阿里云云原生可观测套件
阿里云云原生可观测套件围绕Prometheus服务、Grafana服务和链路追踪服务,通过标准的PromQL和SQL提供数据大盘展示、告警和数据探索能力。
统一观测|如何使用 Prometheus 监控 Windows.统一观测丨如何使用 Prometheus 实现性能压测指标可观测.对比开源丨可观测监控 Prometheus 版多场景存储压测全解析.统一观测丨使用 Prometheus 监控云原生网关,我们该关注哪些指标?分析解析性能与体验优化必要性,梳理关键优化流程,指导企业落地,汇总实践内容,形成性能与...
来自:
云产品
SAP S/4HANA上云最佳实践
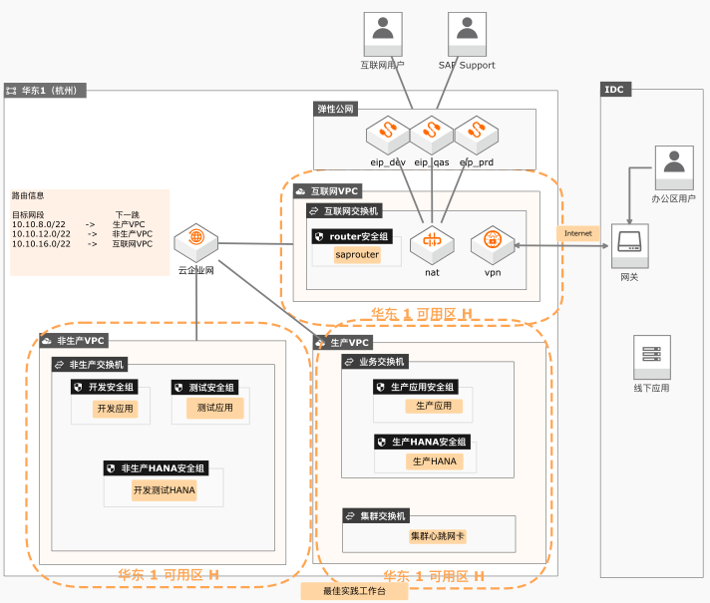
本实践以SAP S/4HANA上阿里云的场景为原型,阐述了如何通过CADT在阿里云上快速交付符合最佳实践的基础云架构。
详见:https://www.aliyun.com/product/developerservices/cadt 日志服务(SLS):日志服务(Log Service)提供基本的日志存储能力。同时日志 服务还一站式提供数据采集、加工、查询与分析、可视化、告警、消费与投递等功 能,全面提升您在研发、运维、运营、安全等场景的数字化能力。详见:...
云数据库专属集群MyBase
云数据库专属集群MyBase是阿里云专为企业级用户定制优化的解决方案。支持MySQL、PostgreSQL、SQL Server、Redis和MongoDB数据库。具有云资源独享、支持资源超分配,自主可运维、开放权限等特点。MyBase不仅能保障客户独享云资源更加安全、享受到云数据库服务的便捷灵活,同时还满足企业对数据库合规性、安全性和高性能的要求。
更多产品与服务.查看全部日志.更多产品与服务.独占资源/高级别隔离,满足安全合规,强监管要求。可对接原有运维体系,快速上云.混合部署多个数据库、数据库与业务系统就近部署,满足业务诉求,提升数据库访问效率.根据业务情况灵活配置资源,错峰利用 CPU、内存等资源,实现更高性价比,降低总体 TCO.支持 MySQL、PostgreSQL...
