金融专属大数据workshop

实践目标 学习搭建一个实时数据仓库,掌握数据采集、存储、计算、输出、展示等整个业务流程。 整个实时数据仓库系统全部基于阿里云产品进行架构搭建,用户可以掌握并学会运用各个服务组件及各个组件之间如何联动。 理解阿里云原生实时离线一体数仓解决方案架构以及掌握交付落地的实践使用方法。 前置知识要求 熟练掌握SQL语法 对大数据体系系统知识有一定的了解
password:阿里云账号的AccessKeySecret,此处方便直接使用主账号的 Secret ᅳ endpoint:Hologres的VPC网络地址,可以登录Hologres控制台,进入目 标 实例的详情页,在实例配置中获取endpoint,endpoint需要包含IP和端口,格 式为ip:port 文档版本:20210803(发布日期)47阿里云最佳实践金融大数据WorkShop 最佳实践项目...
来自:
最佳实践
相关产品:块存储,云服务器ECS,云数据库RDS MySQL 版,对象存储 OSS,弹性公网IP,数据传输,DataWorks,大数据计算服务 MaxCompute,DataV数据可视化,实时计算,数据总线,Quick BI,Hologres
大数据workshop

大数据workshop
Hologres用于接收数据的表名称-username:阿里云账号的 Access Key ID,此处方便直接使用主账号的 AK-password:阿里云账号的 Access Key Secret,此处方便直接使用主账号的 Secret-endpoint:Hologres的 VPC网络地址,可以登录 Hologres控制台,进入目 标实例的详情页,在实例配置中获取 endpoint,endpoint需要包含 IP和端口...
来自:
最佳实践
相关产品:块存储,云服务器ECS,云数据库RDS MySQL 版,对象存储 OSS,弹性公网IP,数据传输,DataWorks,大数据计算服务 MaxCompute,DataV数据可视化,实时计算,数据总线,Quick BI,Hologres
SLS多云日志采集、处理及分析
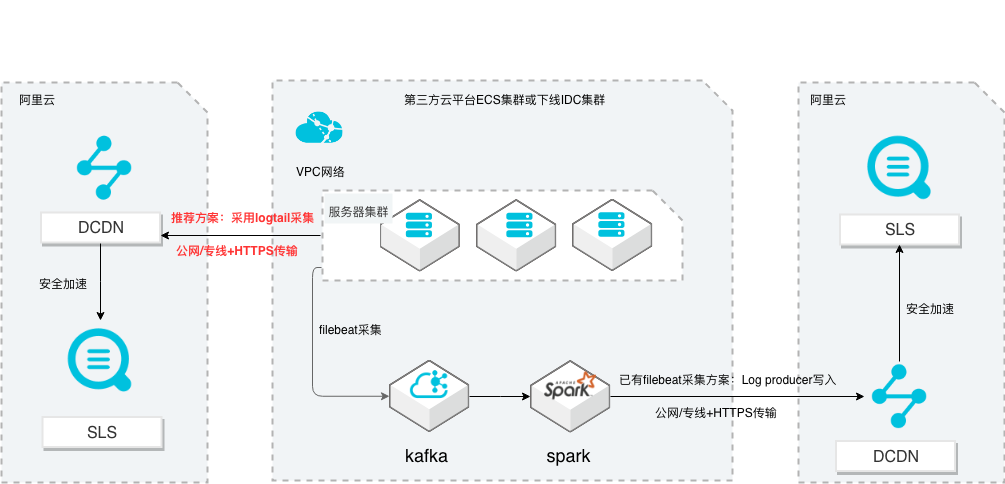
场景描述 从第三方云平台或线下IDC服务器上采集 日志写入到阿里云日志服务,通过日志服务 进行数据分析,帮助提升运维、运营效率, 建立DT 时代海量日志处理能力。 针对未使用其他日志采集服务的用户,推荐 在他云或线下服务器安装logtail采集并使用 Https安全传输;针对已使用其他日志采集 工具并且已有日志服务需要继续服务的情 况,可以通过Log producer SDK写入日志 服务。 解决问题 1.第三方云平台或线下IDC客户需要使用 阿里云日志服务生态的用户。 2.第三方云平台或线下IDC服务器已有完 整日志采集、处理及分析的用户。 产品列表 E-MapReduce 专有网络VPC 云服务器ECS 日志服务LOG DCDN
文档版本:20211203 64 SLS多云日志采集、处理及分析 编写 Spark作业源码解读及问题排查 步骤5 使用如下命令执行 spark作业(accessKeyId,accessKeySecret从阿里云账号管理 中获取,endpoint,project,logStore 从日志服务中获取,kafkaHost,topic 从 kafka集群中获取 master节点私网 ip和 topic名称):spark-submit-...
基于函数计算FC实现企业级权限精准控制Kafka跨实例消息同步
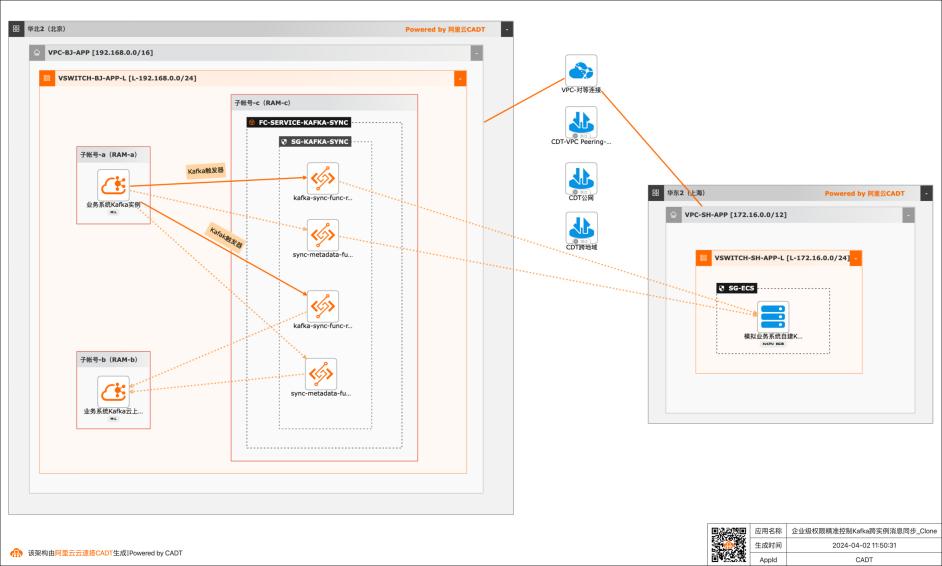
应用场景 在大数据场景,企业的Kafka实例可能存在多种情况,比如使用阿里云Kafka服务,可能是自建开源Kafka,或者是其他云上的云Kafka。不同的业务使用不同类型的Kafka实例,在这个前提下Kafka实例之间可能会需要消息同步的情况: 同帐号容灾场景:比如Kafka实例都是阿里云Kafka,但是Kafka实例会有主备之分,需要将主Kafka实例的消息实时同步到备Kafka。 跨帐号或异地容灾:这类场景比如主Kafka是阿里云Kafka,备Kafka是IDC开源自建Kafka,或者是其他云上的Kafka。 不同业务之间消息同步:因为现在的业务通常不会是信息孤岛,都需要消息互通,所以可能是A业务的Kafka实例消息需要同步到B业务的Kafka实例,并且这两个Kafka实例归属不同的RAM角色,有自己独自的权限控制。 解决问题 解决使用开源组件做消息同步的高成本问题。 解决使用开源组件做消息同步的并发性能、稳定性问题。 解决使用开源组件做消息同步的可靠性问题(重试机制,容错机制,死信队列等)。 大幅提升构建消息同步架构的效率,降低构建复杂度问题。
target_kafka_endpoint:ECS上自建Kafka的连接地址,输入:9092(ECS内网IP的获取方式参见4.2节)文档版本:20240330 45基于函数计算FC实现企业级权限精准控制Kafka跨实例消息同步 场景验证 target_kafka_id:标识目标Kafka的ID,这里用idc_kafka。业务系统Kafka实例的实例ID可以在CADT控制台点击业务系统Kafka实例图表...
