RI和SCU全链路使用实践
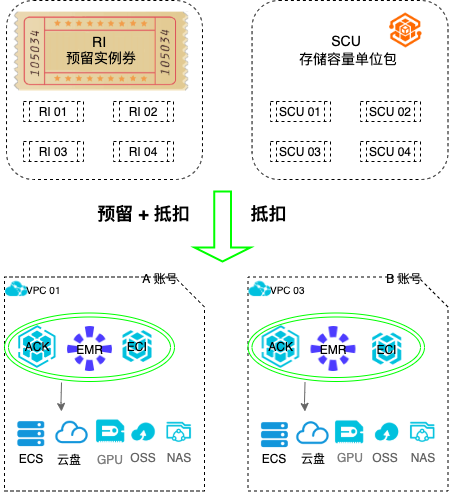
场景描述 随着云计算的不断发展,更多的企业会使用云计算,且会有越来 越多的企业和用户开始重视云上使用成本。 其中计算和存储是云资源使用的主要服务之一。采用预留实例券 业务架构(RI)和存储容量单位包(SCU)可以帮助客户灵活的节省成本。 本文提供全链路使用实践,帮助客户快速验证云上服务,更合理 的使用RI/SCU。借助覆盖率指标和智能推荐,有效管理云上资 源成本。 用户价值 使用RI 和SCU,可以灵活抵扣相关资源。随时创建释放, 稳态业务资源效率提高。 一份RI 可以抵扣ECS+ACK+EMR+ECI 等服务,跨服务高 度灵活,无需再分开购买。 SCU可以跨可用区抵扣某个地域下所有类型的按量付费云 盘,简化购买与管理复杂度。 RI+SCU 大幅降低按量场景的计算和存储成本。 产品列表 专有网络VPC、容器服务Kubernetes 版ACK 云服务器ECS、预留实例券RI、存储容量单位包SCU
5.存储容量单位包 SCU能抵扣的存储容量随云盘类型不同而变化,不同云盘消耗的 SCU系数如下表所示。(以下抵扣规则适用于阿里云中国站大陆地域)购买规划注意事项 预留实例券(RI)对于一些稳定需求(1-3年),购买预留实例券肯定是最简单又最有效的优化使用成本 的方式。根据业务当前资源情况以及预计未来的大致规模,统一...
Function Compute构建高弹性大数据采集系统
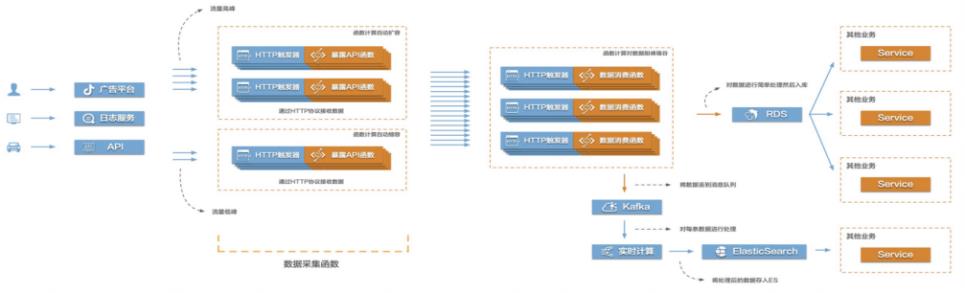
当前互联网很多场景都存在需要将大量的数据信息采集起来然后传输到后端的各类系统服务中,对数据进行处理、分析,形成业务闭环。比如游戏行业中的游戏发行、游戏运营,产互行业中的数字营销,物联网、车联网行业中的硬件、车辆信息上报等等。这些场景普遍存在数据采集量大、数据传输需要稳定且吞吐量大的特点,给整个数据采集传输系统带来很大的挑战。在这个场景中,有三个关键的环节,数据采集、数据传输、数据处理。该最佳实践主要涉
CREATE TABLE `article_table`(`id` bigint(10)NOT NULL AUTO_INCREMENT,`action` text(50)NULL,`articleTitle` text(50)NULL,`articleAuthorId` text(50)NULL,`articleAuthorName` text(50)NULL,`ts` bigint(20)NULL,PRIMARY KEY(`id`))ENGINE=InnoDB DEFAULT CHARACTER SET=utf8;文档版本:20210806(发布日期)33 ...