来自:
云产品
Function Compute搭建前端CICD系统
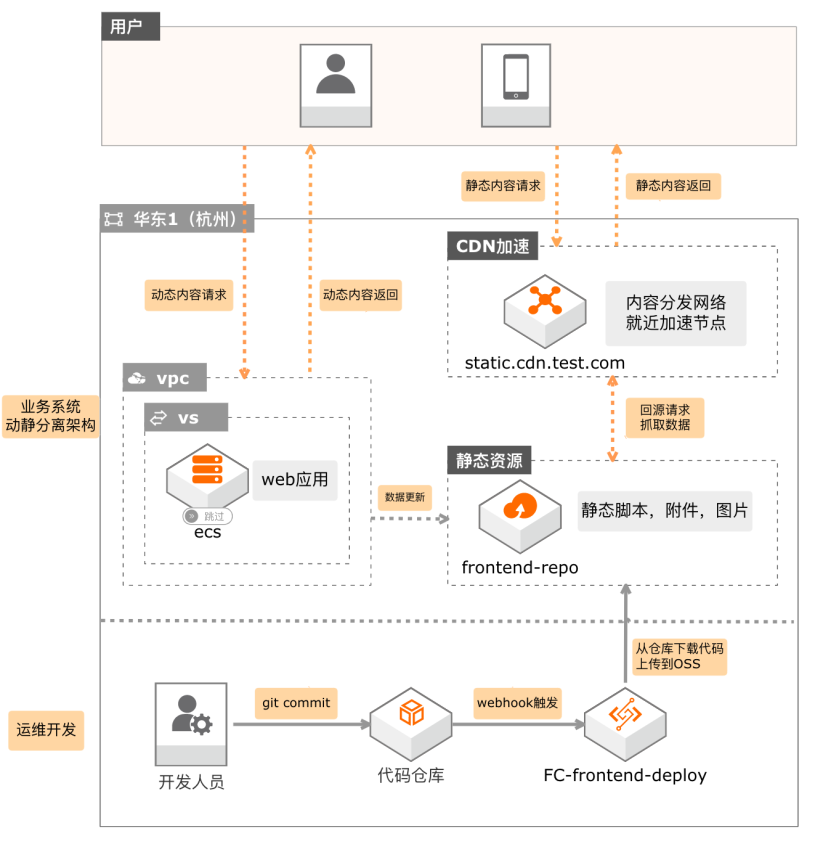
场景描述 传统动静不分离的产品架构,随着访问量在增 长,性能会成为瓶颈。在这种情况下,用户可以 通过利用OSS和CDN对网站进行架构优化, 做到网站文件的动静分离,提升用户访问体验, 实现成本可控。本方案使用函数计算监听前端代 码库提交的分支变更,上传分支文件至OSS,通 过CDN进行前端资源加速。 方案优势 1.面向serverless:无需购买服务器 2.免运维:无需部署配置Jenkins 3.提供日志查询、性能监控和报警等功能 4.一站式:事件驱动方式触发响应 5.费用极低:按需付费 产品列表 专有网络VPC 对象存储OSS 日志服务SLS 函数计算 CDN
费用极低:按需付费 产品列表 最佳实践频道 专有网络 VPC 阿里云最佳实践生态群 对象存储 OSS 日志服务 SLS Function Compute CDN 文档模板(手册名称)/Error!Use the Home tab to 云服务器 ECS(产品名称)apply 标题 to the text that you want to appear here.阿里云 Function Compute计算 搭建前端 CICD系统 最佳实践 ...
数据库自治服务DAS
阿里云数据库自治服务(Database Autonomy Service,简称DAS)是一种基于机器学习和专家经验实现数据库自感知、自修复、自优化、自运维及自安全的云服务,帮助用户消除数据库管理的复杂性及人工操作引发的服务故障,有效保障数据库服务的稳定、安全及高效。
一站式数据库自治服务,支持日志审计、慢日志、SQL洞察、安全合规(云安全版)、空间治理等。畅享云上,V3新版节省20%.企业版V3-按量付费.<查看数据库全部产品.数据库自治服务(Database Autonomy Service,简称DAS)是一种基于机器学习和专家经验实现数据库自感知、自修复、自优化、自运维及自安全的云服务,帮助用户消除...