云上日志集中审计
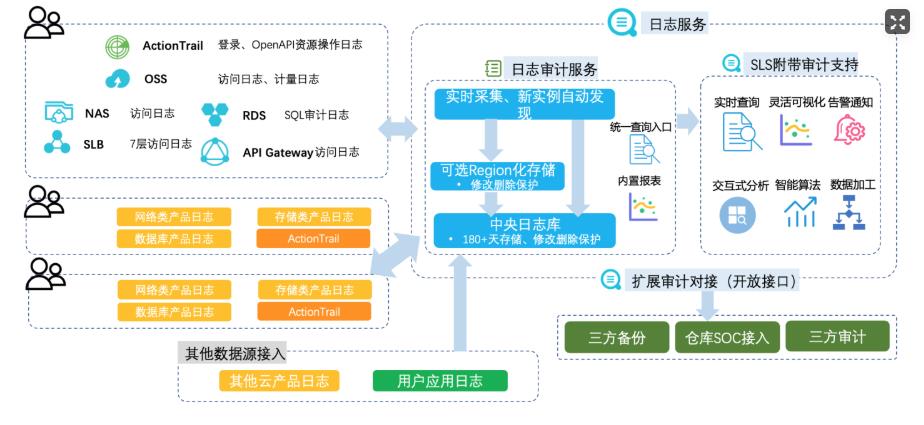
场景描述 云上的各类云产品和客户部署的业务系统会产生各类 日志,企业合规及安全运营等都需要在一个地方能 集中的查看和分析日志;目前各云产品日志大部分 都进了sls,但都是产品独立的project,不方便集中 审计;客户的业务系统日志各种形态都有;多云和混 合云的场景,日志也需要能集中审计。 解决问题 1.所有日志集中到SLS一个中心project下。 2.满足等保合规和内部合规需求。 3.满足运维和安全运营需求。 产品列表 日志服务SLS 专有网络VPC 弹性公网IPEIP 负载均衡SLB 云服务器ECS 云数据库RDS 云防火墙CFW
aliyunlog log get_dashboard-project=cloudfirewall-project-$ALICLOUD_ACCOUNT_ID-cn-hangzhou --entity=cloudfirewall-logstore_cfw_report_center_en --region-endpoint=cn- hangzhou.log.aliyuncs.com > cloudfirewall-logstore_cfw_report_center_en.json aliyunlog log get_dashboard --project=cloudfirewall-project-$...
基于弹性计算的AI推理
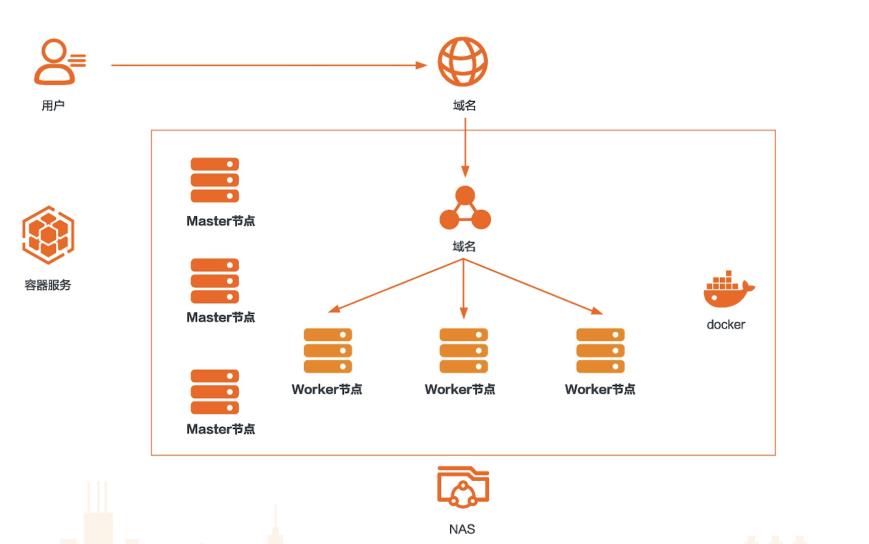
场景描述 本方案适用于使用GPU进行AI在线推理的场 景。在推理之前,模型已经训练完成。例如,刷脸 支付中,我们在刷脸的时候,就是推理的一个过 程。再比如图像分类,目标检测,语音识别,语 义分析等返回结果的过程。 解决问题 使用GPU云服务器搭建推理环境 使用容器服务Kubernetes版构建推理 环境 使用NAS存储模型数据 使用飞天AI加速推理工具加速推理 产品列表 GPU云服务器 容器服务Kubernetes版 NAS共享存储
根据 endpoint和 restful端口测试客户端.51 4.6.在 ECS环境部署推理 client.51 4.6.1.查看集群所有节点列表.51 4.6.2.获取 server的 cluterip.52 4.6.3.这里我们用 worker节点来演示.52 4.7.性能测试.54 4.8.飞天 AI加速推理工具使用说明.55 4.8.1.单独启动 perseus_inference容器镜像.55 4.8.2.启动 server端.56 4.8.3....
