自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
对象存储 OSS 3.Hive跨版本迁移到 Databricks数据洞察 专有网络 VPC 使用 Delta表查询以提高查询效率。阿里云最佳实践分享群 最佳实践频道 如二维码过期,请搜索群号:31852400 云服务器 ECS(产品名称)文档模板(手册名称)/文档版本信息 阿里云 自建Hive 数据仓库跨版本迁移到 阿里云Databricks数据洞察 文档版本:...
PolarDB 应对大并发复杂查询实践
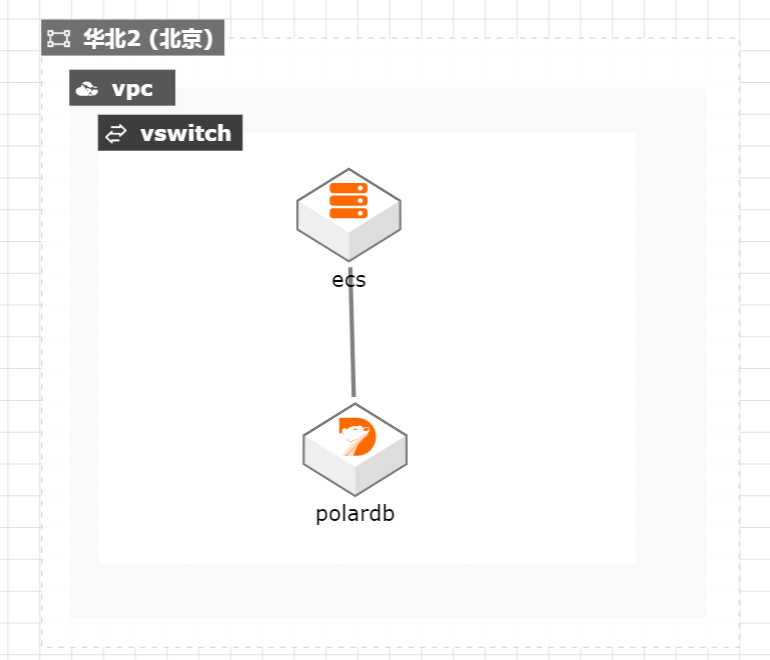
MySQL架构是单线程处理SQL,遇到大并发复杂查询时,需要排队长时间等待,容易形成慢查询,影响业务。PolarDB并发查询能力可以很好解决此问题。
附录 测试环境安装.26 4.1.TPC-H安装.26 文档版本:20210412 IV PolarDB如何应对大并发复杂查询 最佳实践概述 最佳实践概述 概述 在面向 C端或者多个小 B端的 SaaS化服务场景下,数据库经常面临大并发的复杂查 询业务压力,比如餐饮平台的商户随机查看订单统计情况;ERP服务平台面临大量零 售商户查看库存报表情况。此类...