基于MaxCompute的大数据BI分析
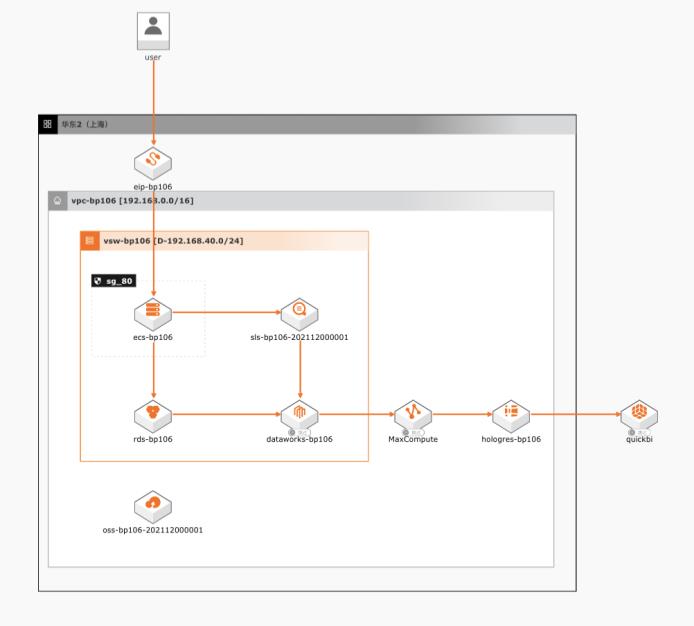
场景描述 本文以电商行业为例,将业务数据和日志数据使用 MaxCompute做ETL之后,同步到ADB进行实时 分析,之后通过QuickBI进行快速可视化展示。 解决问题 1.互联网行业、电商、游戏行业等网站、App、 小程序应用内BI分析场景。 2.可扩展到各类网站BI分析场景使用。 产品列表 1.MaxCompute 2.分析型数据MySQL版 3.日志服务SLS 4.QuickBI 5.云服务器ECS 6.RDSMySQL版
步骤7 在新建用户 AccessKey对话框中,单击保存 AK信息(自动生成一张表格,AK信息 保存在表格中),并关闭对话框。文档版本:20211213 41 基于 MaxCompute的大数据 BI分析 DataWorks大数据处理 步骤8 再返回 DataWorks控制台主页面,刷新页面,可看到出现开通 DataWorks按量付费 按钮。单击开通 DataWorks按量付费。步骤9 ...
游戏业务分区合服

概述 为了提高游戏玩家的体验,并提高留存率,增强付费率.除了游戏本身的内容趣味性外, 改善用户访问加速体验,并对游戏数据分区合服是很常见的业务运营场景. 本方案适用于: 1游戏业务运营,对多个分区数据库进行合并,增加付费用户积极性的需求. 2游戏业务加速,中心化部署的网络加速需求. 方案优势 1便捷数据迁移. 2内网安全传输 3加速远端用户访问质量体验 4快速应对上层业务运营的技术实现操作. 产品列表 网络产品:VPCSLBNAT网关CEN共享带宽包EIP全球加速GA 计算产品:ECS 数据库产品:RDSDTS 存储产品:OSS 云解析
DTS 提供了数据迁移、实时数据 Data 订阅及数据实时同步等多种数据传输能力,可实现 DTS Transmission 不停服数据迁移、数据异地灾备、异地多活(单元 Service 化)、跨境数据同步、实时数据仓库、查询报表分 流、缓存更新、异步消息通知等多种业务应用场景,助您构建高安全、可扩展、高可用的数据架构。阿里云关系型数据库...
