本节书摘来自华章出版社《位置大数据隐私管理》一 书中的第2章,第2.1节,作者潘晓、霍 峥、孟小峰,更多章节内容可以访问云栖社区“华章计算机”公众号查看。
第2章 典型攻击模型和隐私保护模型
本章将对典型攻击模型和相应的隐私保护模型进行说明。攻击模型包括位置连接攻击、位置同质性攻击、查询同质性攻击、位置依赖攻击和连续查询攻击模型。隐私保护模型包括位置k-匿名模型、位置l-差异性模型、查询p-敏感模型和m-不变性模型。为解释方便,在介绍具体攻击模型和隐私保护模型前,首先介绍一种在基于数据失真的隐私保护技术中广泛使用的经典系统结构——中心服务器结构,如图2-1所示。需要说明的是,攻击模型的成立与否与采用的系统结构无关。
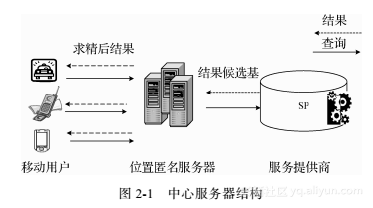
中心服务器结构包含移动用户、基于位置的服务器(即服务提供商)和位置匿名服务器。位置匿名服务器位于用户和基于位置的服务器之间,是可信的第三方,其作用是:①接收位置信息,收集移动对象确切的位置信息,并对每一个移动用户的位置更新进行响应;②匿名处理,将确切的位置信息转换为匿名区域;③查询结果求精,从位置数据库服务器返回的候选结果中选择正确的查询结果返回给相应的移动用户。
在中心服务器结构中一个查询请求的处理过程如下:①发送请求,用户发送包含精确位置的查询请求给位置匿名服务器;②匿名,匿名服务器使用某种匿名算法完成位置匿名后,将匿名后的请求发送给提供位置服务的数据库服务器;③查询,基于位置的数据库服务器根据匿名区域进行查询处理,并将查询结果的候选集返回给位置匿名服务器;④求精,位置匿名服务器从候选结果集中挑出真正的结果返回给移动用户。
2.1 位置连接攻击
2.1.1 攻击模型
2003年,Marco Gruteser[8]第一次关注了基于位置服务中的位置隐私保护问题,提出位置连接攻击,即攻击者利用查询中的位置作为伪标识符(Quasi-Identifier,QI),在用户标识与查询记录间建立关联,泄露了用户标识和查询内容。在位置连接攻击中,攻击者的背景知识是用户的精确位置。背景知识中的位置信息可通过实时通信网络定位技术或对被攻击者进行观察获得。
图2-2显示了用户基于位置的请求以及攻击者能获得的外部数据格式。为了易于表达,使用3个二维表描述不同的数据。表R存储的是用户最初的查询请求,其中,每条元组表示一条服务请求,记为 ,其中id是用户的标识符,l=(x, y)是用户的当前位置,q是查询内容。这3个参数暗含着不同的含义。首先,id可以唯一地标识用户,不能泄露,因此需要在发送给服务提供商之前被隐藏。其次,位置l是一种伪标识符,虽不能直接地标识用户,但可能本身包含隐秘信息或泄露用户身份和查询之间的联系。最后,q是查询内容,对用户而言是否隐私因人而异,但又必须传送给服务提供商。

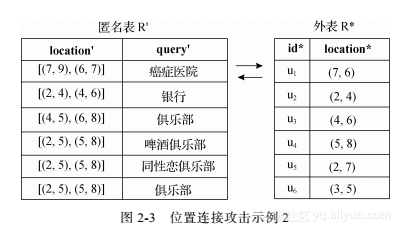
为了保护用户的隐私,可信第三方即匿名服务器需要计算出一个匿名表R',使得:①它包含R的所有属性,除了id;②对应于R中的任何一条元组,它都包含一条对应的匿名后的元组;③不能违背用户的隐私需求。R'中的元组记为r' = (L', q'),其中,L'是匿名服务器对l作匿名化处理之后得到位置信息,图2-2中以匿名区域表示,q'的内容与q一样。表R表示攻击者能够获得的外部信息。R中的每条元组确定了一个用户的位置,表示为 ,l是用户id被攻击者观察到的真实位置。显而易见,如果不对R中的l作任何处理,攻击者已经通过观察获得了位置与id的匹配关系,再进一步通过l与l*的连接操作,暴露查询与id的关系。
