基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测

本篇最佳实践先创建EMR集群作为数据湖对象,Hive元数据存储在DLF,外表数据存储在OSS。然后使用阿里云数据仓库MaxCompute以创建外部项目的方式与存储在DLF的元数据库映射打通,实现元数据统一。最后通过一个毒蘑菇的训练和预测demo,演示云数仓MaxCompute如何对于存储在EMR数据湖的数据进行加工处理以达到业务预期。
基于统一的元数据管 理能力,在完全兼容HDFS文件系统接口的同时,提供充分的POSIX能力支持,能更 好地满足大数据和AI等领域的数据湖计算场景。基于湖仓一体架构使用MaxCompute对OSS湖数据分析预测 1.4.检查EMR集群 本示例使用CADT架构模式创建了EMR集群,配置Hive元数据存储到数据湖构建。步骤1 快速登录到EMR控制台:点击...
云原生大数据计算服务MaxCompute
阿里云云原生大数据计算服务MaxCompute是面向分析的企业级云数仓,作为一体化大数据智能计算平台ODPS的大规模批量计算引擎,MaxCompute以 Serverless 架构提供快速、全托管的在线数据仓库服务,使您经济高效的分析处理海量数据,进行敏捷的业务洞察。
集成对数据湖(OSS或Hadoop HDFS)的访问分析,支持外表映射、Spark直接访问方式开展数据湖分析;在一套数仓服务和用户接口下,实现湖与仓的关联分析.支持流式采集和近实时分析.支持流式数据实时写入并在数据仓库中开展分析;与云上主要流式服务深度集成,轻松接入各种来源流式数据;高性能秒级弹性并发查询,满足近实时...
来自:
云产品
