Databricks数据洞察
阿里云Databricks数据洞察是基于Apache Spark的全托管数据分析平台, 内核采用更高效、稳定的商业版Databricks Runtime和Delta Lake。可满足数据分析师、数据工程师和数据科学家在大数据场景下对数据湖分析、实时数仓、离线数仓、BI数据分析、AI机器学习等需求
产品下线公告.Databricks 数据洞察.Databricks Runtime内核,性能明显优于社区版Spark,最高可达50倍提升。满足高性能、高稳定性、可弹性的计算需求.Databricks Delta Lake为数据湖分析提供了ACID事务能力,轻松处理包含数十亿文件的PB级表的元数据信息,实现了批流一体的数据处理方式.同时满足数据科学家、数据工程师以及...
来自:
云产品
云消息队列 Confluent 版
云消息队列 Confluent 版是阿里云与 Apache Kafka 项目创始团队所创立的 Confluent 公司合作,基于 Apache Kafka 核心能力提供的企业级全托管消息队列服务,旨在为企业提供集成消息流式处理与大数据系统的一站式解决方案。
阿里云 Flink、Databricks、EMR等平台进行数据消费和分布式计算.阿里云产品集成互联互通.更多产品与服务.云消息队列 Confluent 版正式发布!云消息队列 Confluent 版正式发布!查看全部产品.云消息队列 Confluent 版是阿里云与 Apache Kafka 项目创始团队所创立的 Confluent 公司合作,基于 Apache Kafka 核心能力提供的...
来自:
云产品
数据管理与服务
数据管理与服务作为阿里云产品六大版块之一,面向不同业务场景,阿里云提供数据存储、分析、应用等全链路能力,满足企业客户全方位的数据处理需求,实现计算和存储分离、资源解耦、数据移动减化,用以满足行业快速发展的需求和趋势,利用数据重塑其业务。
智能数据建设与治理 Dataphin.Databricks 数据洞察.网络安全升级支持IPV6.天弘基金成立于2004年11月8日,是经中国证监会批准设立的全国性公募基金管理公司之一,目前注册资本5.143亿元。2013年,天弘基金与支付宝合作推出余额宝,是天弘余额宝货币市场基金管理人.web应用防火墙.查看更多>.网络安全升级支持IPV6.基于云原生...
来自:
云产品
阿里云大数据&AI
阿里云大数据和AI产品服务。开放数据处理服务ODPS提供强大的数据分析和管理功能;开源大数据产品支持更加灵活地构建大数据平台;AI和机器学习产品提供AI工程平台和智算服务。
对象存储OSS.Databricks 数据洞察.推荐搭配使用.云原生数据湖.云原生数据湖.2021年3月,MaxCompute、DataWorks 等进入 Forrester Wave 2021 Q1 云数据仓库卓越表现者象限,成为入选此次评测的唯一中国厂商。以 MaxCompute 为核心代表的云数仓已然成为中国受欢迎的云数据仓库服务.国内唯一挺进Forrester全球云数据仓库Wave...
来自:
云产品
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
自建 Hive数据仓库跨版本迁移到阿里云 Databricks数据洞察 业务架构 场景描述 客户在 IDC或者公有云环境自建 Hadoop集群 构建数据仓库和分析系统,购买阿里云 Databricks数据...详 情 请 参 见:Databricks 数 据 洞 察 引 入 多 种 数 据 源(https://help.aliyun.com/document_detail/203265.html)文档版本:20210425 39
DTS数据同步集成MaxCompute数仓
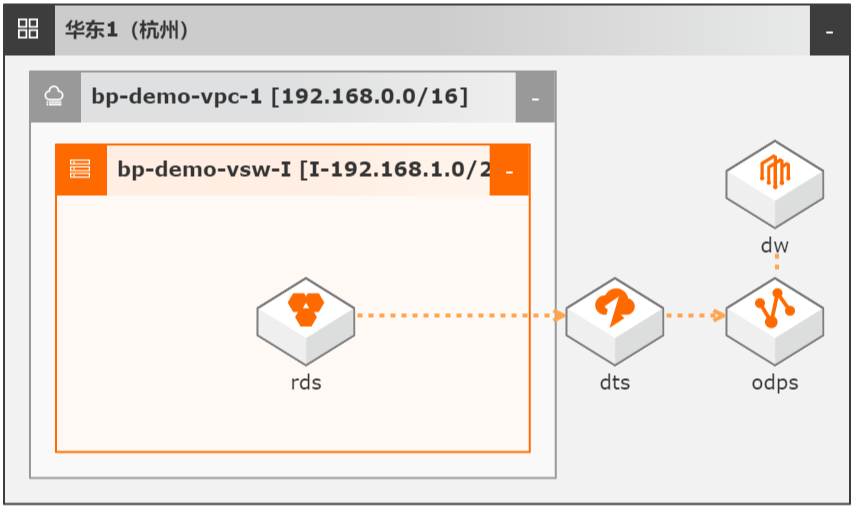
场景描述 本文Step by Step介绍了通过数据传输服务 DTS实现从云数据库RDS到MaxCompute的 数据同步集成,并介绍如何使用DTS和 MaxCompute数仓联合实现数据ETL幂等和数 据生命周期快速回溯。 解决问题 1.实现大数据实时同步集成。 2.实现数据ETL幂等。 3.实现数据生命周期快速回溯。 产品列表 MaxCompute 数据传输服务DTS DataWorks 云数据库RDS MySQL 版
数据抽取不幂等或容错率低,如凌晨 0:00启动的 ETL任务因为各种原因(数据库 HA切换、网络抖动或 MAXC写入失败等)失败后,再次抽取无法获取 0:00时的数 据状态。2.针对不规范设计表,如没有 create_time/update_time的历史遗留表,传统 ETL需 全量抽取。3.实时性差,抽取数据+重试任务往往需要 1-3小时。另外数据库的数据...
