金融分布式架构SOFAStack
阿里云金融分布式架构SOFAStack为金融用户提供全栈式的基础架构能力,是集项目管理、微服务开发、发布部署、监控运维、容灾高可用等全栈式解决方案,助力客户应用轻松转型分布式架构,保证风险安全的同时帮助业务需求敏捷迭代,支撑金融业务创新,开发人员学习成本最多可降低92%、应用开发效率可最多提升80%、运维人力成本最多可节省90%
金融分布式架构 SOFAStack™(Scalable Open Financial Architecture Stack)是构建金融级云原生架构的应用平台,沉淀了金融场景的最佳实践,提供服务构建、应用开发、部署发布、服务治理、监控运维、容灾高可用等全栈式解决方案,兼容Dubbo、Spring Cloud等微服务运行环境,助力客户各类应用轻松转型分布式架构....
来自:
云产品
云工作流
云工作流 CloudFlow 是一个用来协调多个分布式任务执行的全托管 Serverless 云服务,用户可以用顺序、分支、并行等方式来编排分布式任务,服务会按照设定好的顺序可靠地协调任务执行,跟踪每个任务的状态转换,并在必要时执行用户定义的重试逻辑,以确保工作流顺利完成。
将多个批量计算分布式作业串联或并行编排,同时支持执行时间长、并发量大的计算.根据任务依赖关系提交不同的规格批量计算作业,提升并行执行可靠性.数据处理流水线场景.可靠调度海量计算资源,个性化编排大数据处理任务.支持动态并行任务执行,实现数据处理能力的高可扩展性.提升运维效率和可靠性,流程进度可视化界面.自动...
来自:
云产品
基于云速搭CADT快速构建药物筛选批量计算环境-serverless版
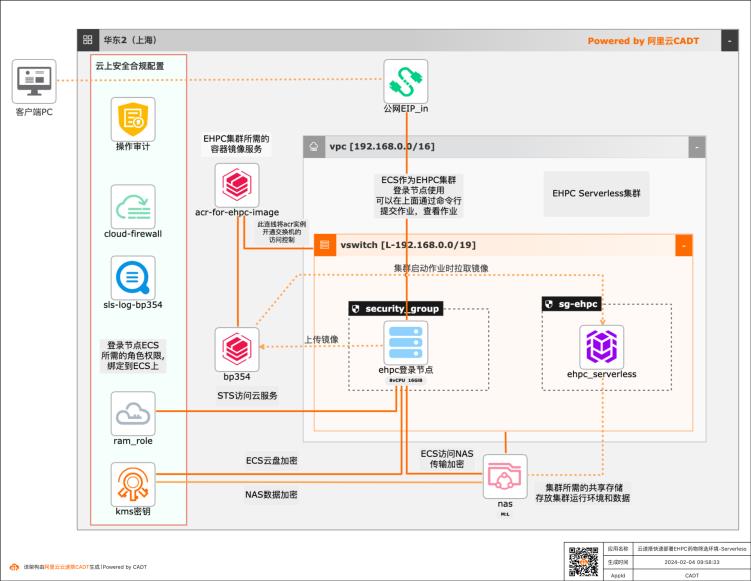
本方案基于云速搭 CADT提供一个快速构建云上Serverless版HPC批量计算环境的模板,针对生物制药领域的药物筛选场景,提供开箱即用的整套解决方案工具包,整个云上环境仅需1个小时即可完成自动化部署搭建。
产品介绍 弹性高性能计算(E-HPC):基于阿里云基础设施,为用户提供一站式公共云 HPC/AI 平台服务,面向科研,生产,教育和行业大计算,提供快捷,弹性,安全和与阿里 文档版本:20240204 2 基于云速搭 CADT部署药物筛选批量计算环境-Serverless版 最佳实践概述 云产品互通的云超算平台。文件存储 NAS:阿里云文件存储 NAS...
