应用身份服务IDaaS
IDaaS是阿里云为企业用户提供的一套集中式身份、权限、应用管理服务,支持一个账号打通所有业务应用,统一控制多因子身份认证,集中管理的应用访问权限控制,集中透明的用户访问日志审计,助力企业解决单点登录问题,是5A统一身份认证管理系统。使用场景分为CIAM和EIAM,是国内第一家提供完整公有云、私有化 CIAM 解决方案的服务提供方。
阿里云原生体系,提供稳定、透明、开放的云服务,即开即用.CRM 应用.BPM 应用.业务应用账户管理.业务应用账户管理.免费开通使用.IDaaS 通过极其简单的配置,提供强大的、整套的身份连接和转化能力,帮助企业弥合身份间的孤岛.IDaaS 能作为桥梁,将不同体系中的身份贯通在一起,可以钉钉、AD 或其他企业身份源进行整合,实现...
来自:
云产品
基于函数计算FC实现大语言模型部署

在现代AI应用中, Qwen /chatglm2-6b 和Stable Diffusion等模型因其强大的功能而受到关注。然而,这些模型对计算资源的高需求和复杂的运维管理成为部署时的挑战。基于函数计算FC的无服务器计算模式为这类模型的部署提供了全新的解决方案。用户只需关注模型的部署和调用逻辑,而无需关心底层的服务器配置、资源分配和扩展性等问题。函数计算FC能够自动处理函数的执行环境,包括冷启动、弹性伸缩等,确保模型能够在大规模的请求下稳定运行。
DashScope中所有不同的模型 API服务都可以使用一个 API-KEY、以一致的 编程方式进行调用,方便开发者进行跨模态的、多个模型的接续调用。文档版本:20240429 4 基于函数计算 FC实现大语言模型部署最佳实践 最佳实践概述 前置条件 在进行本文操作之前,您需要完成以下准备工作:注册阿里云账号,并完成实名认证。您可以登录...
短信服务
阿里云短信服务(Short Message Service-SMS)支持国际和国内短信验证码、短信通知和营销推广短信,国内短信支持三网合一专属通道,支持发送助手及API/SDK接口,按成功收费,免运维,秒级触达,服务范围覆盖全球200多个国家和地区。
设置多个发送队列,确保短 信发送请求被实时接收及处理.查看详情文档.强大的高并发处理.基于阿里云账户及RAM授权 体系,对发送API进行鉴权确 保只有您才可调用自己的API.创建RAM用户文档.API高安全调用.提供群发助手免运维支持5种 编程语言API对接,如Java、PHP、Python、Node.js及C#.设置发送方式文档.免运维简单集成.可...
来自:
云产品
云数据库 SelectDB 版
阿里云数据库 SelectDB 是现代化实时数据仓库 SelectDB 在阿里云上的全托管服务,内核基于业界领先的开源分析型数据库 Apache Doris 研发,由阿里云和飞轮科技联合打造。阿里云数据库 SelectDB 聚焦于满足企业级大数据分析需求,广泛应用于实时报表分析、即席多维分析、日志检索分析、数据联邦与查询加速等场景,致力于为客户提供极致性能、简单易用的数据分析服务。
立即购买免费试用快捷入口控制台文档APISDK价格计算器产品定价热门商品产品动态内容甄选█████询价中.立即购买█████询价中.立即购买█████询价中.立即购买最新动态阿里云 SelectDB 携手 DTS,一键实现 TP 数据实时入仓2024.03.18最新功能基于Apache Doris 2.0开发的阿里云数据库 SelectDB 3.0版发布2023.10.12...
来自:
云产品
实时计算Flink版
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,具备实时应用的作业开发、数据调试、运行与监控、自动调优、智能诊断等全生命周期能力。内核引擎100%兼容Apache Flink,2倍性能提升,拥有FlinkCDC、动态CEP等企业级增值功能,内置丰富上下游连接器,助力企业构建高效、稳定和强大的实时数据应用。
中国信通院权威认证 中国唯一进入 Forrester 象限的实时流计算产品 金融实时数仓方案入围工信部信创典型目录.实时计算Flink版最佳实践.钱大妈基于 Flink 的实时风控实践.实时计算Flink版总体介绍.实时计算Flink版快速入门.实时计算Flink版文档首页.实时计算Flink版应用场景.阿里云实时计算Flink版解决方案白皮书.入门视频...
