- 相关产品:
- 企业级云灾备解决方案 智能媒资管理解决方案 智能语音点餐机解决方案
EMR集群安全认证和授权管理
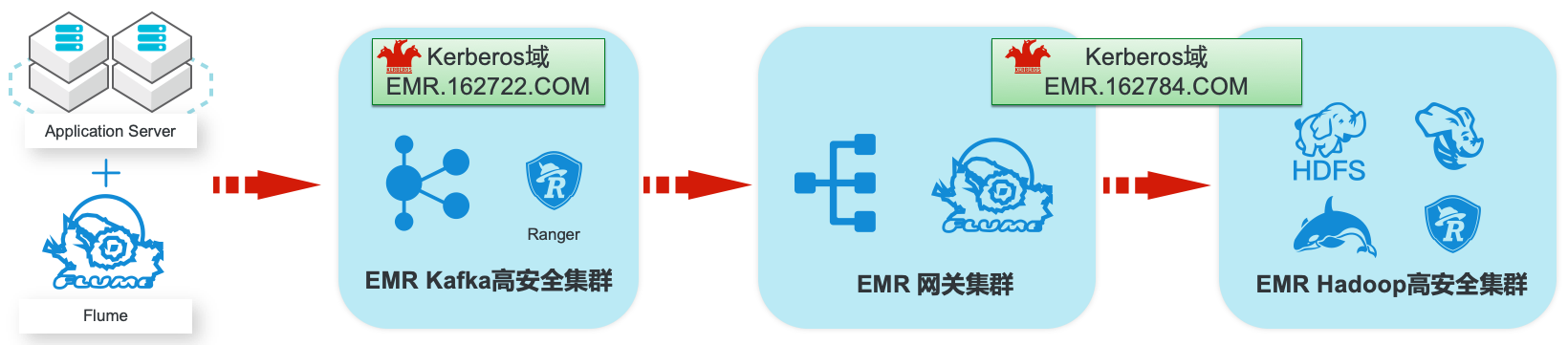
场景描述 阿里云EMR服务Kafka和Hadoop安全集群使 用Kerberos进行用户安全认证,通过Apache Ranger服务进行访问授权管理。本最佳实践中以 Apache Web服务器日志为例,演示基于Kafka 和Hadoop的生态组件构建日志大数据仓库,并 介绍在整个数据流程中,如何通过Kerberos和 Ranger进行认证和授权的相关配置。 解决问题 1.创建基于Kerberos的EMR Kafka和 Hadoop集群。 2.EMR服务的Kafka和Hadoop集群中 Kerberos相关配置和使用方法。 3.Ranger中添加Kafka、HDFS、Hive和 Hbase服务和访问策略。 4.Flume中和Kafka、HDFS相关的安全配 置。 产品列表:E-MapReduce、专有网络VPC、云服务器ECS、云数据库RDS版
Flume会使用默认值,详细内容请查看官方文档:http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#kafka-source http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#hdfs-sink http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#memory- channel Kafka Source...
