本节书摘来自异步社区《Python数据分析》一书中的第2章,第2.9节,作者【印尼】Ivan Idris,更多章节内容可以访问云栖社区“异步社区”公众号查看
2.9 基于位置列表的索引方法
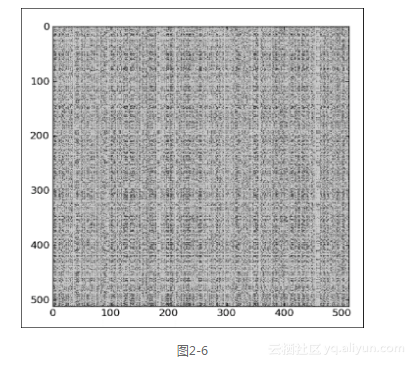
下面利用ix_()函数将莱娜照片中的像素完全打乱。注意,本例中的代码没有提供注释。完整的代码请参考本书代码包中的ix.py文件。
import scipy.misc
import matplotlib.pyplot as plt
import numpy as np
lena = scipy.misc.lena()
xmax = lena.shape[0]
ymax = lena.shape[1]
def shuffle_indices(size):
arr = np.arange(size)
np.random.shuffle(arr)
return arr
xindices = shuffle_indices(xmax)
np.testing.assert_equal(len(xindices), xmax)
yindices = shuffle_indices(ymax)
np.testing.assert_equal(len(yindices), ymax)
plt.imshow(lena[np.ix_(xindices, yindices)])
plt.show()这个函数可以根据多个序列生成一个网格,它需要一个一维序列作为参数,并返回一个由NumPy数组构成的元组。
In : ix_([0,1], [2,3])
Out:
(array([[0],[1]]), array([[2, 3]]))利用位置列表索引NumPy数组的过程如下所示。
1.打乱数组的索引。
用numpy.random子程序包中的shuffle()函数把数组中的元素按随机的索引号重新排列,使得数组产生相应的变化。
def shuffle_indices(size):
arr = np.arange(size)
np.random.shuffle(arr)
return arr2.使用下面的代码画出打乱后的索引。
plt.imshow(lena[np.ix_(xindices, yindices)])3.莱娜照片的像素被完全打乱后,变成图2-6所示的样子。