智能数据建设与治理Dataphin
Dataphin遵循阿里巴巴集团多年实战沉淀的大数据建设OneData体系(OneModel、OneID、OneService),集产品、技术、方法论于一体,一站式地为您提供集数据引入、规范定义、智能建模研发、数据萃取、数据资产管理、数据服务等的全链路智能数据构建及管理服务。助您打造属于自己的标准统一、资产化、服务化和闭环自优化的智能数据体系,驱动创新。
通过SQL、Python、Shell等代码任务完成数据任务的研发,并支持创建代码模板提升开发效率.提供任务视角和字段视角的运维能力,结合限流、基线监控等功能,可支持千万级任务调度与运维.提供业务视角的调度限流及智能基线监控能力,更早发现异常,更快止血以保障系统稳定性和数据可用性.主题式数据查询.支持逻辑数据模型的雪花...
来自:
云产品
云原生大数据计算服务MaxCompute
阿里云云原生大数据计算服务MaxCompute是面向分析的企业级云数仓,作为一体化大数据智能计算平台ODPS的大规模批量计算引擎,MaxCompute以 Serverless 架构提供快速、全托管的在线数据仓库服务,使您经济高效的分析处理海量数据,进行敏捷的业务洞察。
使用Python机器学习三方库.深度集成 Spark 引擎.内建Apache Spark引擎,提供完整的Spark功能;与MaxCompute计算资源、数据和权限体系深度集成.集成对数据湖(OSS或Hadoop HDFS)的访问分析,支持外表映射、Spark直接访问方式开展数据湖分析;在一套数仓服务和用户接口下,实现湖与仓的关联分析.支持流式采集和近实时分析....
来自:
云产品
自建ELK迁移阿里云日志服务
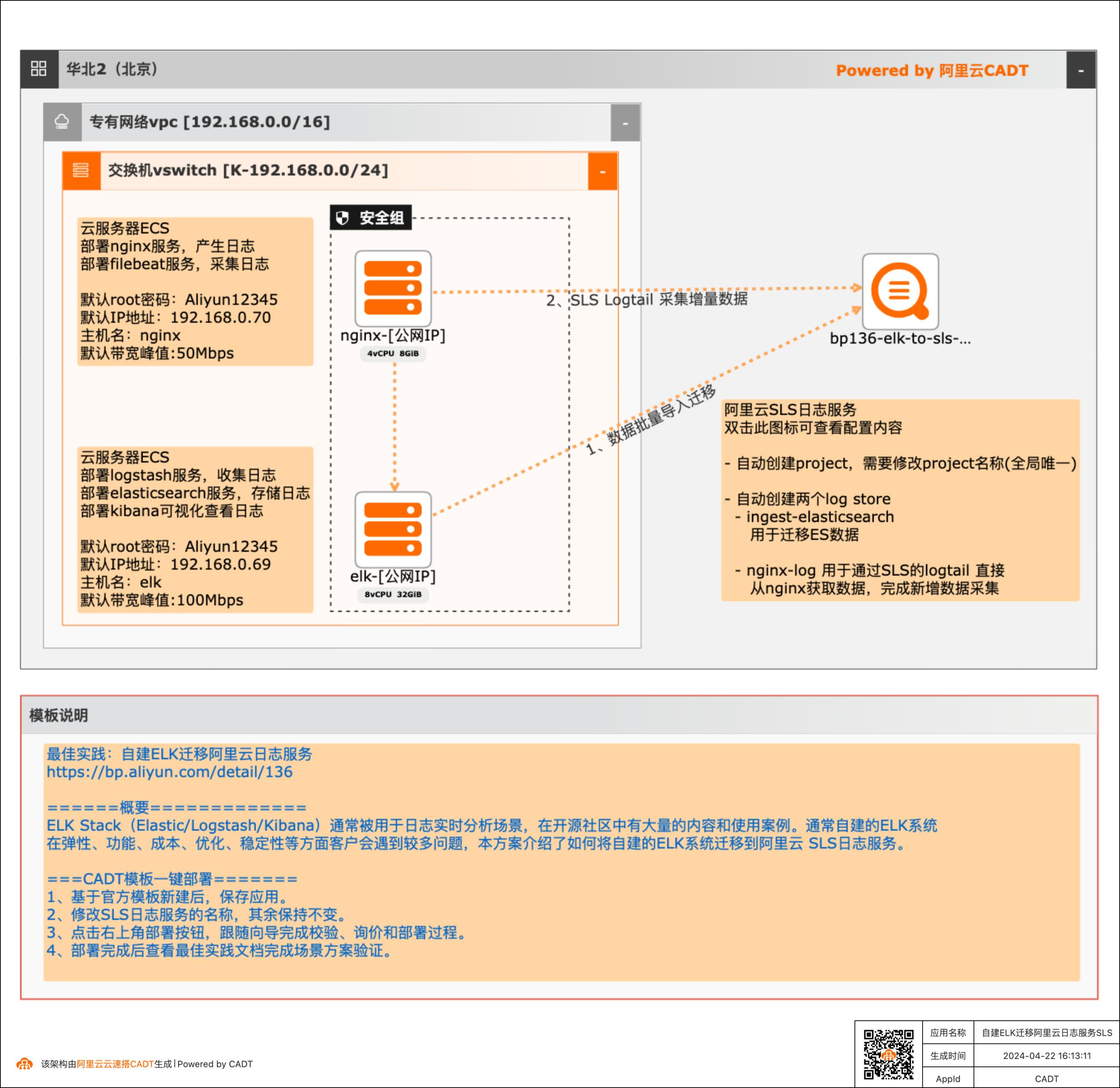
场景描述 ELK Stack(Elastic/Logstash/Kibana) 通常 被用于日志实时分析, 在开源社区中有大量 的内容和使用案例。 本文介绍如何将自建的 ELK 系统迁移到阿里云 SLS 日志服务。 解决问题 1. 自建 ELK 如何迁移到阿里云日志服务。 2. 如何使用 Logtail 采集日志。 3. 如何使用阿里云日志服务对日志进行查 询、 分析。 产品列表 阿里云日志服务(SLS) VPN 网关 IPSec VPN 云服务器
您可以根据需要调整这个间隔 步骤3 通过CADT画布双击nginx服务器,登陆nginx服务器,输入以下命令可以持续产生 nginx的访问日志 python3continuous_request.pyhttp:/{Nginx服务器IP}/启动脚本,循环进行访问 文档版本:20240422 21自建ELK迁移阿里云日志服务(SLS)准备测试数据 3.2.在Kibana上查看测试数据 步骤1 浏览器...
