热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
动态集群协议(DTP)详解:网络设计的智能引擎
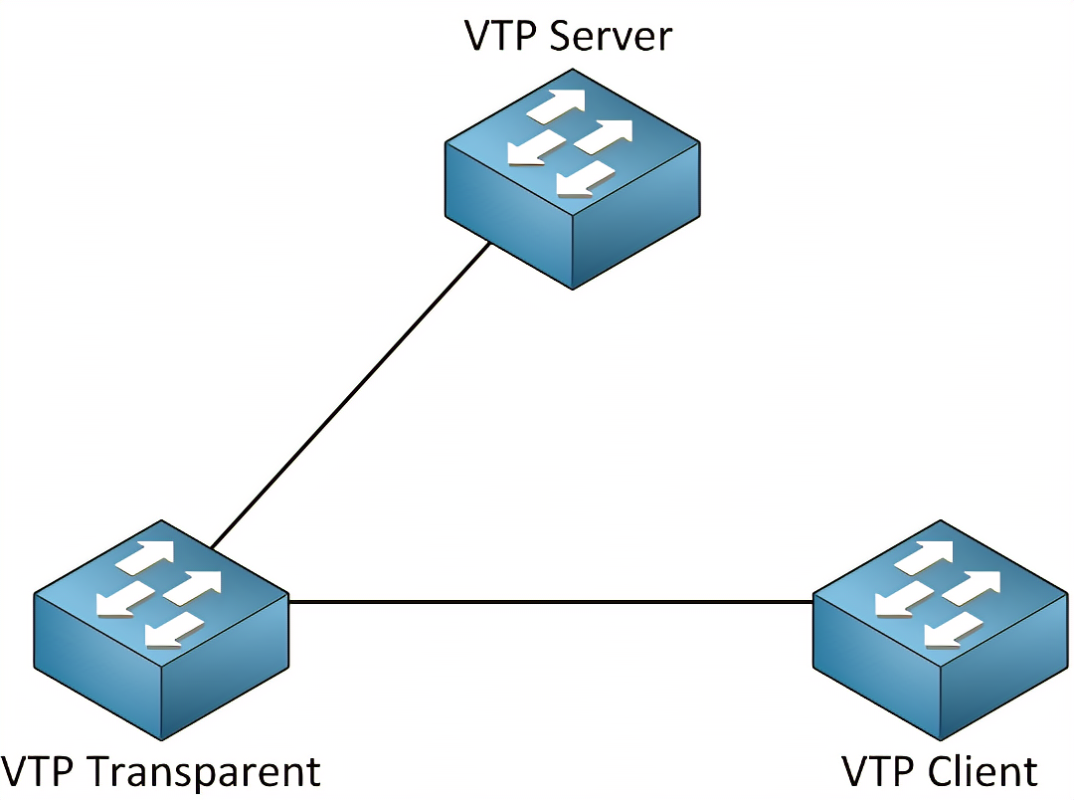
深入解析 VLAN 中继协议(VTP):构建高效网络的关键
中继配置详解:网络设计的桥梁
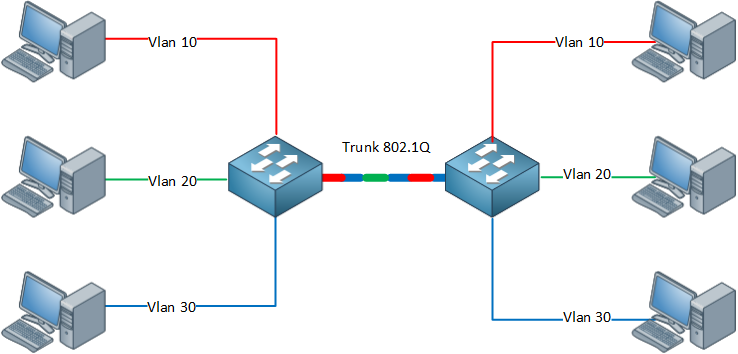
深入浅出 802.1Q:理解虚拟局域网的关键技术
精通VLAN配置:企业网络架构的终极指南
基于SSM+VUE毕业设计网站源码