云原生数据湖分析DLA
阿里云云原生数据湖分析是新一代大数据解决方案,采取计算与存储完全分离的架构,支持对象存储(OSS)、RDS(MySQL等)、NoSQL(MongoDB等)数据源的消息实时归档建仓,提供Presto和Spark引擎,满足在线交互式查询、流处理、批处理、机器学习等诉求。内置大量优化+弹性,比开源自建集群最高降低50%+的成本,最快可1分钟级拉起300个计算节点,快速满足业务资源要求。
无需ETL,可使用SQL跨OSS、关系数据库(PostgreSQL、MySQL等)、NoSQL(TableStore等)多种数据源分析,屏蔽各种数据源访问的差异性;分析环境与生产库隔离,分析过程不会对数据源端的业务系统产生造成影响.拥有优越弹性,支持元数据发现,支持多源一键数据实时入湖分析等功能,直接使用SQL即可分析OSS等数十种源数据.多项企业...
来自:
云产品
在线教育流量洪峰
1. 通过Tair缓存的性能增强型解决高并发读的性能问题,通过持久内存型解决大并发写性能及数据可靠性问题。 2. PolarDB作为主数据库保存业务的交易数据,通过弹性能力和并发SQL解决性能瓶颈。 3. ADB+QuickBI提供的数据仓库方案通过分时弹性能力和实时业务展现能力。
用户可以执行 CREATE TABLE语句指定表的冷热存储策略为:全热 存储(数据全部存储在 SSD)、全冷存储(数据全部存储在 HDD)、冷热混合存储(指 定一定数量的分区存储在 SSD,其余数据存储在 HDD)。注意:使用冷热分层的元数据表等需要对 ADB进行升级,请开工单解决。步骤1 连接到 ADB数据库。mysql-h-utest001-p 步骤2 ...
CDH迁移升级CDP最佳实践
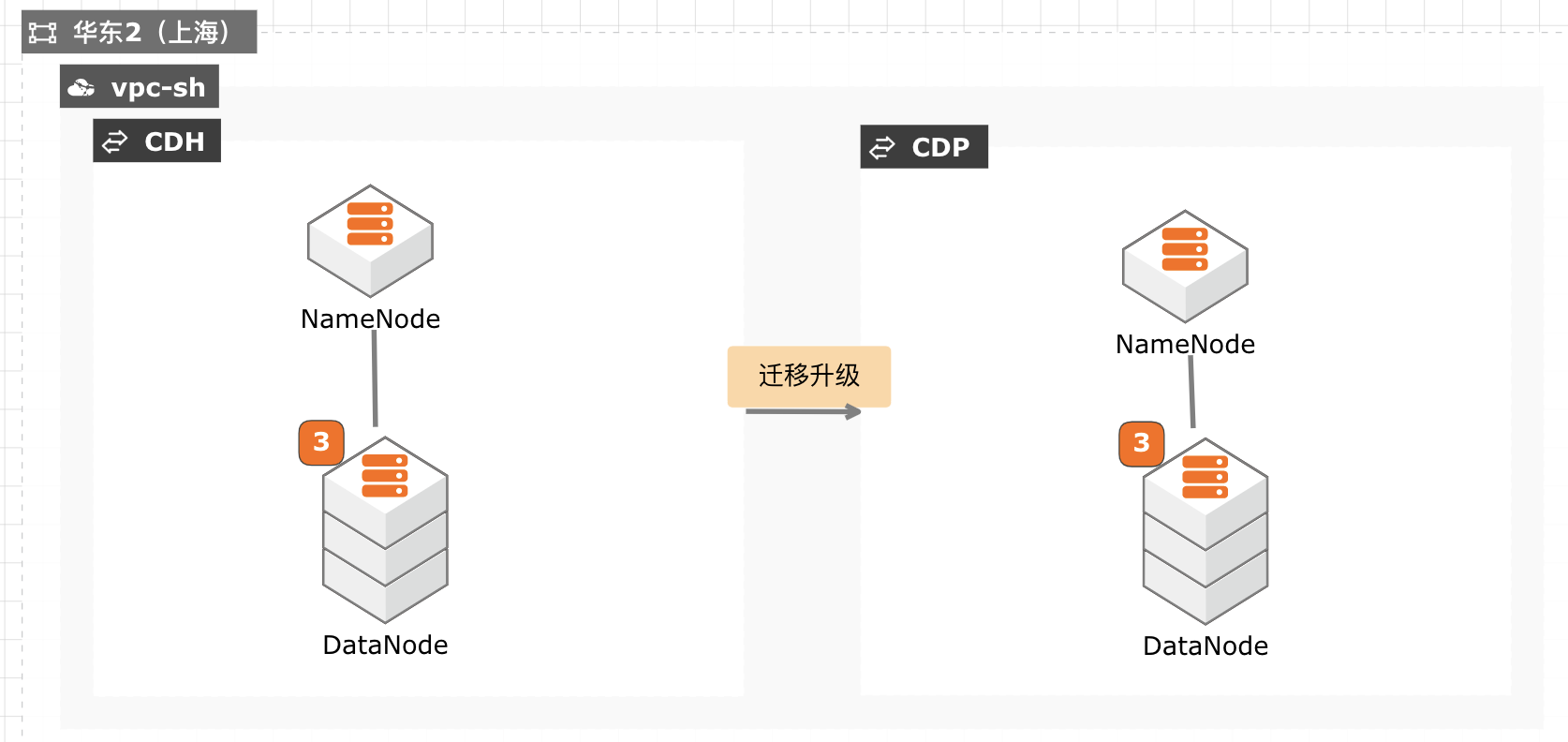
