本节书摘来自华章出版社《伟大的计算原理》一书中的第2章,第2.1节,作者[美]彼得 J. 丹宁(Peter J. Denning)克雷格 H. 马特尔(Craig H. Martell),更多章节内容可以访问云栖社区“华章计算机”公众号查看。
第2章
Great Principles of Computing
计 算 领 域
生物学是一种信息科学。
——David Baltimore
除了理论和实验之外,计算是进行科学研究的第三种方式。
——Kenneth Wilson
科学与科学应用密不可分,如同一个树上结出的多枚果实。
——Louis Pasteur
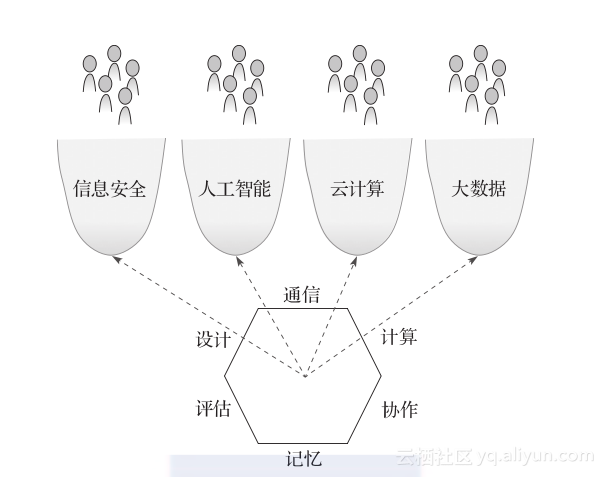
计算活动由人类实施,而不是基本原理。在长期的实践活动中,人们的计算活动逐渐形成了丰富多样的计算领域(computing domain)。每一个计算领域主要关注一项技术或其应用。例如,信息安全领域主要关注信息安全技术,而隐私领域则主要关注如何应用信息安全技术来保护个人的隐私信息。这些领域中的实践者分享相似的问题、技巧、方法,享受计算的基本原理带给他们的权利,同时也受到这些原理的限制。本书所阐述的计算的重要原理不可能脱离这些计算领域而独立存在(Rosenbloom 2012)(见图2.1)。
空气动力学数字仿真是计算领域的一个实例。为了更有效地设计飞机,计算机科学家和航空领域的专家进行了长期的协同工作。自20世纪80年代以来,飞机制造公司开始使用数字仿真技术来设计机翼和机身。传统方法通过风洞和样机进行机翼和机身的设计,对于大尺寸复杂飞机的设计已经不具有可行性。通过运行在大规模并行超级计算机上的新型算法,工程师已经可以在不经过风洞试验的情况下设计出可以安全飞行的飞机。波音777是第一种完全通过数字化设计产生的飞机。航空专家和计算机专家紧密合作,产生了一个新的科学领域——计算流体力学,来计算气流的复杂运动。他们基于3D网格设计出相应的计算方法来求解机身周围空气的流体力学方程。他们探索出一种快速多重网格算法,能够基于超立方体并行处理器网络在很短的时间内完成大尺寸机身的设计工作(Chan and Saad 1986,Denning 1987)。他们还设计了动态网格精化方法,来提高气压和流速变化剧烈区域的计算精度。其中的有些方法甚至体现出了全新的计算基本原理。基于这些进展,计算方法已经成为流体力学不可缺少的构成成分。
图2.1 图中底部所示的6种类型的计算原理都关注于通过管理物质和能量来产生预期的计算行为。而图中上部的计算领域则是实践领域。这些实践领域中的人们通过灵活应用计算的基本原理来求解他们遇到的各种问题(带箭头的虚线)。这些实践领域中的工作为计算也为自身探索出新的基本原理