自建Hadoop迁移到阿里云EMR
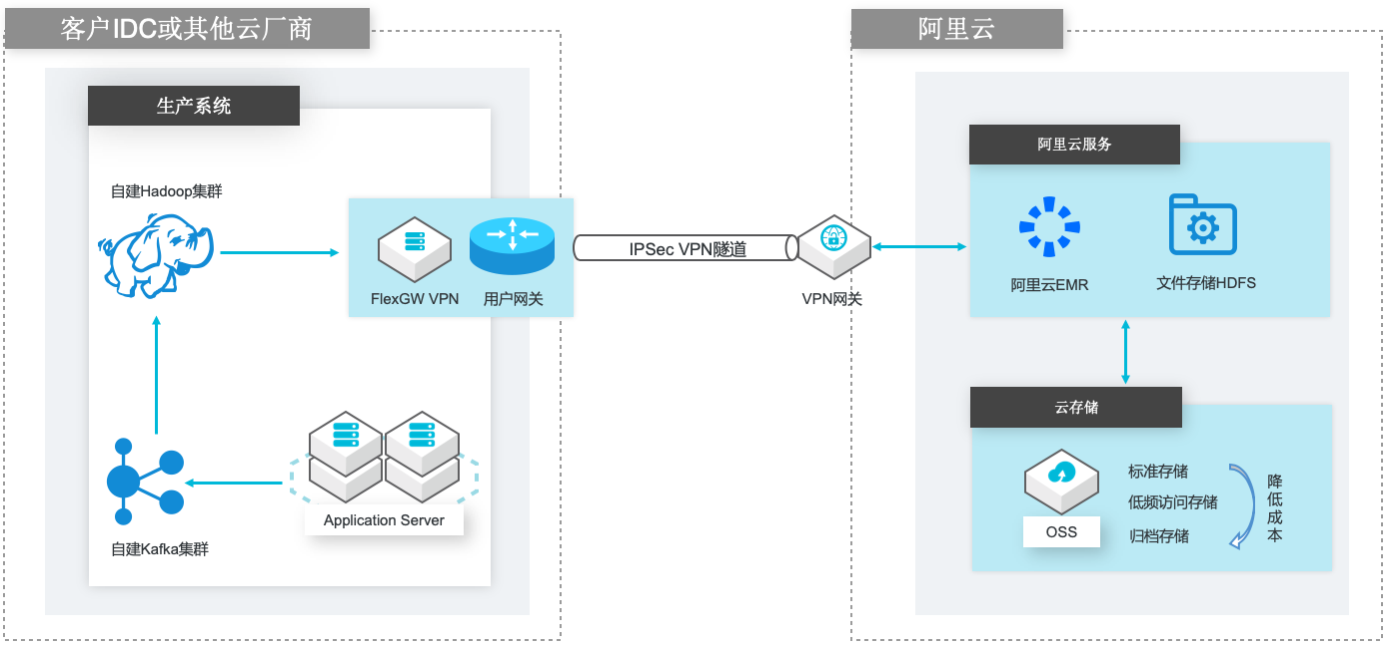
场景描述 场景1:自建Hadoop集群数据(HDFS)迁移到 阿里云EMR集群的HDFS文件系统; 场景2:自建Hadoop集群数据(HDFS)迁移到 计算存储分离架构的阿里云EMR集群,以OSS 和JindoFS作为EMR集群的后端存储。 解决的问题 客户自建Hadoop迁移到阿里云EMR集群的 技术方案; 基于IPSecVPN隧道构建安全和低成本数据 传输链路 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
cd~wget https://mirrors.tuna.tsinghua.edu.cn/apache/flume/1.8.0/apache-flume-1.8.0-bin.tar.gz tar zxf apache-flume-1.8.0-bin.tar.gz文档版本:20210714 21 自建Hadoop数据迁移到阿里云 EMR 自建 Hadoop集群环境搭建 2.下载 flume-env.sh配置文件。cd~/apache-flume-1.8.0-bin/conf wget ...
基于DataWorks的大数据一站式开发及数据治理

概述 基于Dataworks做大数据一站式开发,包含数据实时采集到kafka通过实时计算对数据进行ETL写入HDFS,使用Hive进行数据分析。通过Dataworks进行数据治理,数据地图查看数据信息和血缘关系,数据质量监控异常和报警。 适用场景 日志采集、处理及分析 日志使用Flink实时写入HDFS 日志数据实时ETL 日志HIVE分析 基于dataworks一站式开发 数据治理 方案优势 大数据一站式开发,完善的数据治理能力。 性能优越:高吞吐,高扩展性。 安全稳定:Exactly-Once,故障自动恢复,资源隔离。 简单易用:SQL语言,在线开发,全面支持UDX。 功能强大:支持SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据源计算等Data Lake相关功能 ,以及各种流式及静态数据源关联查询。
可以到官网下载,这里直接提供下载命令(如果不能下载请手动绑定 EIP再下载):cd/root/log wget http://mirrors.tuna.tsinghua.edu.cn/apache/flume/1.9.0/apache-flume-1.9.0- bin.tar.gz tar zxvf apache-flume-1.9.0-bin.tar.gz mv apache-flume-1.9.0-binflume 2.配置环境变量:文档版本:20201020 20 基于 Dataworks的...