实时数仓Hologres
Hologres(原交互式分析)是一站式实时数据仓库引擎,支持海量数据实时写入、实时更新、实时分析,支持标准SQL(兼容PostgreSQL协议),支持PB级数据多维分析(OLAP)与自助分析(Ad Hoc),支持高并发低延迟的在线数据服务(Serving),与MaxCompute、Flink、DataWorks深度融合,提供离在线一体化全栈数仓解决方案。
支持数据湖场景,支持JSON等半结构化数据,OSS、DLF简易入仓.诺亚面向高净值客户提供复杂资产配置服务,高端金融服务的业务属性天然带有“行少列多”的数据特点,需求极为复杂,是数据服务的深水区,如果不是抱着用数据改变行业的决心和过硬的技术,是很难服务好金融行业客户的。Hologres的小伙伴不仅亲自来诺亚为我们提供...
来自:
云产品
EMR HBase on OSS存算分离集群快速恢复
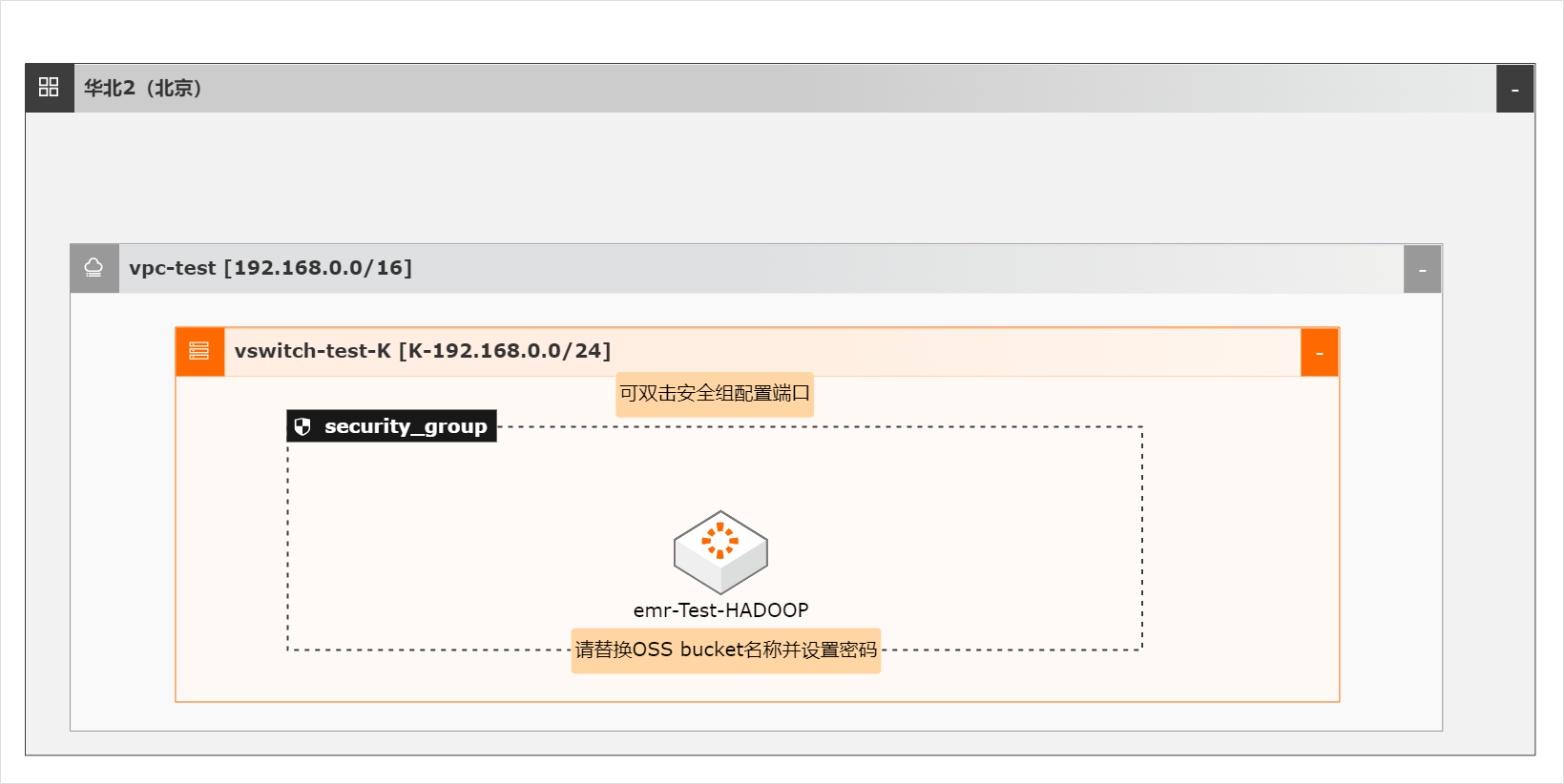
OSS-HDFS服务(JindoFS服务)是一款云原生数据湖存储产品。基于统一的元数据管理能力,在完全兼容HDFS文件系统接口的同时,提供充分的POSIX能力支持,能更好地满足大数据和AI等领域的数据湖计算场景。
基于统一的元数据管理能力,在完全兼容 HDFS文件系统接口的同时,提供充分的 POSIX能力支持,能更好地 满足大数据和 AI 等 领 域 的 数 据 湖 计 算 场 景。详见:https://help.aliyun.com/document_detail/405089.html EMR:开源大数据平台 E-MapReduce(简称“EMR”)是云原生开源大数据平台,向客户提供简单易集成的 ...