目前已经发展了丰富多样的计算领域。ACM(Association for Computing Machinery)总结出其成员所关注的42种计算领域,以及数十种的相关的领域(Denning and Frailey 2011)。本章我们简单介绍一下4种计算领域:信息安全、人工智能、云计算、大数据。对每个计算领域,我们重点关注4个方面的因素:
涉及哪些人;
关注什么问题;
涉及哪些计算基本原理;
如何为计算和所在领域带来新的基本原理。
这种分析有可能揭示一些新的基本原理,并帮助实践者理解计算能够给他们带来的利益和限制,也有可能帮助探索不同技术之间的联系,从而为未来的创新埋下伏笔。
在深入这些计算领域之前,我们应该进一步加深对计算领域与计算基本原理两者之间关系的理解。这种理解能够帮助我们更好地分析这些领域。
领域和基本原理
有两种基本策略来表示特定学科的知识体系。一种策略罗列出该学科包含的所有领域,另一种策略则罗列出所有的基本原理。对同一知识空间的不同表示会对实践活动产生不同的指导意义。在本章中,我们使用“领域”(domain)来表示技术领域,即关注特定技术的领域。
教育者通常使用“知识体系”(BOK)一词来表示对特定学科知识的系统化描述,并且基于知识体系来设计相应的课程体系。ACM在1968年给出了关于计算的第一个知识体系,并在1989年、2001年和2013年进行了更新。1989年版本包含了计算的9个核心领域(Denning et al. 1989),2001版本包含了14个(ACM Education Board 2001),2013版本则进一步扩充到18个(ACM Education Board 2013)。之所以将这些子领域称为核心领域,是因为这些领域都或多或少为其他领域提供了基础技术支持。
基本原理框架(如本书所给出的计算基本原理框架)与面向应用领域的框架是正交的。一条基本原理可能会出现在多个领域中,而一个领域可能会依赖于多条基本原理。这些被领域所依赖的基本原理,其演化速度远低于技术的演化速度。
虽然这两种风格的框架具有很大的差异性,但它们也存在紧密的关联。为了更形象地感受到这种紧密关联,我们可以想象这样一个二维矩阵:每一行代表一个领域,每一列代表一类基本原理,所有的单元格则代表了特定方面的知识空间(见图2.2)。

图2.2 关于计算的知识空间可以被表示为一个矩阵:其中,列代表不同类型的基本原理,行代表不同的领域。图中灰色背景的单元格中给出了信息安全领域使用到的两个协作类型的基本原理:密钥分配协议(用于安全地分配密钥);零知识证明(用于在两个参与者之间安全地交换私密信息)
基于这种矩阵,我们可以说:面向技术的知识体系是对该矩阵中行的罗列,而面向基本原理的知识体系则是对矩阵列的罗列。这两种知识体系从不同的角度对相同的知识进行了阐述。
