引 言
动机
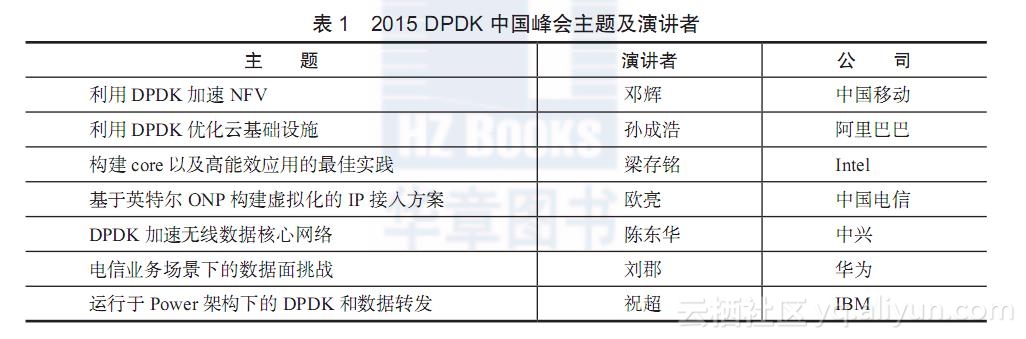
2015年4月,第一届DPDK中国峰会在北京成功召开。来自中国移动、中国电信、阿里巴巴、IBM、Intel、华为以及中兴的专家朋友登台演讲,一起分享了以DPDK为中心的技术主题。表1列出了2015 DPDK中国峰会的主题及演讲者。
这次会议吸引了来自各行业、科研单位与高校的200多名开发人员、专家和企业代表参会。会上问答交流非常热烈,会后我们就想,也许是时间写一本介绍DPDK、探讨NFV数据面的技术书籍。现在,很多公司在招聘网络和系统软件人才时,甚至会将DPDK作为一项技能罗列在招聘要求中。DPDK从一个最初的小众技术,经过10年的孕育,慢慢走来,直至今日已经逐渐被越来越多的通信、云基础架构厂商接受。同时,互联网上也出现不少介绍DPDK基础理论的文章和博客,从不同的角度对DPDK技术进行剖析和应用,其中很多观点非常新颖。作为DPDK的中国开发团队人员,我们意识到如果能够提供一本DPDK的书籍,进行一些系统性的梳理,将核心的原理进行深入分析,可以更好地加速DPDK技术的普及,触发更多的软件创新,促进行业的新技术发展。于是,就萌发了写这本书的初衷。当然,我们心里既有创作的激动骄傲,也有些犹豫忐忑,写书不是一件简单的事情,但经过讨论和考量,我们逐渐变得坚定,这是一本集结团队智慧的尝试。我们希望能够把DPDK的技术深入浅出地解释清楚,让更多的从业人员和高校师生了解并使用DPDK,促进DPDK发展日新月异,兴起百家争鸣的局面,这是我们最大的愿景。
多核
2005年的夏天,刚加入Intel的我们畅想着CPU多核时代的到来给软件业带来的挑战与机会。如果要充分利用多核处理器,需要软件针对并行化做大量改进,传统软件的并行化程度不高,在多核以前,软件依靠CPU频率提升自动获得更高性能。并行化改进不是一件简单的工作,许多软件需要重新设计,基本很难在短期实现,整个计算机行业都对此纠结了很久。2005年以前,整个CPU的发展历史,是不断提升芯片运算频率核心的做法,软件性能会随着处理器的频率升高,即使软件不做改动,性能也会跟着上一个台阶。但这样的逻辑进入多核时代已无法实现。首先我们来看看表2所示的Intel?多核处理器演进。
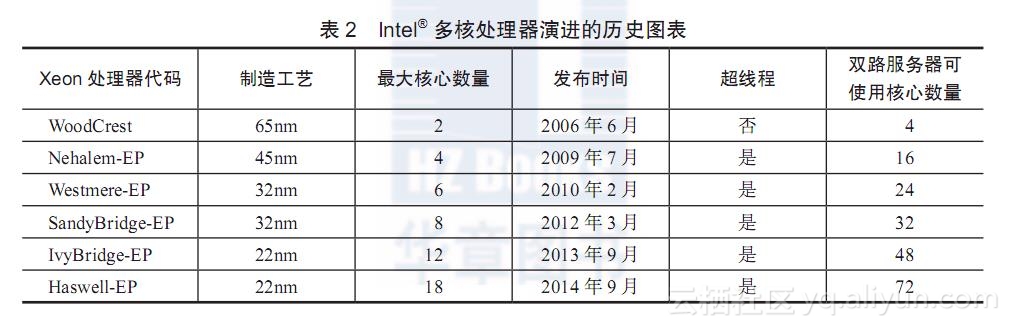
在过去10年里,服务器平台的处理器核心数目扩展了很多。表2参考了英特尔至强系列的处理器的核心技术演进历史,这个系列的处理器主要面向双通道(双路)服务器和相应的硬件平台。与此同时,基于MIPS、Power、ARM架构的处理器也经历着类似或者更加激进的并行化计算的路线图。在处理器飞速发展的同时,服务器平台在硬件技术上提供了支撑。基于PCI Express的高速IO设备、内存访问与带宽的上升相辅相成。此外,价格和经济性优势越发突出,今天一台双路服务器的价格可能和10年前一台高端笔记本电脑的价格类似,但计算能力达到甚至超越了当年的超级计算机。强大的硬件平台为软件优化技术创新蕴蓄了温床。
以太网接口技术也经历了飞速发展。从早期主流的10Mbit/s与100Mbit/s,发展到千兆网(1Gbit/s)。到如今,万兆(10Gbit/s)网卡技术成为数据中心服务器的主流接口技术,近年来,Intel等公司还推出了40Gbit/s、100Gbit/s的超高速网络接口技术。而CPU的运行频率基本停留在10年前的水平,为了迎接超高速网络技术的挑战,软件也需要大幅度创新。
