云原生数据仓库AnalyticDB PostgreSQL版
阿里云MPP架构的云原生数据仓库,可提供PB级海量数据在线/离线分析服务,是面向各行各业的有竞争力的数仓方案,真正做到“人人可用的数据分析服务”。
用户现有的OLTP数据库实例,包括 RDS MySQL,PostgreSQL,或传统数据库实例 Oracle,SQL Server等,数据可以通过 数据传输服务 DTS,数据集成服务 Dataworks 等实时同步到云原生数据仓库AnalyticDB PostgreSQL版,构筑可线性扩展的在线企业数据仓库服务。同时可以结合 Dataworks 的 ETL 调度功能,基于 AnalyticDB for ...
来自:
云产品
AnalyticDB和通义千问快速构建RAG应用
利用AnalyticDB PostgreSQL与DashScope灵积模型服务提供的通义千问模型构建Retrieval-Augmented Generation (RAG) 应用,通过检索相关信息并结合上下文生成准确的自然语言回答,增强语言模型处理和理解复杂查询的深度。
相关产品云服务器 ECS云原生数据仓库 AnalyticDB PostgreSQL 版模型服务灵积 DashScope在线咨询方案优势检索外部知识从外部数据源(例如企业知识库)中检索强相关的信息,避免了仅依赖预训练知识的局限性。回答准确度高基于知识检索结果,结合上下文和用户意图的理解,生成准确的答案。由于整合了外部数据源的知识,因此...
来自:
解决方案
云原生数据仓库AnalyticDB MySQL数据仓库
阿里云云原生数据仓库AnalyticDB MySQL版(简称AnalyticDB)是融合数据库、大数据技术于一体的云原生企业级数据仓库平台。云原生数据仓库AnalyticDB MySQL版支持数据实时写入和同步更新、实时计算和实时服务,可用于构建企业级报表系统、数据仓库和数据服务引擎。
通过简单几步配置即可将RDS、PolarDB 或者日志服务中某个日志库中的数据快速同步到云原生数据仓库AnalyticDB MySQL版集群中.将RDS和PolarDB的多个数据库实例一键配置DTS同步链路.数据库数据接入.配置SLS数据同步链路,将日志数据快速接入.日志数据接入.PolarDB MySQL数据免费接入、多表增量更新物化视图、UDF、Multi-...
来自:
云产品
基于函数计算FC实现物联网音视频处理
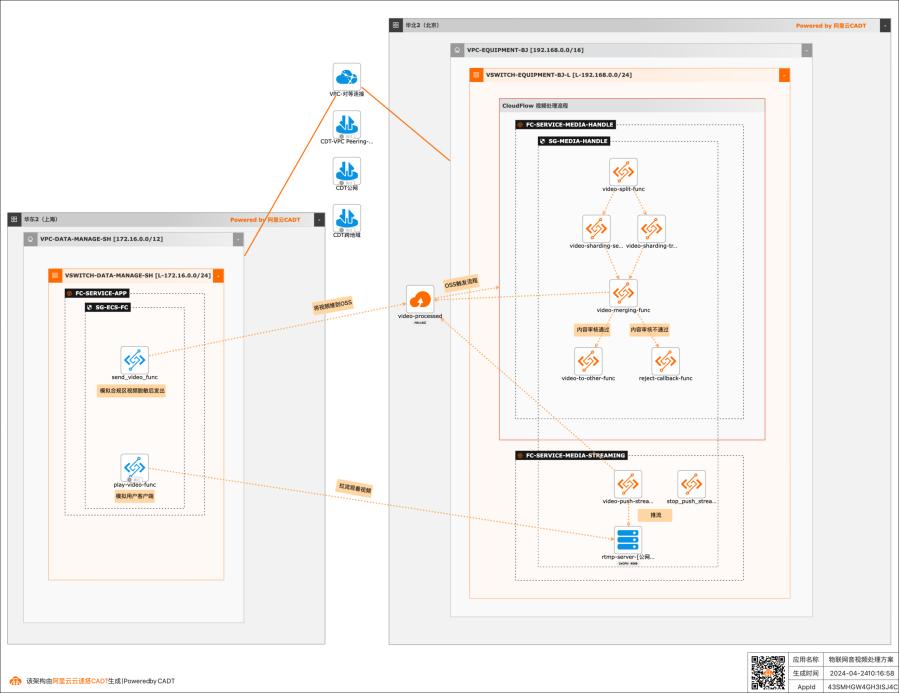
在物联网场景中,智能设备会产生大量的非结构化数据,并且采集量和频率都很高。比如各类摄像头(家用摄像头、车载摄像头、工业监控摄像头等)采集的数据。企业需要对这些非结构化数据做快速的分析和处理,然后应用到下游业务中,所以需要一套高并发、低成本、自动化的方案。该最佳实践就适用于这类场景。
应用场景 在物联网场景中,智能设备会产生大量的非结构化数 据,并且采集量和频率都很高。比如各类摄像头(家 用摄像头、车载摄像头、工业监控摄像头等)采集的 数据。企业需要对这些非结构化数据做快速的分析和 处理,然后应用到下游业务中,所以需要一套高并发、低成本、自动化的方案。该最佳实践就适用于这类场 景。解决...