当前 CDH 免费版停止下载,终止服务,针对需要企业版服务能力并且CDH 升级过程对业务影响较小的客户,通过安装新的 CDP 集群,将现有数据拷贝至新集群,然后将新集群切换为生产集群,升级过程没有数据丢失风险,停机时间较短,适合大部分互联网客户升级使用。
kudu table list cdp-master-1.c-e34371c2cc31480a 为了能使用 impala 查询 kudu 表,需进一步创建 impala 外表进行映射。首先查看 tpcds_kudu_2.db文件授予 hdfs用户的读写权限。1.查看权限 hadoop fs-ls/user/hive/warehouse/tpcds_kudu_2.db 2.CDP集群默认不允许切换用户到 hdfs,需先进行修改 vi/etc/passwd 把 hdfs:x:...
基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测

本篇最佳实践先创建EMR集群作为数据湖对象,Hive元数据存储在DLF,外表数据存储在OSS。然后使用阿里云数据仓库MaxCompute以创建外部项目的方式与存储在DLF的元数据库映射打通,实现元数据统一。最后通过一个毒蘑菇的训练和预测demo,演示云数仓MaxCompute如何对于存储在EMR数据湖的数据进行加工处理以达到业务预期。
说明:1.SQL引擎会把ML_PREDICT函数下的子查询结果存到临时表,临时表生命周期 同样是1天。2.ML_PREDICT的结果可以放在SQL语句里面直接查询,也可以通过INSERT或 CREATETABLEAS语句存到另一个表里。查询预测结果表,发现预测结果基本与实际结果一致。SELECT*FROMmushroom_predict_resultLIMIT10;基于湖仓一体架构使用...