结合硬件技术的发展,DPDK(Data Plane Development Kit),一个以软件优化为主的数据面技术应时而生,它为今天NFV技术的发展提供了绝佳的平台可行性。
IXP
提到硬件平台和数据面技术,网络处理器是无法绕过的话题。电信行业通常使用网络处理器或类似芯片技术作为数据面开发平台首选。Intel此前也曾专注此领域,2002年收购了DEC下属的研究部门,在美国马萨诸塞州哈德逊开发了这一系列芯片,诞生了行业闻名的Intel Exchange Architecture Network Processor(IXP4xx、IXP12xx、IXP24xx、IXP28xx)产品线,曾取得行业市场占有率第一的成绩。即使今日,相信很多通信业的朋友,还对这些处理器芯片有些熟悉或者非常了解。IXP内部拥有大量的微引擎(MicroEngine),同时结合了XSCALE作为控制面处理器,众所周知,XSCALE是以ARM芯片为核心技术的一种扩展。
2006年,AMD向Intel发起了一场大战,时至今日结局已然明了,Intel依赖麾下的以色列团队,打出了新一代Core架构,迅速在能效比上完成超车。公司高层同时确立了Tick-Tock的研发节奏,每隔两年推出新一代体系结构,每隔两年推出基于新一代制造工艺的芯片。这一战略基本保证了每年都会推出新产品。当时AMD的处理器技术一度具有领先地位,并触发了Intel在内部研发架构城门失火的状况下不得不进行重组,就在那时Intel的网络处理器业务被进行重估,由于IXP芯片系列的市场容量不够大,Intel的架构师也开始预测,通用处理器多核路线有取代IXP专用处理芯片的潜力。自此,IXP的研发体系开始调整,逐步转向使用Intel CPU多核的硬件平台,客观上讲,这一转型为DPDK的产生创造了机会。时至今日,Intel还保留并发展了基于硬件加速的QuickAssist技术,这和当日的IXP息息相关。由此看来,DPDK算是生于乱世。
DPDK的历史
网络处理器能够迅速将数据报文接收入系统,比如将64字节的报文以10Gbit/s的线速也就是14.88Mp/s(百万报文每秒)收入系统,并且交由CPU处理,这在早期Linux和服务器平台上无法实现。以Venky Venkastraen、Walter Gilmore、Mike Lynch为核心的Intel团队开始了可行性研究,并希望借助软件技术来实现,很快他们取得了一定的技术突破,设计了运行在Linux用户态的网卡程序架构。传统上,网卡驱动程序运行在Linux的内核态,以中断方式来唤醒系统处理,这和历史形成有关。早期CPU运行速度远高于外设访问,所以中断处理方式十分有效,但随着芯片技术与高速网络接口技术的一日千里式发展,报文吞吐需要高达10Gbit/s的端口处理能力,市面上已经出现大量的25Gbit/s、40Gbit/s甚至100Gbit/s高速端口,主流处理器的主频仍停留在3GHz以下。高端游戏玩家可以将CPU超频到5GHz,但网络和通信节点的设计基于能效比经济性的考量,网络设备需要日以继夜地运行,运行成本(包含耗电量)在总成本中需要重点考量,系统选型时大多选取2.5GHz以下的芯片,保证合适的性价比。I/O超越CPU的运行速率,是横在行业面前的技术挑战。用轮询来处理高速端口开始成为必然,这构成了DPDK运行的基础。