利用交互式分析(Hologres)进行数据查询
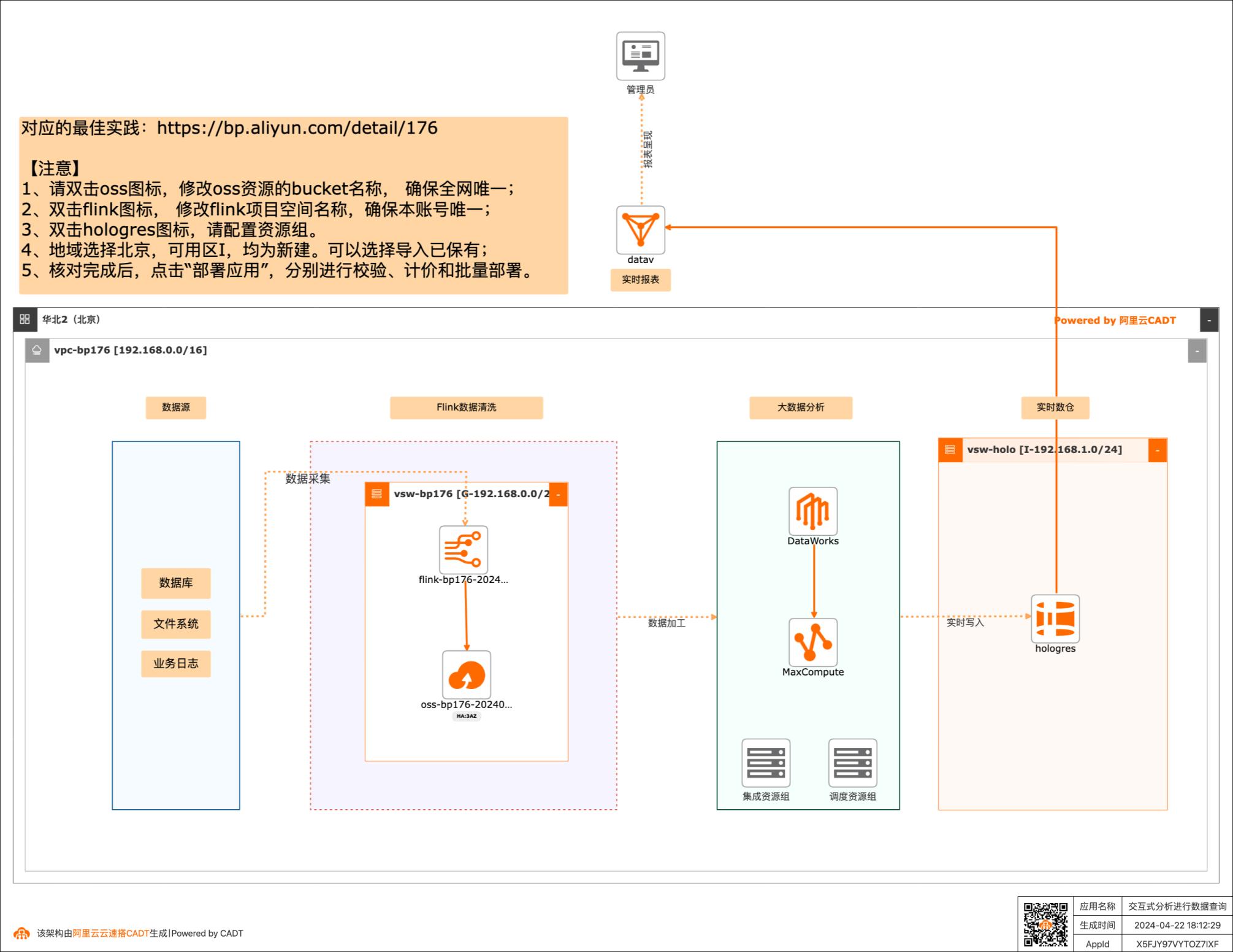
场景描述:随着收集数据的方式不断丰富,企业信息化 程度越来越高,企业掌握的数据量呈TB、 PB或EB级别增长。同时,数据中台的快 速推进,使数据应用主要为数据支撑、用户 画像、实时圈人及广告精准投放等核心业务 服务。高可靠和低延时地数据服务成为企业 数字化转型的关键。 Hologres致力于低成本和高性能地大规模 计算型存储和强大的查询能力,为您提供海 量数据的实时数据仓库解决方案和实时交 互式查询服务。 解决问题 1.加速查询MaxCompute数据 2.快速搭建实时数据仓库 3.无缝对接主流BI工具 产品列表 MaxCompute Hologres 实时计算Flink 专有网络VPC DataWorks DataV
基于交互式分析工具进行数据查询最佳实践 业务架构 场景描述 随着收集数据的方式不断丰富,企业信息化程度越来越高,企业掌握的数据量呈TB、PB或EB级别增长。同时,数 据中台的快速推进,使数据应用主要为数据支撑、用户画 像、实时圈人及广告精准投放等核心业务服务。高可靠和 低延时地数据服务成为企业数字化转型的关键。...
- 产品推荐
- 这些文档可能帮助您