设想一个人试图罗列出一个技术涉及的所有基本原理。这个人可以从基本原理的6种类别出发分析出该技术领域涉及的所有基本原理,即对应于矩阵中的一行(见图2.3)。在本章的余下部分,我们将用这种方式对4个领域涉及的基本原理进行分析。
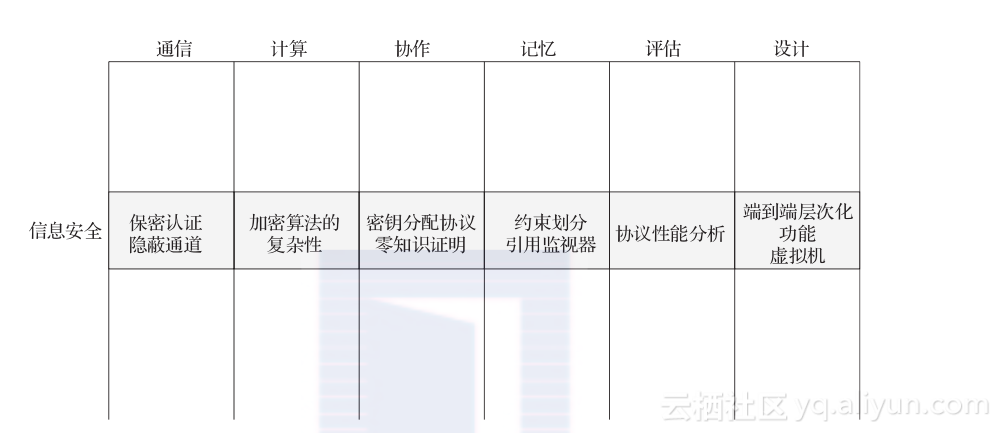
图2.3 安全领域涉及的计算基本原理在矩阵中对应于安全领域所在的那一行。如同大多数的计算领域一样,安全领域涉及的计算基本原理也可以划分为六种类型
这种基本原理框架也指出了另外一种分析方法:一个人可以罗列出涉及特定基本原理的所有技术(见图2.4)。
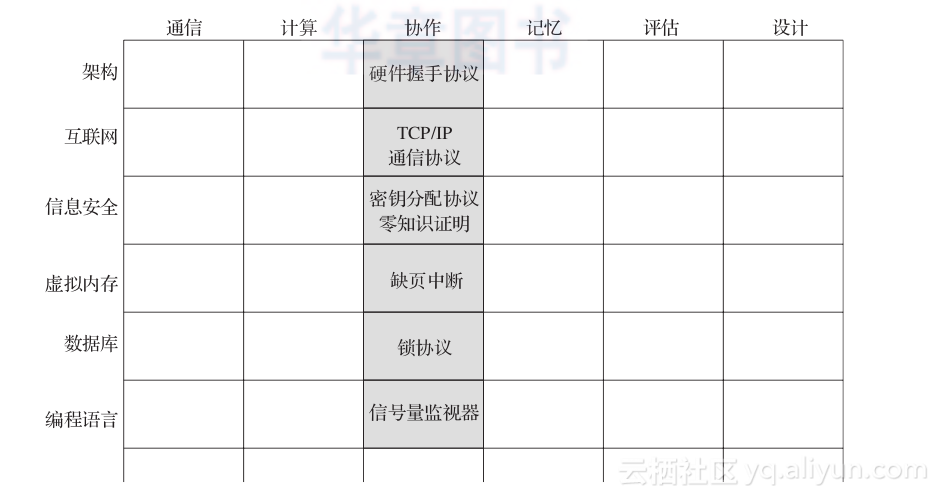
图2.4 协作技术表现为矩阵中协作所在的那一列。在几乎所有的计算领域中(包括列出的6种计算领域)都会涉及协作相关的基本原理
信息安全
信息安全是计算机科学中一个具有悠久历史的领域。甚至在任务批处理大行其道的时代,用户就开始关注存放于计算机中的数据的安全问题。计算机是否存放在一个物理安全的地方?在一个新的任务被装载前,存储器是否已被清空?操作者的错误或硬件失效是否会导致数据的丢失?
1960年左右,随着第一代多道程序分时系统的出现,操作系统的设计者就已经对信息保护问题有了深刻的实践认知。他们设计出各种方式对主存储器进行分区,从而保证不同程序的代码和数据不会混淆在一起。这其中,虚拟存储器是最复杂的一种机制。他们发明了分层文件系统,使得用户可以真正地管理他们的文件,并设定其他用户对这些文件的访问权限。他们发明了密码系统以避免未经授权的用户使用计算机。他们构造了多种结构,以避免特洛伊木马或其他恶意软件对系统和数据的干扰和破坏。他们发明了多种访问控制机制,使得机密信息无法写入公共文件中。他们创建了针对计算机操作者的各种操作策略,以保护数据和防范入侵。自1970年以来,人们已经广泛认识到,保证信息的安全是操作系统设计者一项责无旁贷的任务(Denning 1971,Saltzer and Schroeder 1975)。
20世纪70年代的ARPANET、80年代的Internet、90年代的万维网(World Wide Web)提供了一种世界范围的信息共享网络,也使得信息的丢失或偷盗成为一个更加现实的问题。密码系统在信息安全和身份验证中承担了核心角色(Denning 1982)。设计者在实践中遇到并应对各种问题,比如:数据库记录保护、密码保护、基于生物信息的用户验证、反入侵保护、入侵检测、病毒/蠕虫/恶意软件的防范、多层安全系统、信息流管理、匿名事务、信任分级准则、数据恢复等。法律实践专家开始遇到越来越多的针对计算机系统的犯罪行为,并开始唤醒每个人对个人信息重要性的认识。然而,很少有人认真对待这个问题。为了能够更快地交付新的系统,很多开发者开始降低对信息安全的重视程度。他们认为,等到信息安全问题真正出现后再亡羊补牢,也未为迟也。这种观点注定是错误的。大量可被轻易入侵的系统出现在重要的业务活动中,这些系统缺乏对信息保护的系统性考虑,因而对各种(善意、恶意或无意的)操作采取了宽松容忍的策略。