湖仓一体架构EMR元数据迁移DLF
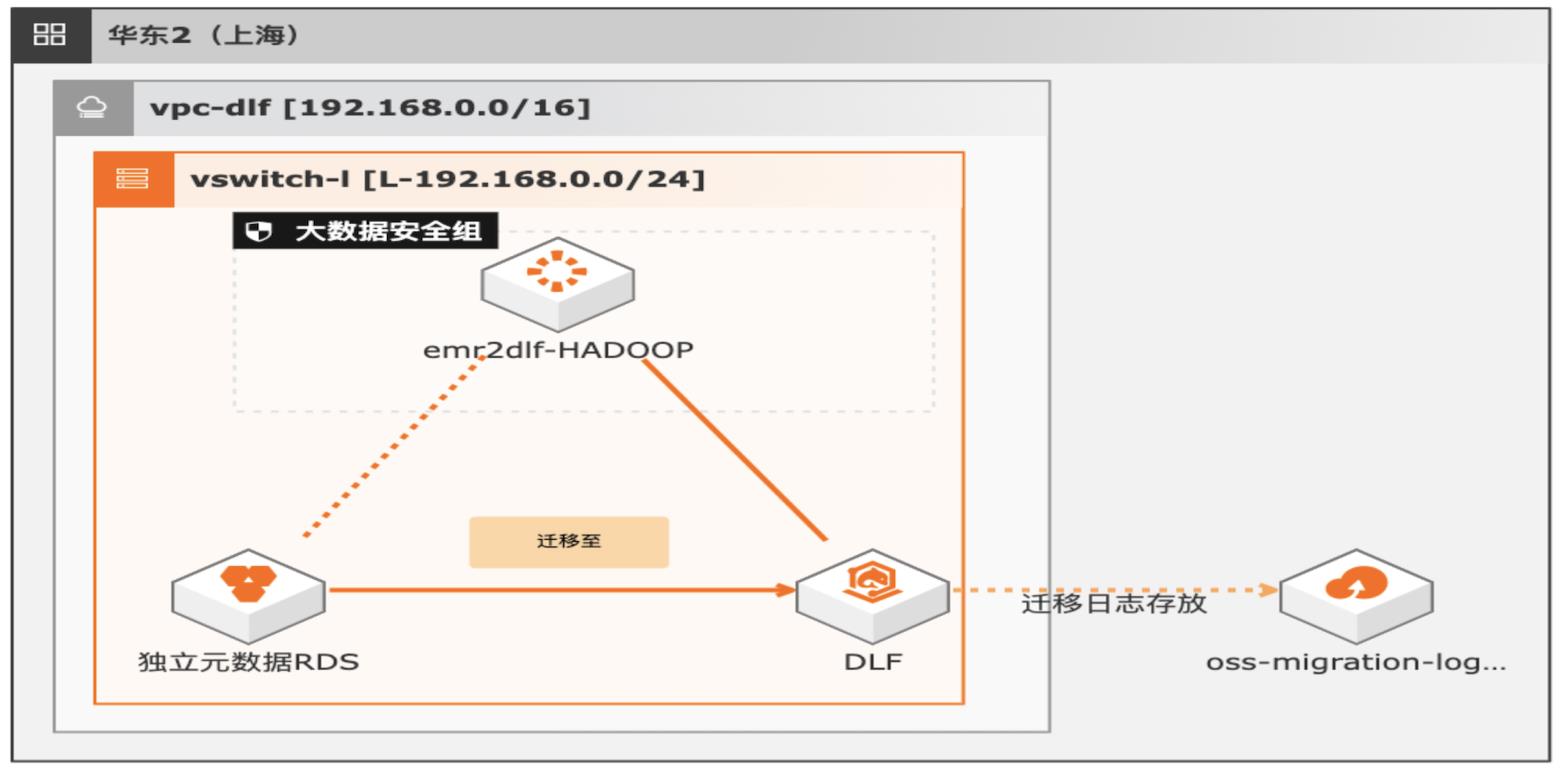
通过EMR+DLF数据湖方案,可以为企业提供数据湖内的统一的元数据管理,统一的权限管理,支持多源数据入湖以及一站式数据探索的能力。本方案支持已有EMR集群元数据库使用RDS或内置MySQL数据库迁移DLF,通过统一的元数据管理,多种数据源入湖,搭建高效的数据湖解决方案。
数据湖构建(Data Lake Formation,DLF)作为云原生数据湖架构核心组成部分,帮助用户简单快速地构 建云原生数据湖解决方案。数据湖构建提供湖上元数据统一管理、企业级权限控 制,并无缝对接多种计算引擎,打破数据孤岛,洞察业务价值。(https://www.aliyun.com/product/bigdata/dlf)云速搭 CADT:是一款为上云应用提供...