EHPC药物筛选
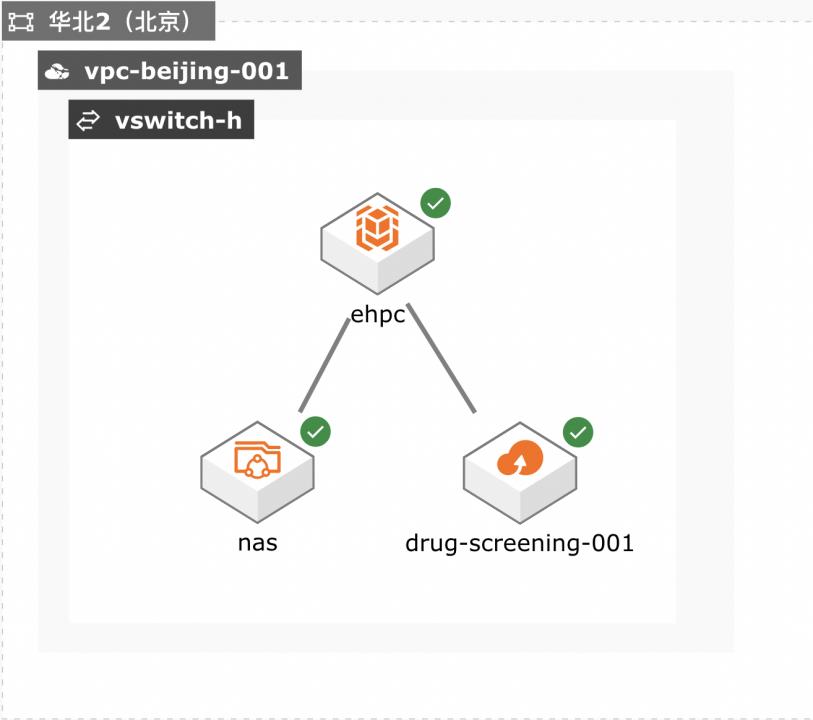
场景描述 本方案适用于使用弹性高性能计算 EHPC和文件存储NAS来搭建基础环 境,运行药物筛选应用AutodockVina 的场景中,这里采用批处理方式来提交 作业,并可以可视化计算结果。 方案架构 1.计算之前,将数据通过互联网/闪电立方/高速通道上传到阿里云OSS 2.计算时,将数据从OSS拉取到文件共享存储NAS上 3.计算时,在EHPC集群上进行,计算节点从NAS上读写数据 • 容量型NAS:低成本,大容量 • 性能型NAS:适合高IOPS应用,作为临时目录 • CPFS:适合超大规模,并行度极高的作业 4.计算节点: • 如果对计算时间不敏感,希望低成本运算,可选ECS实例 • 如果时效性要求高,建议采用SCC超级计算集群 5.可视化 • 如果可视化部分计算量不大,可以采用EHPC自带的可视化服务 解决问题 1.使用EHPC运行药物筛选应用 2.使用nas存储计算数据 3.使用OSS保存计算结果 • 通过分子对接(moleculardocking)模拟计算进行药物筛选,是模拟小分子配体和生物大分子受体的 相互作用,预测配体和受体的结合模式和亲和力。 • 通常,有很多已有的配体库,如商业化的Specs、Enamine和ChemDiv化合物库。提供大量配体,模 拟计算就是计算这些配体和给定受体的相互作用。 • 每次模拟计算通常处理一个配体和一个受体,不同配体之间没有依赖,因此可以同时大规模并行处 理。 本解决方案同样适用于有批量、高并发处理需求的其它生物、医药等场景。 产品列表 弹性高性能计算E-HPC 文件存储NAS 对象存储OSS
请输入语言(CH/EN,默认为:CH,该配置项将在此次 config 命令成功结束后生效):(点击 Enter)请输入 endpoint:oss-cn-beijing-internal.aliyuncs.com(输入 endpoint,在 ossbucket 的页面获取内 网访问地址)请输入 accessKeyID:L*Q(输入 accessID)请输入 accessKeySecret:F*w(输入 accesskey)请输入 stsToken:...
E-HPC低成本实现量化策略回测
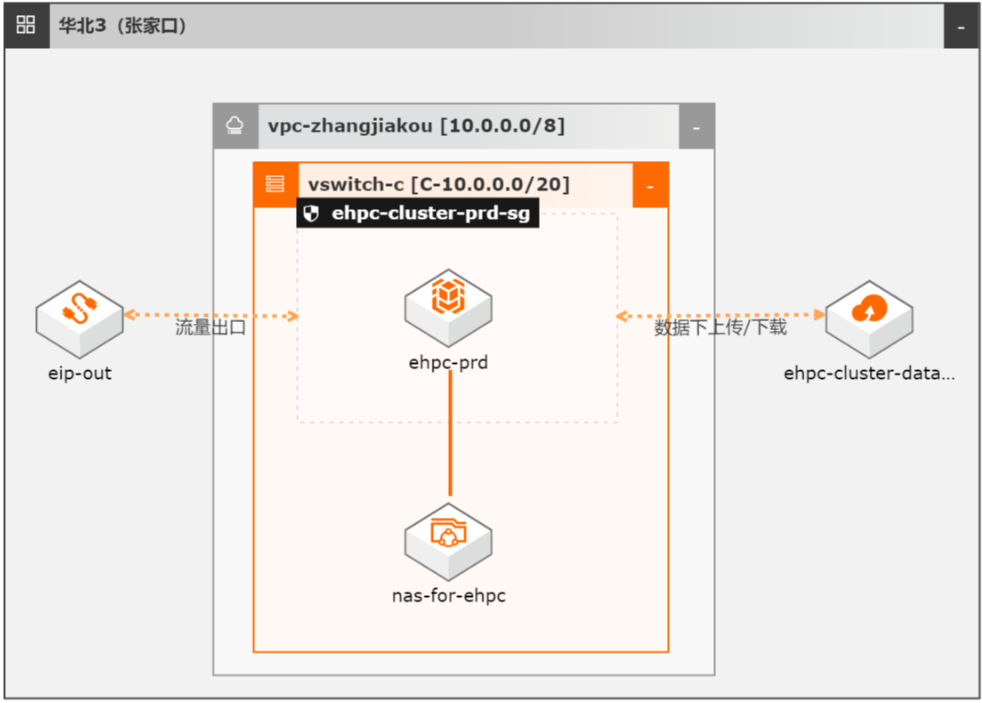
在量化交易场景下,量化策略的构建流程一般包括:想法、数据获取、建模、回测、结果分析等,在回测过程中往往需要海量的算力,进行大量数据的分析和处理,如何快速、高效和低成本的进行批量任务的调度,并快速获取结果是量化领域遇到的普遍挑战,这也是云计算能够带给客户的巨大优势。
而结果精度则与运行环境有着巨大的关系,不 同的代码运行环境版本(比如 Python2.7或者 Python3.8)则可能会有不同的结果。为屏蔽代码运行环境对最后结果的影响,我们推荐使用容器化镜像进行统一、标准化 的运行环境 Docker。Docker可以让开发者打包自己的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何一个...