深入理解虚拟局域网(VLAN):网络架构的变革者
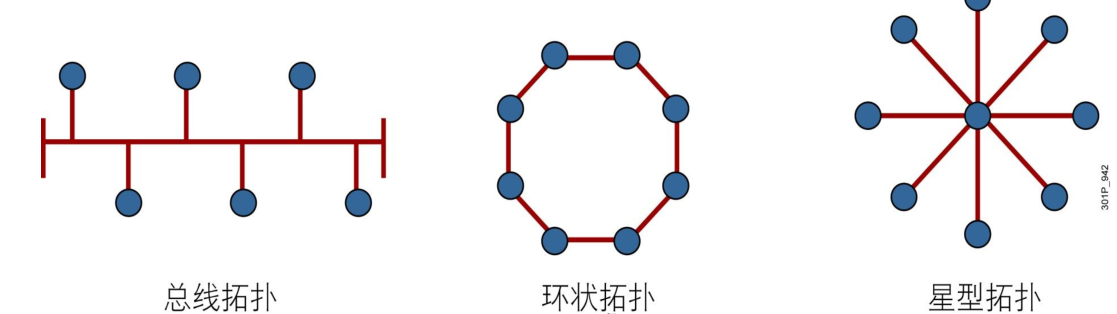
网络拓扑的艺术:构建高效连接的蓝图
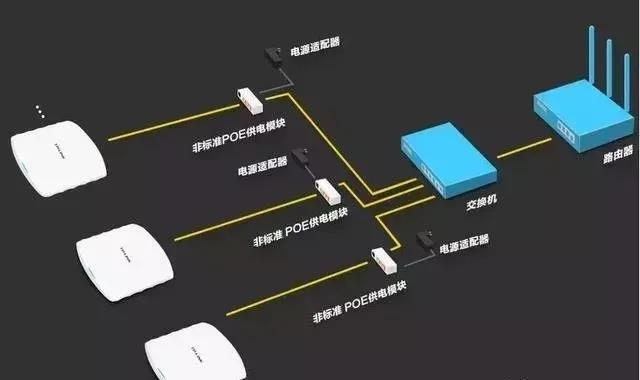
以太网供电(POE):技术详解与应用探索
交换机的智能之路:MAC地址学习机制详解
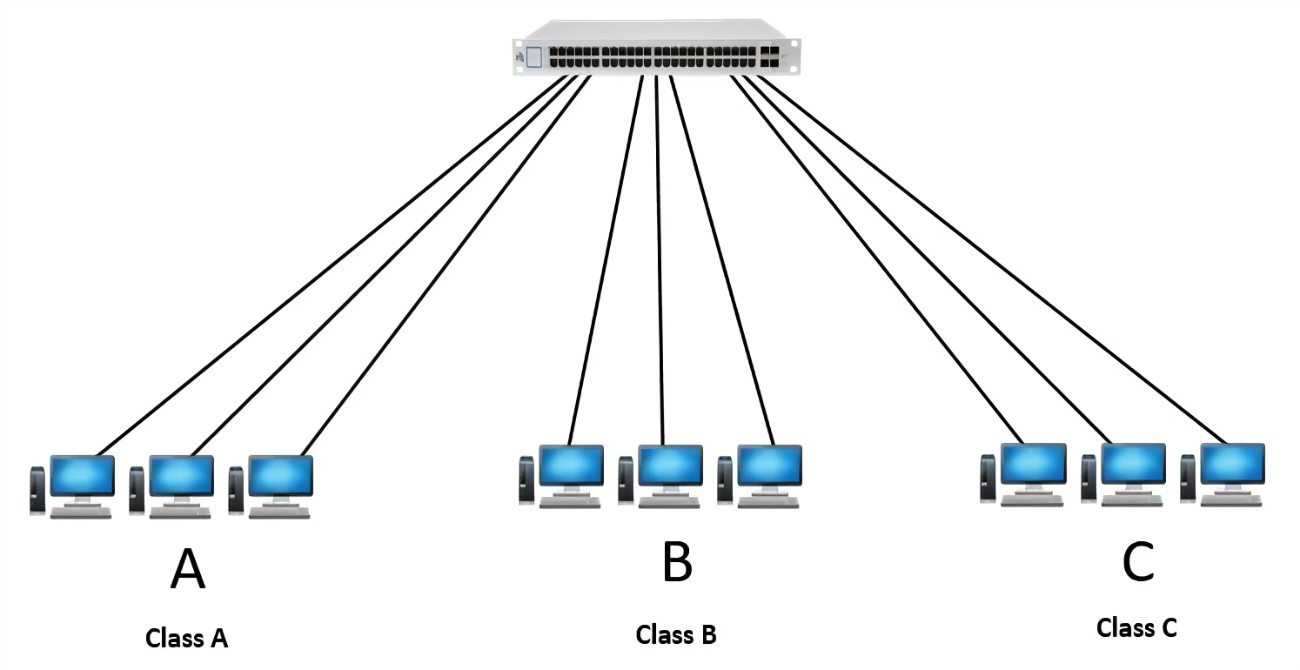
广播域完全解析:网络设计的根基与挑战
探索网络冲突域:保障数据流畅传输的关键