数据湖-在线学习场景数据分析

场景描述 本场景以在线教育中一个答题闯关类的应用为 例,使用WebServer来模拟演示这类日志数据 的分析处理。通过Nginx和Pythonflask搭建 WebServer,模拟应用中的关键页面,比如登 录、课程内容等,之后构造若干用户使用的模拟 日志数据,投递到数据湖进行分析后获取应用 PV、UV、课程内容访问排行、平均得分等等。 解决问题 基于数据湖(EMR+OSS)搭建大数据平台。 EMR和OSS使用和配置。 数据统一存储到OSS。 产品列表 E-MapReduce 对象存储OSS 云服务器ECS 访问控制RAM 专有网络VPC
通过Nginx和Pythonflask搭建WebServer,模拟应用中的关 键页面,比如登录、课程内容等,之后构造若干用户使用的模拟日志数据,投递到数 据湖进行分析后获取应用PV、UV、课程内容访问排行、平均得分等等。方案优势 支持超过10亿条元数据规模的数据管理,同时支持高可靠和高可用。 支持元数据实时备份和重建集群快速恢复...
云原生数据湖分析DLA
阿里云云原生数据湖分析是新一代大数据解决方案,采取计算与存储完全分离的架构,支持对象存储(OSS)、RDS(MySQL等)、NoSQL(MongoDB等)数据源的消息实时归档建仓,提供Presto和Spark引擎,满足在线交互式查询、流处理、批处理、机器学习等诉求。内置大量优化+弹性,比开源自建集群最高降低50%+的成本,最快可1分钟级拉起300个计算节点,快速满足业务资源要求。
通过控制台的简单配置,即可完成数据同步导入OSS,将原来占用RDS计算资源的部分业务,迁移到数据湖分析+OSS上来,降低了对RDS业务库的压力.丰富的生态支持,支持Microstrategy、MySQL Workbench等多种GUI管理工具,支持QuickBI、Tableau、DataV等多种可视化工具.兼容MySQL协议,基于SQL分析,没有学习成本,屏蔽了底层技术...
来自:
云产品
AnalyticDB MySQL湖仓版的用户运营分析实践
本方案只需一个湖仓版实例就能完成“数据入湖+作业开发+在线分析”的一站式用户运营数据分析,提供更高效的数据处理方案与更低的数据存储成本。
产品解决方案文档与社区权益中心定价云市场合作伙伴支持与服务了解阿里云备案控制台AnalyticDB MySQL湖仓版的用户运营分析实践方案介绍方案优势应用场景方案部署方案权益AnalyticDB MySQL湖仓版的用户运营分析实践方案使用AnalyticDB MySQL湖仓版实现对应用数据的分析。过去的方案中,为了不影响在线分析的性能和稳定性,...
来自:
解决方案
自建Hive数据仓库跨版本迁移到阿里云Databricks数据洞察

场景描述 客户在IDC或者公有云环境自建Hadoop集群构建数据仓库和分析系统,购买阿里云Databricks数据洞察集群之后,涉及到数仓数据和元数据的迁移以及Hive版本的订正更新。 方案优势 1. 全托管Spark集群免运维,节省人力成本。 2. Databricks数据洞察与阿里云其他产品(OSS、RDS、MaxCompute、EMR)进行深度整合,支持以这些产品为数据源的输入和输出。 3. 使用Databricks Runtime商业版引擎相比开源Spark性能有3-5倍的提升。 解决问题 1. Hive数仓数据迁移OSS方案。 2. Hive元数据库迁移阿里云RDS方案。 3. Hive跨版本迁移到Databricks数据洞察使用Delta表查询以提高查询效率。
使用 oss对象存储方案,计算存储分离节省客户存储成本,并为以后数据湖和多 计算框架做铺垫。推荐客户将数据格式存储为 Parquet,性能会有非常大优化。Databricks 数据洞察与阿里云其它产品(Kafka、Redis、MongoDB、Elasticseach、RDS和 MaxCompute等)进行了深度整合,支持以这些产品作为 Spark计算引擎的输入源或者输出...
数据管理与服务
数据管理与服务作为阿里云产品六大版块之一,面向不同业务场景,阿里云提供数据存储、分析、应用等全链路能力,满足企业客户全方位的数据处理需求,实现计算和存储分离、资源解耦、数据移动减化,用以满足行业快速发展的需求和趋势,利用数据重塑其业务。
数据管理与服务包含数据库、大数据计算、数据开发、治理和应用类产品.数据管理与服务.MongoDB与阿里云迎来合作三年的“里程碑”,双方在庆祝合作硕果的同时,重申将继续携手,致力将 MongoDB现代化数据库的创新成果与阿里云相结合,通过充分释放云数据库的潜能,赋能各行业客户拓展开发数据价值.MongoDB与阿里云携手开启下...