EHPC工业仿真
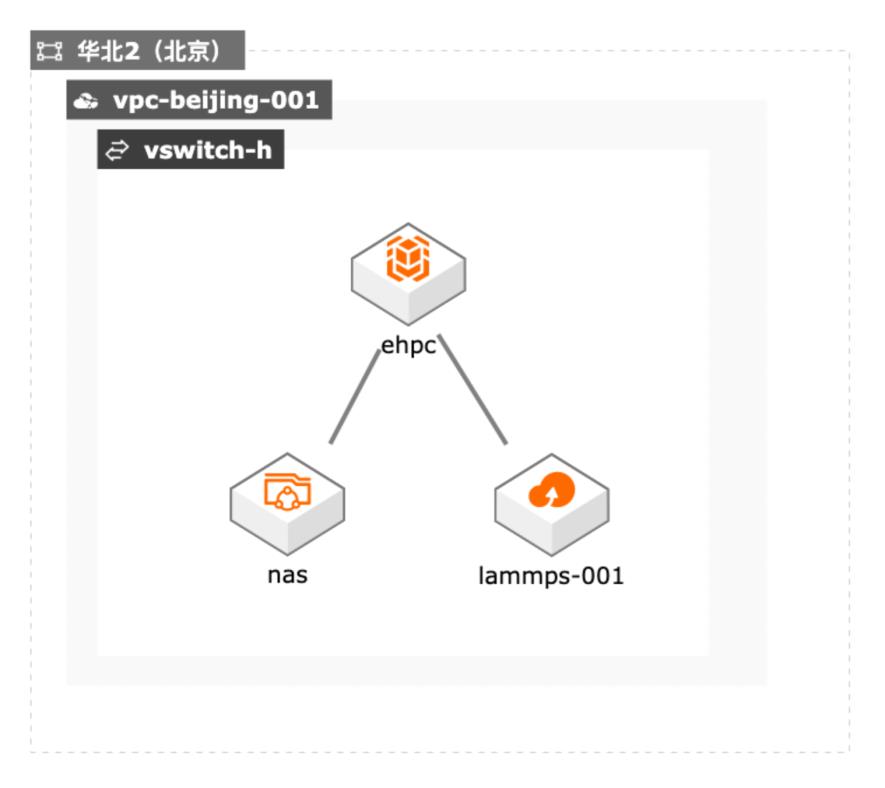
场景描述 本实践适用于使用弹性高性能计算EHPC+ 对象存储OSS运行仿真软件进行模型仿真 的场景中,这里运行的是LAMMPS这款开 源的仿真软件,数据通过OSS上传。 解决问题 1.使用EHPC运行工业仿真软件 2.使用OSS存储数据和代码 3.可视化计算结果 产品列表 弹性高性能计算E-HPC 对象存储OSS
请输入语言(CH/EN,默认为:CH,该配置项将在此次 config命令成功结束后生效):(点击 Enter)请输入 endpoint:oss-cn-beijing-internal.aliyuncs.com(输入 endpoint,在 ossbucket的页面获取内 网访问地址)请输入 accessKeyID:L*Q(输入 accessID)请输入 accessKeySecret:F*w(输入 accesskey)请输入 stsToken:...
Function Compute搭建前端CICD系统
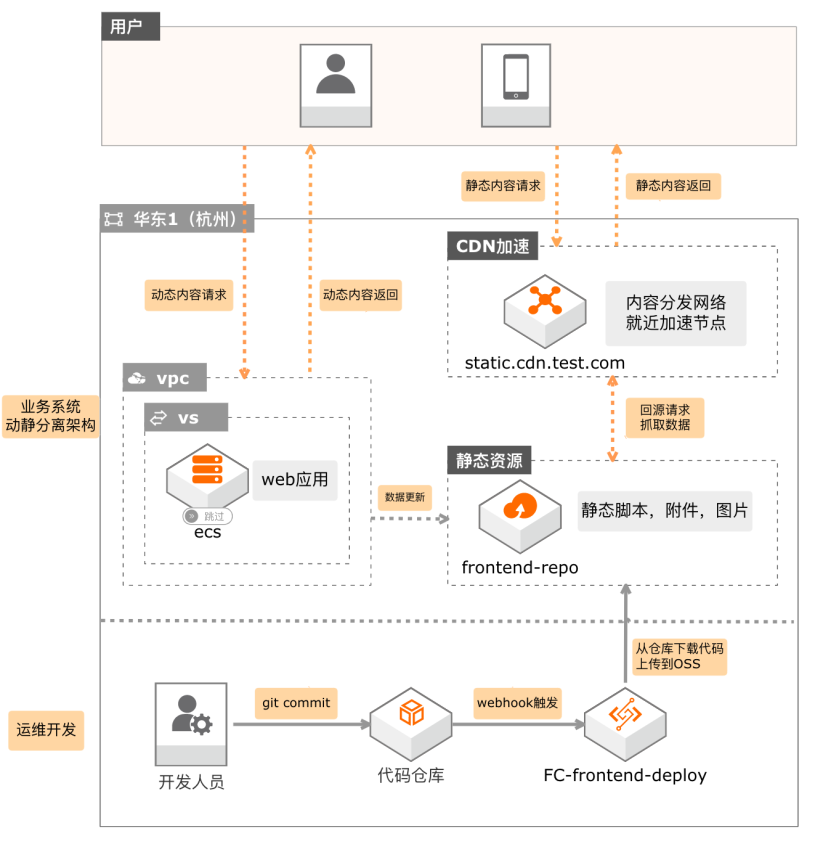
场景描述 传统动静不分离的产品架构,随着访问量在增 长,性能会成为瓶颈。在这种情况下,用户可以 通过利用OSS和CDN对网站进行架构优化, 做到网站文件的动静分离,提升用户访问体验, 实现成本可控。本方案使用函数计算监听前端代 码库提交的分支变更,上传分支文件至OSS,通 过CDN进行前端资源加速。 方案优势 1.面向serverless:无需购买服务器 2.免运维:无需部署配置Jenkins 3.提供日志查询、性能监控和报警等功能 4.一站式:事件驱动方式触发响应 5.费用极低:按需付费 产品列表 专有网络VPC 对象存储OSS 日志服务SLS 函数计算 CDN
' 11.12.13.#if you open the initializer feature,please implement the initializer function,as bel ow:14.#def initializer(context):15.#logger=logging.getLogger()16.#logger.info('initializing')17.18.def handler(environ,start_response):19.#配置OSS访问端点 20.endpoint='' 21.#配置bucket名称 22.bucketname=...