批量计算BCS
阿里云批量计算(BatchCompute)是一种适用于大规模并行批处理作业的分布式云服务。支持海量作业并发规模,系统自动完成资源管理,作业调度和数据加载,并按实际使用量计费。可广泛应用于电影动画渲染、生物数据分析、多媒体转码、金融保险分析、科学计算等领域。
批量计算(BatchCompute)是一种适用于大规模并行批处理作业的分布式云服务。可支持海量作业并发规模,系统自动完成资源管理,作业调度和数据加载,并按实际使用量计费。广泛应用于电影动画渲染、生物数据分析、多媒体转码、金融保险分析、科学计算等领域.孙慧颖,靖鑫,也树.MySQL低至1折起,前往限时优惠活动!1元体验简单...
来自:
云产品
基于函数计算FC实现阿里云Kafka消息轻量级ETL处理
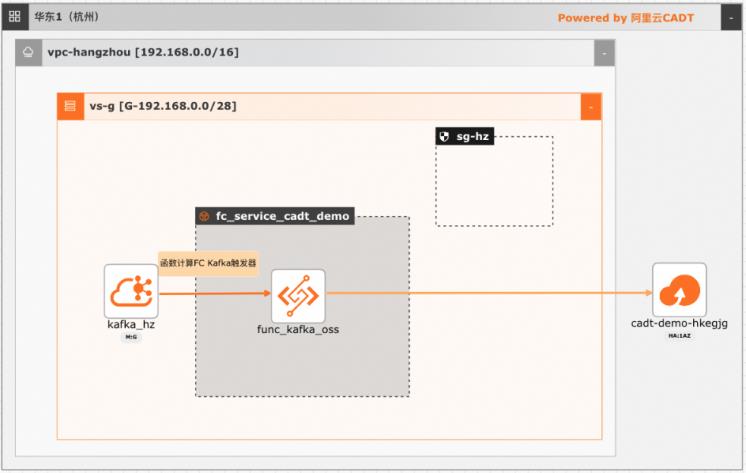
在大数据ETL场景,Kafka是数据的流转中心,Kafka中的数据一般是原始数据,可能存在多种数据混杂的情况,需要进一步做数据清洗后才能进行下一步的处理或者保存。利用函数计算FC,可以快速高效的搭建数据处理链路,用户只需要关注数据处理的逻辑,数据的触发,弹性伸缩,运维监控等阿里云函数计算都已经做了集成,函数计算FC也支持多种下游,OSS/数据库/消息队列/ES等都可以自定义的对接
使用函数计 算,您无需采购与管理服务器等基础设施,只需编写并上传代码或镜像。函数计算为您准 备好计算资源,弹性地、可靠地运行任务,并提供日志查询、性能监控和报警等功能。云消息队列 Kafka 版:云消息队列 Kafka 版是阿里云提供的分布式、高吞吐、可扩展的 消息队列服务。云消息队列 Kafka 版广泛用于日志收集、监控...
云原生分布式数据库PolarDB-X
阿里云云原生分布式数据库PolarDB-X(原DRDS升级版),可解决分库分表、海量数据存储、超高并发吞吐、复杂计算效率等问题。最高可支撑千万级并发和百PB级海量存储。
PolarDB 分布式版升级发布会,共建云原生分布式数据库生态 最新发布 公告 PolarDB产品体验升级和优化 新功能 PolarDB分布式版V2.3 集中式和分布式一体化开源发布 新功能 将DRDS模式数据库转换为AUTO模式数据库 新功能 Binlog日志服务 方案咨询 业务中台技术解决方案产品规格 PolarDB 新用户首次购买包年包月实例,指定规格...
