本节书摘来异步社区《机器学习项目开发实战》一书中的第2章,第2.4节,作者:【美】Mathias Brandewinder(马蒂亚斯·布兰德温德尔),更多章节内容可以访问云栖社区“异步社区”公众号查看
2.4 实现分类器
我们已经讨论了许多数学和模型方面的内容,但是还没有讨论编码。幸运的是,这就是我们所需要的一切:现在,我们已经为实现一个简单的贝叶斯分类器做好了准备。从根本上说,分类器依赖于两个要素:将文档分解为标记的标记化程序,以及一组标记——用于求得文档得分的单词。有了这两个组件,我们需要从一个示例样本中知道每个标记的垃圾短信和非垃圾短信得分,以及每一组的相对权重。
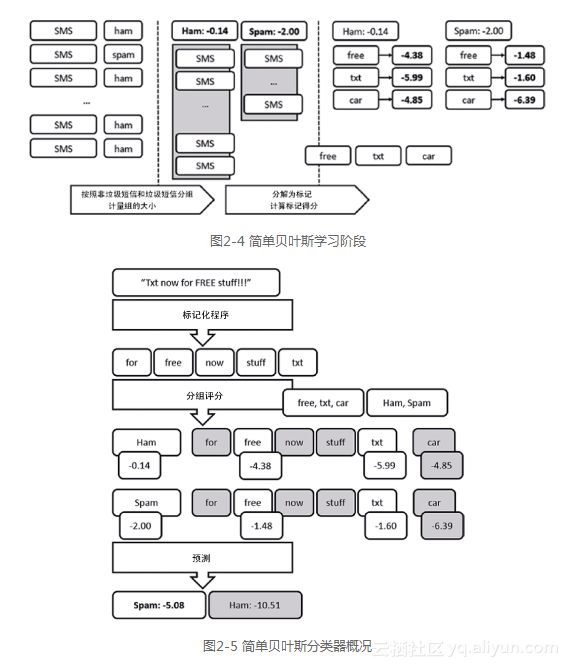
图2-4概述了学习阶段。从具备标签的消息语料库开始,将它们分解为两组:垃圾短信和非垃圾短信,并计量其相对规模。然后,对选中的一组标记(“free”“txt”和“car”),计量其频度,将每一组文档归纳为对应于其总体权重的得分,为每个标记求得特定组别的得分。
得到上述信息之后,新文档的分类遵循图2-5中概述的过程:标记化文档,根据存在的标记计算每组得分,并预测最高得分的组。
在这个特殊的例子中,一旦文档标记化,我们搜索每个单独标记(忽略其他情况)是否都有一个得分,计算每组的总体得分,确定哪一组更可能匹配。
2.4.1 将代码提取到模块中
为了避免在脚本中聚集过多代码,我们将分类器提取为一个模块。这只需用鼠标右键单击解决方案,选择“新建项”(Add New Item),然后选择“源文件”(Source File)。将文件改名为NaiveBayes.fs,删除其中的所有默认代码,用如下代码代替:
namespace NaiveBayes
module Classifier =
let Hello name = printfn "Hello, %s" name```
最后,用鼠标右键单击该文件并选择“上移”(Move up)(或者Alt+向上箭头),直到 NaiveBayes.fs出现在解决方案文件列表中的第一个(也可以在解决方案资源管理器中选择文件,使用“在上方添加”(Add Above)或者“在下方添加”(Add Below)将文件直接添加到所需的位置)。现在,你已经创建了一个文档,可以开始编写函数了,从脚本中调用,或者从F#或者C#项目中使用。为了说明,下面是从当前脚本使用Hello函数的方法:load "NaiveBayes.fs"
open NaiveBayes.Classifier
Hello "World"`
■ 注意:
你可能觉得疑惑,为什么必须将刚创建的文件上移。和C#不同,F#解决方案中的文件顺序很重要,主要原因是类型推理系统。编译器查看到目前为止代码文件中已有的定义,自动理解类型的含义。类似地,如果打算在代码中使用函数f,该函数必须在使用它的代码之前定义。这是一个附加的限制,但是在我看来,相对于类型推理的好处,这种代价非常合理。而且,作为有趣的副作用,这提供了F#解决方案中的自然顺序,使它们容易解读:从第一行开始正向阅读,或者从最后一行开始反向阅读!