自建Hadoop迁移MaxCompute
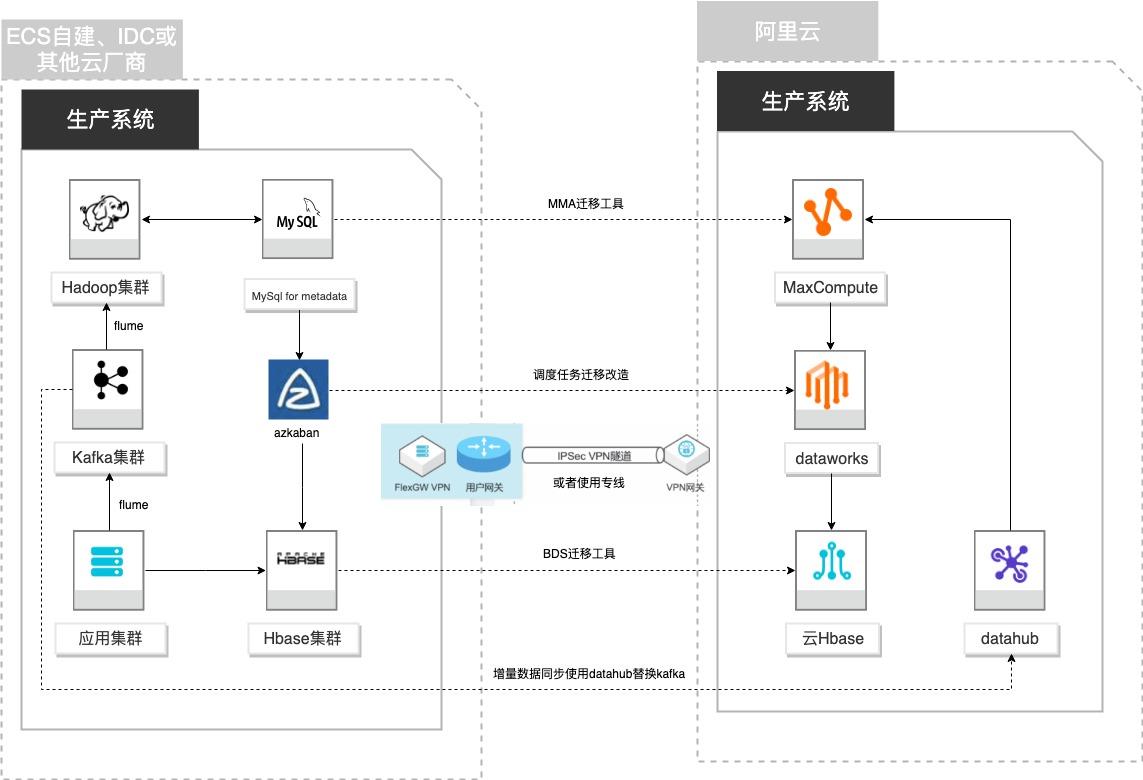
场景描述 客户基于ECS、IDC自建或在友商云平台自建了大数 据集群,为了降低企业大数据计算平台的成本,提高 大数据应用开发效率,更有效保障数据安全,把大数 据集群的数据、作业、调度任务以及业务数据库整体 迁移到MaxCompute和其他云产品。 解决的问题 自建Hadoop集群搬迁到MaxCompute 自建Hbase集群搬迁到云Hbase 自建Kafka或应用数据准实时同步到 MaxCompute 自建Azkaban任务迁移到Dataworks任务 产品列表 MaxCompute,Dataworks、云数据库Hbase版、Datahub、VPC,ECS。
Flume Flume是一种分布式,可靠且可用的服务,用于有效地收集,聚合和移动大量日 志数据。它具有基于流数据流的简单灵活的体系结构。它具有可调整的可靠性机 制以及许多故障转移和恢复机制,具有强大的功能和容错能力。它使用一个简单 的可扩展数据模型,允许在线分析应用程序。文档版本:20210723 IV 自建Hadoop迁移...
