云架构必修课:云上高可用架构
从企业上云最基础的需求出发,面向可能遇到的单点故障风险,介绍了经典的业务上云高可用架构方案设计。
相关产品应用型负载均衡 ALB专有网络 VPC云服务器 ECS云数据库 RDS MySQL 版在线咨询方案优势稳定性高ECS多可用区多实例可用性可达99.995%,云数据库RDS MySql高可用系列可用性可达99.95%。容灾与备份ALB、ECS、RDS均具备跨可用区的自动备份和灾难恢复能力,确保关键数据的稳定性和安全。弹性伸缩负载均衡ALB将应用流量分发...
来自:
解决方案
云上公网架构设计和安全管理
云上公网的设计可以帮助企业更加统一、安全地管理自己的云上互联网出入口,同时可以实现统一监控运维和公网的成本优化。
产品解决方案文档与社区权益中心定价云市场合作伙伴支持与服务了解阿里云备案控制台云上公网架构设计和安全管理方案介绍方案优势应用场景方案部署方案权益云上公网架构设计和安全管理随着企业业务云化进程逐渐进入深水区,简单地使用云上资源出入公网已经无法满足业务的诉求,安全、成本、权限、监控等诉求的迭代,需要企业...
来自:
解决方案
跨云迁移单写双读过渡架构
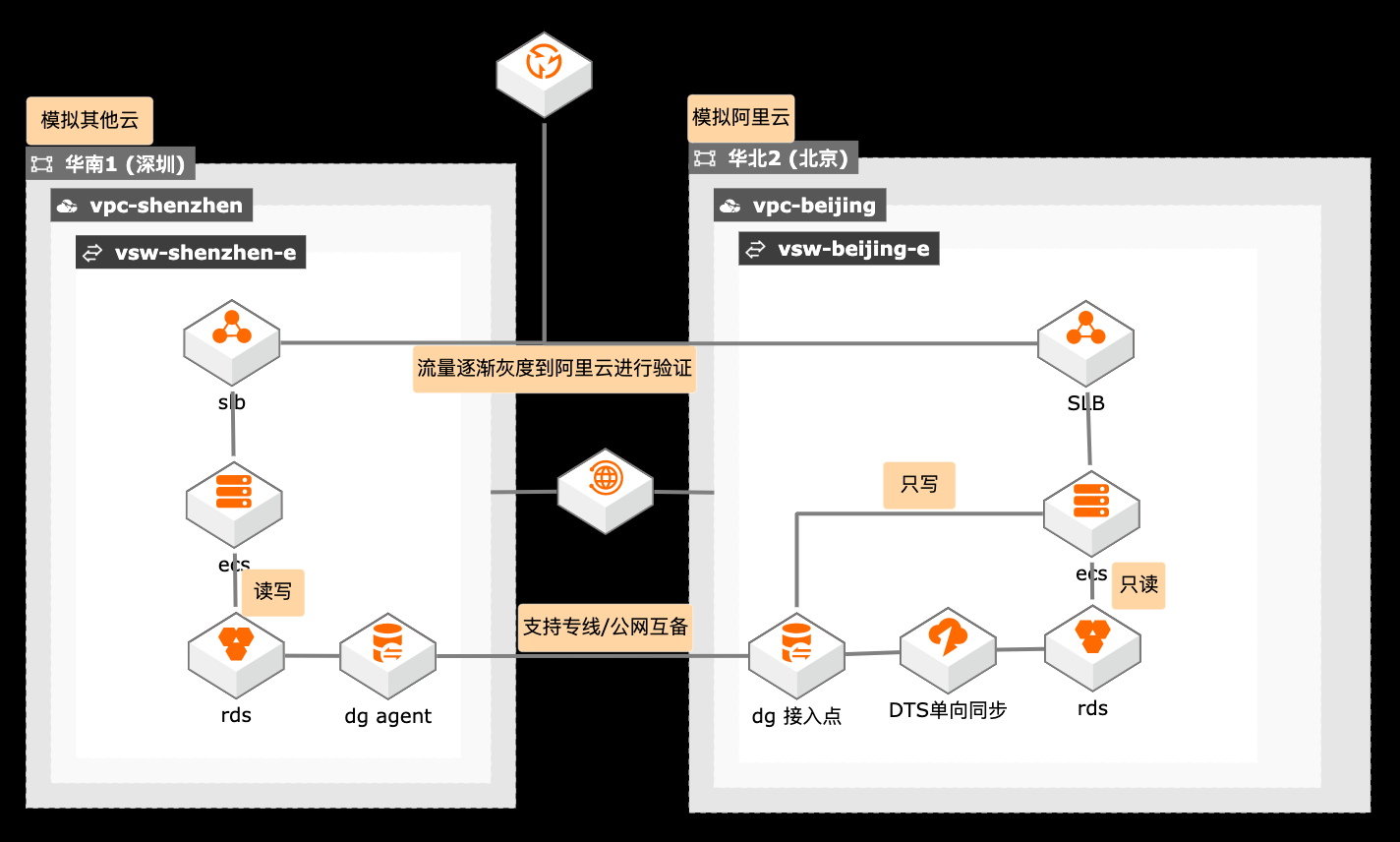
概述 在搬站场景下,涉及迁移跨度较长,在过渡阶段客户需要跨云访问,如何保障数据链路的高可用尤为关键,采用专线和公网双备的方案保障数据传输的高可用,也降低双专线的迁移成本。 适用场景 数据迁移链路的高可用 跨云迁移过渡期架构 读写分类架构设计 技术架构 本实践方案基于如下图所示的技术架构和主要流程编写操作步骤: 方案优势 在迁移时间持续较长的情况下,使用单写双读架构降低业务改造成本。 使用数据库网关做专线和公网互备。 流量逐渐灰度验证,保障迁移平滑过渡。 安全:原生的多租户系统,以项目进行隔离,所有计算任务在安全沙箱中运行。
阿里云最佳实践分享群 最佳实践频道 产品列表 云服务器 ECS、负载均衡 SLB、云企业网 CEN 云数据库 RDS、性能测试 PTS 如二维码过期,请搜索群号:数据传输服务 DTS 31852400 云服务器 ECS(产品名称)文档模板(手册名称)/文档版本信息 阿里云 跨云迁移单写双读过渡架构 最佳实践 文档版本:20201209 文档版本:20150122...