来自:
云产品
基于函数计算FC实现企业级权限精准控制Kafka跨实例消息同步
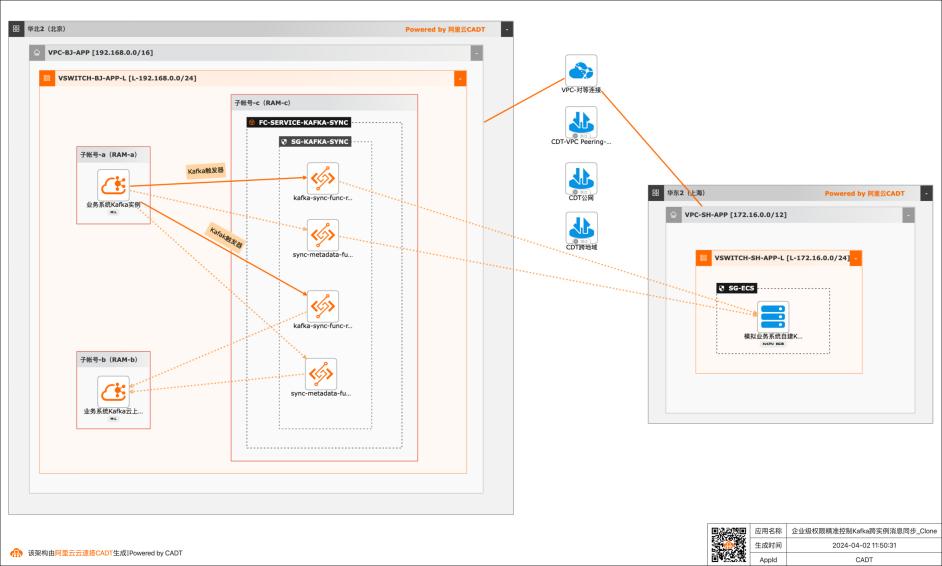
应用场景 在大数据场景,企业的Kafka实例可能存在多种情况,比如使用阿里云Kafka服务,可能是自建开源Kafka,或者是其他云上的云Kafka。不同的业务使用不同类型的Kafka实例,在这个前提下Kafka实例之间可能会需要消息同步的情况: 同帐号容灾场景:比如Kafka实例都是阿里云Kafka,但是Kafka实例会有主备之分,需要将主Kafka实例的消息实时同步到备Kafka。 跨帐号或异地容灾:这类场景比如主Kafka是阿里云Kafka,备Kafka是IDC开源自建Kafka,或者是其他云上的Kafka。 不同业务之间消息同步:因为现在的业务通常不会是信息孤岛,都需要消息互通,所以可能是A业务的Kafka实例消息需要同步到B业务的Kafka实例,并且这两个Kafka实例归属不同的RAM角色,有自己独自的权限控制。 解决问题 解决使用开源组件做消息同步的高成本问题。 解决使用开源组件做消息同步的并发性能、稳定性问题。 解决使用开源组件做消息同步的可靠性问题(重试机制,容错机制,死信队列等)。 大幅提升构建消息同步架构的效率,降低构建复杂度问题。
使用函数计 算,您无需采购与管理服务器等基础设施,只需编写并上传代码或镜像。函数计算为您准 备好计算资源,弹性地、可靠地运行任务,并提供日志查询、性能监控和报警等功能。 云消息队列Kafka 版:云消息队列Kafka 版是阿里云提供的分布式、高吞吐、可扩展的 消息队列服务。云消息队列Kafka版广泛用于日志收集、监控...