数据湖-在线学习场景数据分析

场景描述 本场景以在线教育中一个答题闯关类的应用为 例,使用WebServer来模拟演示这类日志数据 的分析处理。通过Nginx和Pythonflask搭建 WebServer,模拟应用中的关键页面,比如登 录、课程内容等,之后构造若干用户使用的模拟 日志数据,投递到数据湖进行分析后获取应用 PV、UV、课程内容访问排行、平均得分等等。 解决问题 基于数据湖(EMR+OSS)搭建大数据平台。 EMR和OSS使用和配置。 数据统一存储到OSS。 产品列表 E-MapReduce 对象存储OSS 云服务器ECS 访问控制RAM 专有网络VPC
步骤3 ssh 登 录 到 EMR Hadoop 的 master 节 点 修 改 flume 的 配 置 文 件/usr/lib/flume-current/conf/flume-k2hadoop.conf(配置文件可以在附件中下载):文档版本:20200331 48数据湖-在线学习场景数据分析 应用场景 启动flume,执行命令:flume-ng agent-conf/usr/lib/flume-current/conf/-name a1-conf-file/usr/...
金融专属大数据workshop

实践目标 学习搭建一个实时数据仓库,掌握数据采集、存储、计算、输出、展示等整个业务流程。 整个实时数据仓库系统全部基于阿里云产品进行架构搭建,用户可以掌握并学会运用各个服务组件及各个组件之间如何联动。 理解阿里云原生实时离线一体数仓解决方案架构以及掌握交付落地的实践使用方法。 前置知识要求 熟练掌握SQL语法 对大数据体系系统知识有一定的了解
步骤10登录到shell命名行后,在/root目录下,下载本文的实例代码:首先安装git工具:yuminstall-ygit gitclonehttps:/code.aliyun.com/best-practice/bigdata-fin.git,如图:文档版本:20210803(发布日期)24阿里云最佳实践金融大数据WorkShop 最佳实践项目实践 步骤11本步骤会安装:Java、Flume、Flume-datahub等,并...
来自:
最佳实践
相关产品:块存储,云服务器ECS,云数据库RDS MySQL 版,对象存储 OSS,弹性公网IP,数据传输,DataWorks,大数据计算服务 MaxCompute,DataV数据可视化,实时计算,数据总线,Quick BI,Hologres
数据总线Datahub
数据总线(DataHub)服务是阿里云提供的流式数据(Streaming Data)服务,它提供流式数据的发布(Publish)和订阅(Subscribe)的功能,拥有高吞吐量、高稳定性、低成本等特点,与阿里云大数据生态系统完美打通,让您可以轻松构建基于流式数据的分析和应用。
提供多种SDK、API和Flume、Logstash等第三方插件,让您高效便捷的把数据接入到数据总线.提供DataConnector模块,稍作配置即可把接入的数据实时同步到下游MaxCompute、OSS、TableStore等存储分析系统,极大减轻了数据链路的工作量.灵活的缓存时间,下游可重复消费,自动多备份,保障数据高可靠性.既有适合人交互的Web控制台...
