云原生数据湖分析DLA
阿里云云原生数据湖分析是新一代大数据解决方案,采取计算与存储完全分离的架构,支持对象存储(OSS)、RDS(MySQL等)、NoSQL(MongoDB等)数据源的消息实时归档建仓,提供Presto和Spark引擎,满足在线交互式查询、流处理、批处理、机器学习等诉求。内置大量优化+弹性,比开源自建集群最高降低50%+的成本,最快可1分钟级拉起300个计算节点,快速满足业务资源要求。
适合大量数据清洗,Streaming,编写Java、Scala、Python等SQL难表达的场景.采用Serverless形态,支持Presto和Spark两种引擎,集群分钟级弹性扩缩容,相比线下部署机房成本更低.丰富的产品系列,全面覆盖多种场景需求.CU时资源包.采用按量付费+资源包的付费模式,适用于业务量波动较大且频繁场景。用资源包抵扣数据湖分析...
来自:
云产品
企业构建统一CMDB数据源
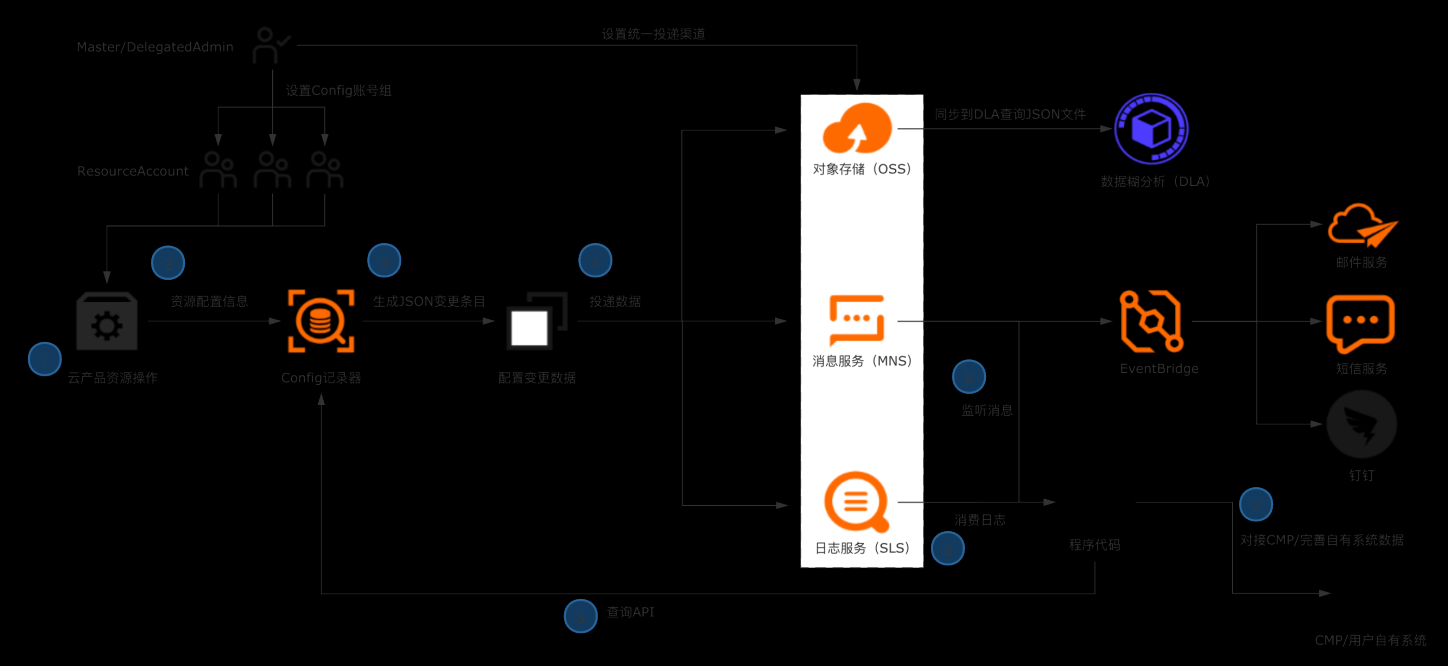
典型场景 l 企业/ISV构建多云CMDB平台,对接数十款产品的API,拉取、清洗、格式化、存储配置数据是复杂且高成本的工作。 l 企业日常的资源管理,需依赖资源配置历史、资源关系数据进行故障溯源和影响评估。 解决方案 l 企业管理账号设置Config配置数据投递,将所有账号的资源配置快照和历史归集到统一地址留存。 l 使用OSS做长期归档,使用SLS做实时分析和监听。获取全量资源数据并及时感知云上资源的变更。 l 将数据集成到自有CMDB平台 客户价值 l 基于配置审计简单便捷的持续收集云上资源配置数据,在自建CMDB过程中节省大量人力和时间成本。 l 跨账号统一收集数据,实现中心化的资源配置管理。 l 实现资源配置数据的持续收集和监听,及时感知云上资源的增删改,洞察异常变更。
资源管理平台(CMDB)最重 要的是构建完整可靠的底层数据,需要获取各 个云平台的所有资源配置数据,对数据进行持 续的下载、数据格式抽象统一、数据清洗、资 源关系解析和长期留存等处理,用可靠的数据 支持基于资源数据构建的运维管理流程和 Devops 程序。当使用的云平台比较多、使用 云产品比较多样、云上部署规模越来越...