在理论框架和核心技术取得一定突破后,Intel与6wind进行了合作,交由在法国的软件公司进行部分软件开发和测试,6wind向Intel交付了早期的DPDK软件开发包。2011年开始,6wind、Windriver、Tieto、Radisys先后宣布了对Intel DPDK的商业服务支持。Intel起初只是将DPDK以源代码方式分享给少量客户,作为评估IA平台和硬件性能的软件服务模块,随着时间推移与行业的大幅度接受,2013年Intel将DPDK这一软件以BSD开源方式分享在Intel的网站上,供开发者免费下载。2013年4月,6wind联合其他开发者成立www.dpdk.org的开源社区,DPDK开始走上开源的大道。
开源
DPDK在代码开源后,任何开发者都被允许通过www.dpdk.org提交代码。随着开发者社区进一步扩大,Intel持续加大了在开源社区的投入,同时在NFV浪潮下,越来越多的公司和个人开发者加入这一社区,比如Brocade、Cisco、RedHat、VMware、IBM,他们不再只是DPDK的消费者,角色向生产者转变,开始提供代码,对DPDK的代码进行优化和整理。起初DPDK完全专注于Intel的服务器平台技术,专注于利用处理器与芯片组高级特性,支持Intel的网卡产品线系列。
DPDK 2.1版本在2015年8月发布,几乎所有行业主流的网卡设备商都已经加入DPDK社区,提供源代码级别支持。另外,除了支持通用网卡之外,能否将DPDK应用在特别的加速芯片上是一个有趣的话题,有很多工作在进行中,Intel最新提交了用于Crypto设备的接口设计,可以利用类似Intel的QuickAssit的硬件加速单元,实现一个针对数据包加解密与压缩处理的软件接口。
在多架构支持方面,DPDK社区也取得了很大的进展,IBM中国研究院的祝超博士启动了将DPDK移植到Power体系架构的工作,Freescale的中国开发者也参与修改,Tilera与Ezchip的工程师也花了不少精力将DPDK运行在Tile架构下。很快,DPDK从单一的基于Intel平台的软件,逐步演变成一个相对完整的生态系统,覆盖了多个处理器、以太网和硬件加速技术。
在Linux社区融合方面,DPDK也开始和一些主流的Linux社区合作,并得到了越来越多的响应。作为Linux社区最主要的贡献者之一的RedHat尝试在Fedora Linux集成DPDK;接着RedHat Enterprise Linux在安装库里也加入DPDK支持,用户可以自动下载安装DPDK扩展库。RedHat工程师还尝试将DPDK与Container集成测试,并公开发布了运行结果。传统虚拟化的领导者VMware的工程师也加入DPDK社区,负责VMXNET3-PMD模块的维护。Canonical在Ubuntu 15中加入了DPDK的支持。
延伸
由于DPDK主体运行在用户态,这种设计理念给Linux或者FreeBSD这类操作系统带来很多创新思路,也在Linux社区引发一些讨论。
DPDK的出现使人们开始思考,Linux的用户态和内核态,谁更适合进行高速网络数据报文处理。从简单数据对比来看,在Intel的通用服务器上,使用单核处理小包收发,纯粹的报文收发,理想模型下能达到大约57Mp/s(每秒百万包)。尽管在真实应用中,不会只收发报文不处理,但这样的性能相对Linux的普通网卡驱动来说已经是遥不可及的高性能。OpenVSwitch是一个很好的例子,作为主流的虚拟交换开源软件,也尝试用DPDK来构建和加速虚拟交换技术,DPDK的支持在OVS2.4中被发布,开辟了在内核态数据通道之外一条新的用户态数据通道。目前,经过20多年的发展,Linux已经累积大量的开源软件,具备丰富的协议和应用支持,无所不能,而数据报文进出Linux系统,基本都是在Linux内核态来完成处理。因为Linux系统丰富强大的功能,相当多的生产系统(现有软件)运行在Linux内核态,这样的好处是大量软件可以重用,研发成本低。但也正因为内核功能强大丰富,其处理效率和性能就必然要做出一些牺牲。