基于函数计算FC实现阿里云Kafka消息轻量级ETL处理
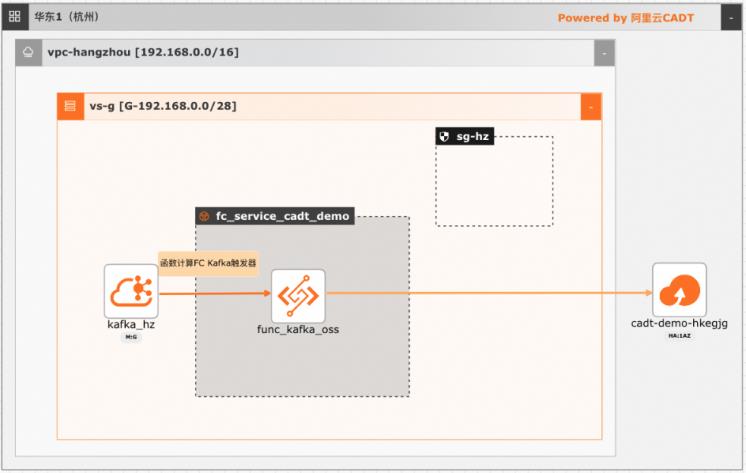
在大数据ETL场景,Kafka是数据的流转中心,Kafka中的数据一般是原始数据,可能存在多种数据混杂的情况,需要进一步做数据清洗后才能进行下一步的处理或者保存。利用函数计算FC,可以快速高效的搭建数据处理链路,用户只需要关注数据处理的逻辑,数据的触发,弹性伸缩,运维监控等阿里云函数计算都已经做了集成,函数计算FC也支持多种下游,OSS/数据库/消息队列/ES等都可以自定义的对接
Kafka消息轻量级 ETL处理 场景验证 creds.security_token)endpoint='https://oss-{}- internal.aliyuncs.com'.format(context.region)self.bucket=oss2.Bucket(auth,endpoint,oss_bucket)def persist(self,bucket_name,object):logger.info("Persist,bucket_name:{},object:{}".format(bucket_name,json.dumps(object)))...
跨云迁移单写双读过渡架构
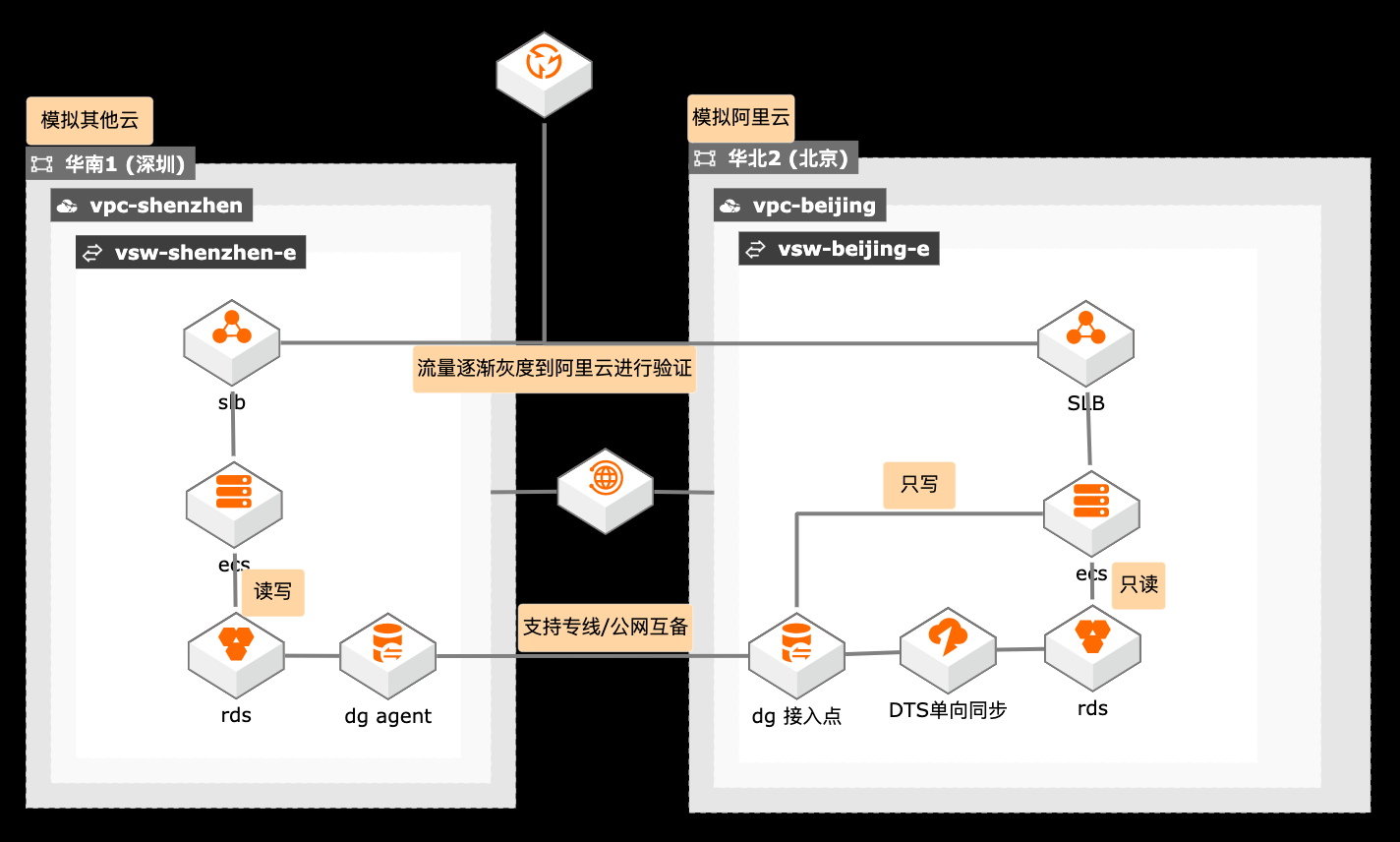
概述 在搬站场景下,涉及迁移跨度较长,在过渡阶段客户需要跨云访问,如何保障数据链路的高可用尤为关键,采用专线和公网双备的方案保障数据传输的高可用,也降低双专线的迁移成本。 适用场景 数据迁移链路的高可用 跨云迁移过渡期架构 读写分类架构设计 技术架构 本实践方案基于如下图所示的技术架构和主要流程编写操作步骤: 方案优势 在迁移时间持续较长的情况下,使用单写双读架构降低业务改造成本。 使用数据库网关做专线和公网互备。 流量逐渐灰度验证,保障迁移平滑过渡。 安全:原生的多租户系统,以项目进行隔离,所有计算任务在安全沙箱中运行。
跨云迁移单写双读过渡架构 最佳实践 业务架构 场景描述 解决的问题 在搬站场景下,涉及迁移跨度较长,在过渡阶段客户 数据迁移链路的高可用 需要跨云访问,如何保障数据链路的高可用尤为关 跨云迁移过渡期架构 ...nohup./dg_agent-reboot-endpoint internal-cn-beijing.dg.aliyuncs.com &> dg_agent.out &文档版本:20201209 41
通过ES兼容接口方式使用Kibana访问SLS数据
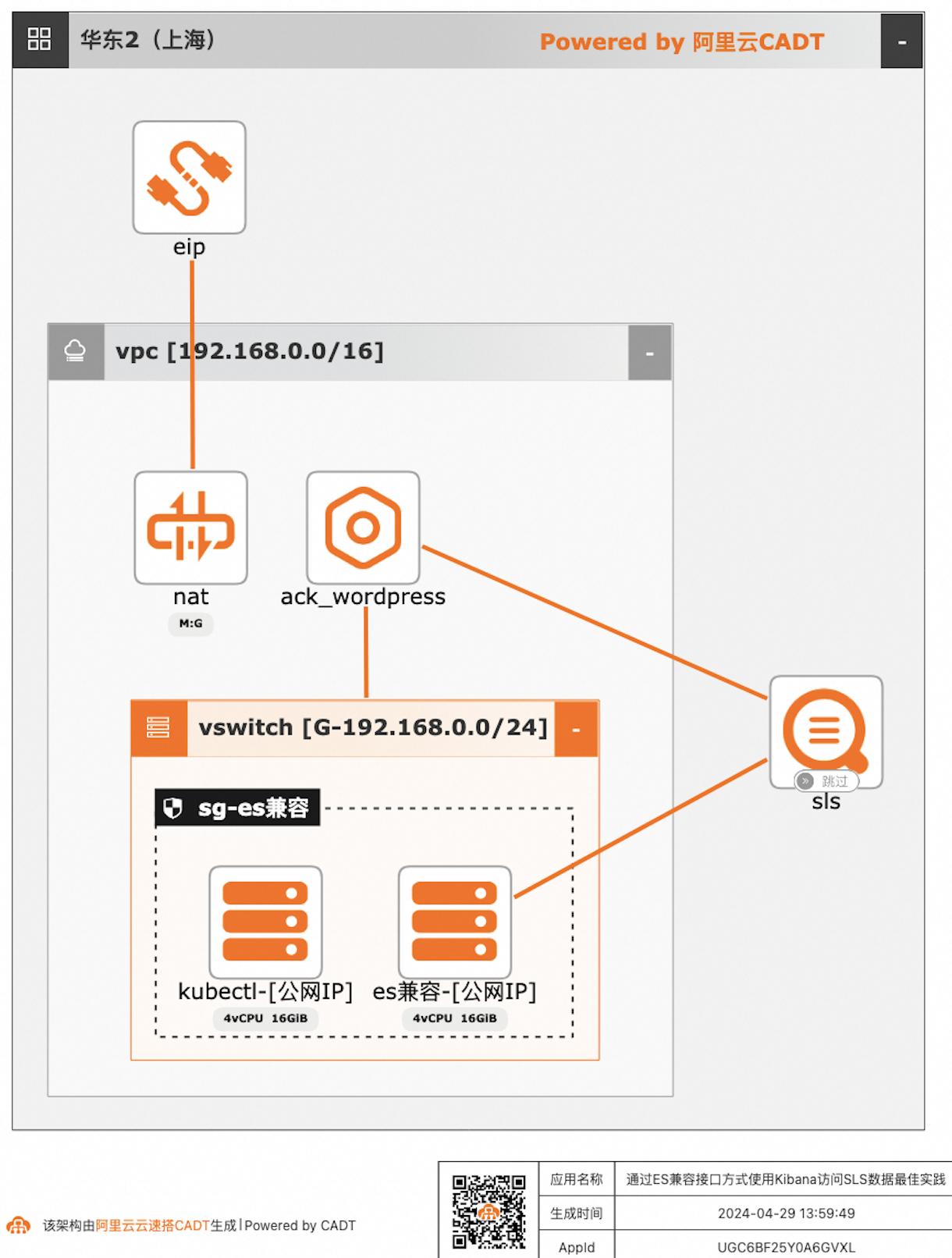
自建ELK日志系统的客户迁移到阿里云日志服务SLS后,对SLS查询分析语法不太熟悉的客户,可以继续沿用原有的查询分析习惯,在不改变使用方式习惯的情况下,通过Elasticsearch兼容接口的方式使用Kibana访问SLS。