基于函数计算FC镜像部署Stable Diffusion大模型
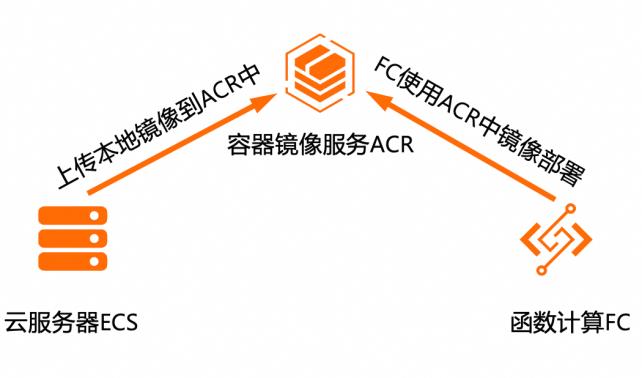
在现代AI应用中, Stable Diffusion等模型因其强大的功能而受到关注。然而,这些模型对计算资源的高需求和复杂的运维管理成为部署时的挑战。基于函数计算FC的无服务器计算模式为这类模型的部署提供了全新的解决方案。用户只需关注模型的部署和调用逻辑,而无需关心底层的服务器配置、资源分配和扩展性等问题。函数计算FC能够自动处理函数的执行环境,包括冷启动、弹性伸缩等,确保模型能够在大规模的请求下稳定运行。
这些场景通常需要处理大 产品列表 量的数据,并实时生成准确的响应。通过将 SD等模 阿里云函数计算(FC)型部署在函数计算 FC上,提供了高效、弹性、低成 阿里云镜像容器服务(ACR)本的部署解决方案。云服务器(ECS)解决问题•简化模型部署流程•全链路自适应弹性,无需为流量峰谷做频繁的手 工处理•内置CICD平台能力,...
大数据近实时数据投递MaxCompute
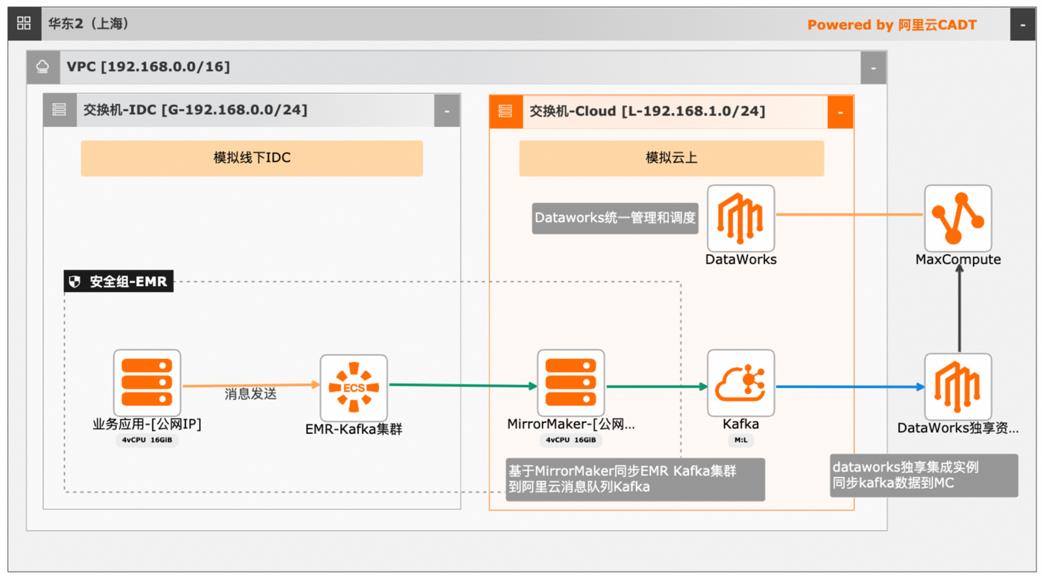
本文介绍离线大数据场景使MaxCompute构建云 上近实时数仓,打通云下数据上云链路,解决数据复杂类型支持和动态分区问题,满足高级数据处理需求的最佳实践。 l混合云环境下,现有业务系统零改造,打通数据上云链路。 l使用UDF实现复杂数据类型转换和数据动态分区。 l使用DataWorks配置周期调度业务流程,数据自动入仓。 l借助MaxCompute优化计算引擎,实现降本增效。 产品列表 云服务器ECS 专有网络VPC 访问控制RAM 数据总线DataHub E-MapReduceEMR DataWorks 大数据计算服务MaxCompute
文档版本:20240419 3 大数据近实时数据投递 MaxCompute 在官方模板库内找到 大数据近实时数据投递 MaxCompute 模版,选择基于方案新 建。根据提示信息和实际需求修改资源参数,完成配置后,点击保存,设定应用名称后点 击确认。应用保存成功后,点击部署应用。双击 Kafka实例,模板中已配置 Topic,白名单等信息。文档版本...
