本节书摘来自异步社区《Python数据科学指南》一书中的第1章,第1.3节,作者[印度] Gopi Subramanian ,方延风 刘丹 译,更多章节内容可以访问云栖社区“异步社区”公众号查看。
1.3 使用字典的字典
我们之前提到,为了完成目标,你得创造性地应用各类数据结构,这样才能发挥它们的威力。接下来,我们通过一个实例来帮助理解“字典的字典”。
1.3.1 准备工作
请看表1-1。
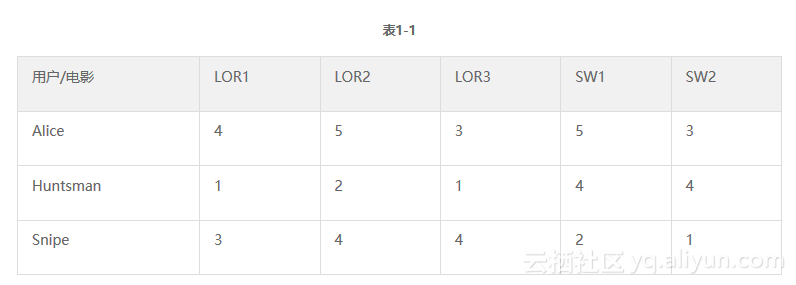
第1列中列出了3个用户,其他列都是电影,单元格里是每个用户给电影的评分。我们要把这些数据放到内存中,这样大型程序的其他部分也能方便地访问,此时我们将使用“字典的字典”。
1.3.2 操作方法
我们通过匿名函数来创建一个user_movie_rating的字典对象,以此展示“字典的字典”这一概念。
我们先将字典的字典填满数据。
from collections import defaultdict
user_movie_rating = defaultdict(lambda :defaultdict(int))
# 初始化艾丽丝的评分
user_movie_rating["Alice"]["LOR1"] = 4
user_movie_rating["Alice"]["LOR2"] = 5
user_movie_rating["Alice"]["LOR3"] = 3
user_movie_rating["Alice"]["SW1"] = 5
user_movie_rating["Alice"]["SW2"] = 3
print user_movie_rating1.3.3 工作原理
user_movie_rating就是一个字典的字典,在前一节中,defaultdict将一个函数作为参数,在本例中,我们传递了一个内置的匿名函数lambda,它返回一个字典。每当一个新的键被传递到user_movie_rating中,同时也有一个新的字典被创建。我们在后续章节中会经常提及lambda函数。
通过这种方式,我们可以快速地对每个用户和电影的组合体的评分进行操作,同样地,还有许多字典的字典的用例充分说明其便利性。
总之,熟练掌握字典数据结构,能帮助你简化数据科学的程序开发任务。以后我们将看到,在机器学习中,字典被大量用来存储特征值和标签。Python的NLTK库在文本挖掘的时候也会大量地使用字典来存储特征值,详见:http://www.nltk.org/book/ch05.html。
上面链接中“使用字典映射词到特征”这一节展示了如何高效地使用字典。
1.3.4 参考资料
第1章“Python在数据科学中的应用”中1.16节“使用lambda创建匿名函数”的相关内容。