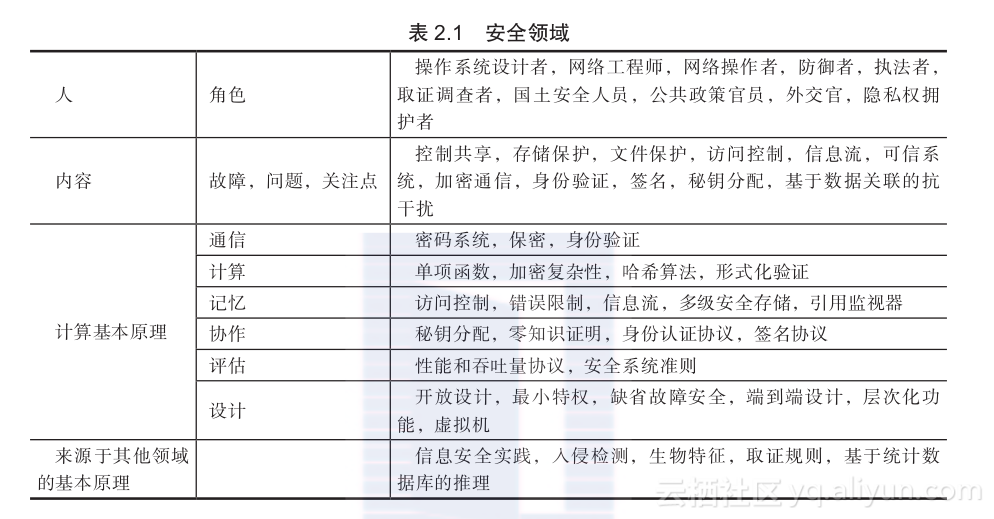
随着越来越多的金融数据、人事数据、个人隐私数据以及公司数据被存储在可在线访问的计算机中,对这些数据的恶意入侵行为出现了极大地增加。安全专家已经开始担忧信息战争的可能性(Denning 1998)。隐私专家则向公众奋力疾呼保护个人隐私数据的重要性,这关系到我们每个人的基本自由(Garf?inkel 2001)。在1999年,公众开始普遍担心“千年虫”问题有可能导致网络的崩溃,这个问题产生的原因是在计算机中一个年份数据被存储为两位而不是四位十进制数。自此以后,人们开始关注到信息网络的脆弱性问题以及保证信息安全的重大挑战。多国专家开始忧虑大规模的信息攻击行为有可能导致世界经济甚至人类文明的毁灭(Schneier 2004,2008,Clark 2012)。表2.1给出了信息安全领域涉及的人、问题以及计算基本原理。
人工智能
让机器可以执行人类智力活动的想法可以追溯到5个世纪之前。1642年,Blaise Pascal建造了一台机械式计算器。1823年,Charles Babbage发明了差分机,用于自动进行算数函数的计算。在19世纪后期,一个名为“mechanical Turk”的自动下棋机器人,在受到广泛关注后最终被发现只是一个恶作剧(Standage 2003)。实际上,很多这些类似的想法都可以被看作人工智能的萌芽(Russell and Norvig 2010)。
1956年,在Claude Shannon和Nathaniel Rochester的帮助下,John McCarthy在德国达特茅斯组织了一次研讨会。这次研讨会标志着人工智能领域的诞生。当时,研究者的一个基本观点是“原则上,人类智能的机理可以被精确地描述出来,因此,可以用机器来仿真人类智能”。这种观点是非常合理的,因为很多人类智力活动似乎就是在执行某种算法,而且人的大脑似乎就是一个可以执行算法的电子化网络。Herbert Simon预测,到1967年计算机可能成为世界象棋冠军,可能发现并证明一些重要的数学定理,而且很多心理学理论可以体现在计算机程序中。他的第一个设想比预计时间迟到了30年才得以实现,而剩下的两个设想目前仍然没有实现。
图灵(1950)为现代人工智能留下了很多火种:图灵测试、机器学习以及通过“成长”形成一台智能机器。图灵意识到,由于对“智能”一词人们始终缺少一个足够明确的定义,以至于无法有效衡量一台机器是否有智能或具有何种程度的智能。他提出的模拟游戏(即图灵测试)不再关注一台机器是否有智能,转而关注一台机器是否表现出智能的行为。他预测,到2000年,机器至少能够让70%的人类评审者在5分钟的时间内无法判断与之交谈的是一台机器还是一个人类。这个设想到目前还没有实现。