基于函数计算FC实现阿里云Kafka消息轻量级ETL处理
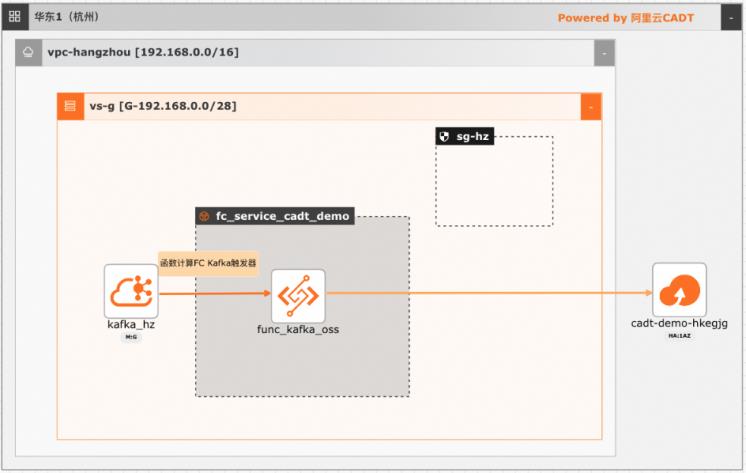
在大数据ETL场景,Kafka是数据的流转中心,Kafka中的数据一般是原始数据,可能存在多种数据混杂的情况,需要进一步做数据清洗后才能进行下一步的处理或者保存。利用函数计算FC,可以快速高效的搭建数据处理链路,用户只需要关注数据处理的逻辑,数据的触发,弹性伸缩,运维监控等阿里云函数计算都已经做了集成,函数计算FC也支持多种下游,OSS/数据库/消息队列/ES等都可以自定义的对接
利用函数计算 FC,可以快速高效的搭建数据处理链路,用户只需要关注数据处理的逻辑,数据的触发,弹性 伸缩,运维监控等阿里云函数计算都已经做了集成,函数计算 FC也支持多种下游,OSS/数据 库/消息队列/ES等都可以自定义的对接。方案优势 快速搭建起数据处理全链路 全链路自适应弹性,无需为流量峰谷做频繁的手工处理 ...
基于Flink+ClickHouse构建实时游戏数据分析
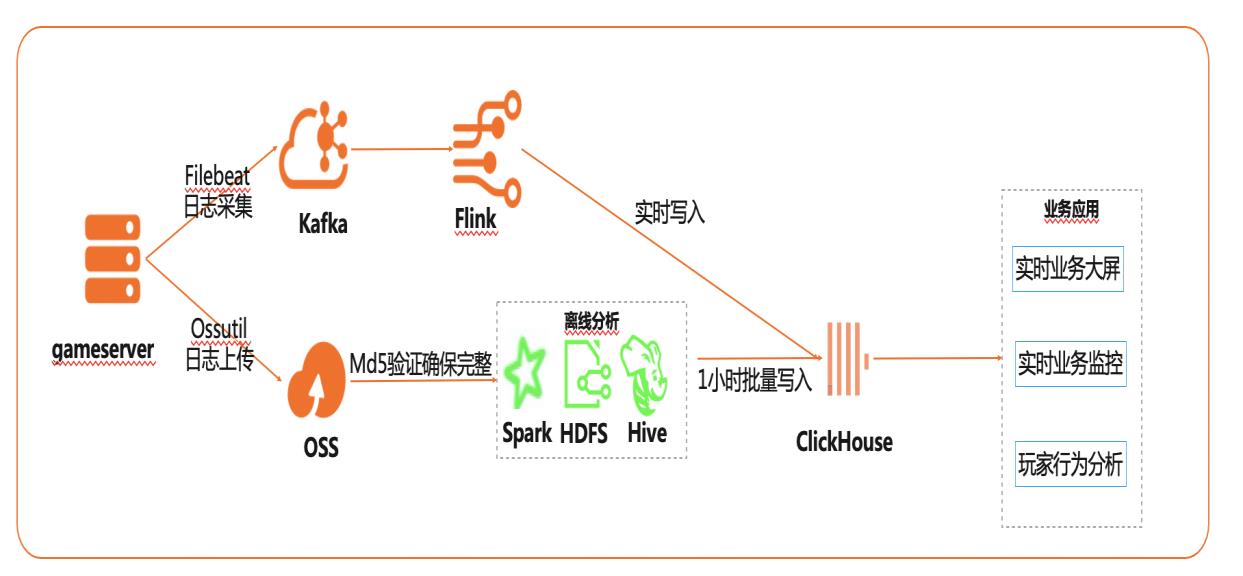
在互联网、游戏行业中,常常需要对用户行为日志进行分析,通过数据挖掘,来更好地支持业务运营,比如用户轨迹,热力图,登录行为分析,实时业务大屏等。当业务数据量达到千亿规模时,常常导致分析不实时,平均响应时间长达10分钟,影响业务的正常运营和发展。 本实践介绍如何快速收集海量用户行为数据,实现秒级响应的实时用户行为分析,并通过实时流计算Flink/Blink、云数据库ClickHouse等技术进行深入挖掘和分析,得到用户特征和画像,实现个性化系统推荐服务。 