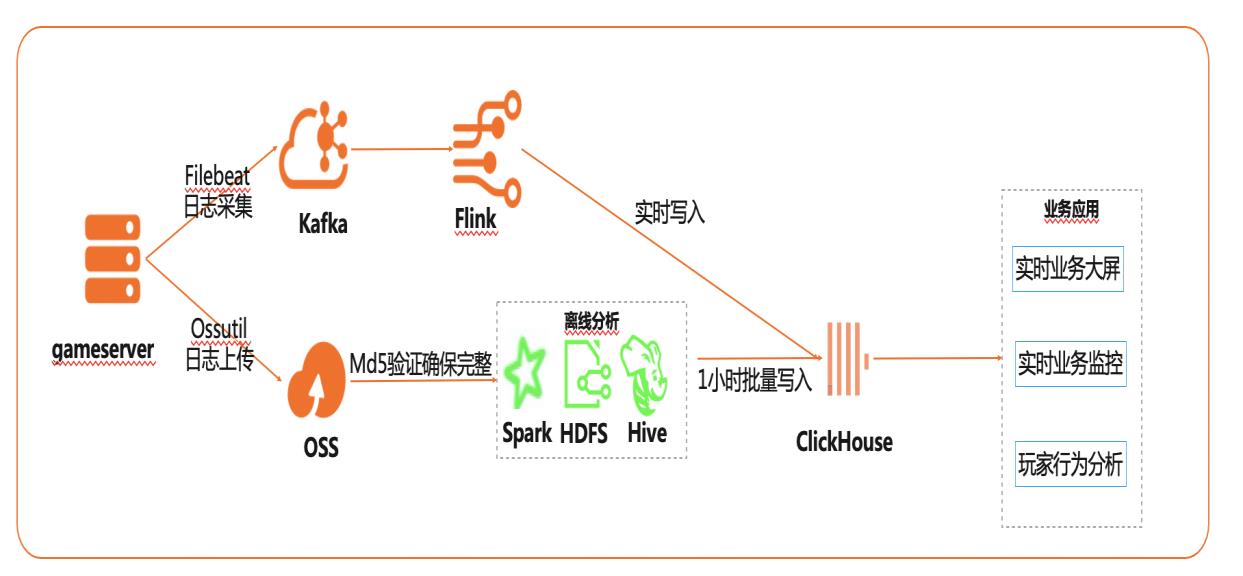
在互联网、游戏行业中,常常需要对用户行为日志进行分析,通过数据挖掘,来更好地支持业务运营,比如用户轨迹,热力图,登录行为分析,实时业务大屏等。当业务数据量达到千亿规模时,常常导致分析不实时,平均响应时间长达10分钟,影响业务的正常运营和发展。 本实践介绍如何快速收集海量用户行为数据,实现秒级响应的实时用户行为分析,并通过实时流计算Flink/Blink、云数据库ClickHouse等技术进行深入挖掘和分析,得到用户特征和画像,实现个性化系统推荐服务。 通过云数据库ClickHouse替换原有Presto数仓,对比开源Presto性能提升20倍。 利用云数据库ClickHouse极致分析性能,千亿级数据分析从10分钟缩短到30秒。 云数据库ClickHouse批量写入效率高,支持业务高峰每小时230亿的用户数据写入。 云数据库ClickHouse开箱即用,免运维,全球多Region部署,快速支持新游戏开服。 Flink+ClickHouse+QuickBI
本实践介绍如何快速收集海量用户行为数 据,实现秒级响应的实时用户行为分析,并 通过实时流计算、云数据库 ClickHouse等 技术进行深入挖掘和分析,得到用户特征和 画像,实现个性化系统推荐服务。产品列表 最佳实践频道 阿里云最佳实践分享群 专有网络 VPC 弹性公网 IP EIP 云服务器 ECS 消息队列 Kafka版 云数据库 ...