数据库异地灾备
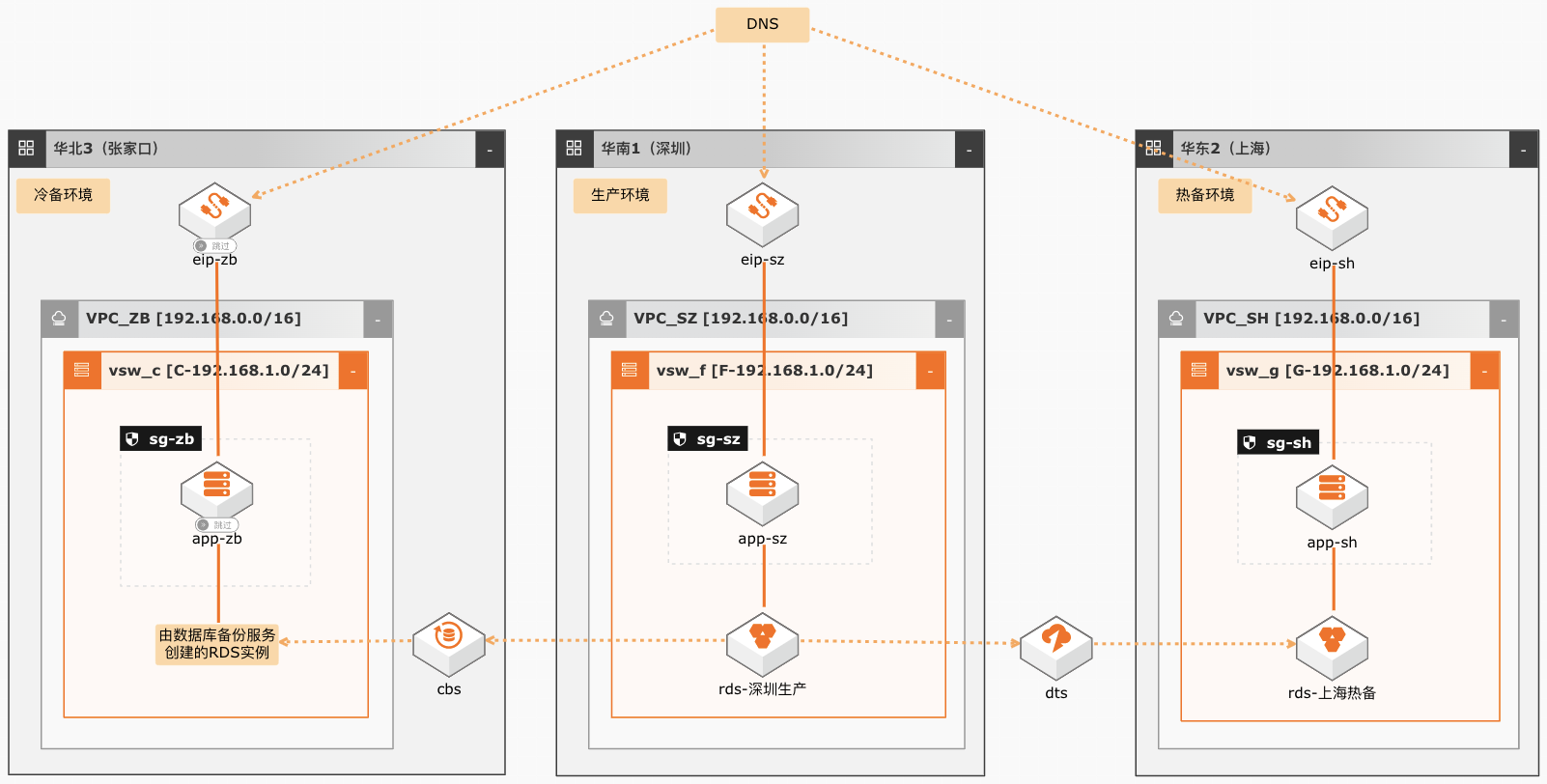
场景描述 适用于不满足于单地域,对数据可靠性 (RPO)和服务可用性(RTO)要求更高 的,希望防范断电、断网等机房故障,抵 御地震、台风等自然灾害,具备异地容灾 备份恢复能力的客户业务场景。 解决问题 1.实时备份,RPO达到秒级 2.表级恢复,故障恢复时间大大缩短 3.长期归档,自动管理备份生命周期 4.异地灾备,构建数据库灾备中心 产品列表 专有网络VPC 云服务器ECS 弹性公网IP(EIP) 负载均衡SLB 云数据库RDSMySQL 数据库备份服务DBS 对象存储服务OSS 数据湖分析服务DLA 数据管理服务DMS 数据传输服务DTS
无需 ETL,就可通过此服务在云上通过标准 JDBC 直接对阿里云 OSS、TableStore、RDS等不同数据源里存储的数据轻松进行查询 和分析。DLA 无缝集成各类商业分析工具,提供便捷的数据可视化。详见:https://www.aliyun.com/product/datalakeanalytics DMS:数据管理服务(Data Management Service,简称 DMS)支持 MySQL、SQL ...