基于SpringCloud应用玩转MSE实践
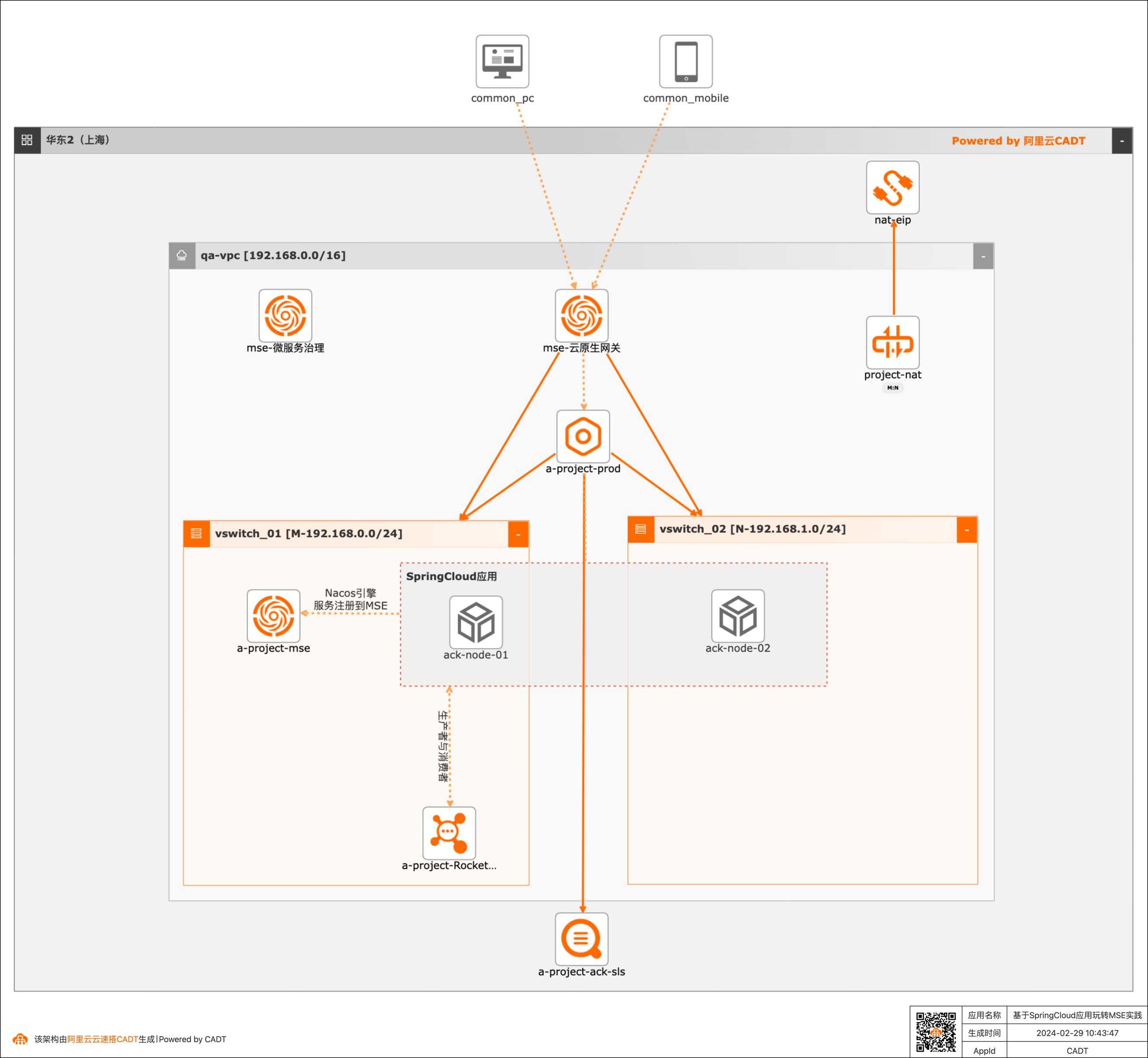
随着业务不断创新,大型的单个应用和服务会被拆分为数个甚至数十个微服务,微服务架构已经被广泛应用。 微服务的好处在于快速迭代,如何在迭代过程中保障线上流量不受损。依赖开源产品缺少无运维工具,常常需要投入较大的运维人力和成本。 本实践提供基于云原生应用产品提供微服务注册配置中心、微服务治理和云原生网关等一系列高性能和高可用的企业级云服务能力。
name=jinfeng 步骤 也可以通过 脚本批量调用通过服务治理的分流监控,观察流量分情况。4 shell 登录 控制台,通过 管理集群入口,执行如下脚本:ACK cloudshell#!bin/bash for((i=1;i 流量防护-行为管理-新增行为 {"resultCode":"503","message":"requestlimit","detail":"流量超限触发流控规则了"} 文档版本:20240229基于...