大数据系统基准性能测试最佳实践
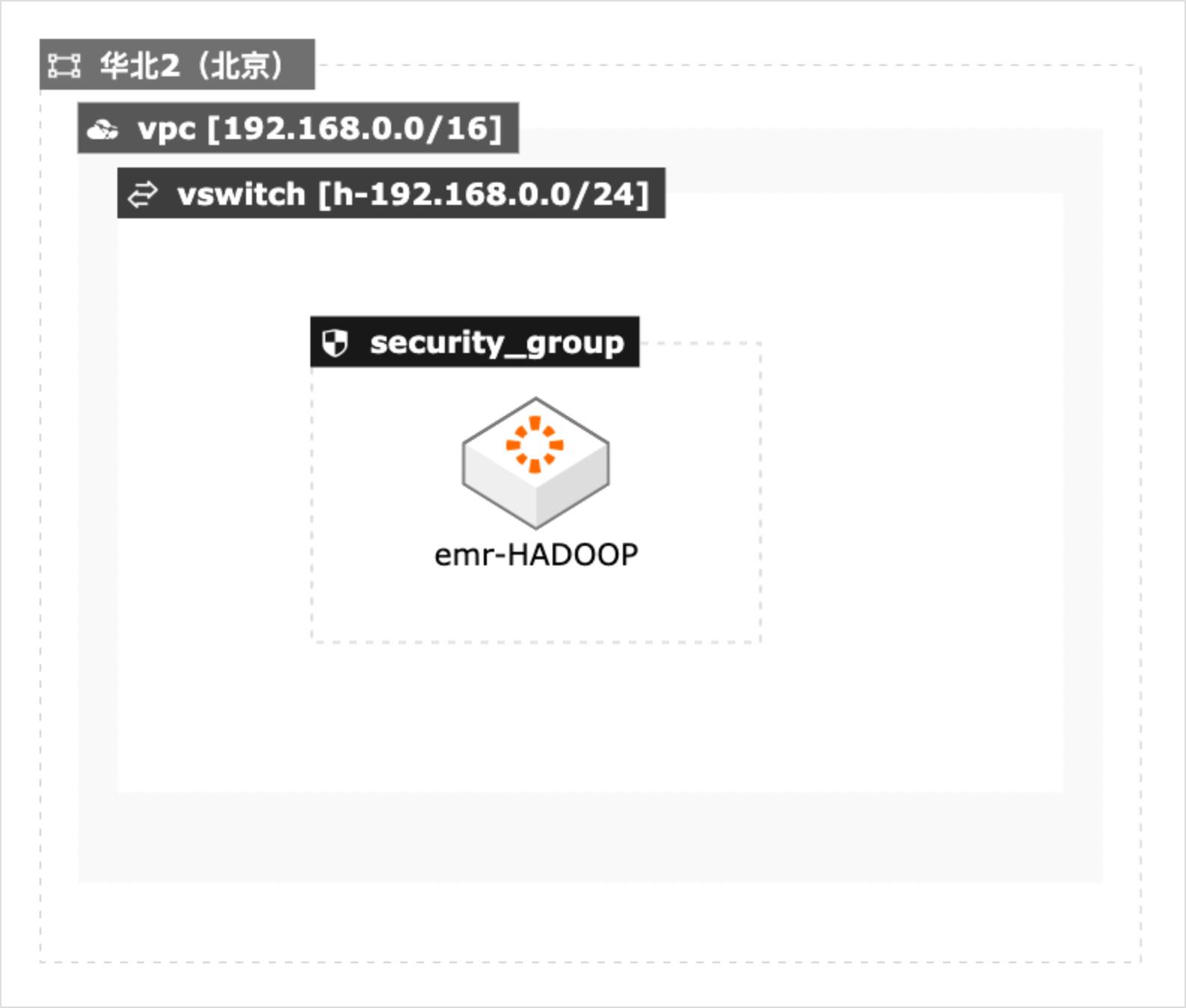
本方案适用于在阿里云上进行大数据基准性能测试的场景,包括 Teragen和Terasort测试,TestDFSIO测试。本文采用CADT工具结合阿里云的E-MapReduce服务快速构建测试集群,并提供了Teragen和Terasort测试,TestDFSIO测试的测试脚本,便于迅速开展测试。
大数据系统基准性能测试 最佳实践 部署架构图 场景描述 本方案适用于大数据系统基准性能测 试的场景,这里以 Terasort&Teragen 测试,以及 TestDFSIO测试,来衡量 大数据系统的基准能力。解决问题 1.使用 CADT快速构建大数据系统 测试环境 2.进行 Terasort&Teragen 3.进行 TestDFSIO测试 产品列表 EMR 云服务器 ECS 云速搭 ...