图灵关于智能的行为观点在人工智能领域的形成中起到了重要作用。然而,到20世纪70年代,这种观点受到了尖锐的批判。很多人工智能项目开始以设计“专家系统”为目标,即:构造出与某些领域(如医学诊断领域)的人类专家具有相同能力的智能系统。Hubert Dreyfus(1972,1992)则坚持认为,专家的行为绝不是基于规则的机器所能完全模拟的。当时,人们对这种观点嗤之以鼻,但时间证明了这种观点的正确性。只有非常少的专家系统表现出一定的实用价值,但没有一个专家系统能够达到人类专家的水平。John Searle(1984)则认为传统机器具有智能是不可能的:一个基于规则的机器可能可以使用中文与人对话,但机器根本不知道这些中文的含义。他不认同“强人工智能”的概念(即机器行为能产生意识),而更偏向于“弱人工智能”(即机器能够模仿出人类的行为,但这种模仿背后的机制可能与人类大脑的工作机制没有任何相似之处)。Terry Winograd和Fernando Flores(1987)认为人工智能基于某些人类的哲学假设,而这些假设可能根本无法解释智能的工作机理或根本无法导致智能的产生。
到20世纪80年代中期,人们逐渐意识到关于人工智能的很多初始设想很难在短时间内实现。提供研究基金的机构开始停止向人工智能领域提供新的资金支持并且要求已有研究项目提供更为确实的研究成果。缺少资金的支持,很多研究者无法展开具体的研究工作,转而开始认真反思这个领域面临的问题。人工智能领域的先驱者Raj Reddy将这一黑暗时期称为“人工智能的冬天”。
这一时期的反思酝酿了人工智能研究的一个新方向。人们不再关注如何对人类意识活动进行建模,转而去寻求构造一些能够替代人类认知活动的智能系统。自动认知系统的工作原理不需要与人类意识活动的原理相一致。它们甚至根本不去刻意模仿人类解决问题的过程。这一新方向更强调通过实验来确认所提出的自动化工作原理是否有用、可靠和安全(Russell and Norvig 2010,Nilsson 2010)。这一新方向最近引起公众广泛关注的进展包括:1997年IBM深蓝国际象棋程序击败国际象棋世界冠军Garry Kasparov,2010年Google的无人驾驶汽车,2011年IBM的Watson计算机在益智问答游戏节目“危险边缘”中获得冠军(击败人类对手)。这些计算机程序中使用到的方法具有极高的效率,但却没有刻意模仿人类思考或大脑运作的机制。同时,这些方法仅对解决特定的问题有效,而不具有通用性。
计算机科学、认知科学、医学及心理学领域的很多研究者仍然在研究人脑的工作机理和意识的产生机理。Kurzweil的畅销书《奇点临近》(Kurzweil 2005)和2013年对外公布的研究项目Brain Activity Map Project表明,这个研究方向仍然具有非常强大的吸引力。