基于函数计算FC实现阿里云Kafka消息内容控制MongoDB DML操作
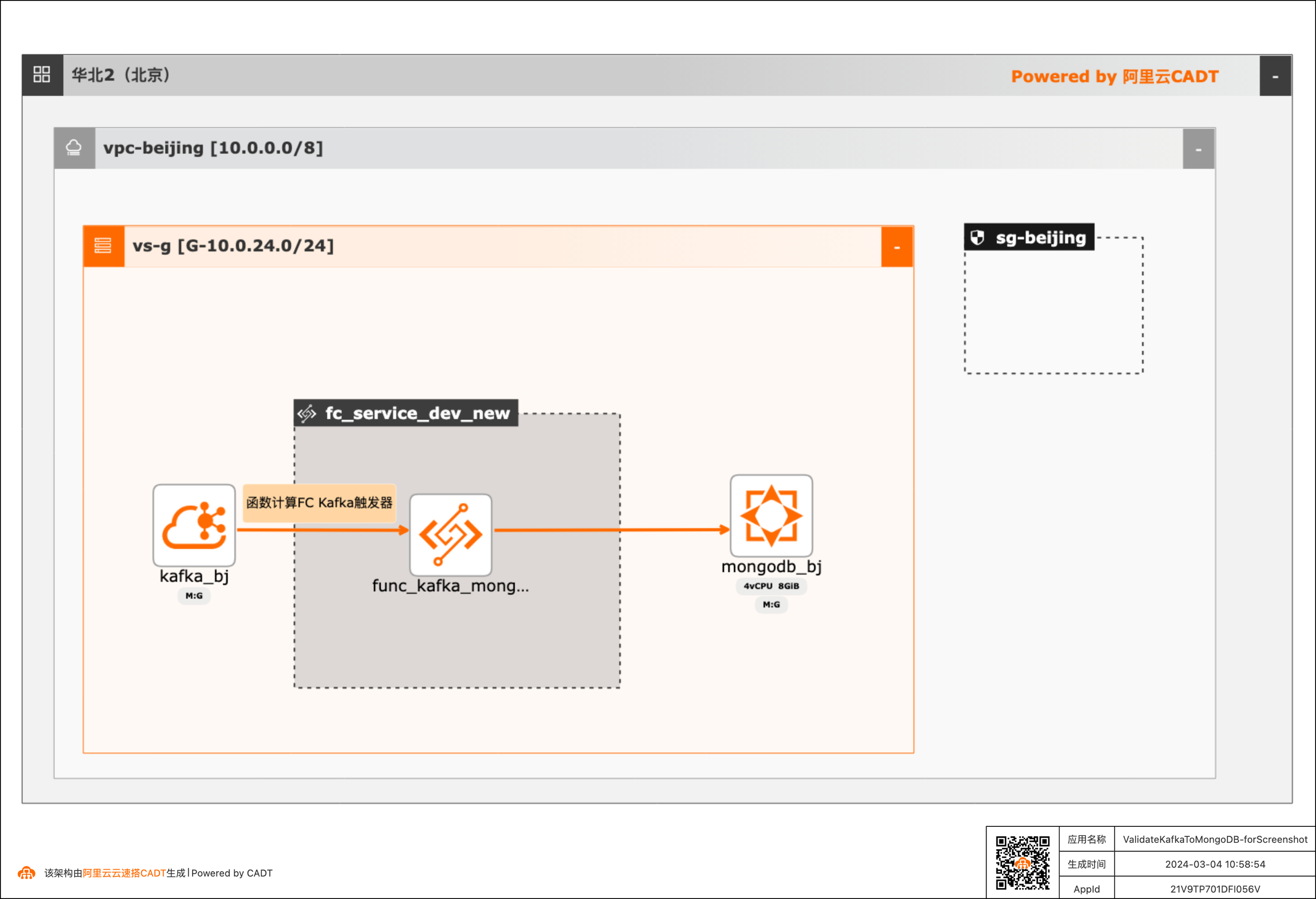
在大数据ETL场景,将Kafka中的消息流转到其他下游服务是很常见的场景,除了常规的消息流转外,很多场景还需要基于消息体内容做判断,然后决定下游服务做何种操作。 该方案实现了通过Kafka中消息Key的内容来判断应该对MongoDB做增、删、改的哪种DML操作。 当Kafka收到消息后,会自动触发函数计算中的函数,接收到消息,对消息内容做判断,然后再操作MongoDB。用户可以对提供的默认函数代码做修改,来满足更复杂的逻辑。 整体方案通过CADT可以一键拉起依赖的产品,并完成了大多数的配置,用户只需要到函数计算和MongoDB控制台做少量配置即可。
整体方案通过 CADT 可以一键拉起依赖的产品,并完成了大多数的配置,用户只需要到函数计 算和 MongoDB 控制台做少量配置即可。方案优势 l 可以实现根据 Kafka 消息的具体内容判断,该对 MongoDB 做哪种 DML 操作,灵活性和可 扩展性极高。l 函数计算具有完善的日志系统、容错机制。可以清晰的看到对每条消息的处理日志,...
EHPC药物筛选
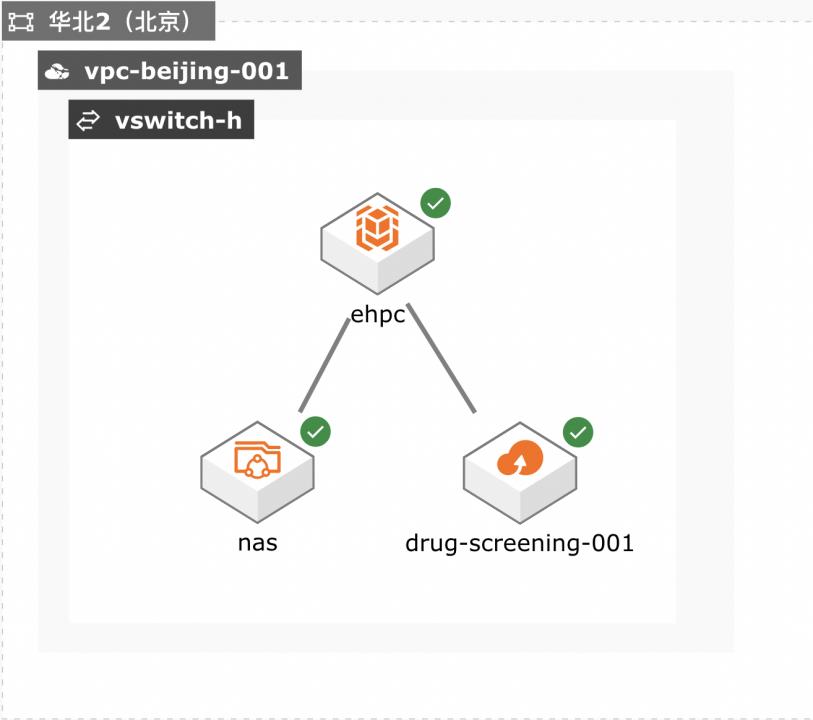
场景描述 本方案适用于使用弹性高性能计算 EHPC和文件存储NAS来搭建基础环 境,运行药物筛选应用AutodockVina 的场景中,这里采用批处理方式来提交 作业,并可以可视化计算结果。 方案架构 1.计算之前,将数据通过互联网/闪电立方/高速通道上传到阿里云OSS 2.计算时,将数据从OSS拉取到文件共享存储NAS上 3.计算时,在EHPC集群上进行,计算节点从NAS上读写数据 • 容量型NAS:低成本,大容量 • 性能型NAS:适合高IOPS应用,作为临时目录 • CPFS:适合超大规模,并行度极高的作业 4.