数据总线Datahub
数据总线(DataHub)服务是阿里云提供的流式数据(Streaming Data)服务,它提供流式数据的发布(Publish)和订阅(Subscribe)的功能,拥有高吞吐量、高稳定性、低成本等特点,与阿里云大数据生态系统完美打通,让您可以轻松构建基于流式数据的分析和应用。
数据总线(DataHub)服务是阿里云提供的流式数据(Streaming Data)服务,它提供流式数据的发布(Publish)和订阅(Subscribe)的功能,让您可以轻松构建基于流式数据的分析和应用.提供多种SDK、API和Flume、Logstash等第三方插件,让您高效便捷的把数据接入到数据总线.提供DataConnector模块,稍作配置即可把接入的数据实时同步到...
来自:
云产品
云原生数据仓库AnalyticDB MySQL数据仓库
阿里云云原生数据仓库AnalyticDB MySQL版(简称AnalyticDB)是融合数据库、大数据技术于一体的云原生企业级数据仓库平台。云原生数据仓库AnalyticDB MySQL版支持数据实时写入和同步更新、实时计算和实时服务,可用于构建企业级报表系统、数据仓库和数据服务引擎。
通过智能的业务分析系统快速获得实时的业务数据,实现海量数据的即席分析查询,充分挖掘数据价值,支撑更高效的业务决策.运营效率提升.云服务器ECS.云数据库RDS MySQL版.数据传输DTS.推荐搭配产品.物联网:终端信息实时查.查询效率提升数倍,综合成本大幅降低.该场景客户需降低海量的历史订单和监控数据的存储成本,并确保...
来自:
云产品
数据迁移上云
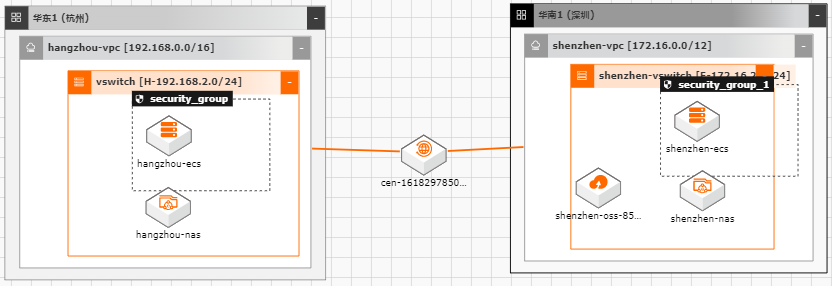
随着越来越多的企业选择将业务系统上云,各种类型的数据如何便捷、平滑的迁移上 云,成了用户上云较为关注的点;业务上云后,因为业务或者其他方面调整等因素, 也存在如跨区域,跨账号等数据迁移的场景。针对以上需求,阿里云上提供了较为丰 富的工具(如ossimport)、服务(在线迁移服务),旨在能够帮助客户便捷进行数据迁 移。 本文通过云架构设计工具CADT来快速创建云上基础资源,并以杭州区域来模拟线 下IDC(或友商),深圳区域模拟阿里云云上资源。通过云上的工具命令、服务来提 供常见数据迁移场景的最佳实践。
示例应用场景 线下 IDC数据 迁移至阿里云 OSS 线下 NAS数据迁移至阿里云 NAS 线上杭州区域 NAS数据通过 CEN迁 移至深圳区域 NAS 最佳实践频道 阿里云最佳实践分享群 云服务器 ECS(产品名称)文档模板(手册名称)/文档版本信息 阿里云 企业上云实践 数据迁移上云最佳实践 文档版本:20201013 文档版本:20150122(发布日期...