来自:
云产品
办公安全平台SASE
阿里云办公安全平台(Security Access Service Edge)依托阿里云海量的边缘节点,将安全能力延伸至用户边缘,为企业分支机构/门店、远程移动办公场景的访问互联网及云上服务流量提供就近接入的安全防护能力。
安全客户端支持在Windows、MacOS、Android及IOS等企业常用的操作系统上部署,可覆盖企业的PC、移动设备、云桌面等办公终端.只需简单的配置即可实现对企业IDC或其它云上资产的统一安全访问管控.企业办公安全中心.一站式办公安全平台.办公安全平台SASE与阿里云SD-WAN方案深度整合,支持覆盖集团总部、分支机构/门店与远程移动...
来自:
云产品
Exchange Server云上部署最佳实践
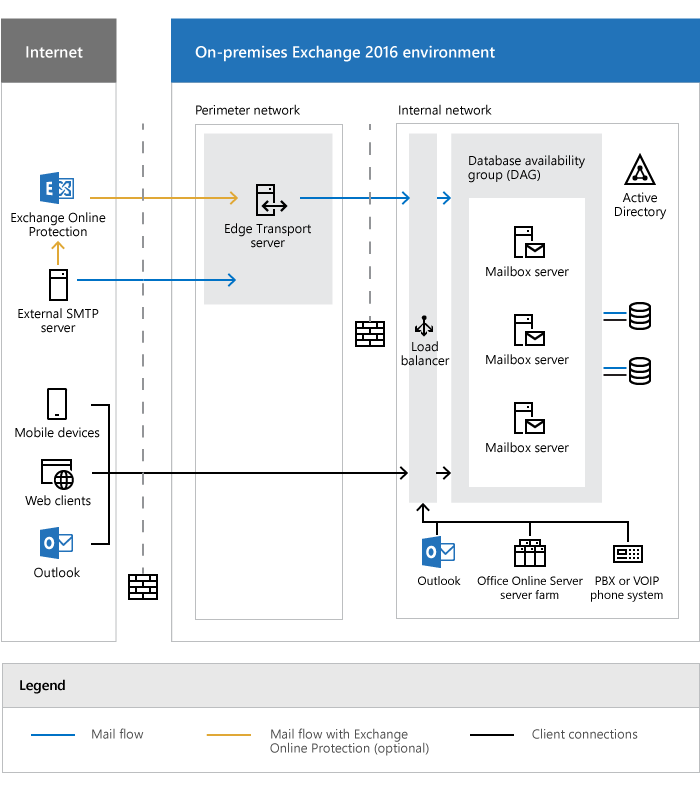
阿里云提供基础设施服务,能够以高可用、高容错且经济实惠的方式将Exchange Server部署在云上。通过在 阿里云上部署,可以获得Exchange Server的功能以及阿里云天然灵活性和安全性。
方案架构 文档版本:20220119 1 Exchange Server云上部署最佳实践 最佳实践概述 资源说明 服务器 服务器名称 角色 提供服务 别名(本文以别名描述)ecs-ad1 AD AD、DNS AD1 ecs-ad2 AD AD、DNS AD2 ecs-ex1 Mail Exchange EX1 ecs-ex2 Mail Exchange EX2 文档版本:20220119 2 Exchange Server云上部署最佳实践 最佳实践...
云原生内存数据库Tair
云原生内存数据库Tair是阿里云推出的,基于云原生架构的内存数据库,兼容Redis API,支持内存、持久内存、ESSD三种存储介质,并提供大量扩展型数据结构及企业级能力。
查看更多商品.SQL Server是发行最早的商用数据库产品之一,支持复杂的SQL查询,性能优秀,对基于Windows平台.NET架构的应用程序具有完美的支持.云数据库RDS SQL Server 版.高可靠双机热备架构及可无缝扩展的集群架构,满足高读写性能场景及容量需弹性变配的业务需求.云数据库 Redis 版.云数据库MongoDB版支持ReplicaSet和...