使用
在专业的通信网络系统中,高速数据进出速率是衡量系统性能的关键指标之一。大多通信系统是基于Linux的定制系统,在保证实时性的嵌入式开发环境中开发出用户态下的程序完成系统功能。利用DPDK的高速报文吞吐优势,对接运行在Linux用户态的程序,对成本降低和硬件通用化有很大的好处,使得以软件为主体的网络设备成为可能。对Intel? x86通用处理器而言,这是一个巨大的市场机会。
对于通信设备厂商,通用平台和软件驱动的开发方式具有易采购、易升级、稳定性、节约成本的优点。
- 易采购:通用服务器作为主流的基础硬件,拥有丰富的采购渠道和供应商,供货量巨大。
- 易升级:软件开发模式简单,工具丰富,最大程度上避免系统升级中对硬件的依赖和更新,实现低成本的及时升级。
- 稳定性:通用服务器平台已经通过大量功能的验证,产品稳定性毋庸置疑。而且,对于专用的设计平台,系统稳定需要时间累积和大量测试,尤其是当采用新一代平台设计时可能需要硬件更新,这就会带来稳定性的风险。
- 节约研发成本和降低复杂性:传统的网络设备因为功能复杂和高可靠性需求,系统切分为多个子系统,每个子系统需要单独设计和选型,独立开发,甚至选用单独的芯片。这样的系统需要构建复杂的开发团队、完善的系统规划、有效的项目管理和组织协调,来确保系统开发进度。而且,由于开发的范围大,各项目之间会产生路径依赖。而基于通用服务器搭建的网络设备可以很好地避免这些问题。
版权
DPDK全称是Data Plane Development Kit,从字面解释上看,这是专注于数据面软件开发的套件。本质上,它由一些底层的软件库组成。目前,DPDK使用BSD license,绝大多数软件代码都运行在用户态。少量代码运行在内核态,涉及UIO、VFIO以及XenDom0,KNI这类内核模块只能以GPL发布。BSD给了DPDK的开发者和消费者很大的自由,大家可以自由地修改源代码,并且广泛应用于商业场景。这和GPL对商业应用的限制有很大区别。作为开发者,向DPDK社区提交贡献代码时,需要特别注意license的定义,开发者需要明确license并且申明来源的合法性。
社区
参与DPDK社区[Ref1-1](www.dpdk.org)就需要理解它的运行机制。目前,DPDK的发布节奏大体上每年发布3次软件版本(announce@dpdk.org),发布计划与具体时间会提前公布在社区里。DPDK的开发特性也会在路标中公布,一般是通过电子邮件列表讨论dev@dpdk.org,任何参与者都可以自由提交新特性或者错误修正,具体规则可以参见www.dpdk.org/dev,本书不做详细解读。对于使用DPDK的技术问题,可以参与user@dpdk.org进入讨论。
子模块的维护者名单也会发布到开源社区,便于查阅。在提交代码时,源代码以patch方式发送给dev@dpdk.org。通常情况下,代码维护者会对提交的代码进行仔细检查,包括代码规范、兼容性等,并提供反馈。这个过程全部通过电子邮件组的方式来完成,由于邮件量可能巨大,如果作者没有得到及时回复,请尝试主动联系,提醒代码维护人员关注,这是参与社区非常有效的方式。开发者也可以在第一次提交代码时明确抄送相关的活跃成员和专家,以得到更加及时的反馈和关注。