异地双活场景下的数据双向同步
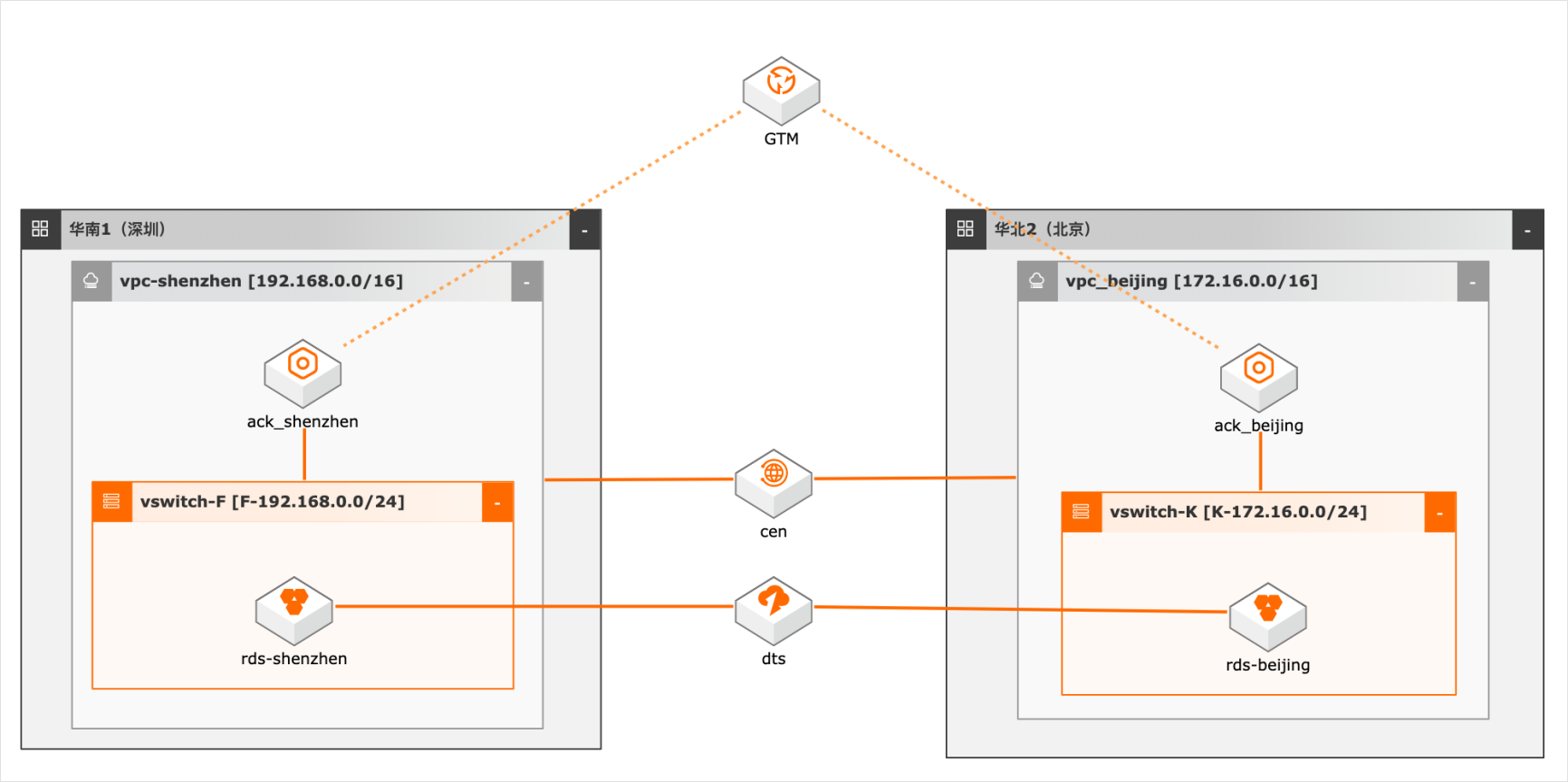
概述 随着客户业务规模的扩大,对系统高可用性要求越来越高,越来越多用户采用异地双活/多活架构,多活架构往往涉及业务侧做单元化改造,本方案仅模拟用户已做单元化改造后的数据双向同步,数据库采用双主架构,本地写本地读,同时又保证双库的数据一致性,为业务增加可用性和灵活性。 适用场景 数据库双向同步 数据库全局ID不冲突 双活架构的数据库建设问题 技术架构 本实践方案基于如下图所示的技术架构和主要流程编写操作步骤: 方案优势 DTS双向同步,采用独立模块避免数据同步占用系统资源。 奇偶ID涉及,避免数据冲突。 DTS多种处理冲突的方式供业务选择。 安全:原生的多租户系统,以项目进行隔离,所有计算任务在安全沙箱中运行。
随着客户业务规模的扩大,对系统高可用性要求越 数据库双向同步 来越高,越来越多用户采用异地双活/多活架构,多 数据库全局 ID不冲突 活架构往往涉及业务侧做单元化改造,本方案仅模 双活架构的数据库建设问题 拟用户已做单元化改造后的数据双向同步,数据库 采用双主架构,本地写本地读,同时又保证双库的数 据一致性,为...
EMR本地盘实例大规模数据集测试
场景描述 阿里云为了满足大数据场景下的存储需求,在云 上推出了本地盘D1机型,这个系列提供了本地 盘而非云盘作为存储,提高了磁盘的吞吐能力, 发挥Hadoop的就近计算优势。阿里云EMR 产品针对本地盘机型,推出了一整套的自动化运 维方案,帮助用户方便可靠地使用本地盘机型, 不需要关注整个运维过程同时数据的高可靠和 服务的高可用。 解决问题 1.云盘多份冗余数据导致成本高 2.磁盘吞吐量不高 3.节点的高可靠分布问题 4.本地盘与节点的故障监控问题 5.数据迁移时自动决策问题 6.自动故障节点迁移与数据平衡问题 产品列表 EMR(E-MapReduce) 本地盘 VPC