9200 返回上述内容,表示ES部署成功 步骤5 部署Proxy sudopodmanpullsls-registry.cn-hangzhou.cr.aliyuncs.com/kproxy/kproxy:1.9d 然后输入如下配置信息 sudopodmanrun-d-nameproxy\-eES_ENDPOINT=${Elasticsearch所在机器的IP地址}:9200\-eSLS_ENDPOINT=https://${Project名称}.${Project所在 region}.log.aliyuncs....
基于日志服务构建业务可观测性系统
现在已知的各种监控数据的工具,以及对应的监控系统有非常多的选择,比如ZABBIX,Prometheus,Skywalking等。但是这些系统都存在同样的一个问题,只覆盖了可观察性的一部分,举个简单的类比,大家在日常开车的过程中,会用到很多的辅助设备,仪表盘,行车记录仪,导航,倒车影像等等,这些设备都各自承载了一部分的功能,但是都存在着如下的问题: l 数据覆盖不完整 l 存在数据孤岛(无法关联协同) l 使用门槛高,不够人性化 核心价值 l 全覆盖,统一协议,支持各类平台。 l 数据关联,统一Schema,关联Metrics/Logs。 l 云原生,SaaS服务,拥抱云原生。 l 简单易用,自动化埋点,数十项易用功能。 智能化,异常诊断,根因分析。
步骤3 在配置管理>配置项页面,添加一个配置项"environment-variables",根据实际情况 在配置项中添加下列配置 1.PROJECT:(前面步骤 CADT自动创建的 project – e.g:sls-trace-qiling)2.INSTANCE:(前面步骤 创建的 trace实例 ID – e.g:k8s-tracing-app)3.HTTPS_ENDPOINT:(project+endpoint+固定端口号:10010。...
混合云存储构建VMware虚拟化平台
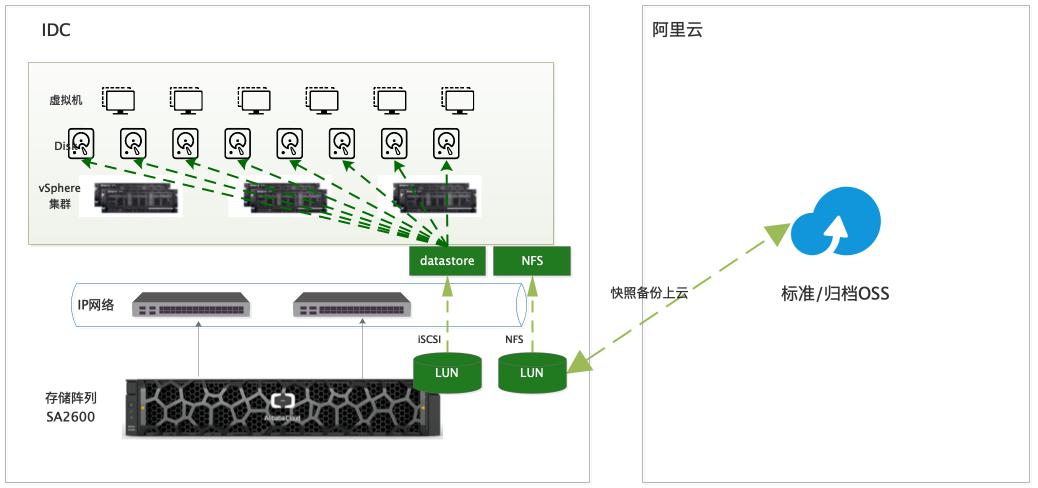
场景描述 本文以混合云存储阵列SA2600系统为例,介绍如 何在混合云存储环境下部署VMware虚拟化平台, 以及混合云环境下虚拟机的部署、扩容、云备份等功 能演示。 解决问题 1.如何使用混合云存储部署VMware虚拟化平台。 2.存储阵列在混合云环境下的使用,比如虚拟机部 署、扩容、云备份等。 产品列表 1.混合云存储阵列 2.对象存储OSS
本文由于 是专线环境所以使用vpc内网的EndPoint,如果是公网环境,请 选用公网EndPoint。bucket名称 OSS的bucket名称,请参见4.2.创建云存储网关。访问密钥ID AK,请参见4.1.配置RAM子账号。签名密钥 SK,请参见4.1.配置RAM子账号。文档版本:20191223 94 混合云存储构建VMware虚拟化平台 存储阵列配置 步骤5 配置文件系统...
