
阿里云开发者社区






大家在互动










综合
最新
有奖励
免费用
让你的文档从静态展示到一键部署可操作验证
通过函数计算的能力让阿里云的文档从静态展示升级为动态可操作验证,用户在文档中单击一键部署可快速完成代码的部署及测试。这一改变已在函数计算的活动沙龙中得到用户的认可。
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
本教程将带领大家免费领取阿里云PAI-EAS的免费试用资源,并且带领大家在 ComfyUI 环境下使用 SVD的模型,根据任何图片生成一个小短视频。
倚天使用|YODA倚天应用迁移神器,让跨架构应用迁移变得简单高效
YODA(Yitian Optimal Development Assistant,倚天应用迁移工具)旨在帮助用户更加高效、便捷地实现跨平台、跨结构下的应用迁移,大幅度缩短客户在新平台上端到端性能验
Paimon 与 Spark 的集成(二):查询优化
通过一系列优化,我们将 Paimon x Spark 在 TpcDS 上的性能提高了37+%,已基本和 Parquet x Spark 持平,本文对其中的关键优化点进行了详细介绍。
ECS实例选型最佳实践
本课程主要讲解在客户明确自身业务功能、性能、稳定性需求,以及成本成本约束后去了解各规格族/规格特性,匹配自身需求选择所需服务器类型。实例规格选型最佳实践,就是为了帮助用户结合自身业务需求中性能、价格、

创建to do list应用教程
阿里云讲师手把手带你部署to do list,本实验支持使用 个人账号资源 或 领取免费试用额度 进行操作,建议优先选用通过已领取的云工开物高校计划学生300元优惠券购买个人账号资源的方案,如您具备免
conda数据源在昨天失效返回404,当前依赖的包无法安装和使用
问题描述conda数据源在失效返回404当前依赖的包无法安装和使用失效的镜像通道地址conda-forge: http://mirrors.aliyun.com/anaconda/cloud
阿里云百炼大模型产品实践
PAI-EAS 一键启动ComfyUI!SVD 图片一键生成视频 stable video diffusion 教程 SVD工作流
PAI-EAS 一键启动ComfyUI!SVD 图片一键生成视频 stable video diffusion 教程 SVD工作流

阿里云产品手册2024版
阿里云作为数字经济的重要建设者,不断加深硬核科技实力,通过自身能力助力客户实现高质量发展,共创数字新世界。阿里云产品手册 2024 版含产品大图、关于阿里云、引言、安全合规等内容,覆盖人工智能与机器学

加载ModelScope模型以后,为什么调用,model.chat()会提示错误?
加载ModelScope模型以后为什么调用model.chat()会提示错误AttributeError: Qwen2ForCausalLM object has no attribute chat

深入探究Java微服务架构:Spring Cloud概论
**摘要:** 本文深入探讨了Java微服务架构中的Spring Cloud,解释了微服务架构如何解决传统单体架构的局限性,如松耦合、独立部署、可伸缩性和容错性。Spring Cloud作为一个基于
All in One:Prometheus 多实例数据统一管理最佳实践
当管理多个Prometheus实例时,阿里云Prometheus托管版相比社区版提供了更可靠的数据采集和便捷的管理。本文比较了全局聚合实例与数据投递方案,两者在不同场景下各有优劣。
Higress 全新 Wasm 运行时,性能大幅提升
本文介绍 Higress 将 Wasm 插件的运行时从 V8 切换到 WebAssembly Micro Runtime (WAMR) 的最新进展。
访问控制(RAM)|云上安全使用AccessKey的最佳实践
集中管控AK/SK的生命周期,可以极大降低AK/SK管理和使用成本,同时通过加密和轮转的方式,保证AK/SK的安全使用,本次分享为您介绍产品原理,以及具体的使用步骤。


【活动推荐】Alibaba Cloud Linux实践操作学习赛,有电子证书及丰厚奖品!
参与开放原子基金会的[龙蜥社区Alibaba Cloud Linux实践操作学习赛](https://competition.atomgit.com/competitionInfo),获取电子证书。报

Higress 基于自定义插件访问 Redis
本文介绍了Higress,一个支持基于WebAssembly (WASM) 的边缘计算网关,它允许用户使用Go、C++或Rust编写插件来扩展其功能。文章特别讨论了如何利用Redis插件实现限流、缓存
阿里云高级技术专家李鹏:AI基础设施的演进与挑战 | GenAICon 2024
阿里云高级技术专家、阿里云异构计算AI推理团队负责人李鹏将在主会场第二日上午的AI Infra专场带来演讲,主题为《AI基础设施的演进与挑战》。
第十三期乘风伯乐奖--寻找百位乘风者伯乐,邀请新博主入驻即可获奖
乘风伯乐奖,面向阿里云开发者社区已入驻乘风者计划的博主(技术/星级/专家),邀请用户入驻乘风者计划即可获得乘风者定制周边等实物奖励。本期面向阿里云开发者社区寻找100位乘风伯乐,邀请人数月度TOP 1