Master节点 通常可以生成 1TB的数据进行基准性能测试,首先进入 hive-testbench目录下执行如 下脚本并加载测试数据 参数说明:数据集规模参数单位为 GB,1000表示生成的数据量为 1TB/tpcdata/tpcds 为表数据生成的目录,目录不存在就自动生成,如果不指定目录,数 据目录就默认生成到/tmp/tpcds目录下 cd hive-testbench#如果...
数据传输服务DTS
阿里云数据传输服务集数据迁移、订阅及实时同步功能于一体,能够解决公共云、混合云场景下,远距离、毫秒级异步数据传输难题,支持关系型数据库、NoSQL、大数据(OLAP)等数据源,其底层基础设施采用阿里双11异地多活架构,为数千下游应用提供实时数据流,已在线上稳定运行7年之久。
通过数据订阅功能实时获取订单系统的变更数据,业务通过SDK订阅这些变更数据,并触发库存、物流等下游业务逻辑,实现了整个业务系统的简单可靠.优化业务流程.支持本地MySQL、RDS MySQL、Oracle及Kafka生态等,支持创建消费组,满足多个下游需要订阅同一个数据库实例场景.降低使用成本.提供订阅通道状态、下游消费延迟的报警...
来自:
云产品
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
自建 Hive数据仓库跨版本迁移到阿里云 Databricks数据洞察 业务架构 场景描述 客户在 IDC或者公有云环境自建 Hadoop集群 构建数据仓库和分析系统,购买阿里云 Databricks数据洞察集群之后,涉及到数仓数 据和元数据的迁移以及 Hive版本的订正更新。方案优势 1.全托管 Spark集群免运维,节省人力成 本。2.Databricks数据洞察...