基于Flink+ClickHouse构建实时游戏数据分析
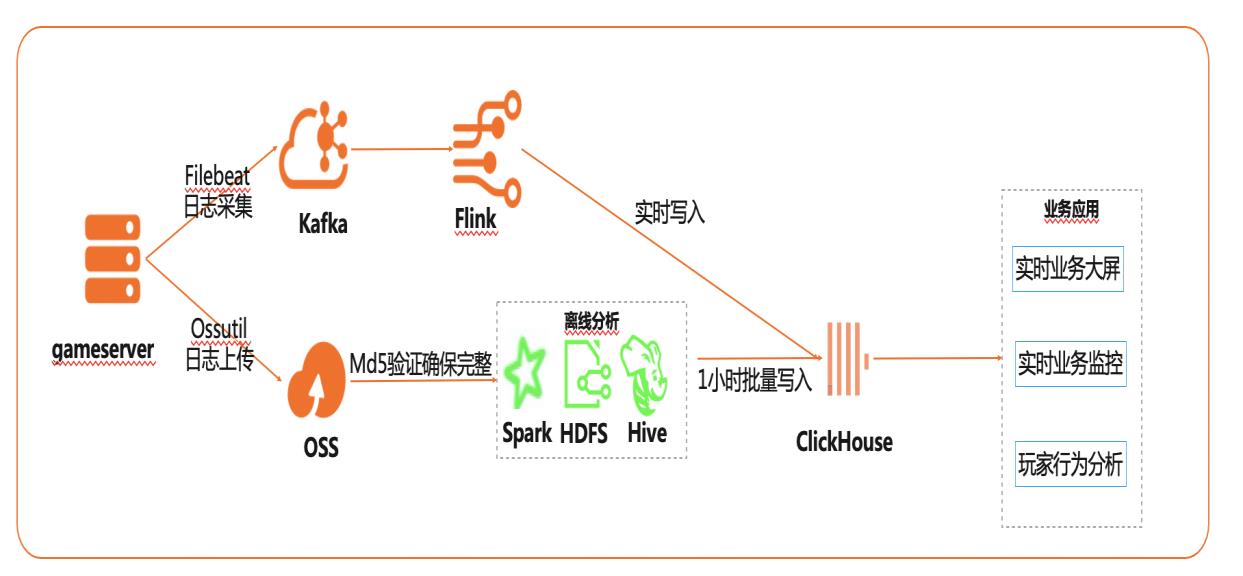
在互联网、游戏行业中,常常需要对用户行为日志进行分析,通过数据挖掘,来更好地支持业务运营,比如用户轨迹,热力图,登录行为分析,实时业务大屏等。当业务数据量达到千亿规模时,常常导致分析不实时,平均响应时间长达10分钟,影响业务的正常运营和发展。 本实践介绍如何快速收集海量用户行为数据,实现秒级响应的实时用户行为分析,并通过实时流计算Flink/Blink、云数据库ClickHouse等技术进行深入挖掘和分析,得到用户特征和画像,实现个性化系统推荐服务。 通过云数据库ClickHouse替换原有Presto数仓,对比开源Presto性能提升20倍。 利用云数据库ClickHouse极致分析性能,千亿级数据分析从10分钟缩短到30秒。 云数据库ClickHouse批量写入效率高,支持业务高峰每小时230亿的用户数据写入。 云数据库ClickHouse开箱即用,免运维,全球多Region部署,快速支持新游戏开服。 Flink+ClickHouse+QuickBI
本实践介绍如何快速收集海量用户行为数 据,实现秒级响应的实时用户行为分析,并 通过实时流计算、云数据库 ClickHouse等 技术进行深入挖掘和分析,得到用户特征和 画像,实现个性化系统推荐服务。产品列表 最佳实践频道 阿里云最佳实践分享群 专有网络 VPC 弹性公网 IP EIP 云服务器 ECS 消息队列 Kafka版 云数据库 ...
基于DataWorks的大数据一站式开发及数据治理

概述 基于Dataworks做大数据一站式开发,包含数据实时采集到kafka通过实时计算对数据进行ETL写入HDFS,使用Hive进行数据分析。通过Dataworks进行数据治理,数据地图查看数据信息和血缘关系,数据质量监控异常和报警。 适用场景 日志采集、处理及分析 日志使用Flink实时写入HDFS 日志数据实时ETL 日志HIVE分析 基于dataworks一站式开发 数据治理 方案优势 大数据一站式开发,完善的数据治理能力。 性能优越:高吞吐,高扩展性。 安全稳定:Exactly-Once,故障自动恢复,资源隔离。 简单易用:SQL语言,在线开发,全面支持UDX。 功能强大:支持SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据源计算等Data Lake相关功能 ,以及各种流式及静态数据源关联查询。