通过云数据库ClickHouse替换原有Presto数仓,对比开源Presto性能提升20倍。 利用云数据库ClickHouse极致分析性能,千亿级数据分析从10分钟缩短到30秒。 云数据库ClickHouse批量写入效率高,支持业务高峰每小时230亿的用户数据写入。 云数据库ClickHouse开箱即用,免运维,全球多Region部署,快速支持新游戏开服。 Flink+ClickHouse+QuickBI
本实践介绍如何快速收集海量用户行为数 据,实现秒级响应的实时用户行为分析,并 通过实时流计算、云数据库 ClickHouse等 技术进行深入挖掘和分析,得到用户特征和 画像,实现个性化系统推荐服务。产品列表 最佳实践频道 阿里云最佳实践分享群 专有网络 VPC 弹性公网 IP EIP 云服务器 ECS 消息队列 Kafka版 云数据库 ...
基于函数计算实现直播流录制-存储-通知
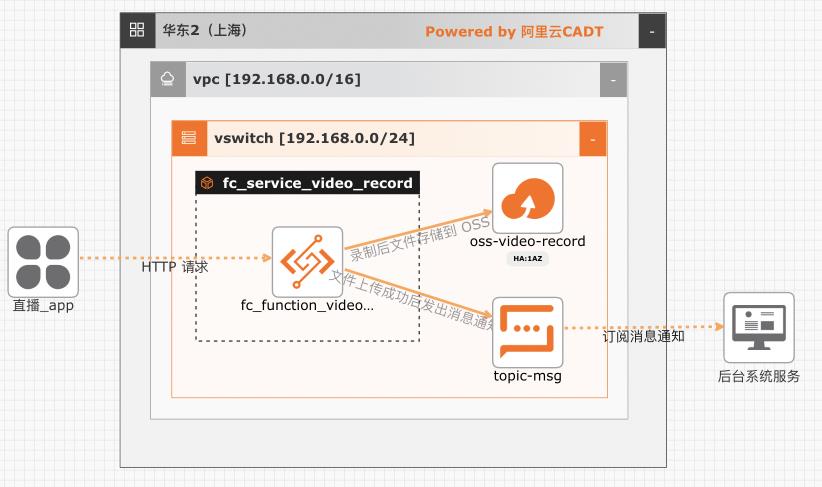
在互娱、教育、电商等行业都会有直播相关的业务,大部分场合都需要对直播相关的业务做安全审核,或者对直播的课程进行录制和转码。该方案实现了一种完全按需拉起、按量弹性、按实际使用付费的录制方案。基于本方案还可以扩展实现直播流截帧、自动化安全审核等能力
基于函数计算实现直播流录制-存储-通知最佳实践 业务架构 场景描述 基于阿里云函数计算实现对直播流的实时录制,录制结束后会把录制的结果写入 OSS 存储桶,并把录制的结果写到消息队列,下游服务可以通 过订阅的方式来消费消息 应用场景 在互娱、教育、电商等行业都会有直播相关的业 务,大部分场合都需要对直播相关的业务...