来自:
云产品
云数据库Redis
云数据库 Redis 版是一种全托管、兼容Redis协议的内存数据库服务,包含社区版Redis和企业版Tair,支持主从、集群和读写分离架构,具备低延迟、大吞吐、弹性扩缩容的特点。Tair提供多种系列满足不同场景的性价比要求,更有全球多活、数据闪回、大热Key探测与优化、丰富的数据结构,赋能大规模高性能要求的在线数据业务。
智能运维:专业监控和数据管理平台,主动升级.SQL Server是发行最早的商用数据库产品之一,支持复杂的SQL查询,性能优秀,对基于Windows平台.NET架构的应用程序具有完美的支持.云数据库RDS SQL Server 版.高可靠双机热备架构及可无缝扩展的集群架构,满足高读写性能场景及容量需弹性变配的业务需求.云数据库 Redis 版.云...
来自:
云产品
数据库备份DBS
数据库备份(Database Backup,简称DBS)是为数据库提供连续数据保护、低成本的备份服务。它可以为多种环境的数据提供强有力的保护,包括企业数据中心、其他云厂商、混合云及公共云。通过使用阿里实时数据流技术,实现数据库秒级备份,秒级恢复,保障数据安全。
更多产品与服务.统一备份策略 恢复演练、备份巡检 批量接入、监控与管理.腾讯云/华为云/AWS等厂商 私网DG/专线/VPN等接入 NAS/HDFS/磁带等TTL管理.秒级RPO,数据库日志解析同步 秒级RTO,全增合并 多级存储自动冷热数据分离 按量付费与弹性扩缩.一键恢复到RDS DLA备份数据湖分析 DMS历史数据归档.查看全部日志.支持的数据源...
来自:
云产品
本地数据中心基于SMB/NFS协议访问对象存储最佳实践
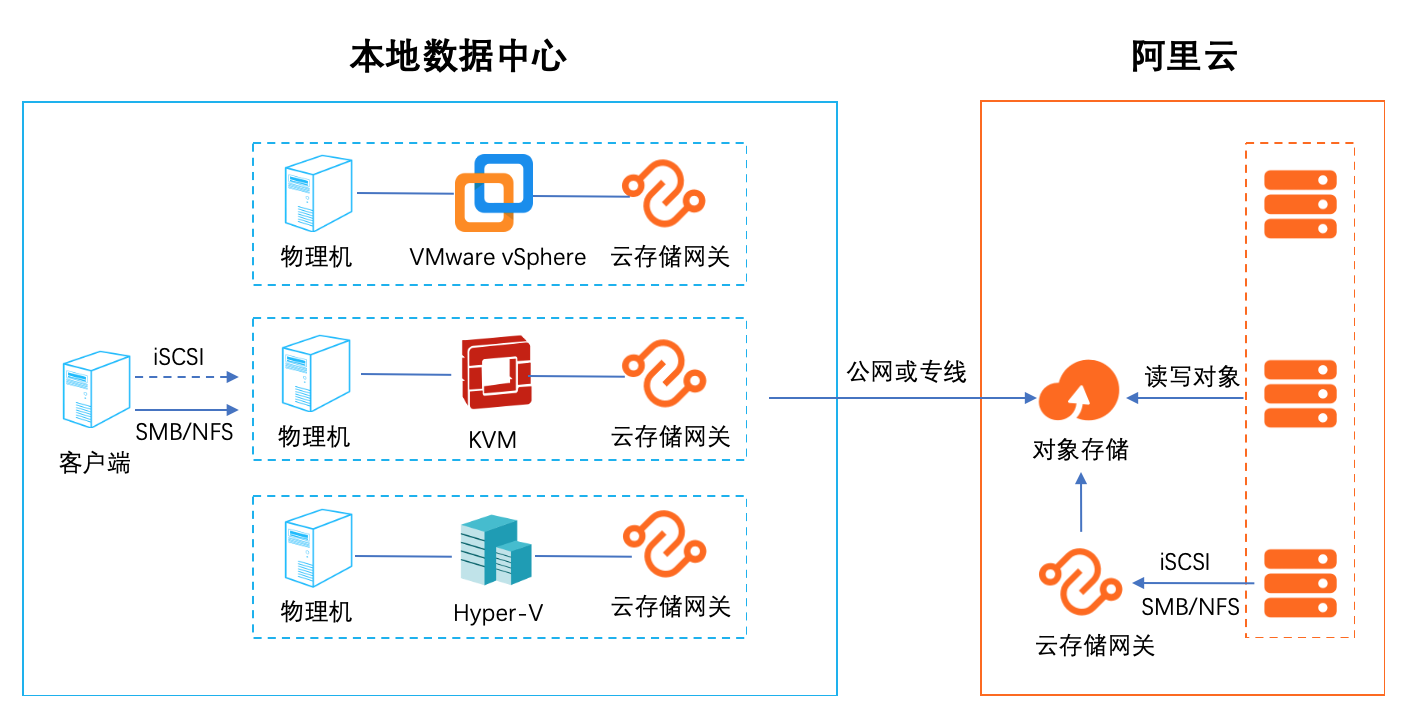
1. 云存储扩容和迁移 集成智能缓存算法,自动识别冷热数据,将热数据保留在本地缓存,保证数据访问体验,无感知的将海量云存储数据接入本地数据中心,拓展存储空间。同时在云端 保留全量数据(冷+热)保证数据的一致性 2.云容灾 随着云计算的普及,越来越多的用户把自己的业务放到了云上。但是随着业务的发展,如何提高业务的可靠性和连续性,跨云容灾是一个比较热门的话题。借助云存 储网关对虚拟化的全面支持,可以轻松应对各种第三方云厂商对接阿里云的数据容灾。 