基于Flink的资讯场景实时数仓
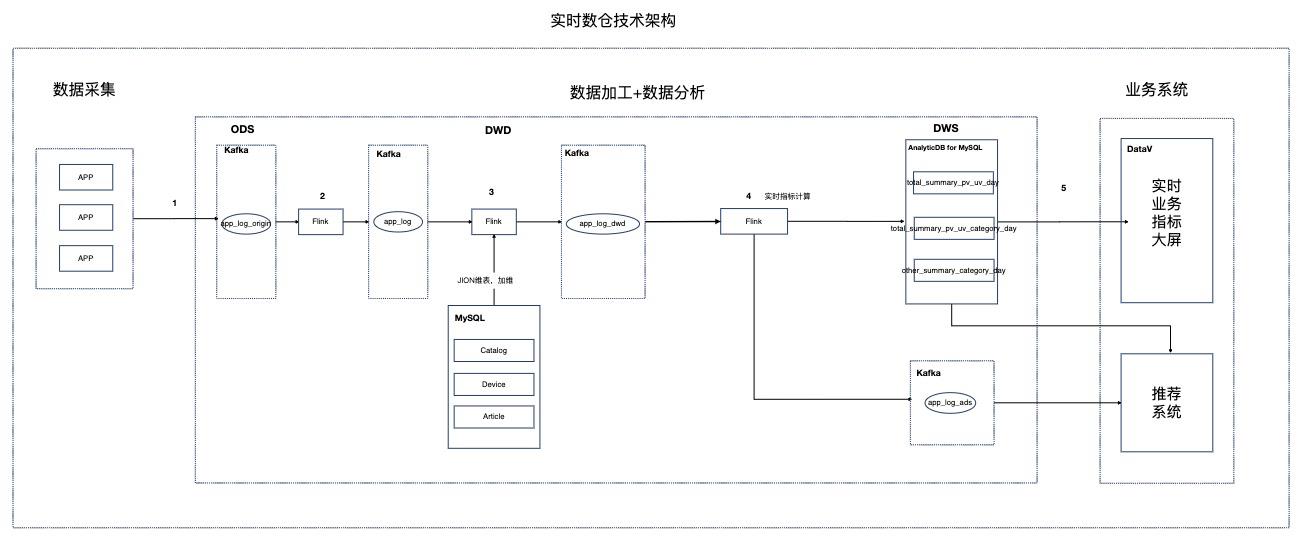
场景描述 本实践针对资讯聚合类业务场景,Step by Step介绍 如何搭建实时数仓。 解决问题 1.如何搭建实时数仓。 2.通过实时计算Flink实现实时ETL和数据流。 3.通过实时计算Flink实现实时数据分析。 4.通过实时计算Flink实现事件触发。 产品列表 实时计算 专有网络VPC 云数据库RDSMySQL版 分析型数据库MySQL版 消息队列Kafka 对象存储OSS NAT网关 DataV数据可视化
数据分析包括以下两步:a)通过实时计算 Flink抽取 DWD中对应信息并进行轻度汇总(如部分业务指标 计算),生成 DWS(Data Warehouse Summary,汇总数据层),并将数据存 储到 AnalyticDB for MySQL。b)通过 AnalyticDB for MySQL进行多维数据分析和大屏实时查询。4.业务系统:业务系统通过 DataV数据可视化实现业务指标实时...
PolarDB 应对大并发复杂查询实践
MySQL架构是单线程处理SQL,遇到大并发复杂查询时,需要排队长时间等待,容易形成慢查询,影响业务。PolarDB并发查询能力可以很好解决此问题。
附录 测试环境安装.26 4.1.TPC-H安装.26 文档版本:20210412 IV PolarDB如何应对大并发复杂查询 最佳实践概述 最佳实践概述 概述 在面向 C端或者多个小 B端的 SaaS化服务场景下,数据库经常面临大并发的复杂查 询业务压力,比如餐饮平台的商户随机查看订单统计情况;ERP服务平台面临大量零 售商户查看库存报表情况。此类...