功能强大:支持 SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据 源计算等 Data Lake相关功能,以及各种流式及静态数据源关联查询。安全:原生的多租户系统,以项目进行隔离,所有计算任务在安全沙箱中运行。文档版本:20201020 2 基于 Dataworks的大数据一站式开发及数据治理 前置条件 前置条件 在进行本文操作...
数据库和应用迁移 ADAM
数据库和应用迁移 Advanced Database & Application Migration(以下简称 ADAM)是一款把数据库和应用迁移到阿里云(公共云或专有云)的产品,支持 Oracle、Teradata、Db2 的异构迁移上云。ADAM 全面评估上云可行性、成本和云存储选型,内置实施协助、数据迁移、应用迁移等工具,确保可靠、快速、低成本上云。
可定制所需步骤(结构迁移、全量迁移、增量同步、数据校验),可添加数据清洗逻辑,支持源和目标的映射关系.数据迁移定制.支持数据的清洗、加工。支持在数据迁移流程里面添加代码脚本,进行数据的过滤、清洗、加工等逻辑,比如某一 Blob 字段同步到 OSS 存储.支持数据的清洗.结构迁移与订正.提供应用迁移开发环境,自动发现...
来自:
云产品
AnalyticDB MySQL湖仓版的用户运营分析实践
本方案只需一个湖仓版实例就能完成“数据入湖+作业开发+在线分析”的一站式用户运营数据分析,提供更高效的数据处理方案与更低的数据存储成本。
过去的方案中,为了不影响在线分析的性能和稳定性,通常用两个实例,一个负责数据清洗,一个负责在线分析,但这种方案存在数据时效性差、一致性差、数据冗余的问题。本方案只需一个湖仓版实例就能完成“数据入湖+作业开发+在线分析”的一站式用户运营数据分析,提供更高效的数据处理方案与更低的数据存储成本。方案预估:...