基于链路追踪+ECI的流量洪峰应对
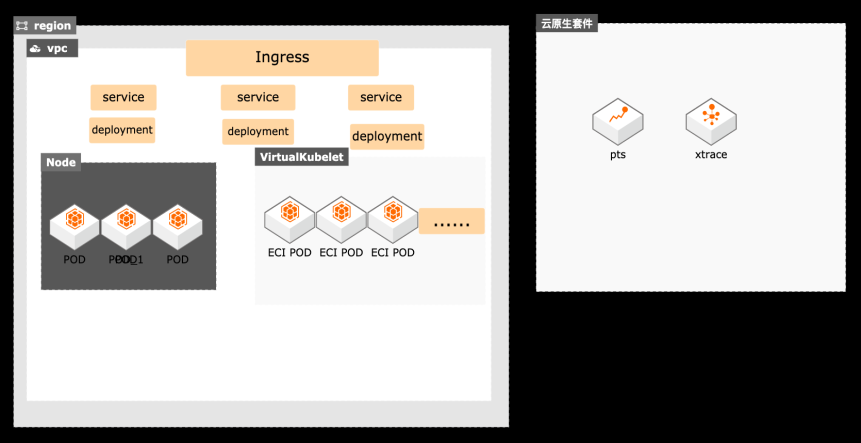
云原生技术已经为越来越多的互联网客户接受,对于在线教育、互动娱乐、电商等类型的客户会由于业务的原因存在突增业务流量,因此对于系统的稳定性非常关注,结合阿里云的容器服务、链路追踪、弹性容器ECI等产品,帮助客户业务实现容器化改造,并且方便发现系统应用架构中的瓶颈等问题,实现系统高弹性的同时优化客户的云资源使用成本。 l 方案优势 ᅳ 支持分布式追踪、调用链分析、DB调用分析、链路拓扑分析、业务指标统计等系统链路调用分析。 ᅳ 运维研发效率提高,链路追踪服务端全托管,免运维。 ᅳ 链路追踪的应用调用链分析能力结合ECI高弹性能力,提升应用系统在洪峰流量冲击下的稳定性。 ᅳ 链路追踪接入方便,ECI POD弹性伸缩,节省用户运维成本和云资源使用成本。 ᅳ 结合SLS Ingress可以基于应用前端访问性能指标做弹性伸缩,更丰富的云原生弹性能力。
文档版本:20201222 9 基于链路追踪+ECI的应用高可用弹性实践 应用部署 环境变量 SQL_ENVIRONMENT配置 mysql的访问地址,按照 1.3章节创建的数 据库服务访问地址进行配置,如下图所示:环境变量 TRACE_ENDPOINT配置链路跟踪接入点地址,获取方式如下:a.登录链路跟踪控制台(https://tracing.console.aliyun.com/)b.获取到...
云原生数据库
PolarDB是阿里云自研的云原生数据库,在存储计算分离架构下,利用了软硬件结合的优势,为用户提供秒级弹性、高性能、海量存储、安全可靠的数据库服务。100%兼容MySQL和PostgreSQL生态,支持分布式扩展,高度兼容Oracle语法。
最多可增加15个只读节点,通过控制台打开事务拆分功能,可把事务中的部分查询路由到只读节点,提升查询速度.PolarDB MySQL引擎可以设置多个连接地址Endpoint,连到不同的节点上,提供给不同的业务使用,一般用于隔离OLAP负载,避免对在线业务造成影响.云数据库PolarDB MySQL.云数据库Redis.云原生数据仓库ADB MySQL.推荐...
