云原生数据湖分析DLA
阿里云云原生数据湖分析是新一代大数据解决方案,采取计算与存储完全分离的架构,支持对象存储(OSS)、RDS(MySQL等)、NoSQL(MongoDB等)数据源的消息实时归档建仓,提供Presto和Spark引擎,满足在线交互式查询、流处理、批处理、机器学习等诉求。内置大量优化+弹性,比开源自建集群最高降低50%+的成本,最快可1分钟级拉起300个计算节点,快速满足业务资源要求。
海量数据分析慢,自建数仓成本高.云原生数据湖分析提供数据采集、快速查询分析及存储的全链路支持,全站加速、日志存档分析一步到位,实现数据驱动业务增长.日志返还全链路产品化,无需关注中间ETL过程,直接拿到清洗后的结果日志表.快速搭建报表,例如分析错误码分布、分析用户访问链路,实现链路可追溯.满足日志合规需求...
来自:
云产品
云原生数据仓库AnalyticDB MySQL数据仓库
阿里云云原生数据仓库AnalyticDB MySQL版(简称AnalyticDB)是融合数据库、大数据技术于一体的云原生企业级数据仓库平台。云原生数据仓库AnalyticDB MySQL版支持数据实时写入和同步更新、实时计算和实时服务,可用于构建企业级报表系统、数据仓库和数据服务引擎。
——打造一站式实时湖仓,可替换CDH/TDH/开源自建/云服务-Spark/Hive/Presto等.AnalyticDB MySQL湖仓版重磅发布.PB级云原生实时湖仓,高度兼容MySQL,毫秒级更新,亚秒级查询,打破湖仓孤岛,数据湖的规模,数据库的体验.最佳实践和社区文章.AnalyticDB MySQL湖仓版架构升级,持续释放技术红利!10倍性能提升!AnalyticDB ...
来自:
云产品
基于Flink的资讯场景实时数仓
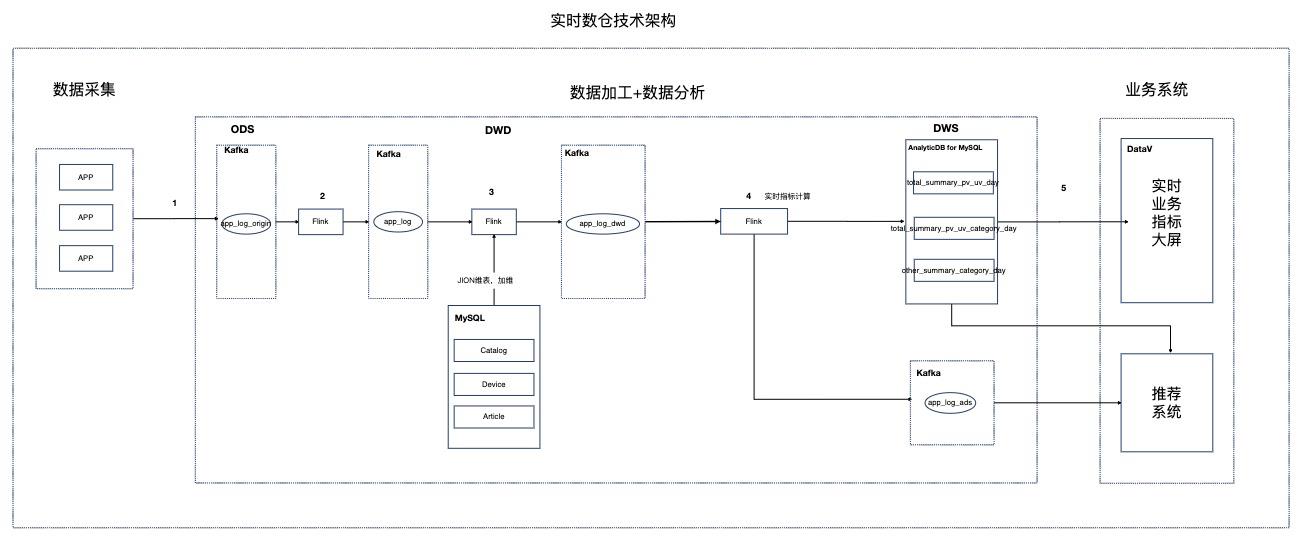
场景描述 本实践针对资讯聚合类业务场景,Step by Step介绍 如何搭建实时数仓。 解决问题 1.如何搭建实时数仓。 2.通过实时计算Flink实现实时ETL和数据流。 3.通过实时计算Flink实现实时数据分析。 4.通过实时计算Flink实现事件触发。 产品列表 实时计算 专有网络VPC 云数据库RDSMySQL版 分析型数据库MySQL版 消息队列Kafka 对象存储OSS NAT网关 DataV数据可视化