来自:
云产品
数据迁移上云
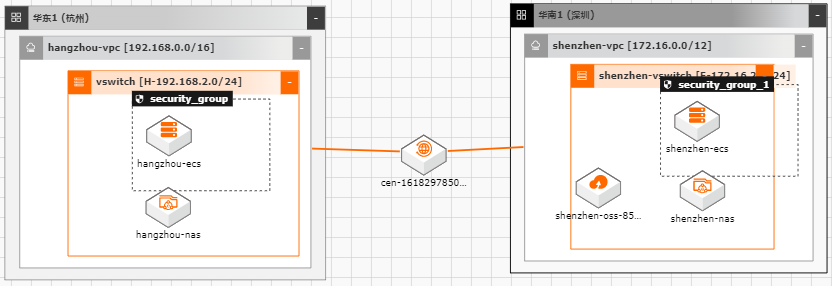
随着越来越多的企业选择将业务系统上云,各种类型的数据如何便捷、平滑的迁移上 云,成了用户上云较为关注的点;业务上云后,因为业务或者其他方面调整等因素, 也存在如跨区域,跨账号等数据迁移的场景。针对以上需求,阿里云上提供了较为丰 富的工具(如ossimport)、服务(在线迁移服务),旨在能够帮助客户便捷进行数据迁 移。 本文通过云架构设计工具CADT来快速创建云上基础资源,并以杭州区域来模拟线 下IDC(或友商),深圳区域模拟阿里云云上资源。通过云上的工具命令、服务来提 供常见数据迁移场景的最佳实践。
广泛应用于容器存储、大数据分析、Web 服务和内容管 理、应用程序开发和测试、媒体和娱乐工作流程、数据库备份。支持冷热数据分级 存储。详见:https://www.aliyun.com/product/nas 云服务器 ECS:云服务器 ECS(Elastic Compute Service)是一种弹性可伸缩的 计算服务,助您降低 IT 成本,提升运维效率,使您更专注于核心...
基于DataWorks的大数据一站式开发及数据治理

概述 基于Dataworks做大数据一站式开发,包含数据实时采集到kafka通过实时计算对数据进行ETL写入HDFS,使用Hive进行数据分析。通过Dataworks进行数据治理,数据地图查看数据信息和血缘关系,数据质量监控异常和报警。 适用场景 日志采集、处理及分析 日志使用Flink实时写入HDFS 日志数据实时ETL 日志HIVE分析 基于dataworks一站式开发 数据治理 方案优势 大数据一站式开发,完善的数据治理能力。 性能优越:高吞吐,高扩展性。 安全稳定:Exactly-Once,故障自动恢复,资源隔离。 简单易用:SQL语言,在线开发,全面支持UDX。 功能强大:支持SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据源计算等Data Lake相关功能 ,以及各种流式及静态数据源关联查询。
支持 Datastream API 作业开发,提供了批流统一的 Flink SQL,简 化 BI 场景下的开发;可与用户已使用的大数据组件无缝对接,更多增值特性助力 企业实时化转型。详情请查看 www.aliyun.com/product/bigdata/product/sc EMR:阿里云 E-MapReduce(EMR)是构建在阿里云云服务器 ECS 上的开源 Hadoop、Spark、HBase、Hive、Flink...
Salesforce on Alibaba Cloud
阿里云和Salesforce共同为中国客户带来了全球广受好评的CRM(客户关系管理)平台,包括销售云、服务云、电商云和 Salesforce 平台。它可以让企业的营销、销售、商务、服务和IT团队从任何地方一起协同工作,以提供卓越的客户体验。
具备简单操作易上手,即开即用,接口开放易集成等优势.CDN通过广泛的网络节点分布,提供快速、稳定、安全、可编程的全球内容分发加速服务,支持将网站、音视频、下载等内容分发至接近用户的节点,使用户可就近取得所需内容,提高用户访问的响应速度和成功率.容器服务 Kubernetes 版(简称 ACK)提供高性能可伸缩的容器应用...
来自:
云产品
营销引擎云码
营销引擎云码(Intelligent Marketing Engine)是阿里云-企业云服务的数字化营销工具平台,围绕企业全域业务增长的目标,提供营销投放、用户建模、智能分发以及消费者触达的一站式全链路SaaS工具平台,并以营销效果为计费单元。
更多产品与服务.针对客户在营销创意素材、企业内部培训、用户运营等多种场景中的素材生产需求,基于通义大模型、高效低...在API方面为用户提供标准业务API对接文档和淘系拉新业务API对接文档与接口方.支持移动应用App、小程序、AIoT媒体等多种媒体形态,用户可以根据业务的实际需求进行自由选择.媒体渠道平台.更多品牌客户.
来自:
云产品
应用实时监控服务ARMS
作为云原生可观测平台,应用实时监控服务 ARMS 包含前端监控、应用监控、云拨测等模块。覆盖浏览器、小程序、APP、分布式应用、容器等不同可观测环境与场景。帮助企业实现全栈性能监控与端到端追踪诊断。提高监控效率,压降运维工作量。
借助云主机、PC端、移动端拨测点,模拟多地域、多运营商用户,对Web应用、网站、API接口进行拨测,及时发现网络质量波动与网站、API服务可用性问题.分析端侧应用在网络请求、页面加载、资源加载过程中的关键性能指标,对应用崩溃、ANR、卡顿等影响用户体验的异常问题追踪详细堆栈信息,定位问题影响范围,促进用户体验性能...
来自:
云产品
- 产品推荐
- 这些文档可能帮助您