极致弹性的云原生架构解决方案
极致弹性的云原生架构解决方案使用容器服务ACK实现业务应用层面的弹性,数据库PolarDB随需弹性扩缩容, 以云原生的方式达到低成本的快速扩展。轻松搞定大促弹性,做到自动部署、自动扩容、自动缩容、高可靠性保障、低运维工作量、低成本。
云数据库POLARDB优势解读:分钟级弹性.阿里云POLARDB新版本:首个兼容Oracle的云原生数据库.POLARDB 新增多款计算型规格,最高可达88核.关于云数据库 POLARDB.高性能可伸缩的容器应用管理能力.容器服务 ACK.主研发的下一代关系型分布式云原生数据库.云原生数据库POLARDB.计算服务,助您降低 IT 成本,提升运维效率.云服务器...
来自:
解决方案
虚拟桌面架构的高性能体验云上部署
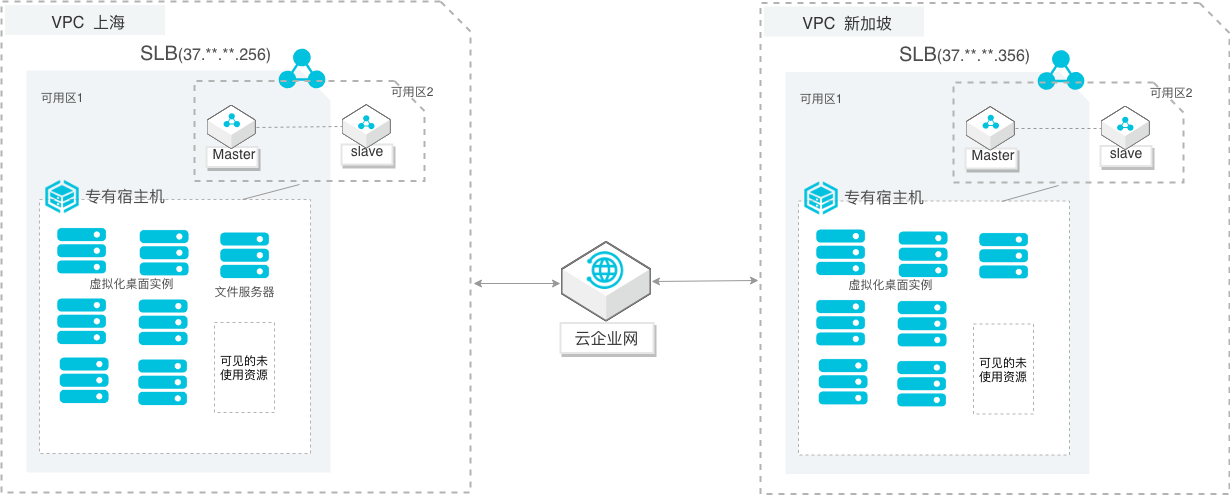
场景描述 针对自建虚拟化桌面架构迁移阿里云,以及有虚拟化桌面 架构需求上云。包括但不限于: 1.有许可证合规要求,利用自带license快速上云的客户。 2.对数据安全较高要求,需要快速构建虚拟化桌面的客 户。 解决问题 利用云上灵活性和规模化优势,构建云上更加高效、高性 能体验的服务,为客户解决: 1.客户VDI部署的需求,能够更及时的得到满足。 2.解决硬件资源限制,根据业务规模化部署并集中管 控。 3.利用公共云的网络、计算、备份容灾方案、安全防护 等,提供高可靠、高性能、高体验的远程桌面服务。 产品列表 VPC(专有网络) SLB(负载均衡) CEN(云企业网) 专有宿主机 OpenAPI
已经开通了如下服务:云服务器(ECS)服务-负载均衡(SLB)服务-云数据库(RDS)服务-云数据库(Redis)服务-专有网络(VPC)服务 提前根据业务发展情况,规划资源。1 企业上云实践 虚拟桌面架构的高性能体验云上部署|演示环境说明 演示环境说明 本示例基础架构图:产品或服务 本文示例 备注 VPC-1 名称:VPC_SH 华东 2...