目前,开源社区的大量工作由很多自愿开发者共同完成,因此需要耐心等待其他开发者来及时参与问答。通过提前研究社区运行方式,可以事半功倍。这对在校学生来说更是一个很好的锻炼机会。及早参与开源社区的软件开发,会在未来选择工作时使你具有更敏锐的产业视角和技术深度。作为长期浸润在通信行业的专业人士,我们强烈推荐那些对软件有强烈兴趣的同学积极参与开源社区的软件开发。
贡献
本书由目前DPDK社区中一些比较资深的开发者共同编写,很多作者是第一次将DPDK的核心思想付诸于书面文字。尽管大家已尽最大的努力,但由于水平和能力所限,难免存在一些瑕疵和不足,也由于时间和版面的要求,很多好的想法无法在本书中详细描述。但我们希望通过本书能够帮助读者理解DPDK的核心思想,引领大家进入一个丰富多彩的开源软件的世界。在本书编纂过程中我们得到很多朋友的帮助,必须感谢上海交通大学的金耀辉老师、中国科学技术大学的华蓓和张凯老师、清华大学的陈渝教授、中国电信的欧亮博士,他们给了我们很多中肯的建议;另外还要感谢李训和刘勇,他们提供了大量的资料和素材,帮助我们验证了大量的DPDK实例;还要感谢我们的同事杨涛、喻德、陈志辉、谢华伟、戴启华、常存银、刘长鹏、Jim St Leger、MJay、Patrick Lu,他们热心地帮助勘定稿件;最后还要特别感谢英特尔公司网络产品事业部的领导周晓梅和周林给整个写作团队提供的极大支持。正是这些热心朋友、同事和领导的支持,坚定了我们的信心,并帮助我们顺利完成此书。最后我们衷心希望本书读者能够有所收获。
目 录
引 言
作者介绍
第一部分 DPDK基础篇
第1章 认识DPDK
1.1 主流包处理硬件平台
1.1.1 硬件加速器
1.1.2 网络处理器
1.1.3 多核处理器
1.2 初识DPDK
1.2.1 IA不适合进行数据包处理吗
1.2.2 DPDK最佳实践
1.2.3 DPDK框架简介
1.2.4 寻找性能优化的天花板
1.3 解读数据包处理能力
1.4 探索IA处理器上最艰巨的任务
1.5 软件包处理的潜力——再识DPDK
1.5.1 DPDK加速网络节点
1.5.2 DPDK加速计算节点
1.5.3 DPDK加速存储节点
1.5.4 DPDK的方法论
1.6 从融合的角度看DPDK
1.7 实例
1.7.1 HelloWorld
1.7.2 Skeleton
1.7.3 L3fwd
1.8 小结
第2章 Cache和内存
2.1 存储系统简介
2.1.1 系统架构的演进
2.1.2 内存子系统
2.2 Cache系统简介
2.2.1 Cache的种类
2.2.2 TLB Cache
2.3 Cache地址映射和变换
2.3.1 全关联型Cache
2.3.2 直接关联型Cache
2.3.3 组关联型Cache
2.4 Cache的写策略
2.5 Cache预取
2.5.1 Cache的预取原理
2.5.2 NetBurst架构处理器上的预取
2.5.3 两个执行效率迥异的程序
2.5.4 软件预取 38
2.6 Cache一致性
2.6.1 Cache Line对齐
2.6.2 Cache一致性问题的由来
2.6.3 一致性协议
2.6.4 MESI协议
2.6.5 DPDK如何保证Cache一致性
2.7 TLB和大页
2.7.1 逻辑地址到物理地址的转换
2.7.2 TLB