图2-3中用匿名区域表示用户位置,采用的是第1章介绍的空间模糊化方法。然而,仅仅模糊位置有时是不够的,依然存在位置连接攻击的风险。用一个具体例子说明,如图2-3所示,有u1~u6 6个用户。外表R中,u1的位置是l1=(7, 6)。在匿名表R'中,有一个查询的匿名区域L1'=[(7, 9), (6, 7)]。当L1'和R*连接时,攻击者观察到L1'只覆盖了一个用户u1的位置。因此,虽然位置信息作了模糊化处理,但仍然可以确定在L1'=[(7, 9)], (6, 7)]中,u1的确切位置在(7, 6)。同时,查询“癌症医院”肯定是由u1发出的。
2.1.2 位置k-匿名模型
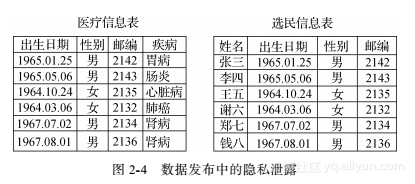
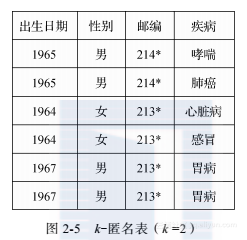
位置k-匿名模型可以解决位置连接攻击问题。k-匿名模型[51]曾是数据发布领域使用最广泛的隐私保护模型。文献[51]中定义了伪标识符和k-匿名性。伪标识符由一组属性组成,可以和外部数据连接用于标识用户。通常可以用于连接的属性有:生日、性别、邮编等。在发布数据时,一般把所有能够唯一标识用户个人信息的属性,如名字等隐藏(不发布),这样该数据就变成匿名的。然而,在大多数情况下,攻击者可以利用其他属性与外部数据之间的联系来匹配个人信息,获取个人隐私。如图2-4所示,当攻击者把医疗信息和选民信息通过出生日期、性别、邮编属性作连接之后,就可以把选民姓名和疾病联系起来,从而获得隐私的个人信息。
k-匿名模型:一个关系是k-匿名关系,如果其中每一个元组所代表的个人信息都至少和关系中其他的k-1个元组不能区分,也就是QI上的每一组值都有k个并发值,每一条元组的QI取值都与其他k-1条元组的QI取值相同。k-匿名模型通过修改两表之间的匹配关系,使得每个用户都匹配到多条元组,避免了用户隐私的泄露。图2-5是对图2-4中医疗信息表进行隐私保护之后得到的2-匿名表。在出生日期、性别、邮编属性上,每一组QI属性值都有两个并发元组。所以即使和外部数据连接,攻击者仍然不能识别出某一个特定个人是哪一条元组。
文献[8]最早将k-匿名的概念应用到位置隐私上,提出了位置k-匿名模型。
位置k-匿名模型:当一个移动用户的位置无法与其他k-1个用户的位置相区别时,称此位置满足位置k-匿名。
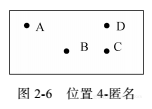
图2-6是一个位置4-匿名的例子。A、B、C和D本来的位置点经过匿名后变成同一个匿名区域。攻击者只知道在此区域中有4个用户,具体哪个用户在哪个位置无法确定,因为用户在匿名区域内任何一个位置出现的概率相同。
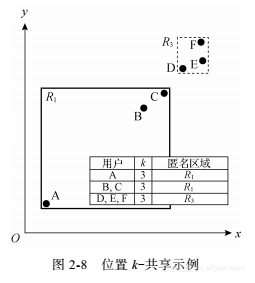
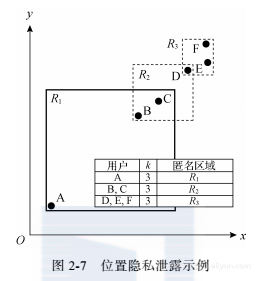
为防止位置连接攻击,匿名集用户仅满足位置k-匿名模型是不够的。文献[40]发现,当用户位置分布已知时,虽然某些匿名区域覆盖k个用户,但由于该匿名区域仅由一个用户发出,也会引发位置连接攻击。如图2-7所示,虽然匿名区域R1中包含3个用户,满足位置3-匿名的要求。但是由于仅有用户A发送R1作为匿名区域。所以当攻击者通过背景知识获知A在位置(1, 1)时,则由R1发出的查询一定是由用户A发出的,用户隐私泄露。
文献[40]提出了位置k-共享特性,其定义如下。
位置k-共享:一个空间匿名区域不仅至少包含k个用户,而且该区域被至少k个用户所共享。
图2-8给出了图2-7所示例子中满足位置2- 共享的位置匿名情况。具体来讲,匿名区域R1和匿名区域R3被至少两个用户共享,同时R1和R3下覆盖了至少两个用户。