AK防泄漏
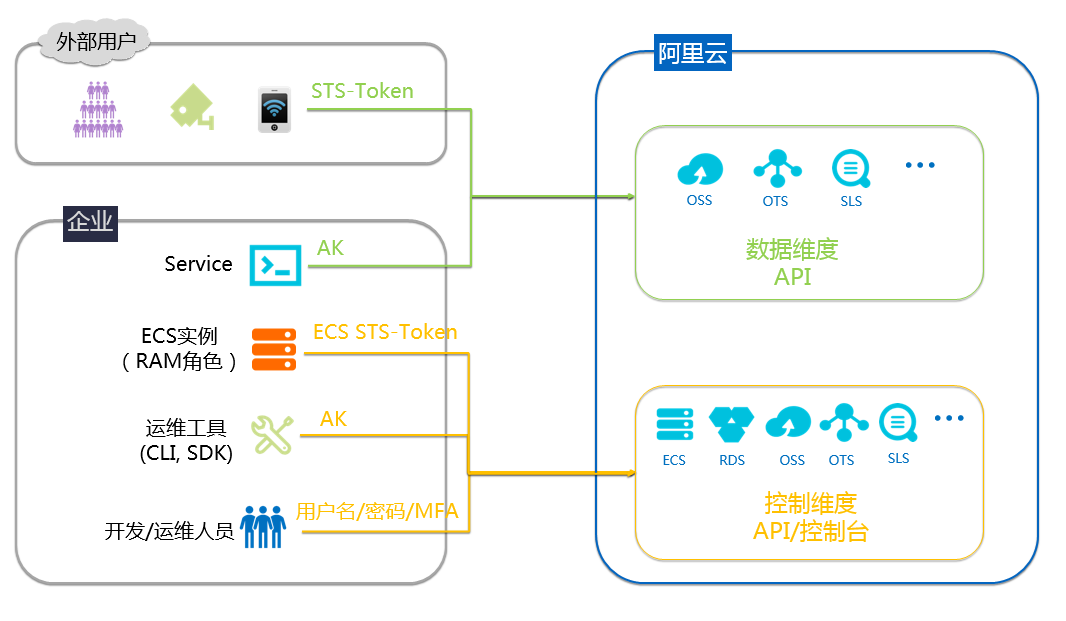
场景描述 用户名密码是开发运维人员访问阿里云控制台 的凭据,AK是软件程序访问阿里云资源的凭据。 如果AK被泄露,那么会造成非常严重的后果, 比如资源被释放导致业务不可用、大量服务器被 创建用来挖矿,等等。采用合适的方式来使用、 保护AK,是每一个云客户都必须关注的问题。 解决问题 1.避免AK被泄露 2.改进已经错误使用AK的方法 产品列表 访问控制RAM 云服务器ECS 操作审计Action Trail 云安全中心
文档版本:20220211 38 AK防泄漏 使用 ECS部署应用的动态身份 步骤2 执行 python文件,python ecs_sts.py 如下图代表执行成功:步骤3 在 oss指定 bucket下查看是否生成了我们创建的文件,如下截图所示表示成功创建:文档版本:20220211 39 AK防泄漏 服务端程序使用子账号及其AK 5.服务端程序使用子账号及其 AK 此种方式适合...
基于函数计算FC实现阿里云Kafka消息内容控制MongoDB DML操作
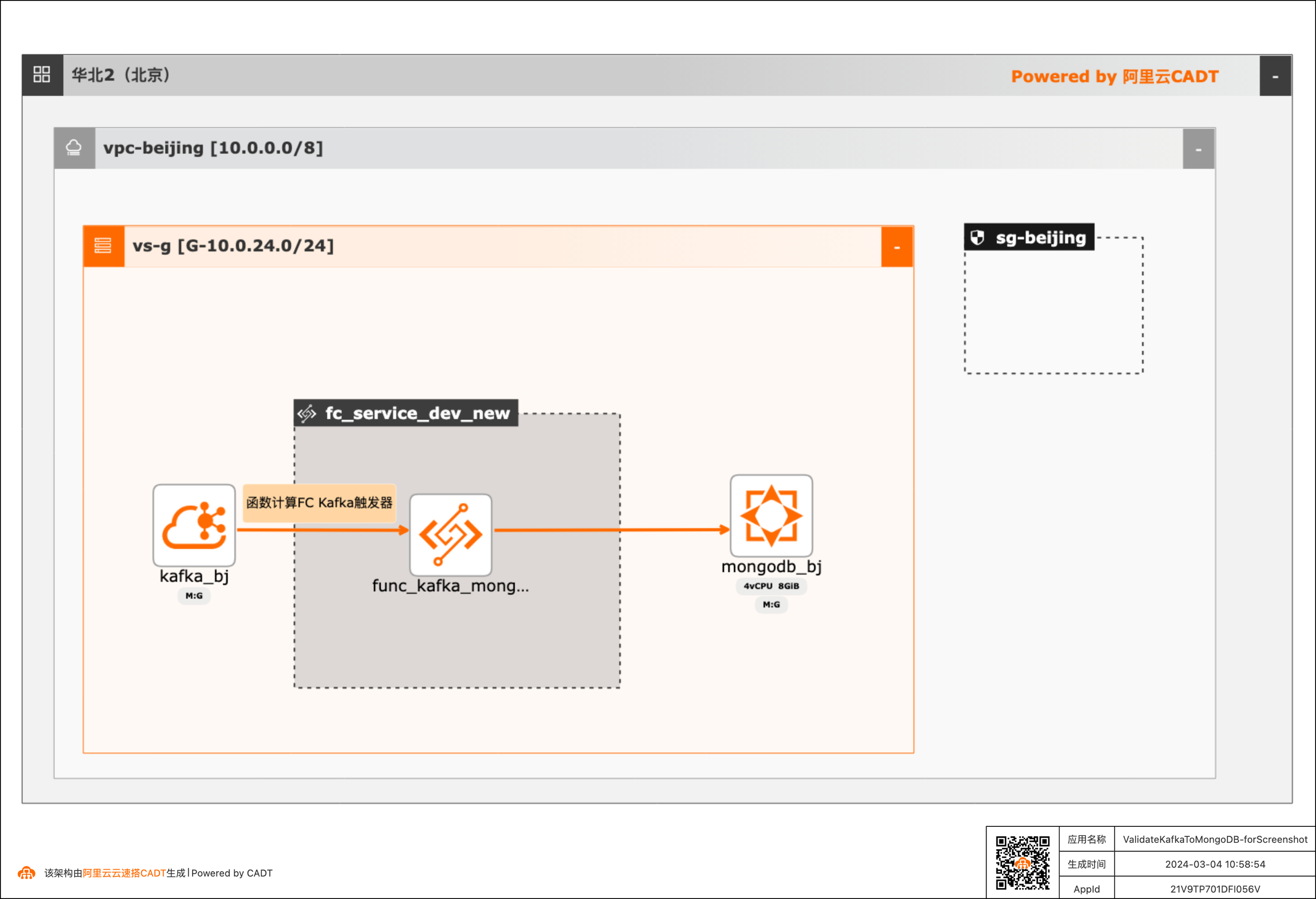
在大数据ETL场景,将Kafka中的消息流转到其他下游服务是很常见的场景,除了常规的消息流转外,很多场景还需要基于消息体内容做判断,然后决定下游服务做何种操作。 该方案实现了通过Kafka中消息Key的内容来判断应该对MongoDB做增、删、改的哪种DML操作。 当Kafka收到消息后,会自动触发函数计算中的函数,接收到消息,对消息内容做判断,然后再操作MongoDB。用户可以对提供的默认函数代码做修改,来满足更复杂的逻辑。 整体方案通过CADT可以一键拉起依赖的产品,并完成了大多数的配置,用户只需要到函数计算和MongoDB控制台做少量配置即可。
31 文档版本:20240304 基于函数计算 FC 实现阿里云 Kafka 消息内容控制 MongoDB DML 操作 场景验证 ARN 的地址为:acs:fc:{region}:1730431480417716:layers/Python3x-PyMongo4x/versions/1 根据自己使用的阿里云地域,将 {region}部分改为地域 ID(各地域 ID 详见:https://help.aliyun.com/zh/drp/support/region-ids )...