来自:
解决方案
云存储解决方案
云存储解决方案面向大数据存储、多媒体存储(视频存储)、视频监控、基因生命科学、数据迁移、自动驾驶、在线教育、混合云存储、数据迁移、数据容灾备份等多个行业用户的多元化场景,提供更安全稳定、更优化、无缝上云的智能数据存储服务,为企业上云、实现数字化转型奠定数据基础。
为自动驾驶业务提供从数据采集上云、数据清洗、分发标注、训练到推理的整体云上存储解决方案.存储效率低:车辆采集数据存储困难与上传到中心存储效率低.数据孤岛现象严重:数据分散在多个存储系统,数据孤岛现象严重.存储系统 IO 存在瓶颈:AI、HPC 需求高性能,存储系统 IO 存在瓶颈.定位问题难度大:容器在多个场景应用,...
来自:
解决方案
Flink+Hologres搭建实时数仓
Flink+Hologres搭建实时数仓解决方案将Hologres与Flink深度集成,提供一体化的实时数仓联合解决方案,实现了数仓分层之间实时数据的高效流动,解决实时数仓分层问题。
过去的方案中,为了不影响在线分析的性能和稳定性,通常用两个实例,一个负责数据清洗,一个负责在线分析,但这种方案存在数据时效性差、一致性差、数据冗余的问题。本方案只需一个湖仓版实例就能完成“数据入湖+作业开发+在线分析”的一站式用户运营数据分析,提供更高效的数据处理方案与更低的数据存储成本。查看详情高...
来自:
解决方案
云数据库ClickHouse
云数据库ClickHouse 是阿里云提供的分布式实时分析型列式数据库服务。具有高性能、开箱即用、企业特性支持。广泛应用于流量分析、广告营销分析、行为分析、人群划分、客户画像、敏捷BI、数据集市、网络监控、分布式服务和链路监控等业务场景。
基于历史大数据计算,实时用户行为数据清洗计算。基于用户的历史标签和实时标签数据进行用户圈选营销,提高客户召回率和DAU.相比较传统日志分析方案,聚合分析性能提升5-10倍,亿级规模大部分查询毫秒级完成.对比传统ES日志写入,可以避免大规模写入OOM问题,写入速度达到50~200MB/s.高效稳定写入.消息队列Kafka版.推荐搭配...
来自:
云产品
云原生大数据计算服务MaxCompute
阿里云云原生大数据计算服务MaxCompute是面向分析的企业级云数仓,作为一体化大数据智能计算平台ODPS的大规模批量计算引擎,MaxCompute以 Serverless 架构提供快速、全托管的在线数据仓库服务,使您经济高效的分析处理海量数据,进行敏捷的业务洞察。
第二阶段通过内部产品打通在DataWorks进行同步和数据清洗.DataWorks进行ETL和OLAP的数据通过Quick BI产出报表.推荐搭配使用.某天气信息查询软件客户将日志分析业务从云下Hadoop集群迁移到阿里云MaxCompute后,开发效率提升超过5倍,存储和计算费用节省了70%,更高效的赋能其个性化运营策略.日志数据全部通过SQL进行分析,...
来自:
云产品
智能商业分析 Quick BI
瓴羊智能商业分析 Quick BI 是阿里云用户臻选的数据可视化工具,大幅提升数据分析和报表开发效率,一站式满足企业各种场景的数据分析和决策的诉求。
Quick BI 功能,选择适合您的版本入门与试用快速上手01连接数据源1创建数据源2选择数据库,添加白名单02数据建模1创建数据集2形成数据清洗模型03数据可视化分析1创建仪表板2选择图表组件,拖拽维度或度量,并在样式中进行渲染04发布分享1发布仪表板2将已完成的仪表板保存发布,并通过链接进行分享免费试用快速使用 Quick BI...