而整个 ETL过程,是实时数 仓架构设计上非常重要的一环,该环节要做到延时小,成本低,可扩展性好,业务 指标计算准确。在系统选型上,推荐使用实时计算 Flink对数据进行处理,因为 Flink具有强大的 数据处理能力,低延时,高吞吐,能够保证业务产出。文档版本:20220223(发布日期)5 基于 Flink的资讯场景实时数仓 实时...
云数据库ClickHouse
云数据库ClickHouse 是阿里云提供的分布式实时分析型列式数据库服务。具有高性能、开箱即用、企业特性支持。广泛应用于流量分析、广告营销分析、行为分析、人群划分、客户画像、敏捷BI、数据集市、网络监控、分布式服务和链路监控等业务场景。
全面数据链路接入,快速构建实时数仓.全方位高效数据接入.自动弹性扩缩.设定弹性区间后,基于负载的自动弹性扩容.提供磁盘、CPU、内存、IOPS、数据库连接、读写量、TPS、ZK、慢SQL等全方位监控诊断体系支撑;数据库领域专家支持,实时解惑答疑.在线数据库管理.支持在线账号管理,数据字典配置,网络管理,集群参数配置,慢...
来自:
云产品
云数据库 Cassandra 版
Cassandra是连续9年DB-Engines排名第一的宽表数据库,支持类SQL语法CQL,开发体验类似MySQL,可扩展PB级存储。推出企业版Lindorm for Cassandra云原生多模数据库,采用存储计算分离架构,支持海量数据的低成本存储和按需付费,具备更高性价比和更为丰富的企业级功能。
数据统一管理,湖仓一体.一分钟300 Spark节点弹性扩展,满足ETL、机器学习等需求;Presto满足在线交互式需求.Serverless分析引擎Spark&Presto.基于Spark RDD构建了统一的时空数据模型,方便建模.Ganos时空数据分析.综合治理,支持丰富的自研、开源引擎.Dataworks构建数据湖统一开发平台.云数据库Cassandra版支持节点升配及...