来自:
云产品
Databricks数据洞察
阿里云Databricks数据洞察是基于Apache Spark的全托管数据分析平台, 内核采用更高效、稳定的商业版Databricks Runtime和Delta Lake。可满足数据分析师、数据工程师和数据科学家在大数据场景下对数据湖分析、实时数仓、离线数仓、BI数据分析、AI机器学习等需求
满足高性能、高稳定性、可弹性的计算需求.Databricks Delta Lake为数据湖分析提供了ACID事务能力,轻松处理包含数十亿文件的PB级表的元数据信息,实现了批流一体的数据处理方式.同时满足数据科学家、数据工程师以及业务分析师的计算需求,提供交互式的协同分析工作平台.计算存储分离,减少数据冗余,实现多引擎间的数据共享...
来自:
云产品
MaxCompute湖仓一体方案
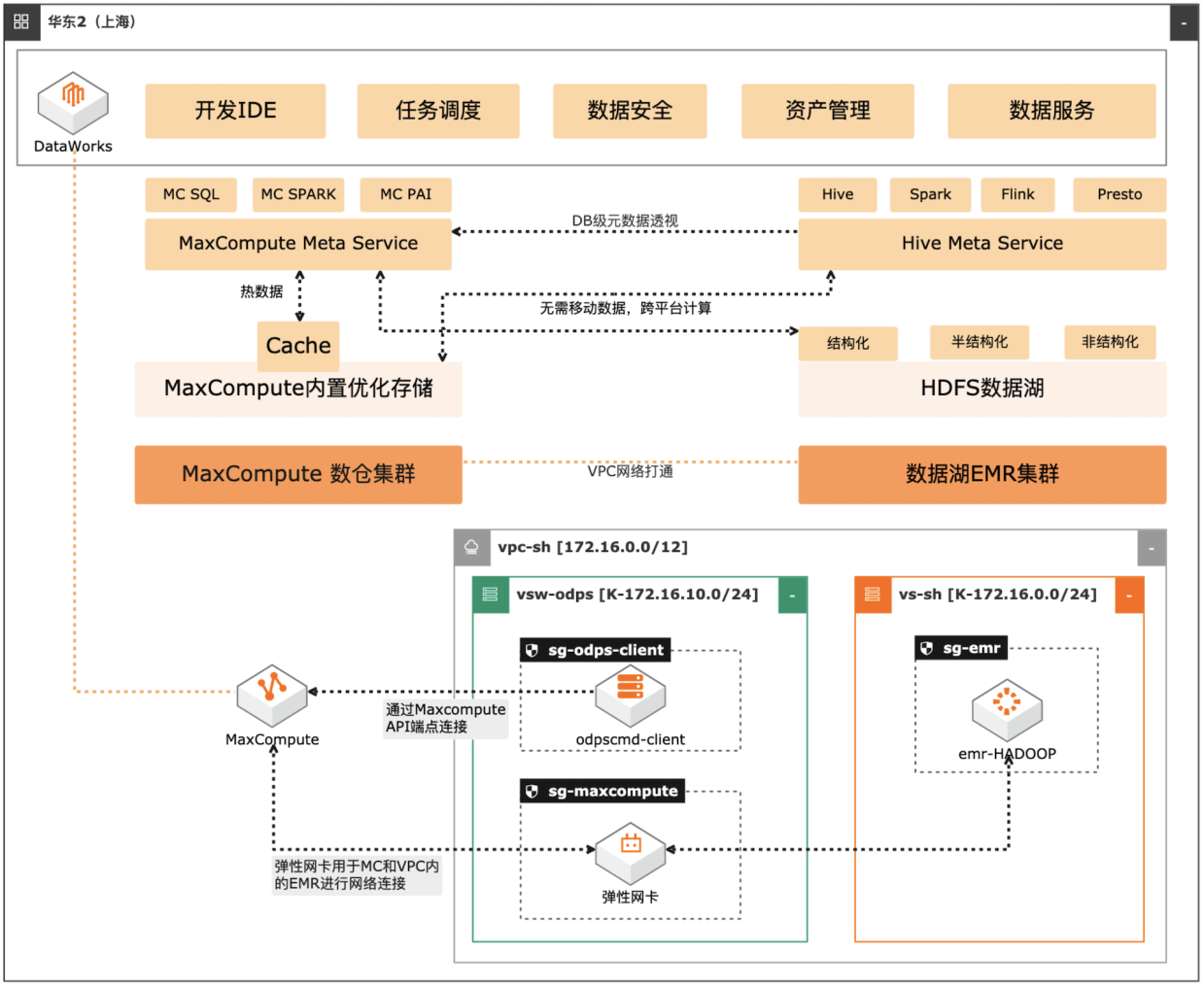
场景描述 自建数据湖与云数仓的融合解决方案,将 MaxCompute与自建的Hive集群做数据打 通,通过存储共享,元数据镜像等方式,解 决传统模式下的存储冗余,计算资源弹性能 力弱的痛点。可大幅度增强系统的资源弹 性,解决业务高峰期计算资源不足的问题。 方案优势 1.业务无侵入性:现有业务无需改造。 2.性能优化:MaxCompute在SQL上做 了大量优化与能力沉淀,可提高SQL 运行性能,降低计算成本。 3.灵活管理:元数据实时同步,无需额外 管理数据同步任务。 4.资源弹性:利用MaxCompute计算池 弹性进行海量数据计算。 解决问题 1.增强业务高峰期的资源弹性。 2.优化自建数据湖的数据治理能力。 3.减少跨平台数据处理的存储冗余。 产品列表 专有网络VPC 云服务器ECS 访问控制RAM 运维编排OOS MaxCompute(原ODPS) 云企业网CEN
MaxCompute湖仓一体方案 最佳实践 业务架构 场景描述 数据湖 EMR与云数仓的融合解决方案,将 MaxCompute与 Hive集群做数据打通,通 过存储共享,元数据镜像等方式,解决传统 模式下的存储冗余,计算资源弹性能力弱的 痛点。可大幅度增强系统的资源弹性,解决 业务高峰期计算资源不足的问题。湖仓一体 兼具数据湖的灵活性与...