来自:
云产品
高价值用户挖掘及触达
使用人工智能平台PAI的强大算法能力,通过对用户数据的计算和预测,辅助客户对人群营销决策的判断,在用户召回,流失预测,高价值用户寻找等多个运营场景。
方案介绍高价值用户挖掘及触达本方案架构包含数据支撑、智能用户增长、运营管理与触达三个核心模块,可将业务相关数据存储在阿里云OSS中,并结合数据开发治理平台DataWorks进行数据清洗,生成符合运营要求的训练数据、人群数据等;阿里云PAI为您提供的智能用户增长插件,可智能圈选待运营人群、生成运行策略,并联合阿里云...
来自:
解决方案
基于函数计算FC实现阿里云Kafka消息轻量级ETL处理
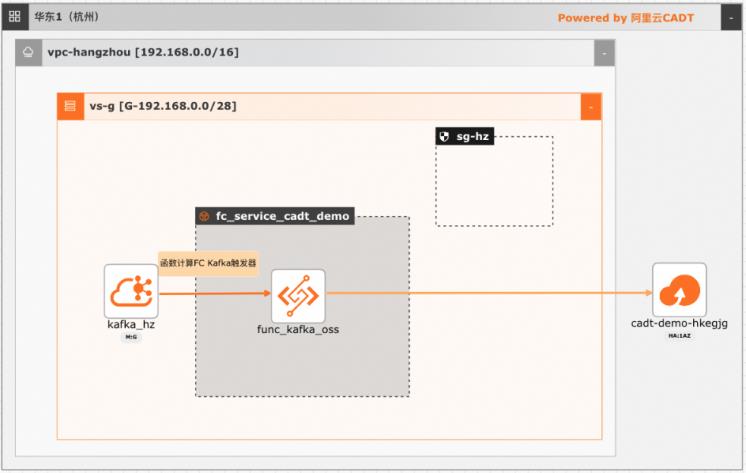
在大数据ETL场景,Kafka是数据的流转中心,Kafka中的数据一般是原始数据,可能存在多种数据混杂的情况,需要进一步做数据清洗后才能进行下一步的处理或者保存。利用函数计算FC,可以快速高效的搭建数据处理链路,用户只需要关注数据处理的逻辑,数据的触发,弹性伸缩,运维监控等阿里云函数计算都已经做了集成,函数计算FC也支持多种下游,OSS/数据库/消息队列/ES等都可以自定义的对接
应用场景 在大数据 ETL场景,Kafka是数据的流转中心,Kafka 中的数据一般是原始数据,可能存在多种 数据混杂的情况,需要进一步做数据清洗后才能 进行下一步的处理或者保存。利用函数计算 FC,可以快速高效的搭建数据处理链路,用户只需要 关注数据处理的逻辑,数据的触发,弹性伸缩,运维监控等阿里云函数计算都已经做了...
大模型RAG对话系统部署
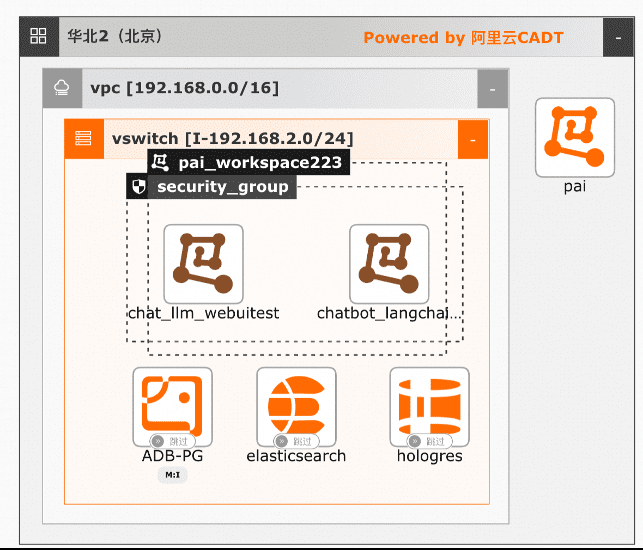
大模型RAG对话系统最佳实践,旨在指引AI开发人员如何有效地结合LLM大语言模型的推理能力和外部知识库检索增强技术,从而显著提升对话系统的性能,使其能更加灵活地返回用户查询的内容。适用于问答、摘要生成和其他依赖外部知识的自然语言处理任务。通过该实践,您可以掌握构建一个大模型RAG对话系统的完整开发链路。
兼容 Greenplum开源数 据仓库,MPP全并行架构,广泛兼容 PostgreSQL/Oracle的语法生态,新一代向 量引擎性能超越传统数据库引擎 10倍以上,分布式 SQL优化器实现复杂查询语 句免调优。实现了对海量数据的即席查询分析、ETL 处理及可视化探索,是各行 业有竞争力的云上数据仓库解决方案。Hologres是一站式实时数据仓库引擎,...