开源开发者沙龙北京站 | 微服务安全零信任架构
讲师/嘉宾简介 刘军(陆龟)|Apache Member 江河清(远云)|Apache Dubbo PMC 孙玉梅(玉梅)|阿里云技术专家 季敏(清铭)|Higress Maintainer 丁双喜(


RocketMQ 之 IoT 消息解析:物联网需要什么样的消息技术?
RocketMQ 5.0 是为应对物联网(IoT)场景而发布的云原生消息中间件,旨在解决 IoT 中大规模设备连接、数据处理和边缘计算的需求。
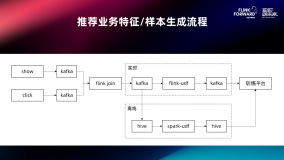
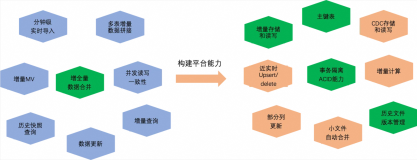
MaxCompute 近实时增全量处理一体化新架构和使用场景介绍
本文主要介绍基于 MaxCompute 的离线近实时一体化新架构如何来支持这些综合的业务场景,提供近实时增全量一体的数据存储和计算(Transaction Table2.0)解决方案。
在Redhat 9部署nginx服务
Nginx是一个高性能、开源的HTTP和反向代理服务器,以其异步非阻塞模型处理高并发,并具有轻量级、高可靠性、良好扩展性和热部署特性。在Redhat 9.2上安装nginx-1.24.0涉及安装依赖、
什么是阿里云FPGA云服务器?FPGA云服务器产品优势及应用场景介绍
FPGA云服务器是阿里云提供的实例规格,融合现场可编程门阵列的低延迟硬件加速与弹性资源。FaaS平台简化了FPGA开发,提供统一硬件、开发环境和丰富的IP生态。特性包括硬件虚拟化、联合仿真和动态互联配