基于函数计算FC实现物联网音视频处理
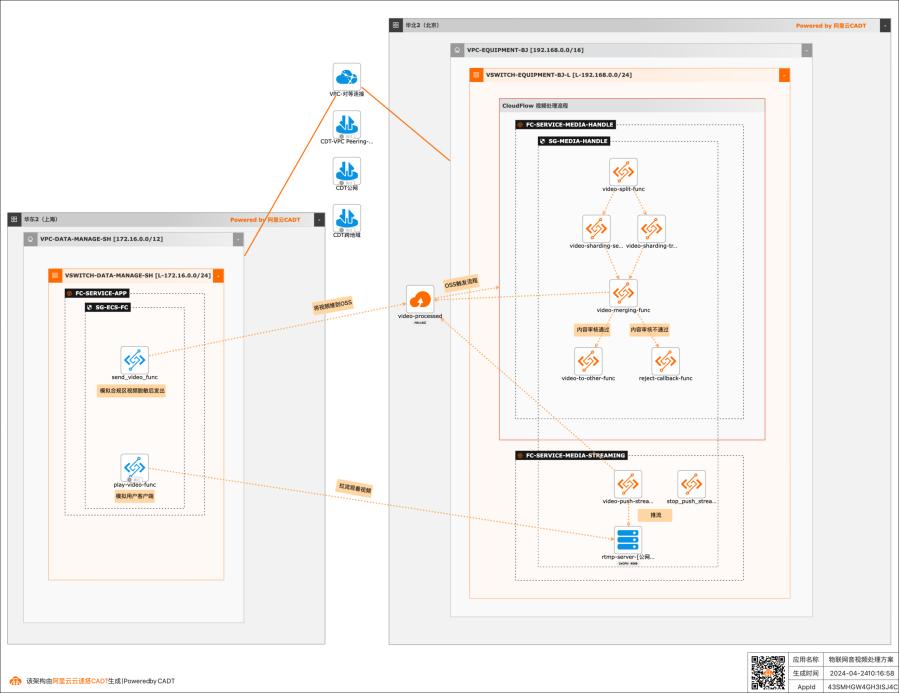
在物联网场景中,智能设备会产生大量的非结构化数据,并且采集量和频率都很高。比如各类摄像头(家用摄像头、车载摄像头、工业监控摄像头等)采集的数据。企业需要对这些非结构化数据做快速的分析和处理,然后应用到下游业务中,所以需要一套高并发、低成本、自动化的方案。该最佳实践就适用于这类场景。
(函数分为HTTP请求驱动和事件驱动) 运行环境:选择Python3.10 代码上传方式:选择使用示例代码。(函数中的代码在后续需要进入函数计算控制 台补充) vCPU规格:1c(函数计算有多种CPU资源规格,可以根据实际情况自行选择) 内存规格:2048MB(函数计算有多种内存资源规格,可以根据实际情况自行选择) 硬盘...
函数计算实现弹性音视频处理系统
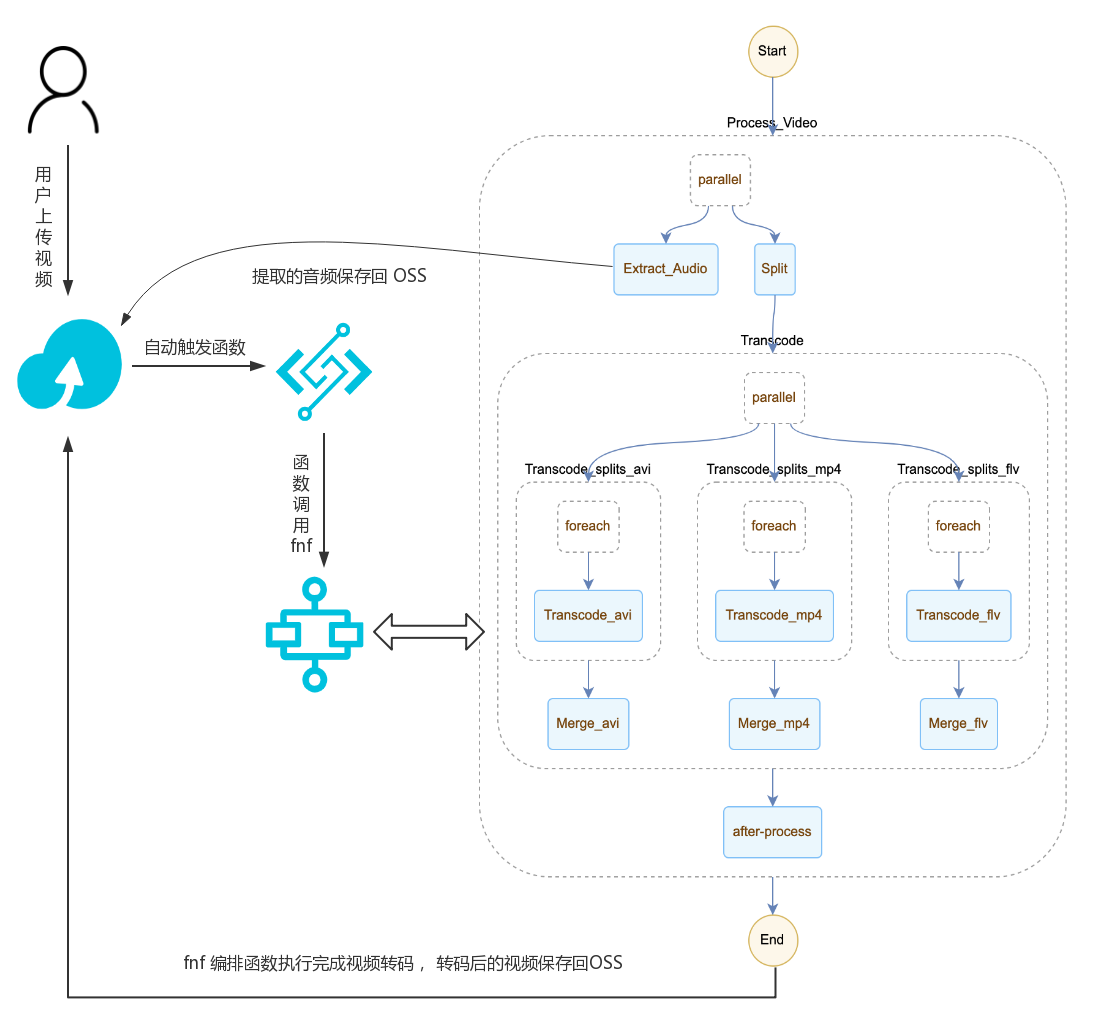
场景描述 本示例通过函数计算部署一个高弹性高可用的 音视频处理系统。尤其适合视频网站使用,每天 有大量的上传视频,需要及时转码处理以适配各 种终端及网络条件,要求短时间内准备大量的计 算资源进行大规模并行转码处理,同时希望基于 FFmpeg自建的转码服务能简单迁移。 解决问题 1.如何使用函数计算部署音视频处理系统。 2.如何进行系统的压测。 产品列表 函数计算服务 文件存储NAS 对象存储OSS 函数工作流FnF 日志服务SLS
pip install-upgrade pip#pip install aliyun-python-sdk-core-v3#pip install aliyun-fc2#pip install aliyun-python-sdk-fnf 5.2.验证功能正常 首先下载一个视频文件,这个视频文件大小为 56MB,来测试功能是否正常。这里我们通过 ossutil 工具进行上传。工具使用方法请参见文档:...