2.4.2 文档评分与分类
有了模块,我们就可以在模块中写入上述算法,然后使用脚本文件以该算法探索数据。我们将遵循典型的F#模式,由底向上构建,编写小的代码块组成更大的工作流。模型的关键要素是得分计算,这个功能计量文档属于某一组(如垃圾短信)的证据强度。
得分取决于两个成分:该组在整个语料库(训练数据)中出现的频度,以及该组中找到某些标记的频度。我们首先定义表现问题域的两个类型。我们不将文档和标记定义为字符串,而是直呼其名,定义一个Token类型——字符串的类型别名。这将使我们在类型签名上更加清晰。例如,现在可以定义一个Tokenizer(标记化程序)函数,以一个字符串(文档)为 参数,返回一组标记。类似地,使用TokenizedDoc类型别名,为已经标记化的文档提供一个名称:
type Token = string
type Tokenizer = string -> Token Set
type TokenizedDoc = Token Set```
为了分类一个新文档(标签未知),我们需要使用已有的有标签文档样本,计算它在每个可能组的得分。这样做需要每个组的两部分信息:比例(该组在整个数据集中被找到的频率)以及为模型选择的每个标记的得分,这表明了标记指向该组的强度。
我们可以用一个数据结构DocsGroup建立模型,它包含Proportion(该组在整个数据集中被找到的频率)和TokenFrequencies——将每个标记与数据集中频率(用拉普拉斯方法校正)关联的Map类型(与字典作用类似的F#数据结构)。举个例子,在本书的特例下,可以创建两个DocsGroup——一个用于非垃圾短信,另一个用于垃圾短信——非垃圾短信DocsGroup包含整个数据集中非垃圾短信的比例,对于我们感兴趣的每个标记,还包含实际标记和出现在非垃圾短信中的频率。type DocsGroup =
{ Proportion:float;
TokenFrequencies:Map<Token,float> }```假定某个文档已经分解为一组标记,计算给定组的得分相当简单。我们没有必要担心这些数字的计算方法。如果这一部分已经完成,需要做的就是加总分组频率的对数,以及每个标记出现在已标记化文档中和模型使用的标记列表中频率的对数:
程序清单2-2 计算文档得分
let tokenScore (group:DocsGroup) (token:Token) =
if group.TokenFrequencies.ContainsKey token
then log group.TokenFrequencies.[token]
else 0.0
let score (document:TokenizedDoc) (group:DocsGroup) =
let scoreToken = tokenScore group
log group.Proportion +
(document |> Seq.sumBy scoreToken)```
然后,文档分类就只是用标记化程序将其转换为标记,找出可能的DocGroups列表中具有最高得分的分组,并返回其标签:
程序清单2-3 预测文档标签let classify (groups:(_*DocsGroup)[])
(tokenizer:Tokenizer)
(txt:string) =
let tokenized = tokenizer txt
groups
|> Array.maxBy (fun (label,group) ->
score tokenized group)
|> fst```你可能对classify函数中的groups:(DocsGroup)[]有些疑惑,为什么对每组文档使用(DocTypeDocsGroup)元组,神秘的符号是什么?请你仔细思考,到目前为止,我们所做的并不依赖于具体的标签。我们考虑了垃圾短信和非垃圾短信,但是同样可以将其应用到不同语料库,例如,预测电影评论是否对应于1、2、3、4或者5星评级。因此,我决定使这些代码通用;只要有一组具备一致标签类型的示例文档,这些代码就有效。符号表示“类型通配符”(任何类型都得到支持),如果检查classify函数签名,就会看到:groups:('a * DocsGroup) [] -> tokenizer:Tokenizer -> txt:string -> 'a。通配符已经被'a(表示泛型类型)所代替,函数也返回一个'a,这是(泛型)标签类型。
2.4.3 集合和序列简介
这里已经引入了两个新类型——序列和集合。我们从集合开始简短地讨论这两种类型,集合代表一组唯一项目,主要目的是回答“项目X 是否属于集合S”的问题。考虑到我们想要搜索特定单词(更通用的说法是标记)是否出现在SMS中,以确定SMS可能是垃圾短信还是非垃圾短信,使用可以有效比较项目集合的数据结构似乎很合理。通过将文档归纳为几组标记,就可以快速识别是否包含某个标记(如“txt”),而无须付出使用Contains()字符串方法的代价。
Set模块提供了许多围绕集合运算的方便函数,如下面的片段所示。在F# Interactive窗口中输入以下内容:
> let set1 = set [1;2;3]
let set2 = set [1;3;3;5];;