来自:
云产品
自建Hive数仓迁移到阿里云EMR
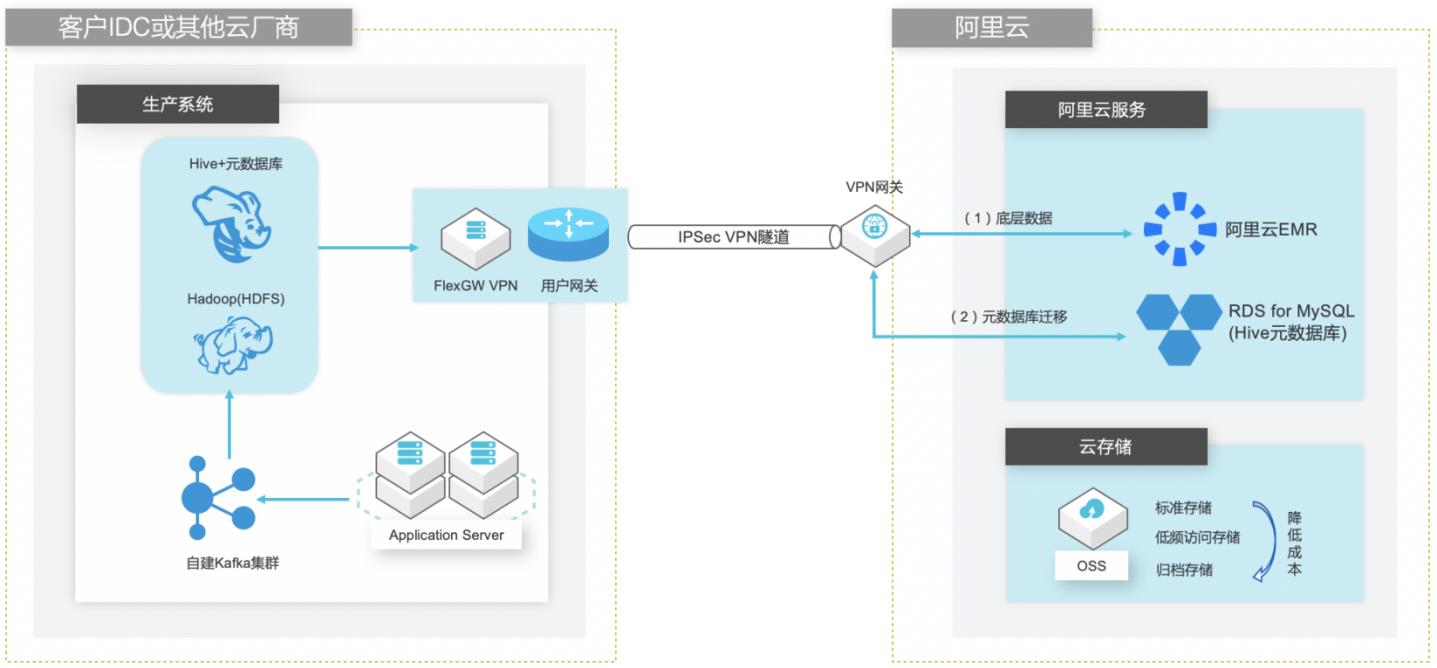
场景描述 客户在IDC或者公有云环境自建Hadoop集群构 建数据仓库和分析系统,购买阿里云EMR集群之 后,涉及到将数据仓库和Hive元数据的数据库迁 移上云。目前主流Hive数据仓库迁移场景为1.x 版本迁移到阿里云EMR(Hive2.x版本),涉及到 数据订正更新步骤。 解决的问题 Hive数据仓库的数据迁移方案 Hive元数据库的迁移方案 Hive跨版本迁移后的数据订正 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
hadoop fs-ls-h/usr/dfs/data/flume/kafka/20191207|wc-l 文档版本:20210721 17 自建Hive数据仓库跨版本迁移到阿里云 EMR 基础环境搭建 hadoop fs-ls-h/usr/dfs/data/flume/kafka/20191207 步骤5 以加载 20191207目录下日志文件为例,执行以下命令。1.创建 2019年 12月 07日对应的分区:hive 在 hive命令行执行以下 HQL...
云消息队列 Kafka 版
云消息队列 Kafka 版是阿里云基于Apache Kafka构建的大数据消息中间件,广泛用于日志收集和分析、数据处理等场景。可提供全托管服务,用户无需部署运维,更专业、更可靠、更安全。
许多公司,比如淘宝、天猫平台每天都会产生大量的日志(一般为流式数据,如搜索引擎pv,查询等),比起以日志为中心的系统比如 Scribe 或者 Flume 来说,Kafka 提供同样高效的性能,实现更强的数据持久化以及更低的端到端响应时间,Kafka 的特性决定它非常适合作为\\.网站所有用户产生的行为信息极为庞大,需要非常高的吞吐...