基于DataWorks的大数据一站式开发及数据治理

概述 基于Dataworks做大数据一站式开发,包含数据实时采集到kafka通过实时计算对数据进行ETL写入HDFS,使用Hive进行数据分析。通过Dataworks进行数据治理,数据地图查看数据信息和血缘关系,数据质量监控异常和报警。 适用场景 日志采集、处理及分析 日志使用Flink实时写入HDFS 日志数据实时ETL 日志HIVE分析 基于dataworks一站式开发 数据治理 方案优势 大数据一站式开发,完善的数据治理能力。 性能优越:高吞吐,高扩展性。 安全稳定:Exactly-Once,故障自动恢复,资源隔离。 简单易用:SQL语言,在线开发,全面支持UDX。 功能强大:支持SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据源计算等Data Lake相关功能 ,以及各种流式及静态数据源关联查询。
简单易用:SQL语言,在线开发,全面支持 UDX。功能强大:支持 SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据 源计算等 Data Lake相关功能,以及各种流式及静态数据源关联查询。安全:原生的多租户系统,以项目进行隔离,所有计算任务在安全沙箱中运行。文档版本:20201020 2 基于 Dataworks的大数据一站式开发...
RAPIDS加速图像搜索
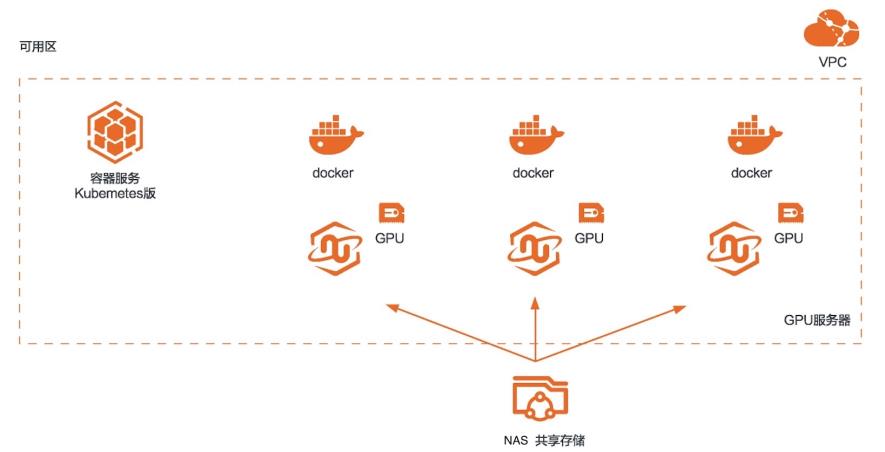
场景描述 本方案适用于使用RAPIDS加速平台 +GPU云服务器来对图像搜索任务进行加 速的场景。相比CPU,利用GPU+ RAPIDS在图像搜索场景下可以取得非常 明显的加速效果。 解决问题 1.搭建RAPIDS加速图像搜索环境 2.使用容器服务Kubernetes版部署图 像搜索环境 3.使用NAS存储计算数据 产品列表 容器服务Kubernetes版 GPU云服务器 文件存储NAS
RAPIDS构建于 Apache Arrow、pandas和 scikit-learn等流行的 开源项目之上,为最流行的 Python数据科学工具链带去 GPU提速。通常一个数据处理流程包含,数据处理,模型训练,可视化三部分。对应以上三部 分,RAPIDS分别使用 CUDF,CUML和 CUGRAPH三个软件库来进行加速。CUDF是一个 GPU版本的 PANDAS(最常用的数据处理 ...
RAPIDS加速机器学习
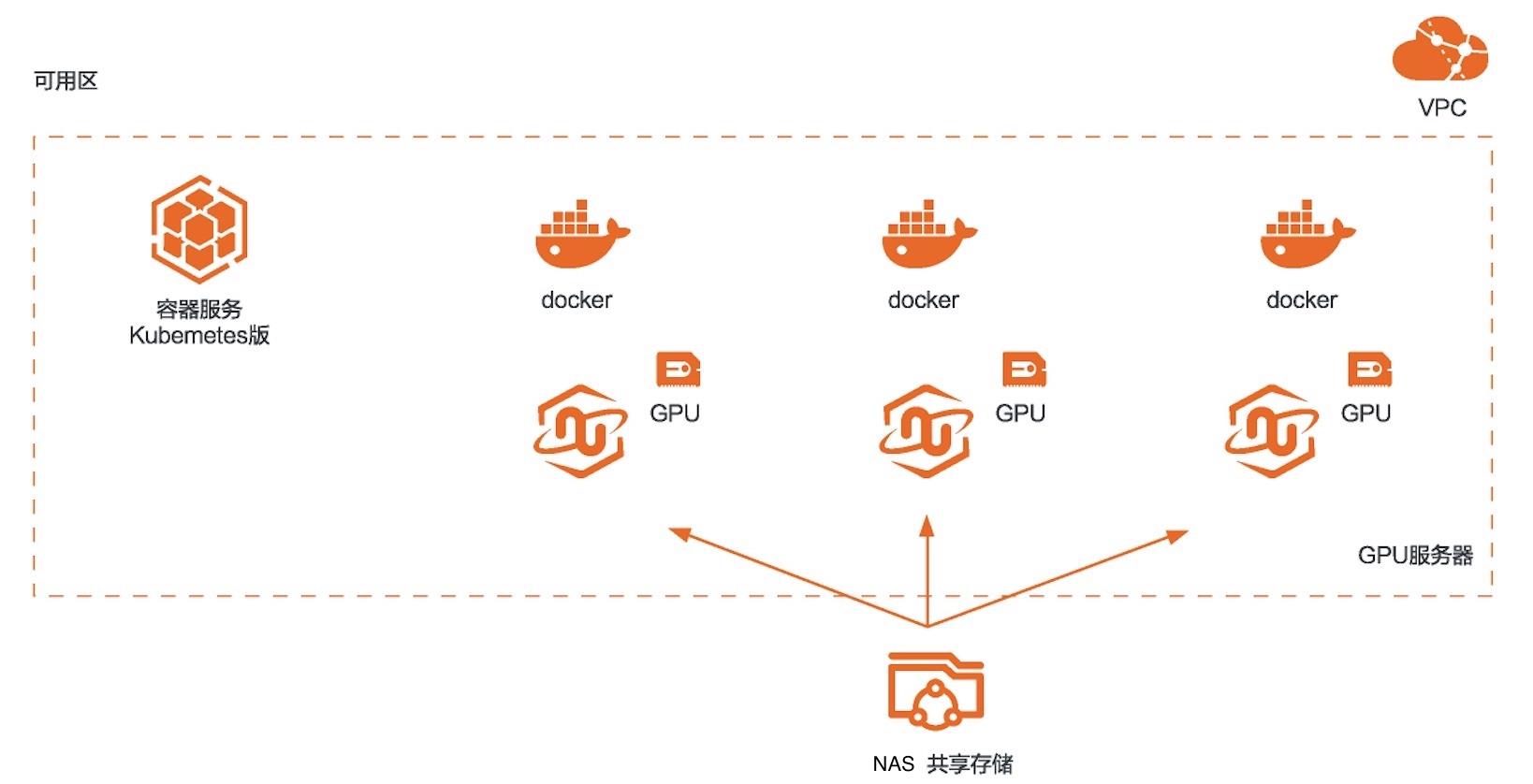
场景描述 本方案适用于使用RAPIDS加速库+GPU 云服务器来对机器学习任务或者数据科学 任务进行加速的场景。相比CPU,利用 GPU+RAPIDS在某些场景下可以取得非常 明显的加速效果。 解决问题 1.搭建RAPIDS加速机器学习环境 2.使用容器服务Kubernetes版部署 RAPIDS环境 3.使用NAS存储计算数据 产品列表 容器服务Kubernetes版 GPU云服务器 文件存储NAS
RAPIDS构建于 Apache Arrow、pandas和 scikit-learn等流行的 开源项目之上,为最流行的 Python数据科学工具链带去 GPU提速。通常一个数据处理流程包含,数据处理,模型训练,可视化三部分。对应以上三部 分,RAPIDS分别使用 CUDF,CUML和 CUGRAPH三个软件库来进行加速。CUDF是一个 GPU版本的 PANDAS(最常用的数据处理 ...