val set1 : Set<int> = set [1; 2; 3]
val set2 : Set<int> = set [1; 3; 5]```
这段代码创建了两个集合,注意从set2删除重复的值3的方法。Set模块提供了可以计算并集及交集的函数;let intersection = Set.intersect set1 set2
let union = Set.union set1 set2;;
val intersection : Set = set [1; 3]
val union : Set = set [1; 2; 3; 5]`
集合还输出一个有用的函数difference,从一个集合中减去另一个集合,也就是说,从第一个集合中删除第二个函数中的每个元素:
> let diff1 = Set.difference set1 set2
let diff2 = Set.difference set2 set1;;
val diff1 : Set<int> = set [2]
val diff2 : Set<int> = set [5]```
注意,与intersection和union函数不同,difference函数不可交换。也就是说,参数的顺序很重要,前一个例子中已经做了说明。最后要注意,集合是不可变的,一旦创建集合,它就不能修改:let set3 = Set.add 4 set1
set1.Contains 4;;
val set3 : Set = set [1; 2; 3; 4]
val it : bool = false`
在set1中添加4创建一个新集合set3,它包含4,但是原始集合set1没有受到这一运算的影响。
我们引入的另一个类型——序列,是惰性求值的元素序列——也就是说,它是仅在必要时计算的集合,这样可以潜在地减少内存或者计算使用量。在F# Interactive中尝试如下代码:
> let arr1 = [| for x in 1 .. 10 -> x |]
let seq1 = seq { for x in 1 .. 10 -> x };;
val arr1 : int [] = [|1; 2; 3; 4; 5; 6; 7; 8; 9; 10|]
val seq1 : seq<int>```
表达式arr1和seq1非常类似;它们都生成从1到10的整数。但是,数组立即显示全部内容——这是立刻求值的。相反,seq1显示为整数的一个序列,但是没有进一步的细节。实际内容只在代码需要的时候才生成。下面的例子可以进一步证明这一点,它取得seq1并将每个元素加倍,构建一个新的序列。注意,我们在序列中增加了其他的作用,每当序列的一个元素生成,就打印输出已经映射的元素:let seq2 =
seq1 |> Seq.map (fun x -> printfn "mapping %i" x 2 * x) ;;
val seq2 : seq`
同样,结果是一个尚无实际内容的序列,因为目前没有任何必要的内容。我们改编代码,要求得到前3个元素的总和:
> let firstThree =
seq2
|> Seq.take 3
|> Seq.sum;;
mapping 1
mapping 2
mapping 3
val firstThree : int = 12```
执行上述代码时,打印输出“mapping 1”“mapping 2”和“mapping 3”,说明序列取出了前3个元素,这是计算总和所必需的。但是,剩下7个元素仍然没有必要,现在仍然没有求值。
那么,在我们已经有数组这样完美的集合类型的情况下,为什么还要有序列呢?第一个好处是惰性求值。因为序列只在“必要”时求值,我们可以用它们生成无限序列。例如,生成数组完全不可能生成的某种集合。下面的片段提供了一个人为的例子:我们创建一个由1和−1交替形成的无限序列。很显然,在内存中实例化这种无限序列是不可能的,但是既然定义了它,我们就可以使用,例如计算任意数量元素的总和:let infinite = Seq.initInfinite (fun i -> if i % 2 = 0 then 1 else -1)
let test = infinite |> Seq.take 1000000 |> Seq.sum;;
val infinite : seq
val test : int = 0`
F#序列常常得到使用的另一个原因是,它们等价于C#的IEnumerable,所有.NET集合类型本身都可以当成序列处理,因此,Seq模块提供的函数可以利用实际集合类型中没有出现的功能性,对其进行操纵。考虑下面的例子:
> let arr = [| 1;2;2;3;4;4;4|]
let counts =
arr
|> Seq.countBy (fun x -> x)
|> Seq.toArray;;
val arr : int [] = [|1; 2; 2; 3; 4; 4; 4|]
val counts : (int * int) [] = [|(1, 1); (2, 2); (3, 1); (4, 3)|]```
我们生成了一个整数数组,然后想要计算每个整数出现了多少次。虽然数组没有直接支持这一功能(至少,在F# 4.0正式交付之前没有),但是序列有此功能,所以我们在数组上调用Seq.countBy,将结果转换为数组,以便触发序列求值。