数据集成 Data Integration
阿里云数据集成 Data Integration是跨异构数据、低成本、弹性扩展的数据采集同步平台,为DataX的商业版,支持ETL,支持50+数据源跨网络离线(全量/增量)同步。
以下仅列出部分常见数据源,作为DataX的超集,数据集成(Data Integration)支持50+种数据源,完整的数据源列表以及对应使用文档请参看帮助文档.离线同步支持的数据源.Reader&Writer插件.主要通过定义数据来源和去向的数据源和数据集,提供一套抽象化的数据抽取插件(称之为 Reader)、数据写入插件(称之为 Writer),并基于...
来自:
云产品
SAP ERP系统B1与钉钉集成解决方案
专为小型企业设计的 SAP® Business One 支持您集成运营整个企业所需的所有重要功能, 其中包括销售和客户关 系以及财务和运营。它能够帮助您根据最新信息制定决策,简化流程并加快盈利性增长。 借助SAP与阿里云的联合解决方案,您可 以彻底告别内部部署的高成本和复杂性,并确保软件、服务与支持费用的可预测性。
专为小型企业设计的 SAP® Business...加速决策的分析报告:基于SAP HANA平台的分析报告从大数据中获取价值,实现数据洞察,加速企业决策.业务财务一体化:实现对销售,采购,生产和财务等核心业务流程的系统管理,构建一套业务部门和财务部门口径一致的报表体系,提高运营效率.SAP ERP系统B1与钉钉集成解决方案.ECS 云服务器.
来自:
解决方案
RAM用户集成企业AD FS身份认证
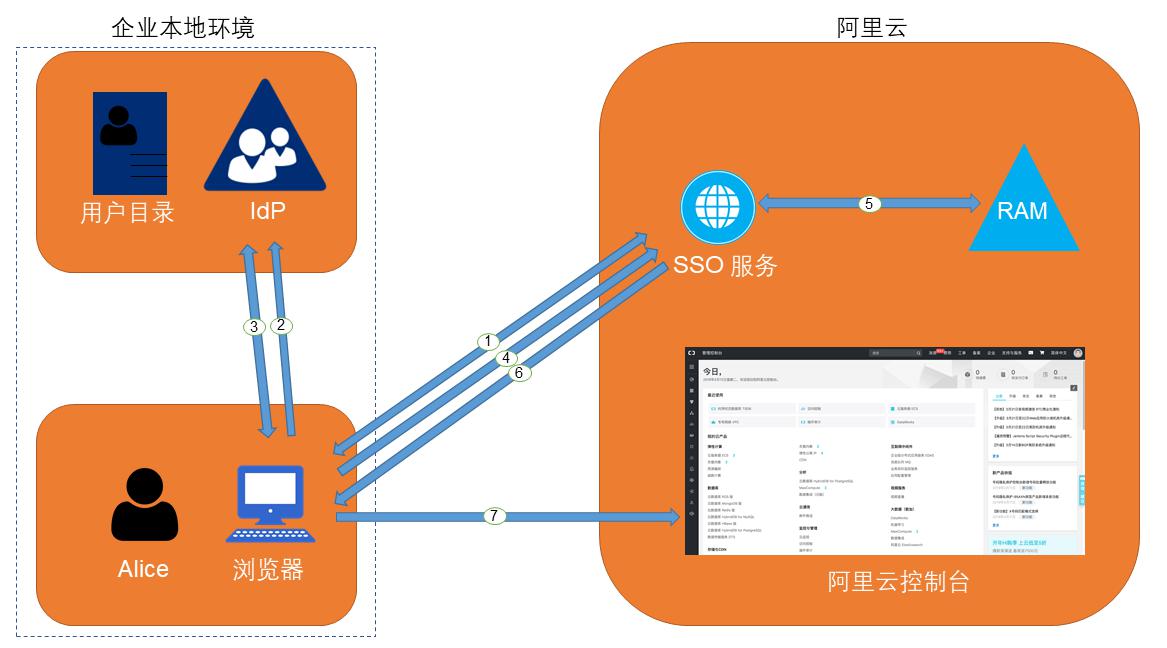
介绍阿里云RAM集成Windows AD FS,使用企 业AD对员工的身份认证及管理功能,配置RAM 用户与AD用户的映射关系,实现企业员工使用企 业AD域账号以单点登录(SSO)的方式访问阿里 云控制台。 解决问题 1.Windows AD域部署。 2.Windows AD证书服务及Web服务部署。 3.Windows AD FS部署。 4.阿里云用户SSO配置。 5.AD FS集成RAM用户SSO。 产品列表 l访问控制RAM l专有网络VPC l云服务器ECS