实时计算Flink版
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,具备实时应用的作业开发、数据调试、运行与监控、自动调优、智能诊断等全生命周期能力。内核引擎100%兼容Apache Flink,2倍性能提升,拥有FlinkCDC、动态CEP等企业级增值功能,内置丰富上下游连接器,助力企业构建高效、稳定和强大的实时数据应用。
面对这种数据体量大,跨全球各区域的复杂场景易仓大数据团队使用实时计算Flink版的高并发pipeline处理数据的能力,实现数据准确毫秒级别同步入仓.查看案例详情.江铃汽车股份有限公司作为中国TOP 20汽车制造厂商、《财富》中国企业500强,在大数据建设方面选择与阿里云强强合作,通过阿里云实时计算平台为公司构建统一的实时...
来自:
云产品
Spark on ECI大数据分析

场景描述 方案优势 1.计算引擎弹性扩缩容,兼顾资源弹性与计 算资源成本优化。 2.计算与存储分离架构,结合阿里云原生云 存储产品,海量数据湖优势。 3.Kubernetes原生的调度性能优势,提升在 大规模分析作业时的分析性能优势分。 4.集群资源隔离和按需分配。 解决问题 1.计算资源弹性能力不足,计算资源成本管 控能力欠缺. 2.集群资源调度能力和隔离能力不足。 3.计算与存储无法分离,大数据量分析时出 现数据存储资源瓶颈。 4.Spark submit方式提交分析作业参数支持 有限等缺点。 产品列表 容器服务Kubernetes版(ACK) 弹性容器实例(ECI) 文件存储HDFS 对象存储OSS 专有网络VPC 容器镜像服务ACR
应用范围 需要使用 Spark on Kubernetes解决方案的用户 对 Spark大数据分析平台计算资源成本控制考虑的用户 需要有灵活可扩展计算平台资源弹性及管控的用户 名词解释 文件存储 HDFS:阿里云文件存储 HDFS是面向阿里云 ECS实例及容器服务等计 算资源的文件存储服务,允许用户像在 Hadoop分布式文件系统中管理和访问数 据,...
- 产品推荐
- 这些文档可能帮助您