■ 提示:
虽然序列有许多好处(无他,谁不想只计算所需要的?),但是惰性求值也有缺点,包括增加了调试的复杂性。
####2.4.4 从文档语料库中学习
为了使用classify函数,我们必须拥有每组文档的摘要数据。生成该摘要数据需要哪些数据?组的比例需要组中的文档数以及文档总数。对于选择用于分类器的每个标记,必须计算标记化文档包含该标记的比例(经过拉普拉斯修正)。
■ 注意:
不管使用何种语言或者风格,这样实现应用程序设计都很有效:创建具备单一功能、具备清晰定义任务的小型组件,不用担心程序中其余部分发生的情况。这有助于提取具备最小数据结构的清晰模型。然后,你可以将所有组件连接起来,那时,改变设计(例如为了性能)就不会很困难。
收集摘要数据的明显方法是编写一个函数,签名中以文档集合为参数,返回包含传递文档组分析结果的DocsGroup。我们仍然假定获得的数据形式对手上的任务很便利,如何实现这一点将在以后研究。
首先,创建两个助手函数,为我们完成比例和拉普拉斯平滑比例计算中的整数-浮点转换,帮助计算存在特定标记的文档数量:let proportion count total = float count / float total
let laplace count total = float (count+1) / float (total+1)
let countIn (group:TokenizedDoc seq) (token:Token) =
group
|> Seq.filter (Set.contains token)
|> Seq.length```现在,我们已经有了分析有相同标签的一组文件、然后将其归结为一个DocsGroup所需的所有组件,下一步需要做的就是:
计算该组与文档总数的比例。
对我们确定用于分类文档的每个标记,找出在组中的拉普拉斯修正比例。
程序清单2-4 分析一组文档
let analyze (group:TokenizedDoc seq)
(totalDocs:int)
(classificationTokens:Token Set)=
let groupSize = group |> Seq.length
let score token =
let count = countIn group token
laplace count groupSize
let scoredTokens =
classificationTokens
|> Set.map (fun token -> token, score token)
|> Map.ofSeq
let groupProportion = proportion groupSize totalDocs
{
Proportion = groupProportion
TokenFrequencies = scoredTokens
}```
■ 注意:
一定要计算标记的数量,我们将通过计算单词在多少文档中出现,确定其出现频率。这对于短消息非常合适,但是对更长的文档却不是很好。如果你试图识别一本书是关于何种主题(如计算机)的,计算这个单词出现的次数可能比简单地问“这个单词在本书中是否至少出现一次”更好。我们用于SMS的这种方法称为“单词集”;另一种标准方法“单词袋”取决于单词的整体频率,可能更适合于某些文档类型。
我们几乎已经完成工作了,现在已经知道如何分析单独的文档组,只需要编排这些代码块,完整地实现图2-4中概述的算法。对于文档及其标签的一个组合,我们需要:
将每个文档分解为标记。
按照标签分隔它们。
分析每个组。
程序清单2-5 从文档中学习let learn (docs:(_ * string)[])
(tokenizer:Tokenizer)
(classificationTokens:Token Set) =
let total = docs.Length
docs
|> Array.map (fun (label,docs) -> label,tokenizer docs)
|> Seq.groupBy fst
|> Seq.map (fun (label,group) -> label,group |> Seq.map snd)
|> Seq.map (fun (label,group) -> label,analyze group total classificationTokens)
|> Seq.toArray```任务就要圆满完成了。从整个过程中,我们真正想得到的是一个函数,以字符串(原始SMS消息)为参数,根据从文档训练集中学到的,返回具有最高得分的标签。
程序清单2-6 训练简单的贝叶斯分类器
let train (docs:(_ * string)[])
(tokenizer:Tokenizer)
(classificationTokens:Token Set) =
let groups = learn docs tokenizer classificationTokens
let classifier = classify groups tokenizer
classifier```