3. 多地数据共享和分发 通过多个异地部署的文件网关实例,对接同一个阿里云OSS Bucket,可以实现快速的异地文件共享和分发,非常适合多个分支机构之间互相同步和共享数据。 4. 适配传统应用 有很多用户在云上的业务是新老业务的结合,老业务是从数据中心迁移过来的使用的是标准的存储协议,例如: NFS/SMB/iSCSI。新的应用往往采用比较新的技 术,支持对象访问的协议。如何沟通两种业务之间的数据是一个比较麻烦的事情,云存储网关正好起到一个桥梁的作用,可以便捷的沟通新旧业务,进行数据交换。 5. 替代 ossfs 和 ossftp ossfs 和 ossftp 都是基于文件协议的开源工具,用户可以通过它们直接上传文件到OSS。但是这两个开源文件都不建议在生产环境使用(POSIX 兼容度低),同时挂 载在用户的客户端需要额外的配置和缓存资源,对于多个客户端的情况安装配置繁琐。通过文件网关的服务可以完美替代 ossfs 和 ossftp。通过创建文件网关,用 户只需要执行简单的挂载(NFS)和映射(Windows SMB)就可以像使用本地文件系统一样使用 OSS。
详见:https://www.aliyun.com/product/vpc 云存储网关:云存储网关(Cloud Storage Gateway:简称 CSG)是一款可在用户 IDC和阿里云上部署的软网关,以阿里云 OSS为后端存储,通过低成本的虚拟机 服务器,为云上和云下应用提供业界标准的文件服务(NFS和 SMB)和块存储服 务(iSCSI)。详见:...
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
1.创建 2020年 12月 07日对应的分区:hive 在 hive命令执行如下 HQL命令:use log_data_warehouse;alter table apache_logs add partition(year="2020",month="12",day="07");文档版本:20210425 17 自建 Hive数据仓库跨版本迁移到阿里云 Databricks数据洞察 基础环境搭建 2.将保存在 HDFS中 20201207目录下的文件加载到 ...