来自:
云产品
自建Hive数仓迁移到阿里云EMR
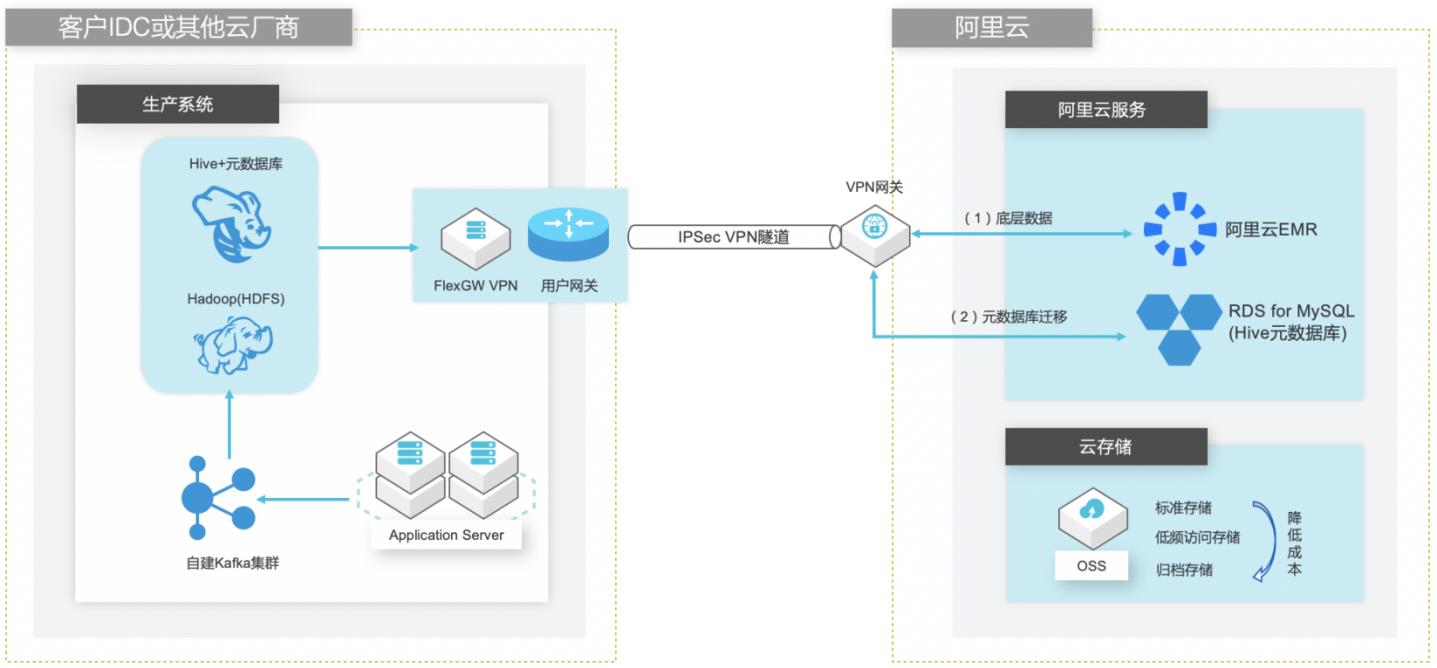
场景描述 客户在IDC或者公有云环境自建Hadoop集群构 建数据仓库和分析系统,购买阿里云EMR集群之 后,涉及到将数据仓库和Hive元数据的数据库迁 移上云。目前主流Hive数据仓库迁移场景为1.x 版本迁移到阿里云EMR(Hive2.x版本),涉及到 数据订正更新步骤。 解决的问题 Hive数据仓库的数据迁移方案 Hive元数据库的迁移方案 Hive跨版本迁移后的数据订正 产品列表 E-MapReduce,VPC,ECS,OSS,VPN网关。
自建 Hive数据仓库跨版本迁移到阿里云 EMR 场景描述 解决的问题 客户在IDC或者公有云环境自建Hadoop集群构建 Hive数据仓库的数据迁移方案 数据仓库和分析系统,购买阿里云 EMR集群之后,Hive元数据库的迁移方案 涉及到将数据仓库和Hive元数据的数据库迁移上 Hive跨版本迁移后的数据订正 云。目前主流 Hive数据仓库迁移场景...
数据可视化DataV
数据可视化DataV是阿里云一款数据可视化应用搭建工具,旨让更多的人看到数据可视化的魅力,帮助非专业的工程师通过图形化的界面轻松搭建专业水准的可视化应用,满足您会议展览、业务监控、风险预警、地理信息分析等多种业务的展示需求。
实时数仓 Hologres.业务监控看板.跨系统数据一屏统管.DataV在数字孪生城市领域,通过统一孪生体定义、智能生成算法、实时感知交互、交通人流仿真以及大规模三维渲染能力,帮助用户构建城市全要素资源平台,实现对城市要素的精细化管理;城市模型快速更新能力,利用地物识别算法、智能生成算法进行城市要素的三维构建,为...