基于函数计算FC实现企业级权限精准控制Kafka跨实例消息同步
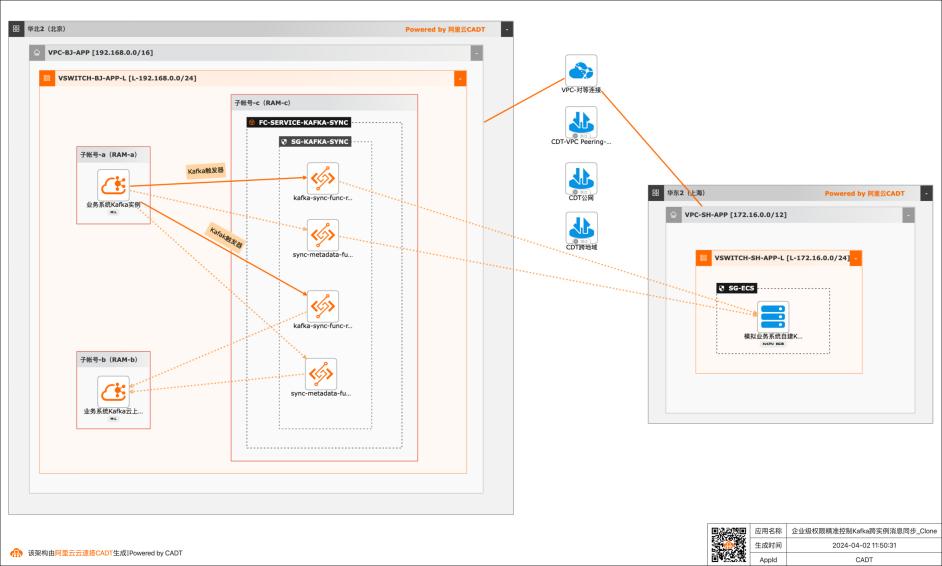
应用场景 在大数据场景,企业的Kafka实例可能存在多种情况,比如使用阿里云Kafka服务,可能是自建开源Kafka,或者是其他云上的云Kafka。不同的业务使用不同类型的Kafka实例,在这个前提下Kafka实例之间可能会需要消息同步的情况: 同帐号容灾场景:比如Kafka实例都是阿里云Kafka,但是Kafka实例会有主备之分,需要将主Kafka实例的消息实时同步到备Kafka。 跨帐号或异地容灾:这类场景比如主Kafka是阿里云Kafka,备Kafka是IDC开源自建Kafka,或者是其他云上的Kafka。 不同业务之间消息同步:因为现在的业务通常不会是信息孤岛,都需要消息互通,所以可能是A业务的Kafka实例消息需要同步到B业务的Kafka实例,并且这两个Kafka实例归属不同的RAM角色,有自己独自的权限控制。 解决问题 解决使用开源组件做消息同步的高成本问题。 解决使用开源组件做消息同步的并发性能、稳定性问题。 解决使用开源组件做消息同步的可靠性问题(重试机制,容错机制,死信队列等)。 大幅提升构建消息同步架构的效率,降低构建复杂度问题。
这里填入kafka-sync-lib 文档版本:20240330 38基于函数计算FC实现企业级权限精准控制Kafka跨实例消息同步 场景验证 兼容运行时:选择Python3.10 层上传方式:选择在线构建依赖层。 构建环境:选择Python3.10 requirements.txt文件:填入 schema confluent-kafka retrying 用换行隔开,不要使用逗号隔开。点击...
异地双活场景下的数据双向同步
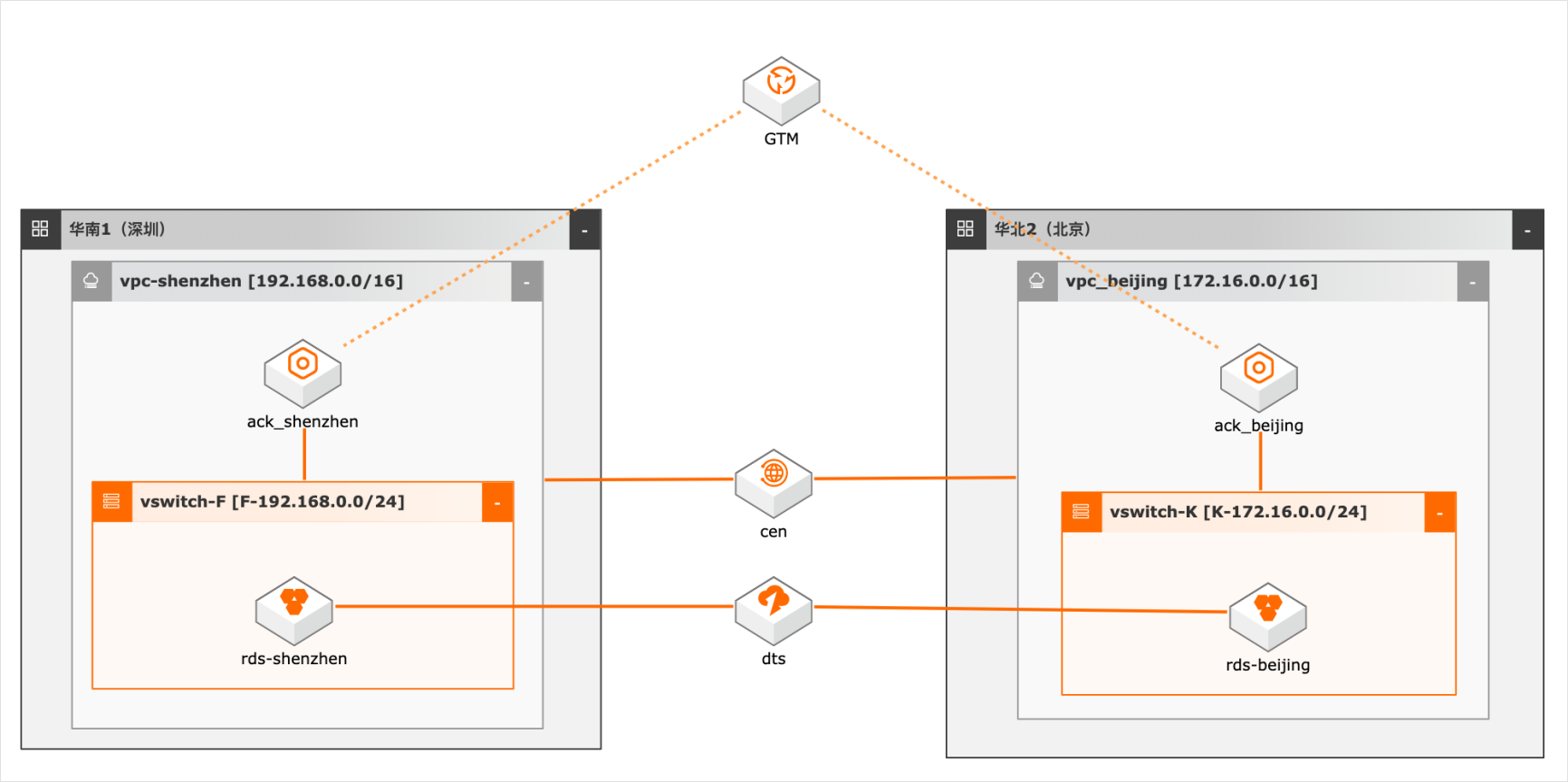