容器多云统一监控日志
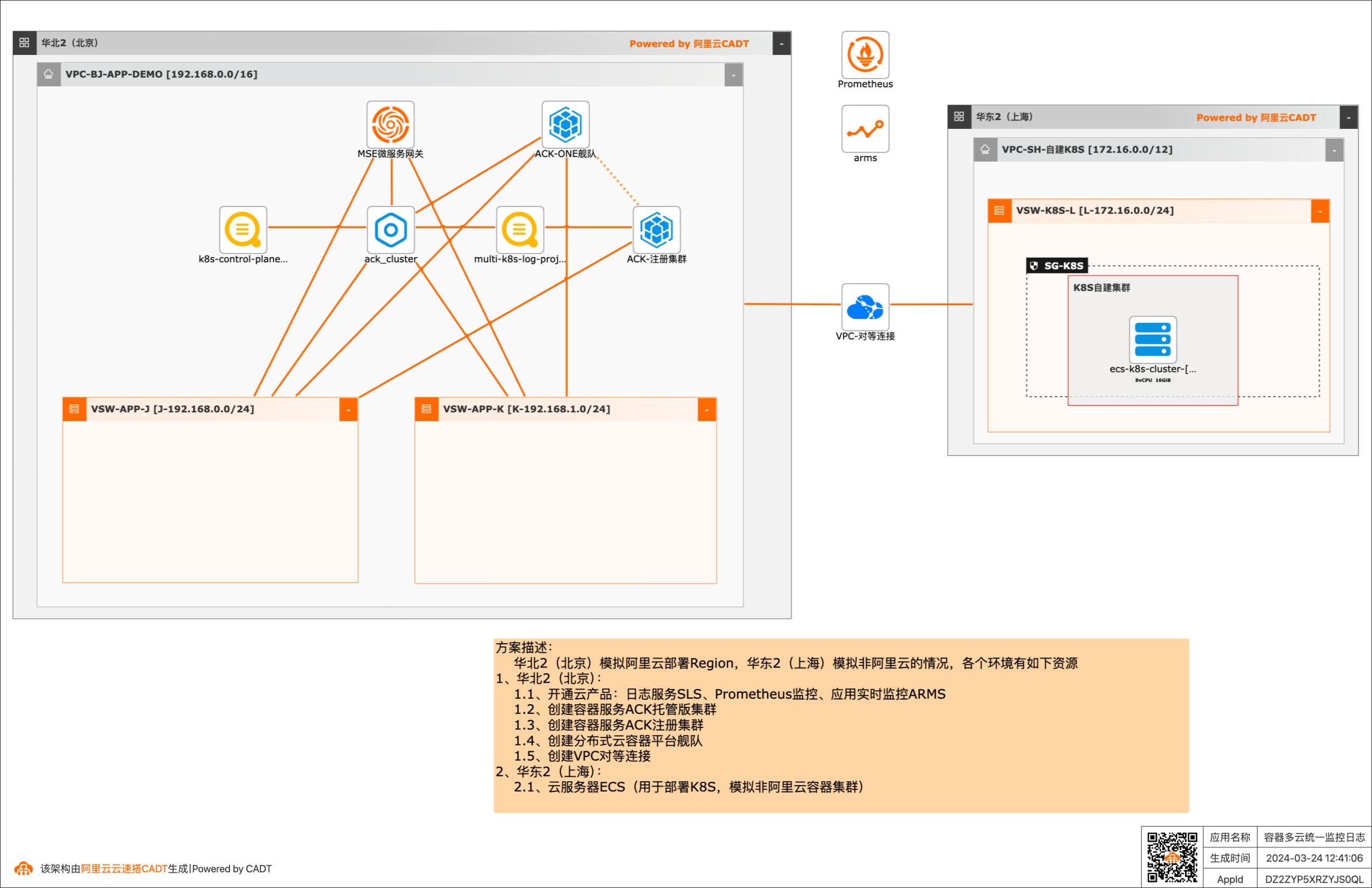
多云、混合云成为常态,Forrester 报告中指出,未来 89% 的企业至少使用两个云,74% 的企业至少使用三个甚至更多公有云,在面对多云/混合云这样大的趋势下,Gartner报告指出,安全、运维复杂性、财务复杂性是多云架构的主要挑战,本方案给出了在多云/混合云场景下,构建基于容器环境下的统一管理、统一监控和统一日志方案,解决多云、混合云场景下,运维复杂性问题。 应用场景 客户在阿里云以外的其他云服务商(AWS、Azure、GCP、TencentCloud、HuaweiCloud等)或者IDC基于容器(Kubernetes)运行业务系统,希望构建容器场景下的统一监控日志系统,方便做不同大屏和问题分析定位。 解决问题 •构建容器多云统一监控和日志系统,在一个平台可以看到不同环境系统的运行情况。
日志服务SLS:是云原生观测与分析平台,为Log、Metric、Trace等数据提供 大规模、低成本、实时的平台化服务,日志服务一站式提供数据采集、加工、查 询与分析、可视化、告警、消费与投递等功能,全面提升您在研发、运维、运营、安全等场景的数字化能力。文档版本:20240322 2容器多云统一监控日志 最佳实践概述 应用...