来自:
云产品
云数据库产品总览(瑶池)
阿里云提供完善的数据库解决方案,多款数据库产品,满足99%的业务场景,荣获Gartner、信通院等国内外多项认证。轻松满足高可靠、高可用性、高性能等数据库需求;运维工作量大幅减少,让企业一站式享受数据上云及分布式架构的技术红利!
通过PolarDB多主集群、HTAP和透明冷热数据分层的方案,升级了SaaS数据库架构,解决了易仓跨境SaaS遇到的单实例海量表维护困难,租户资源调配和利用低效,数据量大存储成本高,数据库实例多数据集成成本高,店铺和商品多维统计分析性能差等一系列数据库痛点。不仅大幅提升数据库资源调配效率和利用率,而且实现了持续降本...
来自:
云产品
云数据库MongoDB版
阿里云云数据库MongoDB版是完全兼容MongoDB协议、高度兼容DynamoDB协议的在线文档型数据库服务。支持单节点、双节点、副本集和分片集群四种部署架构,能够满足不同的业务场景需要。
云数据库 Redis 版.AnalyticDB MySQL 是基于湖仓一体架构打造的实时湖仓,高度兼容MySQL,毫秒级更新,亚秒级查询.云原生数据仓库 AnalyticDB MySQL 版.云数据库 MongoDB 版包年包月全系列规格价格下调.MongoDB 新用户专享1个月免费试用.MongoDB 推出单节点1核2GB 小规格,最低仅需70元/月.阿里云联合MongoDB 助力游戏企业...
来自:
云产品
MySQL数据库上云选型解决方案
MySQL数据库上云选型解决方案,MySQL数据库成为近十年来数据库使用范围最广,数据库生态最好的开源数据库,本方案以MySQL数据库上云的各种场景为切入点,包括数据库的扩展性、数据库水平拆分、数据库垂直拆分、高弹性数据库、数据库大促支持、MySQL数据库海量数据分析等向上云的企业客户介绍如何选择适合企业的MySQL生态数据库。
基于PolarDB的高弹性数据库解决方案,给企业客户提供分钟级弹性能力、百TB存储能力、读写分离读节点延迟低等核心能力,助力有大促属性的客户轻松应对业务高峰.MySQL数据库高弹性、大促场景.ADB一键建仓.基于分析型数据库MySQL版构建的OLAP数据库解决方案,给企业提供PB级实时数据仓库能力,可以毫秒级针对万亿级数据进行...
来自:
解决方案
金融专属大数据workshop

实践目标 学习搭建一个实时数据仓库,掌握数据采集、存储、计算、输出、展示等整个业务流程。 整个实时数据仓库系统全部基于阿里云产品进行架构搭建,用户可以掌握并学会运用各个服务组件及各个组件之间如何联动。 理解阿里云原生实时离线一体数仓解决方案架构以及掌握交付落地的实践使用方法。 前置知识要求 熟练掌握SQL语法 对大数据体系系统知识有一定的了解
详见:https://www.aliyun.com/product/ecs DataHub:数据总线(DataHub)服务是阿里云提供的流式数据(StreamingData)服 务,它提供流式数据的发布(Publish)和订阅(Subscribe)的功能,让您可以轻松构 建基于流式数据的分析和应用。详见:https://www.aliyun.com/product/datahub 实时计算 Flink 版:实时计算 Flink 版...
来自:
最佳实践
相关产品:块存储,云服务器ECS,云数据库RDS MySQL 版,对象存储 OSS,弹性公网IP,数据传输,DataWorks,大数据计算服务 MaxCompute,DataV数据可视化,实时计算,数据总线,Quick BI,Hologres
互联网电商行业离线大数据分析

电商网站销售数据通过大数据分析后将业务指标数据在大屏幕上展示,如销售指标、客户指标、销售排名、订单地区分布等。大屏上销售数据可视化动态展示,效果震撼,触控大屏支持用户自助查询数据,极大地增强数据的可读性。
大数据开发治理平台DataWorks:基于阿里云ODPS/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。作为阿里巴巴数据中台的建设者,互联网电商行业离线大数据分析 最佳实践概述 DataWorks从2009年起不断沉淀阿里巴巴大数据建设方法论,同时与数万名政务/金融/零售/互联网/...