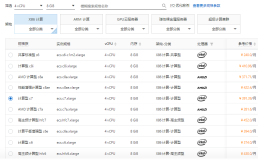
2024阿里云服务器4核8G配置最新租用收费标准与活动价格参考
4核8G配置是大部分企业级用户购买阿里云服务器的首选配置,2024年经过调价之后,4核8G配置的阿里云服务器按量收费标准最低为0.45元/小时,按月租用平均优惠月价最低收费标准为216.0元/1个月,
什么是语句?什么是表达式?怎么区分?
编程语言中的语句和表达式是基础概念。语句是执行操作或命令的代码行,如Python的`print("Hello, World!")`,通常以换行符结束。表达式则表示值或计算过程,如`2 + 2`,可赋值
singleCellNet(代码开源)|单细胞层面对细胞分类进行评估,褒贬不一,有胜于无
`singleCellNet`是一款用于单细胞数据分析的R包,主要功能是进行细胞分类评估。它支持多物种和多分组分析,并提供了一个名为`CellNet`的类似工具的示例数据集。用户可以通过安装R包并下载
Java中的设计模式及其应用
【4月更文挑战第18天】本文介绍了Java设计模式的重要性及分类,包括创建型、结构型和行为型模式。创建型模式如单例、工厂方法用于对象创建;结构型模式如适配器、组合关注对象组合;行为型模式如策略、观察者
深入理解Java虚拟机(JVM)性能调优
【4月更文挑战第18天】本文探讨了Java虚拟机(JVM)的性能调优,包括使用`jstat`、`jmap`等工具监控CPU、内存和GC活动,选择适合的垃圾回收器(如Serial、Parallel、CM
Java模块化:从理论到实践
【4月更文挑战第18天】本文探讨了Java模块化系统(JPMS),旨在解决大型Java应用的可扩展性和维护问题。模块是相关类和接口的集合,模块化有助于依赖管理和版本控制,改善代码组织和重用。核心概念包
函数式编程在Java中的应用
【4月更文挑战第18天】本文介绍了函数式编程的核心概念,包括不可变性、纯函数、高阶函数和函数组合,并展示了Java 8如何通过Lambda表达式、Stream API、Optional类和函数式接口支
Java并发编程:深入理解线程与锁
【4月更文挑战第18天】本文探讨了Java中的线程和锁机制,包括线程的创建(通过Thread类、Runnable接口或Callable/Future)及其生命周期。Java提供多种锁机制,如`sync
正确配置环境路径后,javac、java命令行能正常运行,但是javap不能正常运行?
社区里的大佬好我在检查了问题可能来源的地方仍然无法解决javap指令不能运行的问题。列出以下描述请求社区里的大佬帮助谢谢 以下是我在vscode终端运行javac和java的结果 但是javap
深度学习在图像识别中的应用与挑战
【4月更文挑战第18天】 随着人工智能技术的飞速发展,深度学习已经成为计算机视觉领域的核心技术之一。尤其是在图像识别任务中,深度学习模型已经取得了显著的成果。然而,尽管取得了很多成功,但深度学习在图像
5款开源BI工具优缺点及介绍
【4月更文挑战第15天】对比了几款开源BI报表工具:Superset以其高性能和高度可定制化受青睐,适合复杂分析;Metabase以其简洁易用和广泛兼容性脱颖而出,适合快速构建报表;DataEase以
未来编程:量子计算与量子编程语言的崛起
【4月更文挑战第18天】 在经典计算机科学领域,编程已成为现代文明不可或缺的组成部分。然而,随着量子计算的发展,我们即将迈入一个全新的编程纪元。量子计算机利用量子位(qubits)代替传统的二进制比特
❤Nodejs 第五章(操作本地数据库优化和处理)
【4月更文挑战第5天】本文介绍了在Node.js中操作本地数据库的优化和处理方法。首先展示了如何优化用户查询接口,根据用户条件查询用户列表。通过设置查询参数并使用axios发送GET请求,结合Expr
构建高效Android应用:从内存优化到用户体验
【4月更文挑战第18天】 在移动开发领域,特别是针对Android系统,性能优化和内存管理是确保应用流畅运行的关键。本文将深入探讨如何通过各种技术手段提升Android应用的性能,包括内存使用优化、U
什么是HTML?
HTML是超文本标记语言,用于创建网页的标准语言,专注于内容结构和含义,不涉及样式。它由标签组成,如<title>、<p>、<a>等,与CSS和JavaScript
《手把手教你》系列技巧篇(二十四)-java+ selenium自动化测试-三大延时等待(详细教程)
【4月更文挑战第16天】本文介绍了Selenium的三种等待方式:硬性等待、隐式等待和显式等待。硬性等待是指无论页面是否加载完成,都会等待指定时间后再执行下一步;隐式等待是在整个会话中设置一个全局等待
使用Stream API进行数据处理和分析
【4月更文挑战第18天】Java 8的Stream API为高效声明式处理集合数据提供了革命性功能。Stream非存储、不重复、有顺序且只能消费一次。创建Stream可通过集合、`Stream.of(
Zoho Mail邮箱API发送邮件的方法
Zoho Mail提供了强大的API,使开发者可以通过编程方式轻松地使用Zoho Mail发送邮件。aoksend将介绍如何使用Zoho Mail邮箱API发送邮件,以及一些常见的用法示例。
Java微服务架构设计与实现
【4月更文挑战第18天】本文探讨了如何使用Java设计和实现微服务架构,强调了微服务的自治性、分布式治理、弹性设计和可观测性等关键特性。在设计时,需考虑服务边界、通信机制、数据库、松耦合和高内聚、安全
什么是Shell
Shell是用户与操作系统内核之间的接口,允许用户通过命令行或脚本来与操作系统进行交互。 它解释用户输入的命令,并将其转换为操作系统能够理解的指令,然后执行这些指令并将结果返回给用户。

ZeptoMail邮箱API发送邮件的方法
ZeptoMail是一款便于开发者集成邮件发送功能的API服务,提供发送文本、HTML及附件邮件的能力。基本功能包括设置发件人、收件人、主题和内容。使用步骤涉及注册获取API密钥、构建邮件内容、发送请
Python数据分析工具Seaborn
【4月更文挑战第14天】Seaborn是Python的数据可视化库,基于matplotlib,为数据科学家提供高级接口创建统计图形。其特点包括简洁的API、丰富的图形类型(如散点图、直方图)、内置统计


构建高效的Java缓存策略
【4月更文挑战第18天】本文探讨了如何构建高效的Java缓存策略,强调缓存可提升系统响应和吞吐量。关键因素包括缓存位置、粒度、失效与更新策略、并发管理、序列化及选择合适库(如Ehcache、Guava


从零开始构建Java消息队列系统
【4月更文挑战第18天】构建一个简单的Java消息队列系统,包括`Message`类、遵循FIFO原则的`MessageQueue`(使用`LinkedList`实现)、`Producer`和`Con
什么是EL表达式
EL表达式,全称为Expression Language,意为表达式语言。它是Servlet规范中的一部分,也是JSP2.0规范加入的内容。EL表达式的主要作用是用于在Java Web应用中访问和操作
关系型数据库ALTER语句
`ALTER` 语句常见操作有:添加列(`ADD COLUMN`)、删除列(`DROP COLUMN`)、修改列数据类型(`MODIFY COLUMN`或`CHANGE`)、重命名列(`CHANGE`