基于弹性计算的AI推理
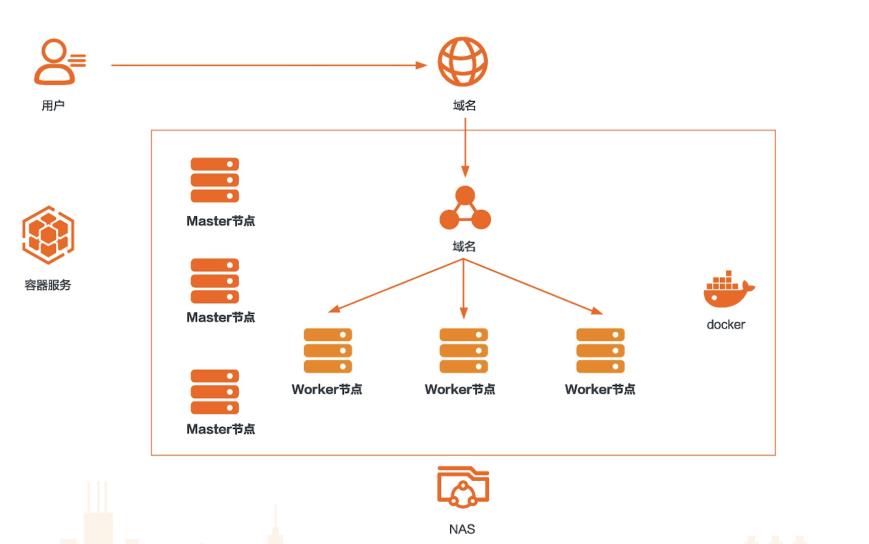
场景描述 本方案适用于使用GPU进行AI在线推理的场 景。在推理之前,模型已经训练完成。例如,刷脸 支付中,我们在刷脸的时候,就是推理的一个过 程。再比如图像分类,目标检测,语音识别,语 义分析等返回结果的过程。 解决问题 使用GPU云服务器搭建推理环境 使用容器服务Kubernetes版构建推理 环境 使用NAS存储模型数据 使用飞天AI加速推理工具加速推理 产品列表 GPU云服务器 容器服务Kubernetes版 NAS共享存储
部署用户模型.61 发布日期:20220320 IV 企业上云实践 基于弹性计算的 AI推理最佳实践|演示环境说明 最佳实践概述 AI数据处理流程 场景描述 通常 AI数据处理分为,数据采集,数据清洗,数据标注,模型训练,模型部署,推理等场景。本方案 适用于 AI推理场景,在推理之前,模型已经训练完成。例如,刷脸支付中,我们在刷脸的...
实时监控应用关键业务异常与告警
使用日志服务(SLS)基于收集的业务日志对业务实现监控与告警,能够帮助您了解应用的运行趋势,及时发现业务异常状态,采用具体措施以保证系统稳定性。
应用场景数据统一采集与管道化通过覆盖服务器与应用、云产品、移动端、物联网、开源软件、标准协议等采集来源,并覆盖日志、指标、链路等数据类型,成为企业的数据总线,满足数据统一采集、加工清洗、实时消费与分发等需求。IT系统运维监控统一采集、监控服务器运行日志、应用日志、数据库日志、网络日志等运维日志,帮助...
来自:
解决方案
- 产品推荐
- 这些文档可能帮助您