计算节点: • 如果对计算时间不敏感,希望低成本运算,可选ECS实例 • 如果时效性要求高,建议采用SCC超级计算集群 5.可视化 • 如果可视化部分计算量不大,可以采用EHPC自带的可视化服务 解决问题 1.使用EHPC运行药物筛选应用 2.使用nas存储计算数据 3.使用OSS保存计算结果 • 通过分子对接(moleculardocking)模拟计算进行药物筛选,是模拟小分子配体和生物大分子受体的 相互作用,预测配体和受体的结合模式和亲和力。 • 通常,有很多已有的配体库,如商业化的Specs、Enamine和ChemDiv化合物库。提供大量配体,模 拟计算就是计算这些配体和给定受体的相互作用。 • 每次模拟计算通常处理一个配体和一个受体,不同配体之间没有依赖,因此可以同时大规模并行处 理。 本解决方案同样适用于有批量、高并发处理需求的其它生物、医药等场景。 产品列表 弹性高性能计算E-HPC 文件存储NAS 对象存储OSS
使用数组作业解决批处理任务 从批处理和数组作业介绍看,数组作业适用批处理计算的场景,但做到简易使用,还存在以 下问题:1.批处理任务与作业的对应关系?当任务数量巨大时,是一个任务就是一个作业,还是一个作业包含多个任 务?2.如何从$PBS_ARRAY_ID 到不同任务的关联?并能够方便对应不同任务的不同参数?3.如何跟踪...
云原生多模数据库Lindorm
云原生多模数据库Lindorm提供各规模、多模型的云原生数据库服务。可兼容HBase/Cassandra、OpenTSDB、Solr、SQL、HDFS等多种开源标准接口。支持海量数据的低成本存储处理和弹性按需付费,是互联网、IoT、车联网、广告、社交等场景首选数据库,也是为阿里核心业务提供支撑的数据库之一。