基于函数计算FC实现企业级权限精准控制Kafka跨实例消息同步
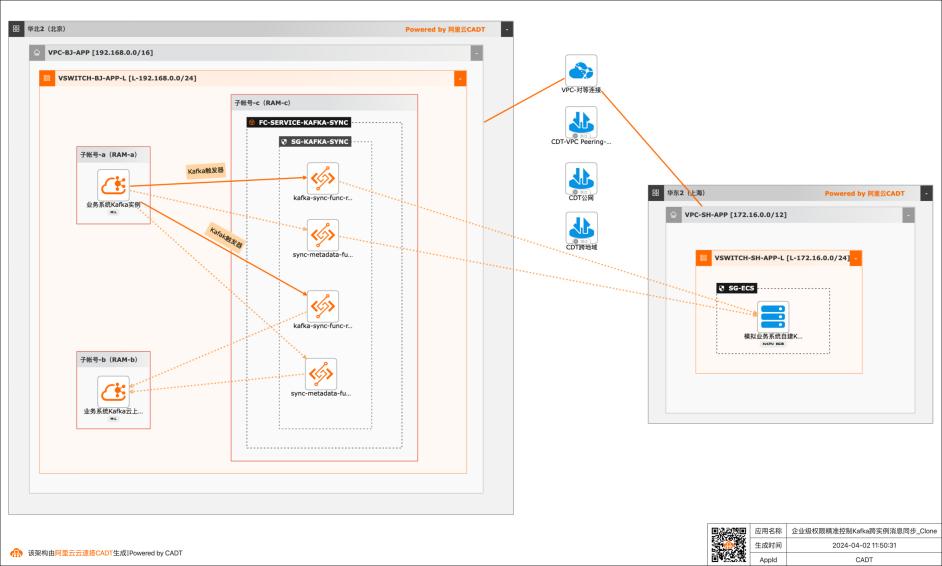
应用场景 在大数据场景,企业的Kafka实例可能存在多种情况,比如使用阿里云Kafka服务,可能是自建开源Kafka,或者是其他云上的云Kafka。不同的业务使用不同类型的Kafka实例,在这个前提下Kafka实例之间可能会需要消息同步的情况: 同帐号容灾场景:比如Kafka实例都是阿里云Kafka,但是Kafka实例会有主备之分,需要将主Kafka实例的消息实时同步到备Kafka。 跨帐号或异地容灾:这类场景比如主Kafka是阿里云Kafka,备Kafka是IDC开源自建Kafka,或者是其他云上的Kafka。 不同业务之间消息同步:因为现在的业务通常不会是信息孤岛,都需要消息互通,所以可能是A业务的Kafka实例消息需要同步到B业务的Kafka实例,并且这两个Kafka实例归属不同的RAM角色,有自己独自的权限控制。 解决问题 解决使用开源组件做消息同步的高成本问题。 解决使用开源组件做消息同步的并发性能、稳定性问题。 解决使用开源组件做消息同步的可靠性问题(重试机制,容错机制,死信队列等)。 大幅提升构建消息同步架构的效率,降低构建复杂度问题。
基于函数计算FC实现企业级权限精准控制Kafka跨实例消息同步最佳实践 场景描述 业务架构 基于阿里云函数计算FC实现同帐号阿里云Kafka实 例之间消息、元数据同步,跨帐号阿里云Kafka实例 之间消息、元数据同步,阿里云Kafka实例和IDC 自建Kafka(其他云Kafka)之间消息、元数据同步。应用场景 在大数据场景,企业的Kafka实例...
基于MSE云原生网关同城多活
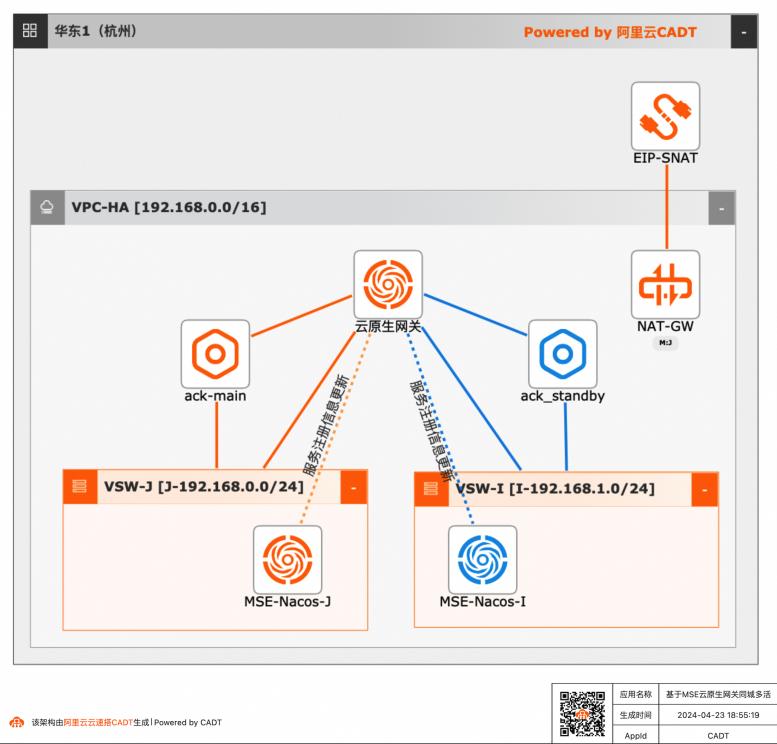
借助云原生微服务MSE网关,MSE配置注册中心的同城容灾多活微服务应用。构建一个经典的微服务场景,实现同城容灾的步骤,体现云原生相关产品在用户上云,高可用同城容灾多活场景下的能力。
文档版本:20240423 40 基于MSE云原生网关同城多活最佳实践 场景验证 步骤4 等待压测任务生成 步骤5 查看压测数据 步骤6 通过在 ack-main中删除资源方式模拟机房故障,有损秒级切换,查看 PTS压测曲线 文档版本:20240423 41 基于MSE云原生网关同城多活最佳实践 场景验证 服务删除时,压测曲线会出现毛刺,请记录删除操作...