来自:
云产品
大数据workshop

大数据workshop
技术选型 阿里云框架 开源框架 ➢ 数据采集传输 DataHub、DTS Flume、Kafka、Canal、MaxWell ➢ 数据存储 RDS、MaxCompute MySQL、Hadoop、HBase ➢ 数据计算 实时计算 Flink版 Spark、Flink ➢ 数据可视化 DataV、QuickBI Tableau、Echarts、Kibana 2.2.4.系统架构设计 下图为所设计的系统架构设计,主要包括数据源(两类...
来自:
最佳实践
相关产品:块存储,云服务器ECS,云数据库RDS MySQL 版,对象存储 OSS,弹性公网IP,数据传输,DataWorks,大数据计算服务 MaxCompute,DataV数据可视化,实时计算,数据总线,Quick BI,Hologres
SLS多云日志采集、处理及分析
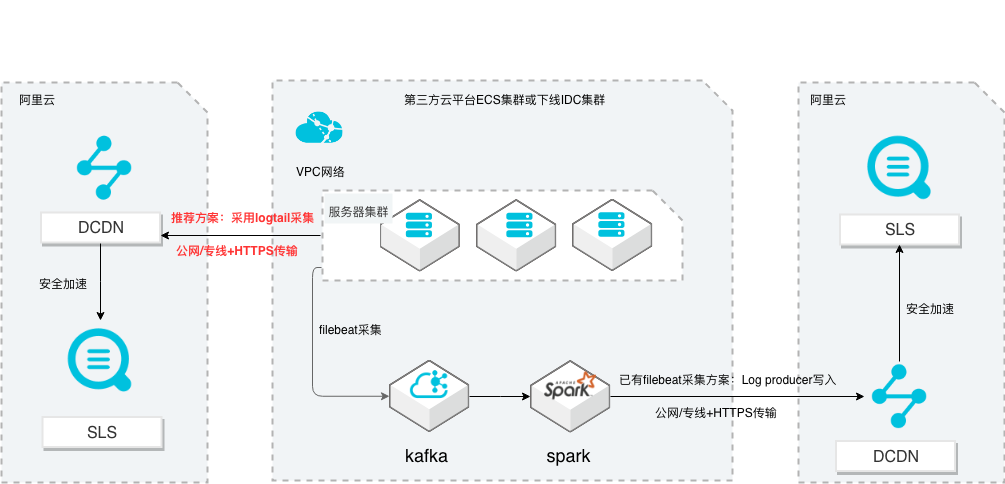
场景描述 从第三方云平台或线下IDC服务器上采集 日志写入到阿里云日志服务,通过日志服务 进行数据分析,帮助提升运维、运营效率, 建立DT 时代海量日志处理能力。 针对未使用其他日志采集服务的用户,推荐 在他云或线下服务器安装logtail采集并使用 Https安全传输;针对已使用其他日志采集 工具并且已有日志服务需要继续服务的情 况,可以通过Log producer SDK写入日志 服务。 解决问题 1.第三方云平台或线下IDC客户需要使用 阿里云日志服务生态的用户。 2.第三方云平台或线下IDC服务器已有完 整日志采集、处理及分析的用户。 产品列表 E-MapReduce 专有网络VPC 云服务器ECS 日志服务LOG DCDN
日志采集的工具有很多种,如 fluentd,flume,logstash,betas等等。首 先要知道为什么要使用 filebeat呢?因为 logstash是 jvm跑的,资源消耗比较大,启 动一个 logstash就需要消耗 500M左右的内存,而 filebeat只需要 10来 M内存资源。工作原理:Filebeat由两个主要组件组成:prospector 和 harvester。这些组件一起工作来...
- 产品推荐
- 这些文档可能帮助您