自建K8S迁移镜像、应用至阿里云ACK最佳实践

云原生技术K8S以其易管控,自动化操作,自修复等特点充分满足了企业的需求,越来越多的企业都加入容器化这个队伍中。但随着技术的更新迭代,自建的K8S相关的容器镜像服务、集群管理、稳定性保障也让企业IT人员感觉到压力,所以上云成了一些企业的选择,将底层的IAAS基础设施和K8S的基础PASS能力交给阿里云来管理,企业本身抽出更多精力聚焦业务的创新。针对以上需求通过使用image-syncer、velero来介绍如何平滑、便捷的迁移自建的K8S镜像和应用至阿里云容器镜像服务和ACK。 针对以上需求场景通过使用image-syncer、velero来介绍如何平滑、便捷的迁移自建的K8S镜像和应用至阿里云容器镜像服务和ACK;本文通过使用河源的ECS自建K8S集群和Harbor镜像仓库来模拟IDC环境
阿里云 企业上云实践 自建 K8S迁移镜像、应用至 ACK 最佳实践 自建 K8S迁移镜像、应用至阿里云 ACK 文档版本信息 文档版本信息 文本信息 属性 内容 文档名称 自建 K8S镜像、应用迁移阿里云 ACK 文档编号 177 文档版本 V1.0 版本日期 2020-05-25 文档状态 内部发布 制作人 吉运 审阅人 川知/明誉 文档变更记录 版本编号 日期...
EMR本地盘实例大规模数据集测试
场景描述 阿里云为了满足大数据场景下的存储需求,在云 上推出了本地盘D1机型,这个系列提供了本地 盘而非云盘作为存储,提高了磁盘的吞吐能力, 发挥Hadoop的就近计算优势。阿里云EMR 产品针对本地盘机型,推出了一整套的自动化运 维方案,帮助用户方便可靠地使用本地盘机型, 不需要关注整个运维过程同时数据的高可靠和 服务的高可用。 解决问题 1.云盘多份冗余数据导致成本高 2.磁盘吞吐量不高 3.节点的高可靠分布问题 4.本地盘与节点的故障监控问题 5.数据迁移时自动决策问题 6.自动故障节点迁移与数据平衡问题 产品列表 EMR(E-MapReduce) 本地盘 VPC
EMR:E-MapReduce(EMR)是构建在阿里云云服务器 ECS上的开源 Hadoop、Spark、Hive、Flink 生态大数据产品,提供用户在云上使用开源技术建设数据仓 库、离线批处理、在线学习、即时查询、机器学习等场景下的大数据解决方案。PT测试:Power Test(PT)功耗测试,TPC-DS用于大数据性能测试的方法。大数据实例本地盘:阿里云为了...
数据库自动扩缩容和自动SQL优化
方案使用数据库自治服务DAS实现RDS MySQL数据库的自动扩缩容和自动SQL优化,将基于人工的手动式运维转变为基于智能的主动式持续优化,具有数据库运维成本低,服务稳定性高的优势。
方案部署方案权益优惠购买免费试用解决方案推荐RDS+ClickHouse构建一站式HTAP通过融合MySQL和ClickHouse的数据同步能力,用户可以在一个可视化窗口中简单灵活地配置和管理实时数据同步,这为业务报表统计、交互式运营分析和实时数仓构建提供了便利。在这个窗口中,用户可以轻松选择需要同步的表和字段,设置同步频率和条件...