基于云速搭CADT快速构建药物筛选批量计算环境-serverless版
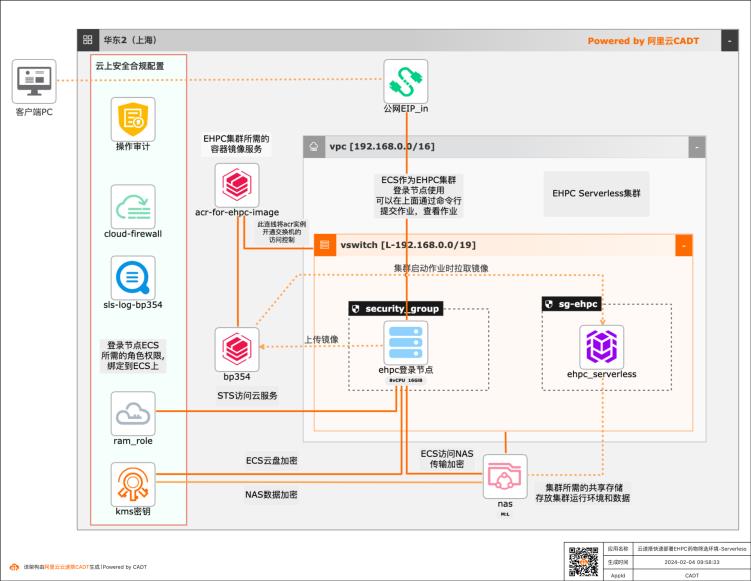
本方案基于云速搭 CADT提供一个快速构建云上Serverless版HPC批量计算环境的模板,针对生物制药领域的药物筛选场景,提供开箱即用的整套解决方案工具包,整个云上环境仅需1个小时即可完成自动化部署搭建。
h)操作审计/SLS:GxP合规要求,为云上所有操作进行审计跟踪,数据留存在 SLS 日志库中。i)云防火墙:提供云环境的边界安全。2、通过云速搭 CADT模板部署,将自动化完成以下任务:模板将自动化完成上述产品实例的构建,以及云资源之间的关联关系绑定。同时本方案提供一个初始化脚本,完成以下运行环境的构建。docker 环境...
数据传输服务DTS
阿里云数据传输服务集数据迁移、订阅及实时同步功能于一体,能够解决公共云、混合云场景下,远距离、毫秒级异步数据传输难题,支持关系型数据库、NoSQL、大数据(OLAP)等数据源,其底层基础设施采用阿里双11异地多活架构,为数千下游应用提供实时数据流,已在线上稳定运行7年之久。
可以将源端数据库数据实时同步到数据仓库,构建实时分析数仓,也可以根据调度策略的配置,定期地将源库中的结构和存量数据迁移至目标库中,构建更加灵活的数据仓库(例如构建T+1的周期性数仓).实时同步功能支持将并发粒度缩小到事务级别,能够并发同步同张表的更新数据,提升同步性能;支持多并发压缩传输,降低传输链路对...