概述 随着客户业务规模的扩大,对系统高可用性要求越来越高,越来越多用户采用异地双活/多活架构,多活架构往往涉及业务侧做单元化改造,本方案仅模拟用户已做单元化改造后的数据双向同步,数据库采用双主架构,本地写本地读,同时又保证双库的数据一致性,为业务增加可用性和灵活性。 适用场景 数据库双向同步 数据库全局ID不冲突 双活架构的数据库建设问题 技术架构 本实践方案基于如下图所示的技术架构和主要流程编写操作步骤: 方案优势 DTS双向同步,采用独立模块避免数据同步占用系统资源。 奇偶ID涉及,避免数据冲突。 DTS多种处理冲突的方式供业务选择。 安全:原生的多租户系统,以项目进行隔离,所有计算任务在安全沙箱中运行。
步骤4 使用”docker build-t ubuntu-16.04/python:3.5.”命令构建镜像。步骤5 点击之前创建的镜像仓库的管理按钮,进入详情页。步骤6 记录拷贝镜像推送到 registry的命令,备用。文档版本:20220209 15 异地双活场景下的数据双向同步 服务部署 步骤7 使用 docker images命令查看 image ID。步骤8 使用步骤 6的命令,将 ...
基于OSS Object FC实现非结构化文件实时处理最佳实践
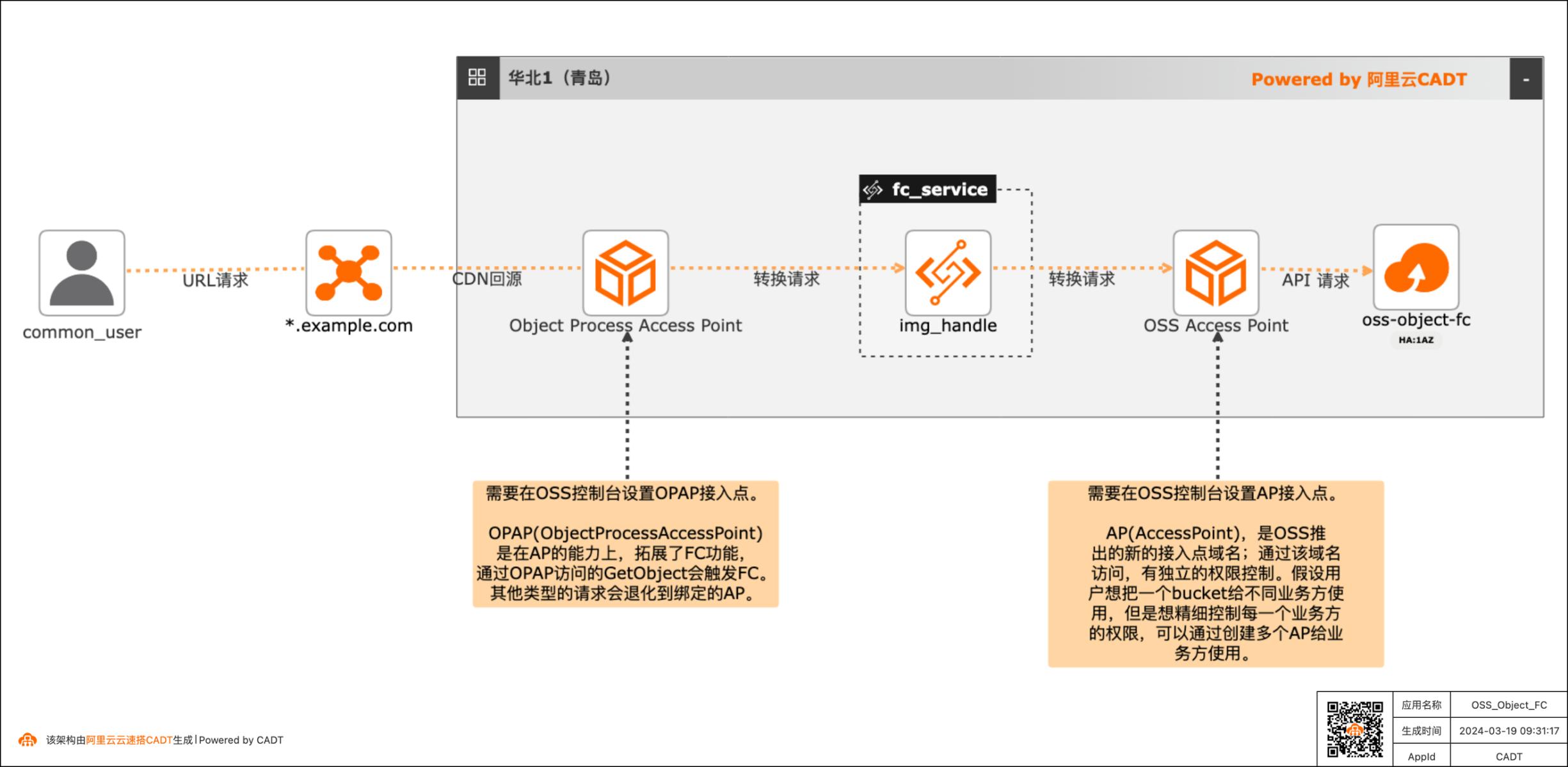
现在绝大多数客户都有很多非结构化的数据存在OSS中,以图片,视频,音频居多。举一个图片处理的场景,现在各种终端种类繁多,不同的终端对图片的格式、分辨率要求也不同,所以一张图片往往会有很多张衍生图,那如果所有的衍生图都存在OSS中,那存储的成本会增加,所以就可以通过OSS Object FC的方案,在不同的终端请求时,对OSS中的原图基于终端的要求做实时处理,然后响应返回,这样OSS中只需要存储原图即可。音视频也有类似的场景。
以上三份Python代码在文档后续内容中会替换到函数计算的函数中。文档版本:20240304 11基于OSSObjectFC实现非结构化文件实时处理最佳实践 场景验证 3.配置对象存储OSS 3.1.创建接入点(AP)步骤1 双击CADT架构图中OSS图标,点击前往控制台,进入阿里云OSS控制台。步骤2 进入接入点列表,点击创建接入点按钮。步骤3 输入接入...