云原生数据湖分析DLA
阿里云云原生数据湖分析是新一代大数据解决方案,采取计算与存储完全分离的架构,支持对象存储(OSS)、RDS(MySQL等)、NoSQL(MongoDB等)数据源的消息实时归档建仓,提供Presto和Spark引擎,满足在线交互式查询、流处理、批处理、机器学习等诉求。内置大量优化+弹性,比开源自建集群最高降低50%+的成本,最快可1分钟级拉起300个计算节点,快速满足业务资源要求。
兼容Presto、Spark.Serverless形态,无需购买任何资源,互联网直接访问,降低运维成本,免去大数据库系统构建烦扰.OSS数据直接分析,构建大规模分析数据集,延迟大约为10分钟.多源数据实时入湖.集群按需快速扩展,1分钟最快弹出300个节点,灵活应对业务变化.海量算力即时扩容.查看全部日志.加和科技通过数据湖分析+OSS的...
来自:
云产品
大数据近实时数据投递MaxCompute
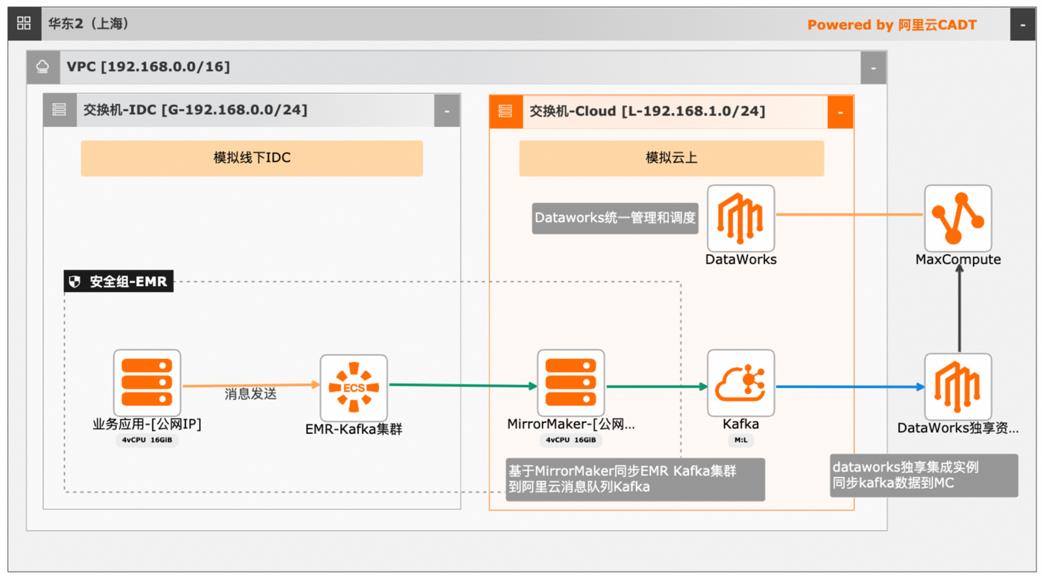
本文介绍离线大数据场景使MaxCompute构建云 上近实时数仓,打通云下数据上云链路,解决数据复杂类型支持和动态分区问题,满足高级数据处理需求的最佳实践。 l混合云环境下,现有业务系统零改造,打通数据上云链路。 l使用UDF实现复杂数据类型转换和数据动态分区。 l使用DataWorks配置周期调度业务流程,数据自动入仓。 l借助MaxCompute优化计算引擎,实现降本增效。 产品列表 云服务器ECS 专有网络VPC 访问控制RAM 数据总线DataHub E-MapReduceEMR DataWorks 大数据计算服务MaxCompute
大数据近实时数据投递 MaxCompute 最佳实践 业务架构 最佳实践 解决问题 场景描述 混合云环境下,现有业务系统零改造,打通数据 本文介绍离线大数据场景使用 MaxCompute构建云 上云链路。上近实时数仓,打通云下数据上云链路,解决数据复 使用 UDF实现复杂数据类型转换和数据动态分 杂类型支持和动态分区问题,满足高级数据...
- 产品推荐
- 这些文档可能帮助您