以太网(Ethernet)技术详解:连接数字世界的基石
闭包的工作原理
闭包对于保护私有变量和函数的作用
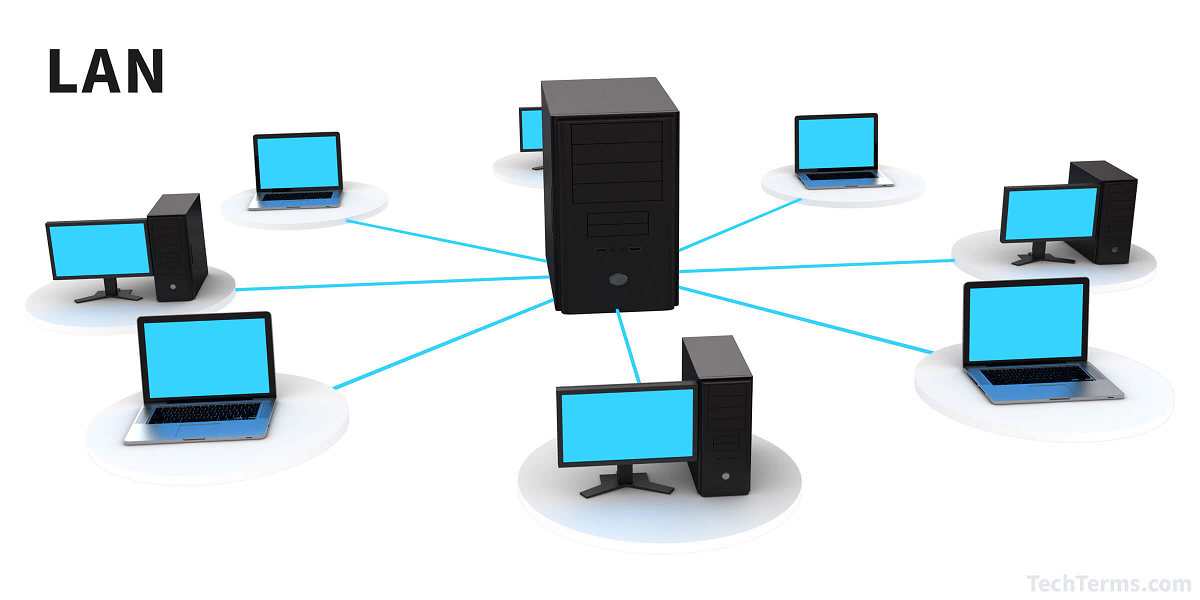
深入局域网络(LAN):构建高速、可靠的网络环境
避免将变量和函数暴露给全局作用域可能导致的命名冲突和代码可维护性
springboot高精度UWB定位系统源码
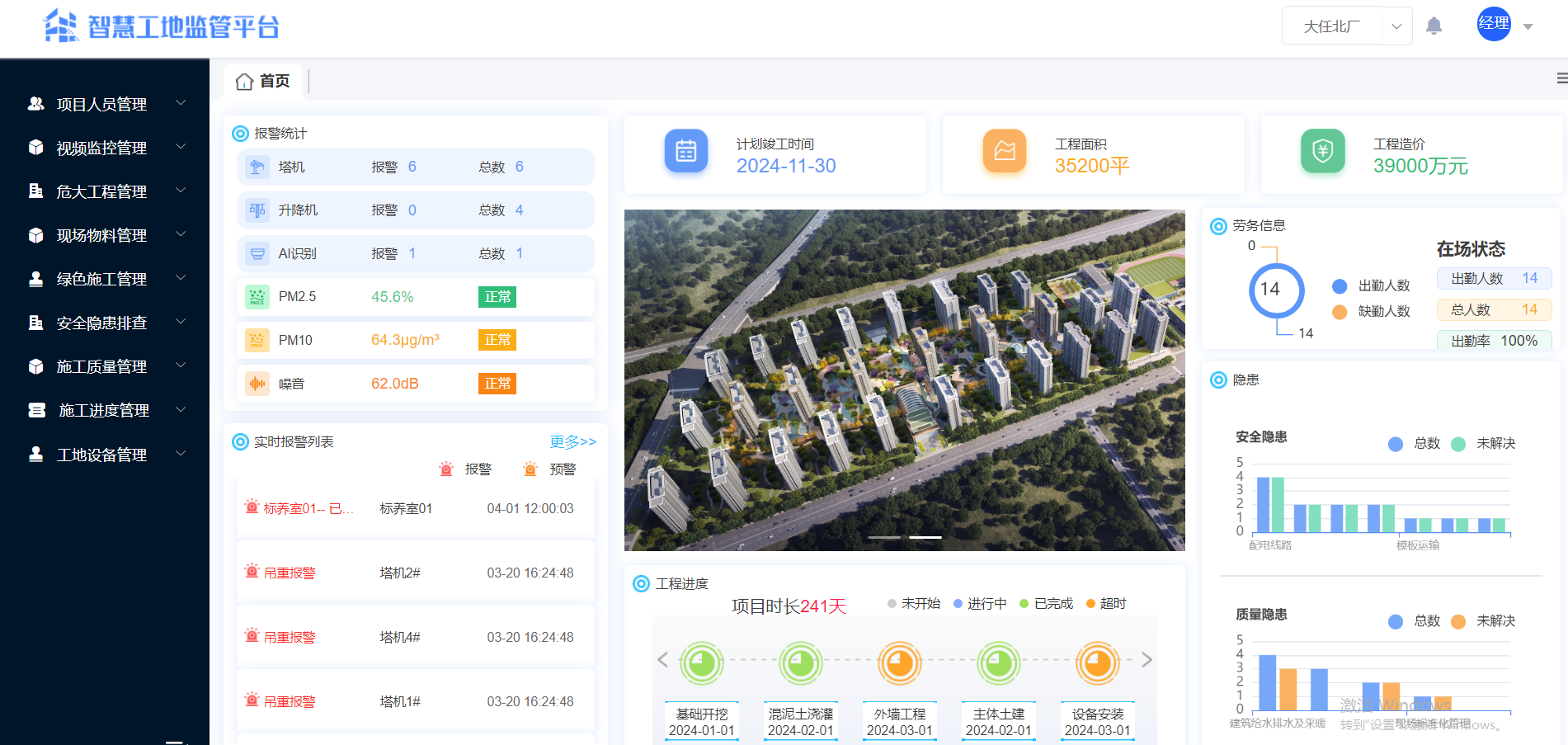
Java智慧工地云平台源码带APP SaaS模式 支持私有化部署和云部署
移动应用与系统:未来技术的关键驱动力