2.7.3 使用大页
2.7.4 如何激活大页
2.8 DDIO
2.8.1 时代背景
2.8.2 网卡的读数据操作
2.8.3 网卡的写数据操作
2.9 NUMA系统
第3章 并行计算
3.1 多核性能和可扩展性
3.1.1 追求性能水平扩展
3.1.2 多核处理器
3.1.3 亲和性
3.1.4 DPDK的多线程
3.2 指令并发与数据并行
3.2.1 指令并发
3.2.2 单指令多数据
3.3 小结
第4章 同步互斥机制
4.1 原子操作
4.1.1 处理器上的原子操作
4.1.2 Linux内核原子操作
4.1.3 DPDK原子操作实现和应用
4.2 读写锁
4.2.1 Linux读写锁主要API
4.2.2 DPDK读写锁实现和应用
4.3 自旋锁
4.3.1 自旋锁的缺点
4.3.2 Linux自旋锁API
4.3.3 DPDK自旋锁实现和应用
4.4 无锁机制
4.4.1 Linux内核无锁环形缓冲
4.4.2 DPDK无锁环形缓冲
4.5 小结
第5章 报文转发
5.1 网络处理模块划分
5.2 转发框架介绍
5.2.1 DPDK run to completion模型
5.2.2 DPDK pipeline模型
5.3 转发算法
5.3.1 精确匹配算法
5.3.2 最长前缀匹配算法
5.3.3 ACL算法
5.3.4 报文分发
5.4 小结
第6章 PCIe与包处理I/O
6.1 从PCIe事务的角度看包处理
6.1.1 PCIe概览
6.1.2 PCIe事务传输
6.1.3 PCIe带宽
6.2 PCIe上的数据传输能力
6.3 网卡DMA描述符环形队列
6.4 数据包收发——CPU和I/O的协奏
6.4.1 全景分析
6.4.2 优化的考虑
6.5 PCIe的净荷转发带宽
6.6 Mbuf与Mempool
6.6.1 Mbuf
6.6.2 Mempool
6.7 小结
第7章 网卡性能优化
7.1 DPDK的轮询模式
7.1.1 异步中断模式
7.1.2 轮询模式
7.1.3 混和中断轮询模式
7.2 网卡I/O性能优化
7.2.1 Burst收发包的优点
7.2.2 批处理和时延隐藏
7.2.3 利用Intel SIMD指令进一步并行化包收发
7.3 平台优化及其配置调优
7.3.1 硬件平台对包处理性能的影响
7.3.2 软件平台对包处理性能的影响
7.4 队列长度及各种阈值的设置
7.4.1 收包队列长度
7.4.2 发包队列长度
7.4.3 收包队列可释放描述符数量阈值(rx_free_thresh)
7.4.4 发包队列发送结果报告阈值(tx_rs_thresh)
7.4.5 发包描述符释放阈值(tx_free_thresh)
7.5 小结
第8章 流分类与多队列
8.1 多队列
8.1.1 网卡多队列的由来
8.1.2 Linux内核对多队列的支持
8.1.3 DPDK与多队列
8.1.4 队列分配
8.2 流分类
8.2.1 包的类型
8.2.2 RSS
8.2.3 Flow Director
8.2.4 服务质量
8.2.5 虚拟化流分类方式
8.2.6 流过滤
8.3 流分类技术的使用
8.3.1 DPDK结合网卡Flow Director功能
8.3.2 DPDK结合网卡虚拟化及Cloud Filter功能
8.4 可重构匹配表
8.5 小结
第9章 硬件加速与功能卸载
9.1 硬件卸载简介
9.2 网卡硬件卸载功能
9.3 DPDK软件接口
9.4 硬件与软件功能实现