人工智能的重生显示了巨大的成功,进而产生了一些崭新的关注点。在与机器的竞赛过程中,Erik Brynjolfsson和Andrew McAfee(2012)发现,自动化的浪潮正逐渐取代人类在知识相关领域的工作,正如在上个世纪中机械自动化取代了大量的人类体力劳动。知识自动化的实例包括:电话转接中心、语音菜单系统、在线商品交易、在线银行、政府服务、出版、新闻传播、音乐发布、广告、监管、反恐等方面。笔者所担忧的是我们正滑向一个不需要大量人工劳动的社会,而这个社会又无法为大量失业的人类个体提供充足的资源。
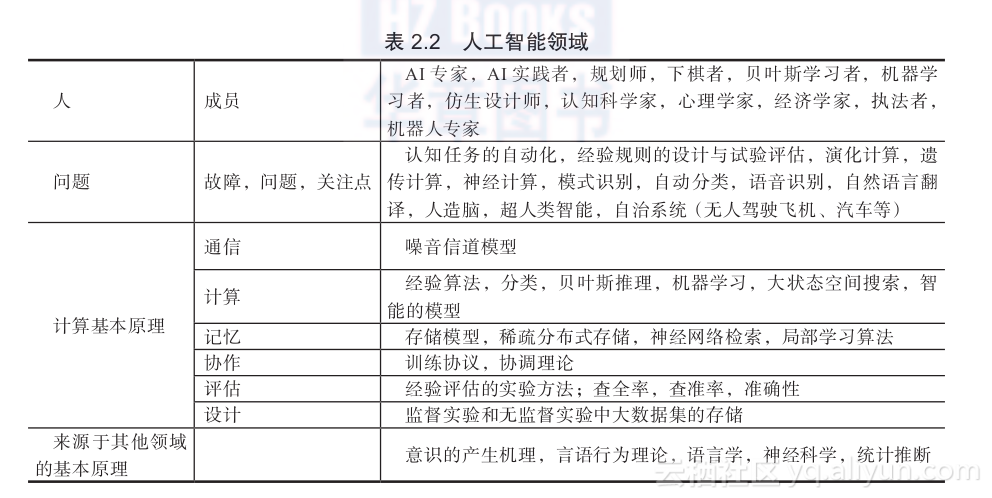
表2.2给出了人工智能领域涉及的人、问题以及计算基本原理。
云计算
云计算是一个现代的时髦概念,其背后隐藏了关于信息共享和分布式计算的丰富含义。大量计算设备的互联产生了一种规模经济:在其中,人们不再关注服务和数据存放的物理位置。“云”这个术语出现在20世纪90年代后期,可能是在相关的技术或市场研讨中,人们使用云来比喻由计算机构成的网络。
早在20世纪60年代中期,MIT的MAC项目已经体现出了类似的想法,即:构建一种能够向众多用户提供计算资源共享的系统。MAC是词组“Multiple-Access Computer”中单词的首字母缩写,有时也代表“Man And Computer”。该项目产生了Multics系统,一个强大的可以对内存、外存、CPU等昂贵的计算资源进行分时复用的多道程序系统(每个用户使用这些资源的成本得到了极大的降低)。J. C. R. Licklider是这种思想灵感的提出者。他认为,计算资源应该成为一种基础设施,任何人都应该可以很方便地接入其中(Licklider 1960)。
在1969年底开始运作的计算机网络ARPANET使得“计算成为基础设施”的宏伟设想得以成真。ARPANET的设计目标就是资源共享:接入网络的任何用户都可以与网络中的其他计算节点互联并使用其上提供的服务。因此,没有必要去复制一个已经共享的服务(在服务质量能够得到保障的前提下)。ARPANET的设计者很快意识到,共享服务应该通过名称而不是物理位置来进行访问,因此,开发一种位置无关的寻址系统对于屏蔽网络通信的底层细节至关重要。Vint Cerf和Bob Kahn发明了TCP/IP通信协议(1974),能够支持互联网上的任何两台计算机在仅知晓对方IP地址(一种逻辑地址)而无需知晓物理地址的情况下进行信息传递。1983年,ARPANET开始正式使用TCP/IP协议。