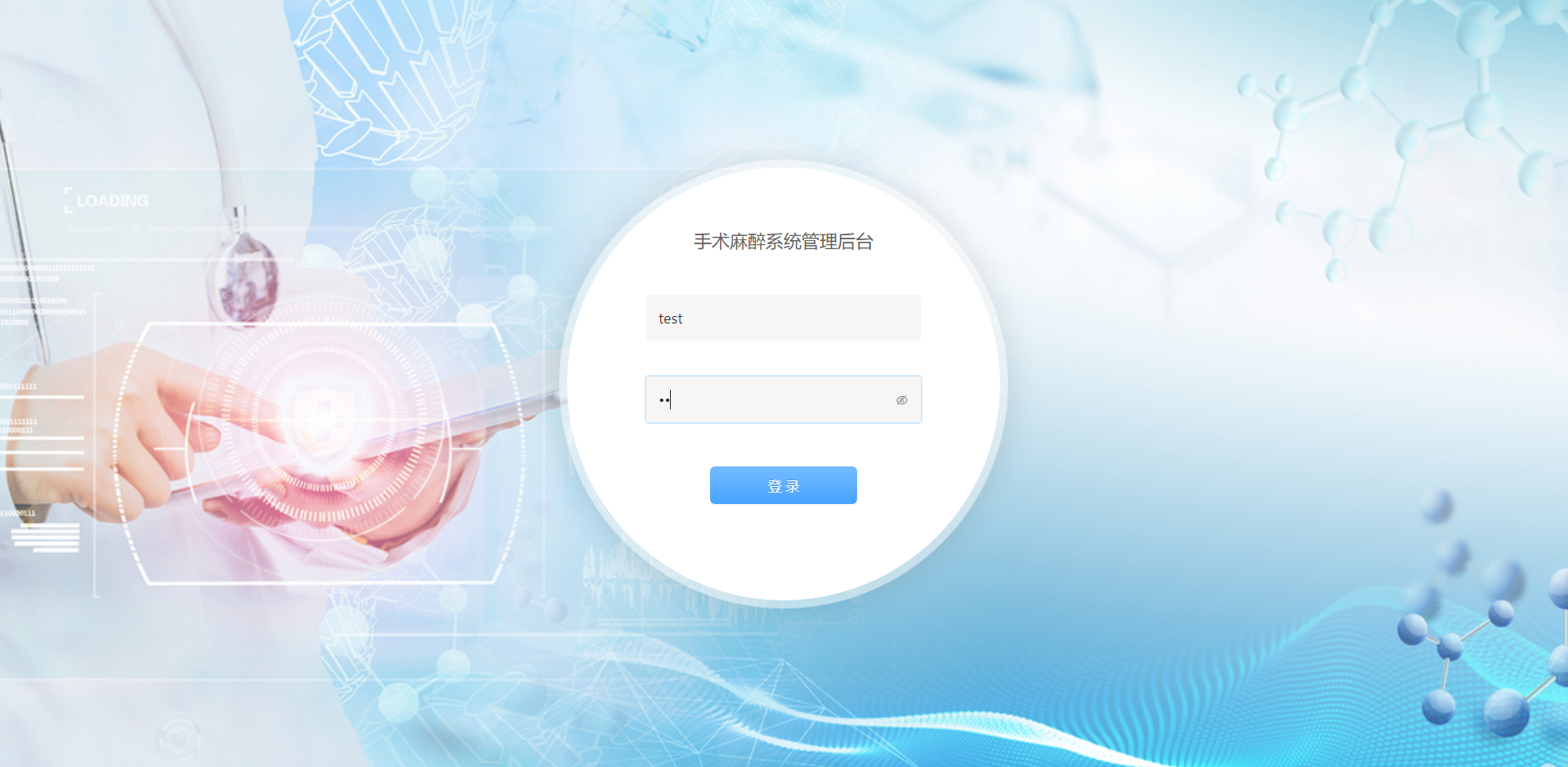
C#医院手术室麻醉信息管理系统源码 自动生成麻醉的各种医疗文书(手术风险评估表、手术安全核查表)
R语言中的广义线性模型(GLM)
R语言在教育研究中的应用
使用R语言进行多维缩放分析
R语言中的混合效应模型
R语言在市场调研中的应用
使用R语言进行非参数统计分析
深入理解PHP的命名空间
R语言中的动态线性模型
014_用vim复制粘贴_保持双手正位
使用R语言进行药物动力学分析
R语言在体育分析中的应用
提升安卓应用性能的实用策略
深度学习在图像识别中的应用及挑战
R语言中的非线性回归模型
js的let、const、var的区别以及应用案例
js变量的作用域、作用域链、数据类型和转换应用案例
在开发者眼中,Docker有怎样通俗易懂的理解方式
java用base64编码案例
构建未来:云原生架构在企业转型中的关键角色
java读取excel数据案例
使用 Python 发送邮件的简单示例
基于深度学习的图像识别技术在自动驾驶车辆中的应用
构建未来:云原生技术在企业数字化转型中的关键作用
python实现股票策略回测案例
python实现股票均线策略案例