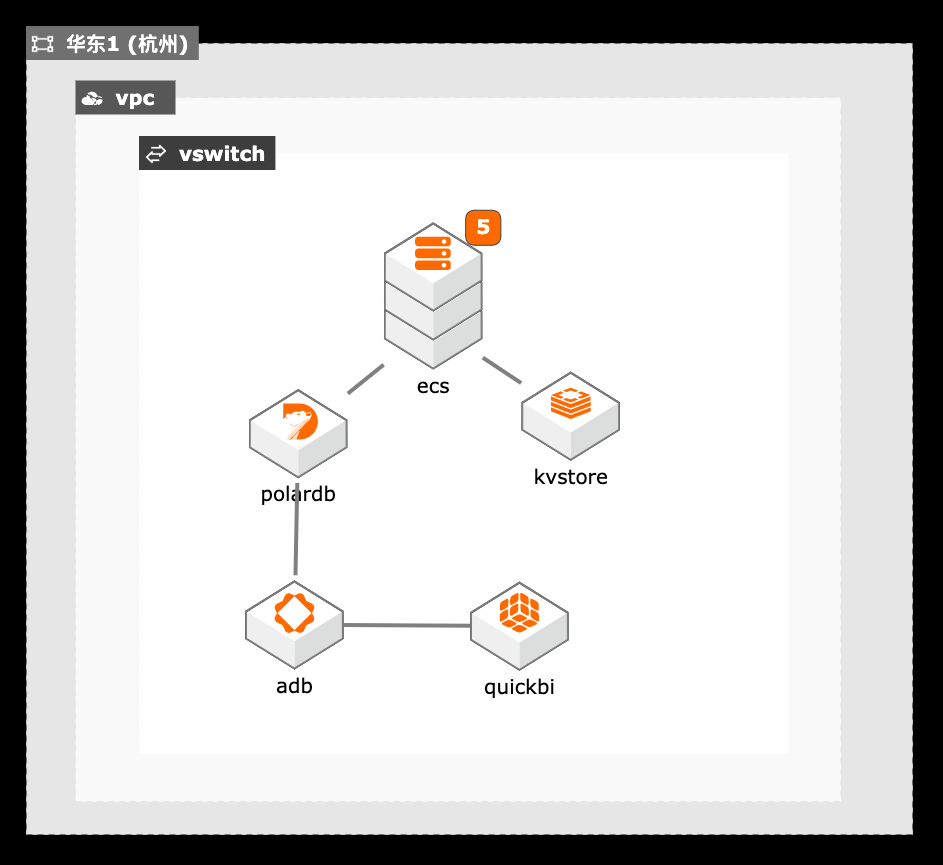
利用交互式分析(Hologres)进行数据查询
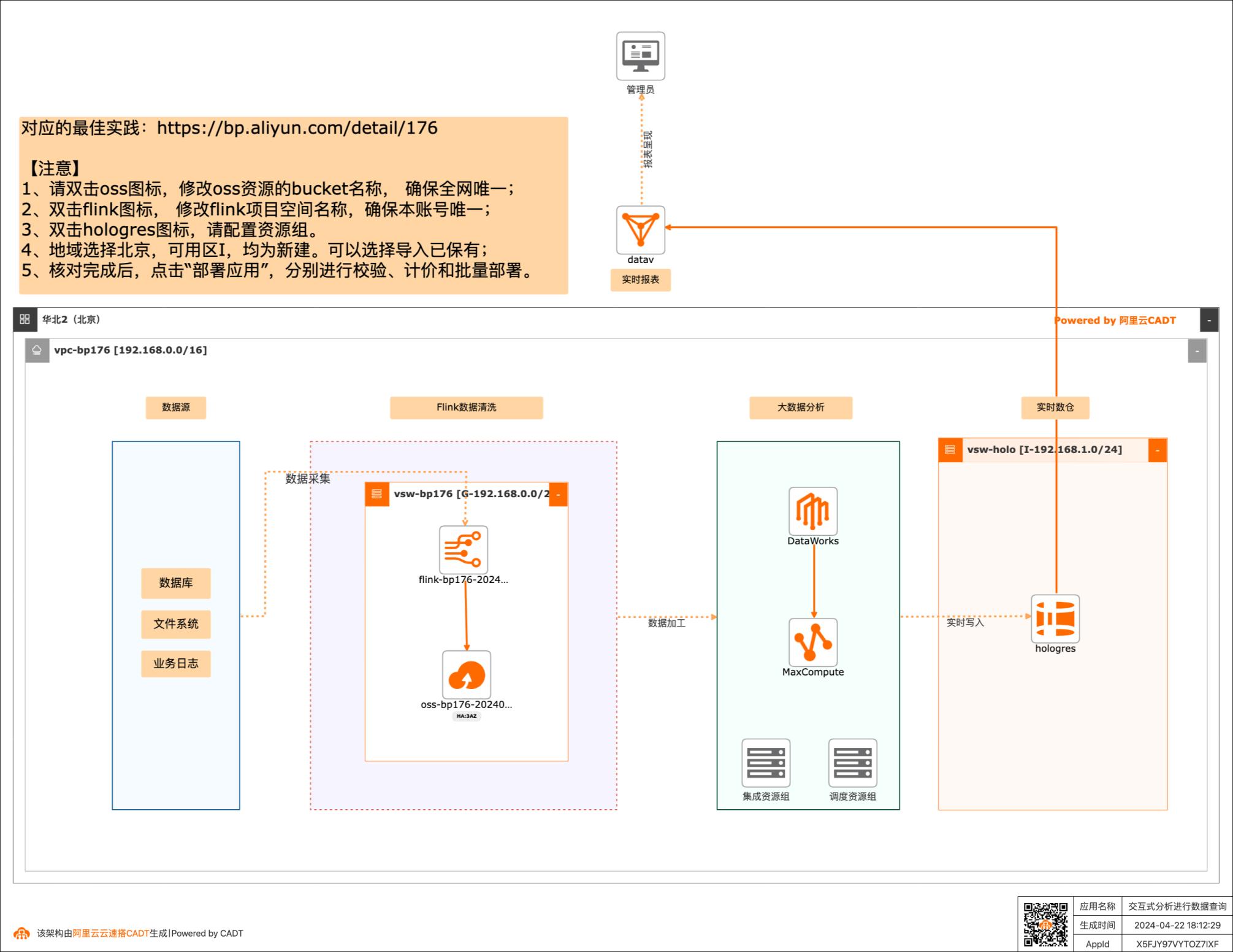
场景描述:随着收集数据的方式不断丰富,企业信息化 程度越来越高,企业掌握的数据量呈TB、 PB或EB级别增长。同时,数据中台的快 速推进,使数据应用主要为数据支撑、用户 画像、实时圈人及广告精准投放等核心业务 服务。高可靠和低延时地数据服务成为企业 数字化转型的关键。 Hologres致力于低成本和高性能地大规模 计算型存储和强大的查询能力,为您提供海 量数据的实时数据仓库解决方案和实时交 互式查询服务。 解决问题 1.加速查询MaxCompute数据 2.快速搭建实时数据仓库 3.无缝对接主流BI工具 产品列表 MaxCompute Hologres 实时计算Flink 专有网络VPC DataWorks DataV
Hologres致力于低成本和高性能地大规模计算型存储和 强大的查询能力,为您提供海量数据的实时数据仓库解决 方案和实时交互式查询服务。解决问题 1.加速查询MaxCompute数据 产品列表 2.快速搭建实时数据仓库 3.无缝对接主流BI工具 专有网络VPC 交换机vswitch 最佳实践频道 Hologres http://bp.aliyun.com 实时...
- 产品推荐
- 这些文档可能帮助您