来自:
云产品
异地双活场景下的数据双向同步
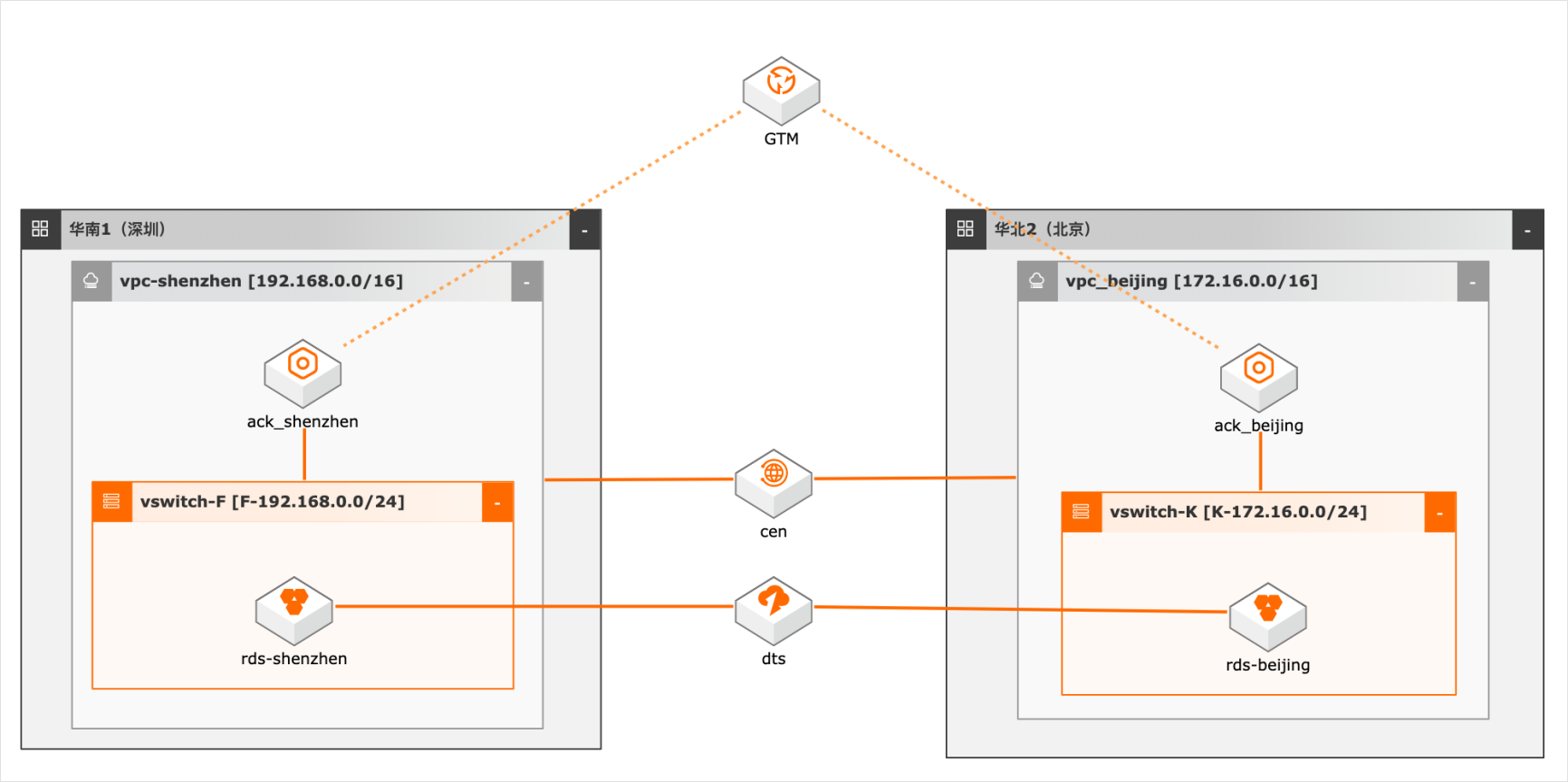
概述 随着客户业务规模的扩大,对系统高可用性要求越来越高,越来越多用户采用异地双活/多活架构,多活架构往往涉及业务侧做单元化改造,本方案仅模拟用户已做单元化改造后的数据双向同步,数据库采用双主架构,本地写本地读,同时又保证双库的数据一致性,为业务增加可用性和灵活性。 适用场景 数据库双向同步 数据库全局ID不冲突 双活架构的数据库建设问题 技术架构 本实践方案基于如下图所示的技术架构和主要流程编写操作步骤: 方案优势 DTS双向同步,采用独立模块避免数据同步占用系统资源。 奇偶ID涉及,避免数据冲突。 DTS多种处理冲突的方式供业务选择。 安全:原生的多租户系统,以项目进行隔离,所有计算任务在安全沙箱中运行。
随着客户业务规模的扩大,对系统高可用性要求越 数据库双向同步 来越高,越来越多用户采用异地双活/多活架构,多 数据库全局 ID不冲突 活架构往往涉及业务侧做单元化改造,本方案仅模 双活架构的数据库建设问题 拟用户已做单元化改造后的数据双向同步,数据库 采用双主架构,本地写本地读,同时又保证双库的数 据一致性,为...
Databricks数据洞察
阿里云Databricks数据洞察是基于Apache Spark的全托管数据分析平台, 内核采用更高效、稳定的商业版Databricks Runtime和Delta Lake。可满足数据分析师、数据工程师和数据科学家在大数据场景下对数据湖分析、实时数仓、离线数仓、BI数据分析、AI机器学习等需求
流批一体数据仓库.流批一体数据仓库.简化机器学习生命周期,快速进行模型测试、实验、以及生产部署,并可视化结果.Spark SQL/Data Frame进行的分布式的数据预处理,EDA和特征工程.利于Spark ML、ML相关模块做特征处理,进行ML/DL模型分布式训练.分布式模型训练.封装模型到Spark ML pipeline,以PMML或Mleap方式存放于OSS,...
来自:
云产品
- 产品推荐
- 这些文档可能帮助您