边缘计算云原生架构解决方案
边缘计算云原生架构解决方案,旨在通过云原生架构构建边缘计算(物联网、CDN、混合云等)云边一体化协同基础设施。通过云端托管边缘资源/应用,无缝对接丰富云产品能力,提供边缘计算业务的自动化运维、高可靠性保障,降低边缘应用的运维工作量,提升边缘计算业务创新效率。
边缘计算云原生解决方案,旨在通过云原生架构构建边缘计算(物联网、CDN、混合云等)云边一体化协同基础设施。通过云端托管边缘资源/应用,无缝对接丰富云产品能力,提供边缘计算业务的自动化运维、高可靠性保障,降低边缘应用的运维工作量,提升边缘计算业务创新效率.边缘计算云原生架构解决方案\\u00A0.【边缘应用管理...
来自:
解决方案
金融分布式架构SOFAStack
阿里云金融分布式架构SOFAStack为金融用户提供全栈式的基础架构能力,是集项目管理、微服务开发、发布部署、监控运维、容灾高可用等全栈式解决方案,助力客户应用轻松转型分布式架构,保证风险安全的同时帮助业务需求敏捷迭代,支撑金融业务创新,开发人员学习成本最多可降低92%、应用开发效率可最多提升80%、运维人力成本最多可节省90%
金融分布式架构 SOFAStack 和分布式数据库 OceanBase 助力中国人保健康打造行业领先的互联网保险云核心业务系统。从5秒处理1单到每秒1000单,人保健康正式开启互联网保险业务新时代.基于金融分布式架构 SOFAStack 和分布式数据库 OceanBase 研发的银行核心系统,让网商银行拥有处理高并发金融交易、海量大数据、弹性扩容和...
来自:
云产品
基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测

本篇最佳实践先创建EMR集群作为数据湖对象,Hive元数据存储在DLF,外表数据存储在OSS。然后使用阿里云数据仓库MaxCompute以创建外部项目的方式与存储在DLF的元数据库映射打通,实现元数据统一。最后通过一个毒蘑菇的训练和预测demo,演示云数仓MaxCompute如何对于存储在EMR数据湖的数据进行加工处理以达到业务预期。
如果没有自动关联指定的OSS,可以手动创建云数据库,指向对应的OSS-bucket。基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测 2.配置DataWorks和PAI 此方案通过DataWorks创建一个工作空间,选择MaxCompute作为计算引擎,并开 通PAIStudio作为机器学习服务(用于后续...
企业级互联网架构解决方案
企业级互联网架构解决方案是在阿里巴巴电商业务环境沉淀下来的互联网中间件,其优秀的架构设计理念,以及大型分布式系统数据化运营能力,帮助企业用户快速构建大型分布式应用,支持业务需求快速创新,助力传统企业快速互联网+转型。
用户需有自建机房,为本地数据中心赋予阿里云同款云架构能力.公共云架构结合专有云,实现快速部署与数据的处理与计算服务.从研发-测试-运维提供一套完整的全流程平台支撑,初步实现了 DevOps.DevOps 闭环整体架构.虎牙在全球 DNS 秒级生效上的实践>.阿里云性能测试 PTS 上手体验>.基于 RocketMQ 实现金融级数据服务的实践...
来自:
解决方案
- 产品推荐
- 这些文档可能帮助您