来自:
解决方案
云速搭部署Flink应用

本水煎通过云速搭实现一个DataHub+Flink的实时流计算引擎架构,利用DataHub收集原始数据,推送到Flink进行基于流式数据的分析和应用。
更多信 息,详见:https://www.aliyun.com/product/bigdata/sc 数据总线 DataHub:是阿里云提供的流式数据(Streaming Data)服务,它提供流 式数据的发布(Publish)和订阅(Subscribe)的功能,让您可以轻松构建基于流式数 据的分析和应用。详见:https://www.aliyun.com/product/datahub 对象存储 OSS(Object Storage Service...
PolarDB 应对大并发复杂查询实践
MySQL架构是单线程处理SQL,遇到大并发复杂查询时,需要排队长时间等待,容易形成慢查询,影响业务。PolarDB并发查询能力可以很好解决此问题。
而使用数据仓库或者大数据手段处理此类,虽然单个复杂查询效率会比 OLTP数据库高很多,但大并发请求对数仓类产品是非常不友好的,CPU等资源极易 被抢占一空。PolarDB MySQL 8.0采用开启并发度的方式,改变单线程处理 SQL的架构,充分利 用多核 CPU多线程优势,利用多线程并行处理复杂查询,有效解决大并发复杂查询的 问题,...
云Clickhouse冷热数据分层存储
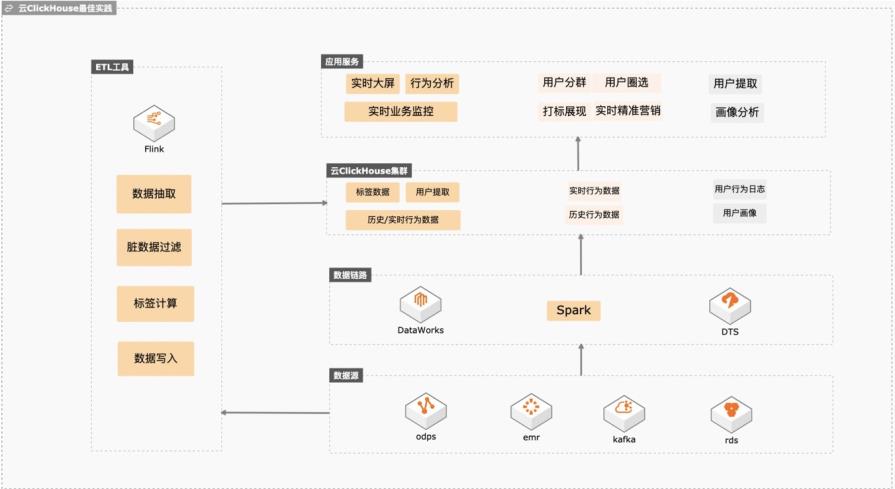
基于云ClickHouse可以给电商、游戏、互联网以及其他行业提供高性能、高稳定性、低维护成本、高性价比的实时数据分析、精准营销、业务运营、业务分析、业务预警、业务营销、数仓加速等场景化方案,本实践会向客户提供数据库低维护成本、数据库链路构建、冷热分层存储、快熟分析等操作实践。 解决问题 1. 维护成本低不用建设维护体系,稳定性高,数据倾斜自动均衡。 2. 完善的数据同步链路,可以平滑将业务库、大数据、日志服务的数据同步到Clickhouse,降低研发成本。 3. 平滑升级版本,业务中断小。 冷热分层后透明读取,帮客户节约整体数据存储成本。
云 ClickHouse冷热数据分层存储最佳实践 技术架构 场景描述 基于云 ClickHouse可以给电商、游戏、互联网以及其他行业提供高性能、高稳定 性、低维护成本、高性价比的实时数据分 析、精准营销、业务运营、业务分析、业 务预警、业务营销、数仓加速等场景化方 案,本实践会向客户提供数据库低维护成 本、数据库链路构建、冷热...
- 产品推荐
- 这些文档可能帮助您