9.5 计算及更新功能卸载
9.5.1 VLAN硬件卸载
9.5.2 IEEE1588硬件卸载功能
9.5.3 IP TCP/UDP/SCTP checksum硬件卸载功能
9.5.4 Tunnel硬件卸载功能
9.6 分片功能卸载
9.7 组包功能卸载
9.8 小结
第二部分 DPDK虚拟化技术篇
第10章 X86平台上的I/O虚拟化
10.1 X86平台虚拟化概述
10.1.1 CPU虚拟化
10.1.2 内存虚拟化
10.1.3 I/O虚拟化
10.2 I/O透传虚拟化
10.2.1 Intel? VT-d简介
10.2.2 PCIe SR-IOV概述
10.3 PCIe网卡透传下的收发包流程
10.4 I/O透传虚拟化配置的常见问题
10.5 小结
第11章 半虚拟化Virtio
11.1 Virtio使用场景
11.2 Virtio规范和原理
11.2.1 设备的配置
11.2.2 虚拟队列的配置
11.2.3 设备的使用
11.3 Virtio网络设备驱动设计
11.3.1 Virtio网络设备Linux内核驱动设计
11.3.2 基于DPDK用户空间的Virtio网络设备驱动设计以及性能优化
11.4 小结
第12章 加速包处理的vhost优化方案
12.1 vhost的演进和原理
12.1.1 Qemu与virtio-net
12.1.2 Linux内核态vhost-net
12.1.3 用户态vhost
12.2 基于DPDK的用户态vhost设计
12.2.1 消息机制
12.2.2 地址转换和映射虚拟机内存
12.2.3 vhost特性协商
12.2.4 virtio-net设备管理
12.2.5 vhost中的Checksum和TSO功能卸载
12.3 DPDK vhost编程实例
12.3.1 报文收发接口介绍
12.3.2 使用DPDK vhost lib进行编程
12.3.3 使用DPDK vhost PMD进行编程
12.4 小结
第三部分 DPDK应用篇
第13章 DPDK与网络功能虚拟化
13.1 网络功能虚拟化
13.1.1 起源
13.1.2 发展
13.2 OPNFV与DPDK
13.3 NFV的部署
13.4 VNF部署的形态
13.5 VNF自身特性的评估
13.5.1 性能分析方法论
13.5.2 性能优化思路
13.6 VNF的设计
13.6.1 VNF虚拟网络接口的选择
13.6.2 IVSHMEM共享内存的PCI设备
13.6.3 网卡轮询和混合中断轮询模式的选择
13.6.4 硬件加速功能的考虑
13.6.5 服务质量的保证
13.7 实例解析和商业案例
13.7.1 Virtual BRAS
13.7.2 Brocade vRouter 5600
13.8 小结
第14章 Open vSwitch(OVS)中的DPDK性能加速
14.1 虚拟交换机简介
14.2 OVS简介
14.3 DPDK加速的OVS
14.3.1 OVS的数据通路
14.3.2 DPDK加速的数据通路
14.3.3 DPDK加速的OVS性能比较
14.4 小结
第15章 基于DPDK的存储软件优化
15.1 基于以太网的存储系统
15.2 以太网存储系统的优化
15.3 SPDK介绍
15.3.1 基于DPDK的用户态TCP/IP栈
15.3.2 用户态存储驱动
15.3.3 SPDK中iSCSI target实现与性能
15.4 小结
附录A 缩略词
附录B 推荐阅读