数据湖-在线学习场景数据分析

场景描述 本场景以在线教育中一个答题闯关类的应用为 例,使用WebServer来模拟演示这类日志数据 的分析处理。通过Nginx和Pythonflask搭建 WebServer,模拟应用中的关键页面,比如登 录、课程内容等,之后构造若干用户使用的模拟 日志数据,投递到数据湖进行分析后获取应用 PV、UV、课程内容访问排行、平均得分等等。 解决问题 基于数据湖(EMR+OSS)搭建大数据平台。 EMR和OSS使用和配置。 数据统一存储到OSS。 产品列表 E-MapReduce 对象存储OSS 云服务器ECS 访问控制RAM 专有网络VPC
本场景以在线教育中一个答题闯关类的应用为例,使用WebServer来模拟演示这类日 志数据的分析处理。通过Nginx和Pythonflask搭建WebServer,模拟应用中的关键 页面,比如登录、课程内容等,之后构造若干用户使用的模拟日志数据,投递到数据 湖进行分析后获取应用PV、UV、课程内容访问排行、平均得分等等。文档版本:20200331 ...
容器镜像服务
阿里云容器镜像服务(简称 ACR)是面向容器镜像、Helm Chart 等符合 OCI 标准的云原生制品安全托管及高效分发平台。 ACR 支持全球同步加速、大规模/大镜像分发加速、多代码源构建加速等全链路提效,与容器服务 ACK 无缝集成,帮助企业降低交付复杂度,打造云原生应用一站式解决方案。
容器镜像服务 ACR 支持多架构容器镜像(Linux、Windows、ARM 等架构)、Helm Chart v2/v3 等云原生资产的全生命周期管理.多类型资产托管.资产访问安全.提供容器镜像和 Helm Chart 的网络访问控制管理,保障资产的访问安全.资产分发安全.支持基于 RAM 的完善权限管理体系,支持镜像加签,加签镜像分发部署的全链路安全.资产...
来自:
云产品
大数据系统基准性能测试最佳实践
本方案适用于在阿里云上进行大数据基准性能测试的场景,包括 Teragen和Terasort测试,TestDFSIO测试。本文采用CADT工具结合阿里云的E-MapReduce服务快速构建测试集群,并提供了Teragen和Terasort测试,TestDFSIO测试的测试脚本,便于迅速开展测试。
阿里云账号下已开通以下阿里云服务:ᅳ GPU云服务器 ᅳ 文件存储服务 下载本文用到的操作命令和代码:以 CentOS主机为例:#yum-y install git#git clone https://code.aliyun.com/best-practice/202.git 如果你是 windows 主机,请下载 windows 版本的 git:https://git- scm.com/download/win 遇到问题,请扫钉钉二维码...