存算一体化设计,支持多种分布式计算模型,多种存储模式融合,多种访问模式融合,开箱即用.海量数采测点数据高通量、高并发、低延迟写入,库内高效数据统计、计算、处理等分析任务执行.海量广告营销数据的实时存储.使用Lindorm存储广告营销中的画像特征、用户事件、点击流、广告物料等重要数据,提供高并发、低延迟、灵活...
来自:
云产品
Databricks数据洞察
阿里云Databricks数据洞察是基于Apache Spark的全托管数据分析平台, 内核采用更高效、稳定的商业版Databricks Runtime和Delta Lake。可满足数据分析师、数据工程师和数据科学家在大数据场景下对数据湖分析、实时数仓、离线数仓、BI数据分析、AI机器学习等需求
满足高性能、高稳定性、可弹性的计算需求.Databricks Delta Lake为数据湖分析提供了ACID事务能力,轻松处理包含数十亿文件的PB级表的元数据信息,实现了批流一体的数据处理方式.同时满足数据科学家、数据工程师以及业务分析师的计算需求,提供交互式的协同分析工作平台.计算存储分离,减少数据冗余,实现多引擎间的数据共享...
来自:
云产品
边缘计算云原生架构解决方案
边缘计算云原生架构解决方案,旨在通过云原生架构构建边缘计算(物联网、CDN、混合云等)云边一体化协同基础设施。通过云端托管边缘资源/应用,无缝对接丰富云产品能力,提供边缘计算业务的自动化运维、高可靠性保障,降低边缘应用的运维工作量,提升边缘计算业务创新效率。
基于运营商边缘节点和网络构建,一站式提供分布式算力资源,帮助用户有效降低计算时延和成本.物联网边缘计算 LinkEdge.能够在不同量级的计算节点中,提供安全可靠、低延时、低成本、易扩展、弱依赖的本地计算服务.容器服务提供高性能可伸缩的容器应用管理能力,支持企业级容器化应用的全生命周期管理.容器镜像服务 ACR.容器...
来自:
解决方案
- 产品推荐
- 这些文档可能帮助您