部署架构图 RAM用户集成企业ADFS身份认证 场景描述 介绍阿里云RAM集成WindowsADFS,使用企 业AD对员工的身份认证及管理功能,配置RAM 用户与AD用户的映射关系,实现企业员工使用企 业AD域账号以单点登录(SSO)的方式访问阿里 云控制台。解决问题 1.WindowsAD域部署。2.WindowsAD证书服务及Web部署。3.WindowsADFS部署。4....
RAM角色集成企业OpenLDAP身份认证
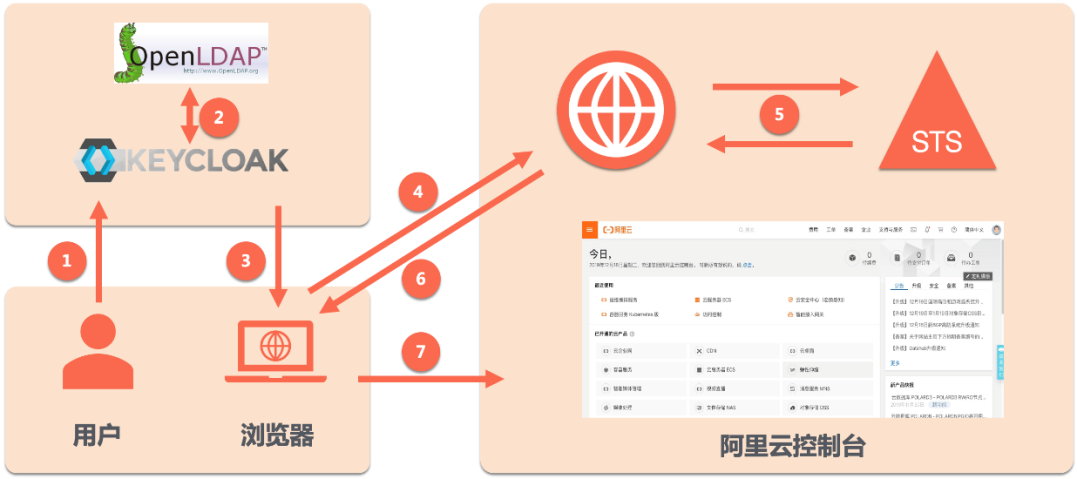
场景描述 本文介绍阿里云RAM使用KeyCloak集成企业OpenLDAP, 管理员工的身份及权限。配置RAM角色与KeyCloak 用户 /用户组的映射关系,实现企业员工使用企业OpenLDAP账 号以单点登录(SSO)的方式访问阿里云控制台。 解决问题 快速部署OpenLDAP及用户创建。 快速部署KeyCloak,并与OpenLDAP实现用户联 合。 阿里云角色SSO配置。 KeyCloak用户绑定RAM角色SSO。 KeyCloak用户组绑定RAM角色SSO。 产品列表 访问控制RAM 专有网络VPC 云服务器ECS 容器镜像服务ACR
RAM角色集成企业 OpenLDAP身份认证 最佳实践 业务架构 场景描述 本文介绍阿里云 RAM使用 KeyCloak集成企业 OpenLDAP,管理员工的身份及权限。配置 RAM 解决问题 角色与 KeyCloak 用户或用户组的映射关系,实 快速部署 OpenLDAP及用户创建。现企业员工使用企业 OpenLDAP账号以单点登 录(SSO)的方式访问阿里云控制台。快速...
- 产品推荐
- 这些文档可能帮助您