企业办公安全访问一体化
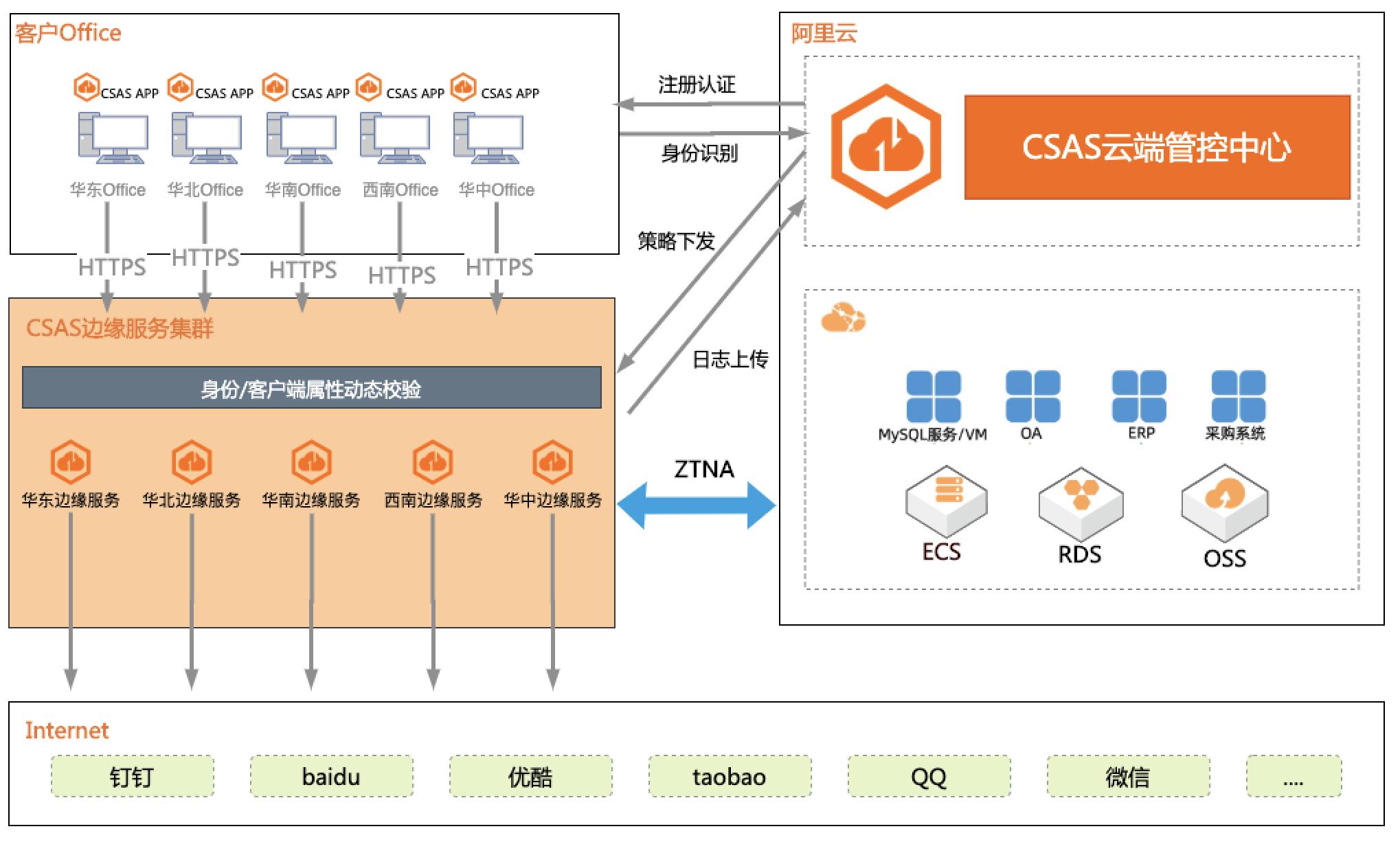
本场景模拟企业办公环境,基于 CSAS 服务构 建企业办公安全一体化方案,将“安全 + 网络” 能力无缝融合,实现了对云下办公终端安全的统 一管理,企业无需在投资复杂且昂贵的传统硬件 安全设备,即可快速构建安全、可靠、低成本的 办公安全防护体系。 1. 企业办公环境访问互联网的安全管理 2. 企业办公环境访问内网服务的安全管理 3. 企业办公网络、安全一体化管理
前言 概述 本文主要介绍如何通过阿里云CSAS(云安全访问服务)来帮助企业建设办公环境下 的安全网络访问,帮助企业更好的维护PC、移动设备端的网络安全管控和网络应用 管理,并提供安全审计日志服务。应用范围 通用行业,具有集团/分支机构的企业客户。名词解释 专有网络VPC:VirtualPrivateCloud,简称VPC,是基于阿里...
- 产品推荐
- 这些文档可能帮助您