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
Python版本 默认版本为 Python3 付费类型 目前支持的付费类型为包年包月和按量付费 可用区 可用区为在同一地域下的不同物理区域,可用区之间内 网互通。一般选择默认的可用区即可,亦可选择与已购阿 里云产品部署在同一个可用区。ECS实例 由 Master和 Worker两种类型的节点组成:Master节点:主要负责集群资源管理和作业...
VMware迁移DDH

场景描述 介绍本地部署或托管在IDC环境的VMware系统迁移 上云至独立宿主机(DDH)的最佳实践。使用DDH在 云端构建由独享物理服务器组成的资源池,同时配合 ECS成熟稳定的虚拟化技术体系,充分利用云上资源 弹性、按使用付费的优势,快速构建高性能、高可靠 和可快速动态伸缩的虚拟化系统,满足安全、合规、 自定义部署、自带许可证(BYOL)等企业级需求。 解决问题 l云端独享高性能、高可靠、高弹性的物理服务器资源池。 l基于成熟云原生虚拟化技术体系,支持ECS自定义部 署,可在DDH环境和多租户环境间迁移。 l支持自带许可证(BYOL)。 产品列表 l访问控制RAM l专有网络VPC l云服务器ECS l对象存储OSS l专有宿主机DDH l资源编排ROS
安装阿里云版本 cloud-init 安装 python-pip 1.yum makecache 2.yum-y install epel-release 文档版本:20200218 14 企业上云实践 VMware 迁移 DDH|自定义镜像导入 3.yum makecache 4.yum-y install python-pip 文档版本:20200218 15 企业上云实践 VMware 迁移 DDH|自定义镜像导入 下载并解压阿里云版本 cloud-init 1.wget...
大数据近实时数据投递MaxCompute
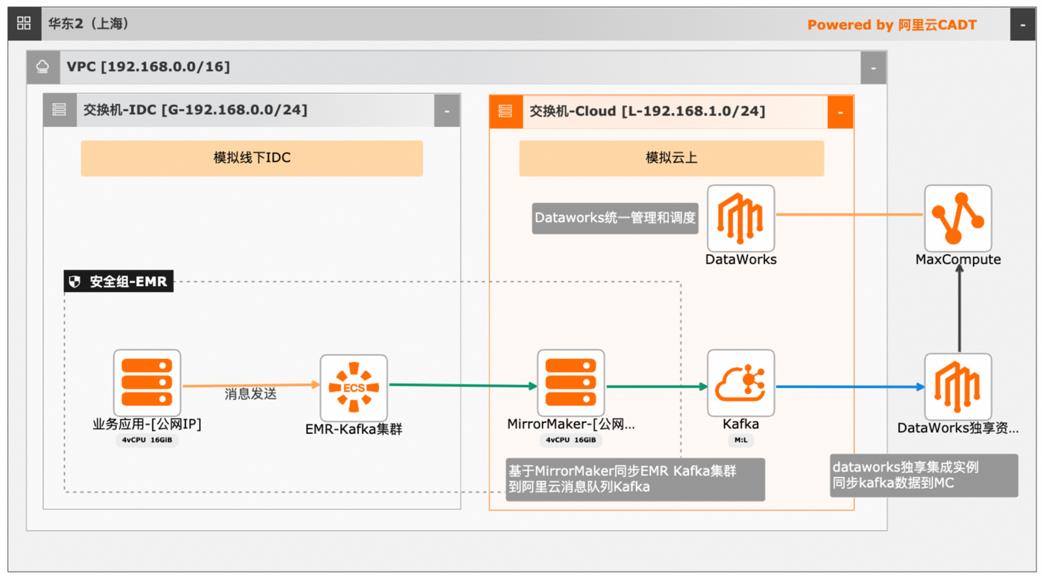
本文介绍离线大数据场景使MaxCompute构建云 上近实时数仓,打通云下数据上云链路,解决数据复杂类型支持和动态分区问题,满足高级数据处理需求的最佳实践。 l混合云环境下,现有业务系统零改造,打通数据上云链路。 l使用UDF实现复杂数据类型转换和数据动态分区。 l使用DataWorks配置周期调度业务流程,数据自动入仓。 l借助MaxCompute优化计算引擎,实现降本增效。 产品列表 云服务器ECS 专有网络VPC 访问控制RAM 数据总线DataHub E-MapReduceEMR DataWorks 大数据计算服务MaxCompute
MaxCompute支持 SQL、MapReduce、UDF(Java/Python)、Graph、基于 DAG的处理、交互式、内存计算、机器学习等计 算类型及 MPI迭代类算法。大幅简化了企业大数据平台的应用架构,具有强数据安 全、低成本、免运维、极致弹性扩展等特点。MaxCompute已与数据集成、DataWorks、QuickBI、机器学习 PAI、ADB、推荐引擎、移动数据...
基于函数计算FC实现阿里云Kafka消息轻量级ETL处理
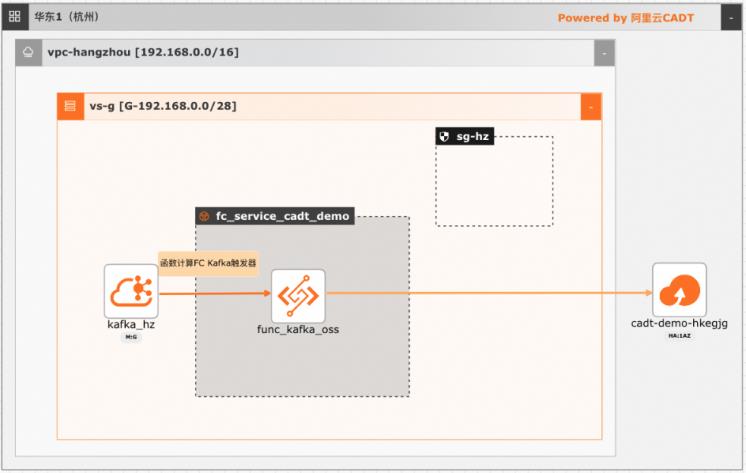
在大数据ETL场景,Kafka是数据的流转中心,Kafka中的数据一般是原始数据,可能存在多种数据混杂的情况,需要进一步做数据清洗后才能进行下一步的处理或者保存。利用函数计算FC,可以快速高效的搭建数据处理链路,用户只需要关注数据处理的逻辑,数据的触发,弹性伸缩,运维监控等阿里云函数计算都已经做了集成,函数计算FC也支持多种下游,OSS/数据库/消息队列/ES等都可以自定义的对接
(函数分为 HTTP请求驱动和事件驱动)运行环境:选择 Python 3.10 代码上传方式:选择使用示例代码。(函数中的代码在后续需要进入函数计算控制 台补充)vCPU规格:0.35c(函数计算有多种 CPU资源规格,可以根据实际情况自行选择)内存规格:512MB(函数计算有多种内存资源规格,可以根据实际情况自行选择)硬盘大小:512MB...
- 产品推荐
- 这些文档可能帮助您