来自:
云产品
SAE-ACK应用双跑最佳实践
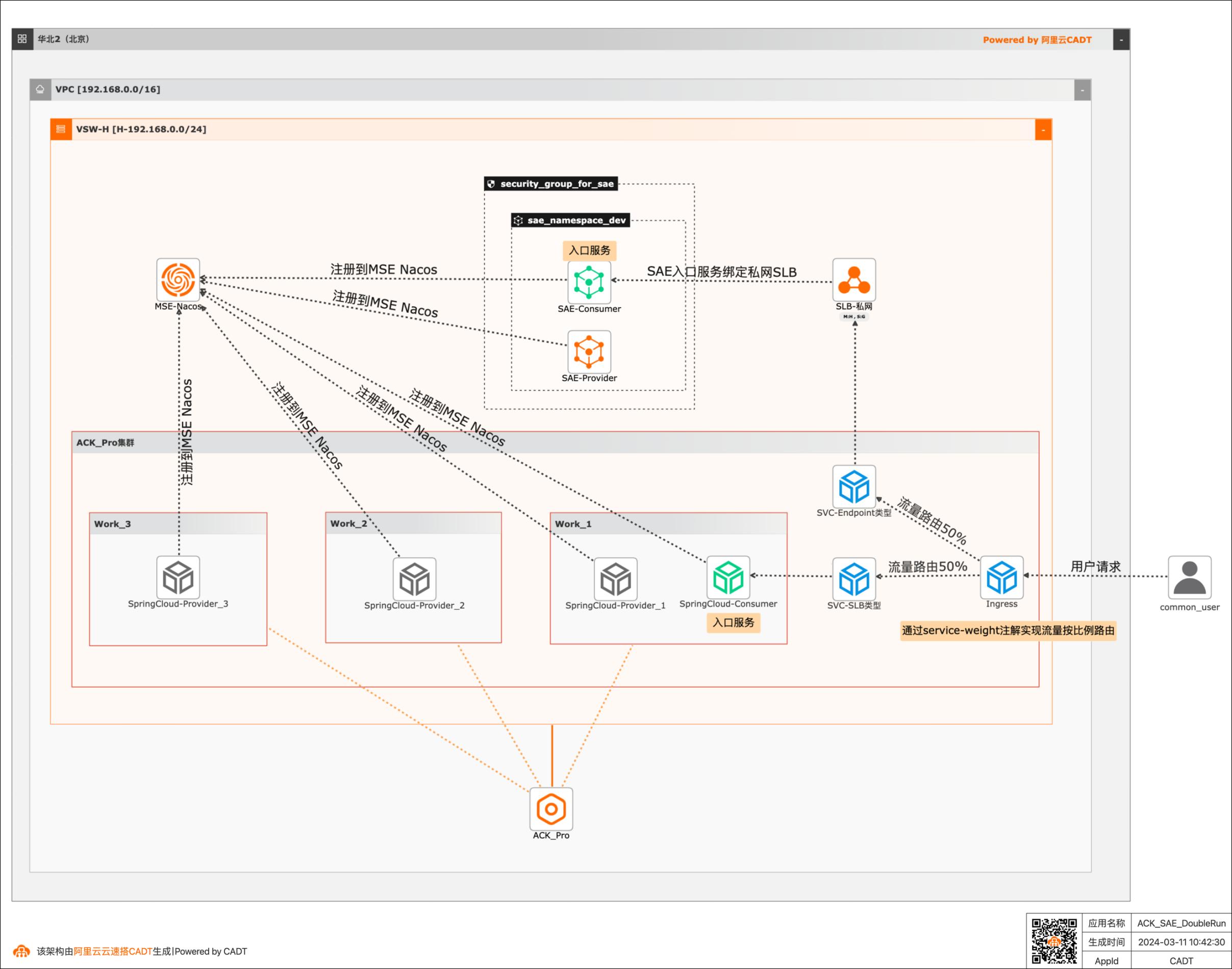
场景描述 实现ACK、SAE中部署的应用在东西向和南北向互通,实现SAE-ACK应用双跑。 应用场景 该最佳实践应用于两类场景: l 因为SAE支持更丰富自动扩缩指标(比如QPS,RT,TCP连接数等),所以将相对稳态的应用部署在ACK中,将相对弹性波动大的应用部署在SAE,借助SAE更强大的自动扩缩应对流量洪峰。 l 将K8s架构迁移到Serverless架构时,需要平滑过渡,所以该最佳实践中的双跑架构可以有效帮用户平滑的完成迁移。
SAE、MSE、ACK的Worker节点(ECS)都在该VPC的H可用区的交换机下 应用架构 SAE中部署Consumer服务和Provider服务,Consumer服务为入口服务,给该服务绑 定私网SLB,向内网暴露Endpoint。 ACK中部署Consumer服务和Provider服务,Consumer服务为入口服务,通过负载均 衡类型的Service暴露该入口服务。 ACK中创建...
企业用户多账号合并之存储迁移集中
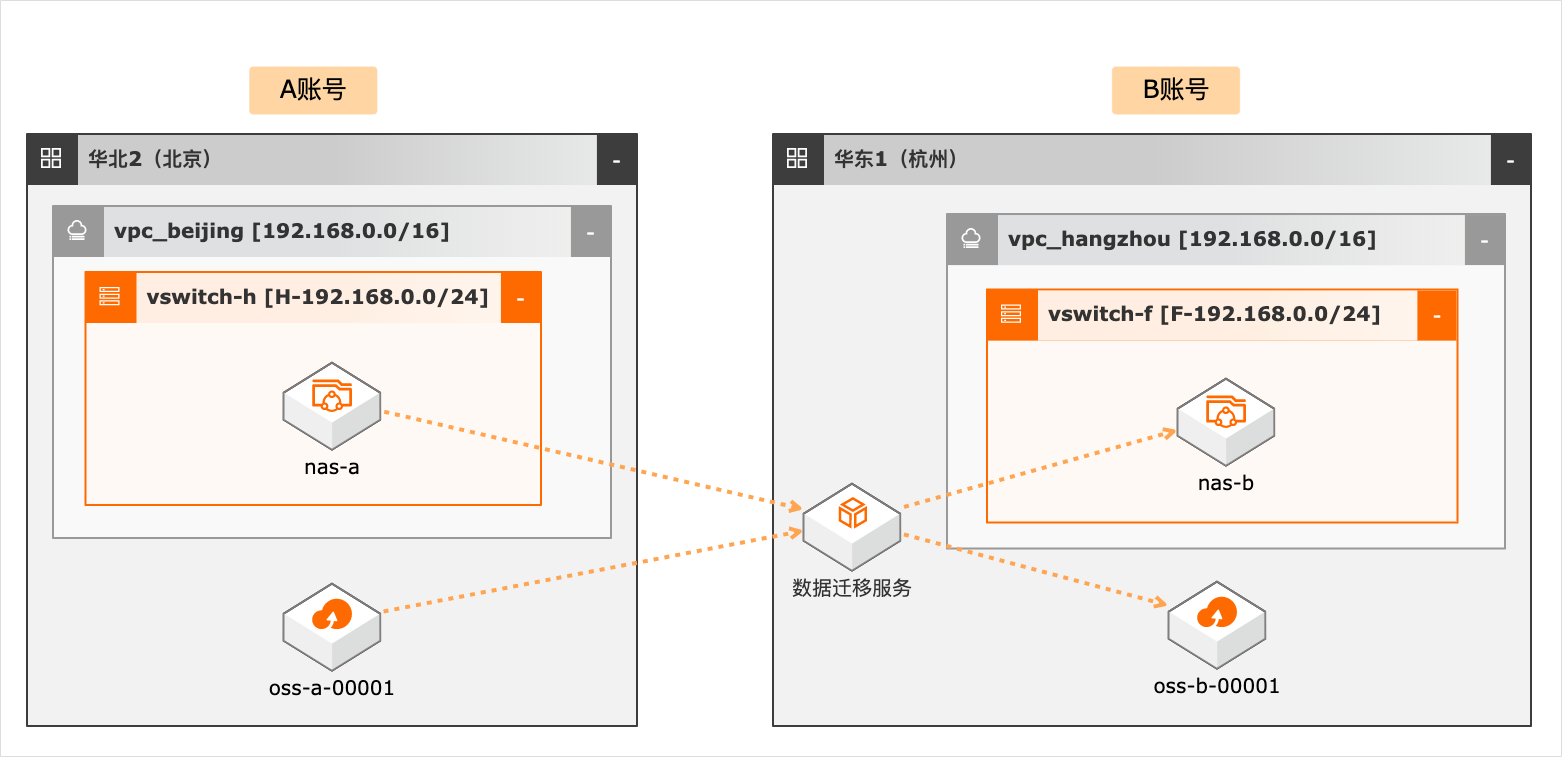
场景描述 本文介绍使用在线迁移服务,将分布在各个云 账号中的对象存储、文件存储数据集中到一个 账号的对象存储或文件存储下。 解决问题 1.安全治理需求,统一的账户体系、身份、权 限及资源管理。 2.业务系统相互访问,数据统一需求。 3.系统架构及资源成本优化需求,多账号下的 带宽、流量、存储包等资源整合优化。 4.企业或部门合并时云账号的合并。 产品列表 RAM OSS NAS 在线迁移
文档版本:20220505 14 企业用户多账号合并之存储迁移集中部署 使用数据迁移服务迁移 OSS数据 如果迁移任务的源数据地址与目的数据地址在同一个区域,则两个地址的 OSS Endpoint都建议设置为内网地址。步骤3 确认创建成功 文档版本:20220505 15 企业用户多账号合并之存储迁移集中部署 使用数据迁移服务迁移 OSS数据 2.2....
EHPC药物筛选
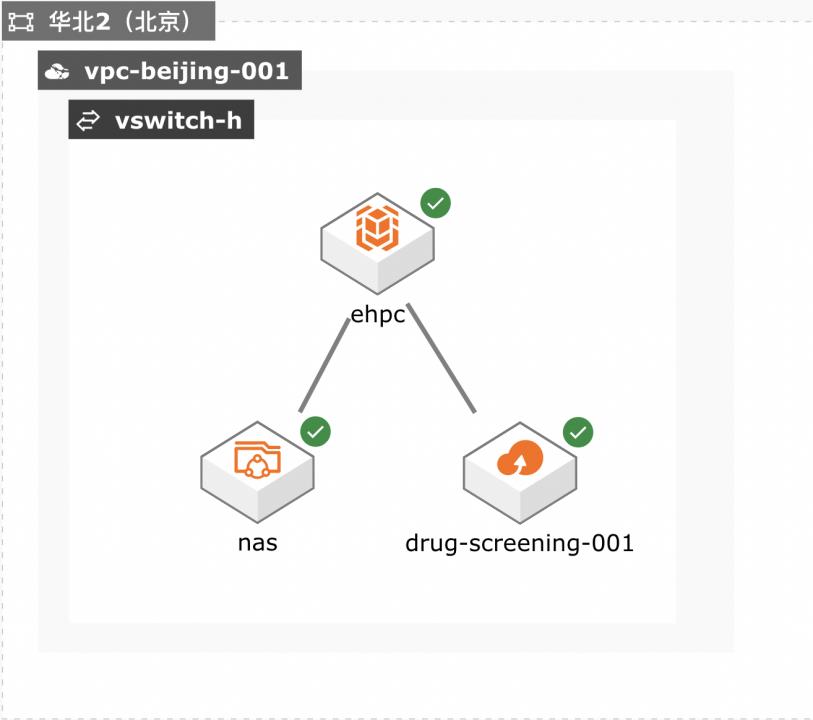
场景描述 本方案适用于使用弹性高性能计算 EHPC和文件存储NAS来搭建基础环 境,运行药物筛选应用AutodockVina 的场景中,这里采用批处理方式来提交 作业,并可以可视化计算结果。 方案架构 1.计算之前,将数据通过互联网/闪电立方/高速通道上传到阿里云OSS 2.计算时,将数据从OSS拉取到文件共享存储NAS上 3.计算时,在EHPC集群上进行,计算节点从NAS上读写数据 • 容量型NAS:低成本,大容量 • 性能型NAS:适合高IOPS应用,作为临时目录 • CPFS:适合超大规模,并行度极高的作业 4.计算节点: • 如果对计算时间不敏感,希望低成本运算,可选ECS实例 • 如果时效性要求高,建议采用SCC超级计算集群 5.可视化 • 如果可视化部分计算量不大,可以采用EHPC自带的可视化服务 解决问题 1.使用EHPC运行药物筛选应用 2.使用nas存储计算数据 3.使用OSS保存计算结果 • 通过分子对接(moleculardocking)模拟计算进行药物筛选,是模拟小分子配体和生物大分子受体的 相互作用,预测配体和受体的结合模式和亲和力。 • 通常,有很多已有的配体库,如商业化的Specs、Enamine和ChemDiv化合物库。提供大量配体,模 拟计算就是计算这些配体和给定受体的相互作用。 • 每次模拟计算通常处理一个配体和一个受体,不同配体之间没有依赖,因此可以同时大规模并行处 理。 本解决方案同样适用于有批量、高并发处理需求的其它生物、医药等场景。 产品列表 弹性高性能计算E-HPC 文件存储NAS 对象存储OSS
请输入语言(CH/EN,默认为:CH,该配置项将在此次 config 命令成功结束后生效):(点击 Enter)请输入 endpoint:oss-cn-beijing-internal.aliyuncs.com(输入 endpoint,在 ossbucket 的页面获取内 网访问地址)请输入 accessKeyID:L*Q(输入 accessID)请输入 accessKeySecret:F*w(输入 accesskey)请输入 stsToken:...
混合云使用Ali-Perseus
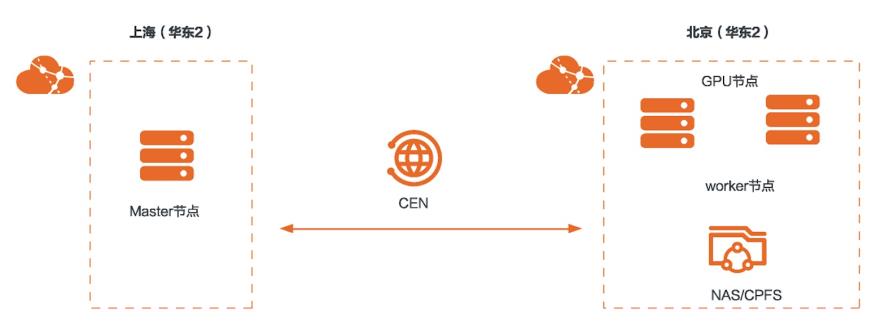
场景描述 本文介绍了混合云场景中,自建 Kubernetes服务,线下集群+云上弹性扩 展阿里云GPU服务实例+飞天AI加速工 具,并采用阿里云CPFS存储,运行AI训 练+AI推理作业的操作步骤。 解决问题 1.利用云企业网打通两个地域的VPC, 自建Kubernetes集群 2.使用飞天AI加速工具运行训练和推理 作业 3.使用CPFS存储共享数据 产品列表 云企业网CEN GPU云服务器 并行文件存储CPFS 文件存储NAS
[root@master001~]#arena serve list NAME TYPE VERSION DESIRED AVAILABLE ENDPOINT_ADDRESS PORTS perseus-serving CUSTOM 201909201648 1 1 10.107.253.138 grpc:8001,restful:8000 这里的 endpoint_address地址是10.107.253.138,记录备用后面推理的客户端会用到。步骤5 检查服务状态。[root@master001~]#kubectl get ...
- 产品推荐
- 这些文档可能帮助您