1984年,ARPANET开始使用域名系统,一种将特定的字符串映射到IP地址的在线数据库(例如,将字符串“gmu.edu”映射为IP地址“129.174.1.38”)。域名系统带来了另一个层次上的位置无关性:用户现在只需要记住一些具有语音信息的字符串,就能够访问对应的互联网服务。
到20世纪90年代,万维网(World Wide Web)的出现使得任何信息对象都可以在互联网上进行共享。信息对象使用URL(Uniform Resource Locator,统一资源定位符)进行命名。URL的基本格式是“主机名/路径名”,其中路径名指出了一个信息对象在给定主机上的目录位置。20世纪90年代中期,Robert Kahn设计了一个互联网服务handle.net。该服务可以把一个具有唯一性的标识符映射为一个信息对象的URL。基于此,他还为美国国会图书馆和大多数的出版商设计了DOI(Digital Object Identif?ier,数字对象标识符)系统(Kahn and Wilensky 2006)。DOI提供了更高层级的透明性:一旦为一个数字对象赋予一个DOI之后,这个DOI将永久指向该数字对象,无论该对象存放在何处或何时被创建(Denning and Kahn 2010)。
面向终端用户的分布式计算服务的技术架构在近年来持续发展。Multics系统使得一个大型计算机系统可以在其用户间分享计算资源。20世纪70年代,施乐Palo Alto研究中心(PARC)构造了Alto系统,一个由连接至以太网的一组图形工作站形成的网络(Metcalfe and Boggs 1983)。施乐将该系统的体系结构命名为“客户端-服务器”架构,因为用户总是通过一个本地的接口(客户端)来访问网络上的服务。X-Window系统(1984年源于MIT)是一个通用的客户端-服务器系统:它支持一个新的服务提供者将其硬件和用户接口接入网络,而无需设计相应的客户端-服务器通信协议。今天,大多数的web服务都使用了客户端-服务器架构:服务提供者通过展现在标准web浏览器上的界面为用户提供服务。大多数云中的服务也采用客户端-服务器架构,其中URL系统对服务器的物理位置进行了完全的屏蔽。
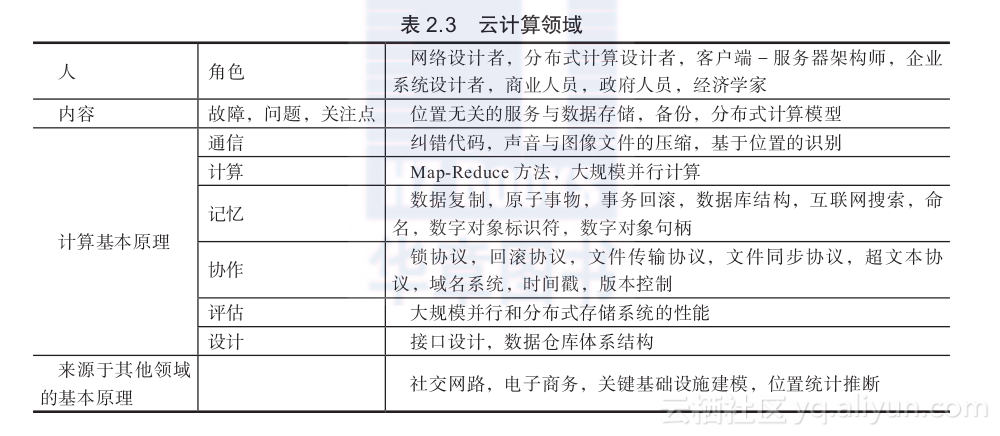
表2.3给出了云计算领域涉及的人、问题以及计算基本原理。
大数据
大数据是最近出现的另一个时髦概念,其背后隐藏了关于计算的丰富信息。大数据关注如何对互联网上的海量数据进行分析,从中发现有价值的统计规律和相关性等信息。这种分析可以广泛应用于各种领域,例如科学、工程、商业、人口普查、执法等。
计算机科学家对数据的存储、查询及处理已经进行了长时间的关注,而且很多关注的问题甚至比目前的技术进展还要超前。可惜的是,这些超前的想法由于各种因素的影响被埋没在历史的尘埃中,被大众所遗忘。“大数据”这一术语在很大程度上是新瓶装旧酒,虽然这一术语确实对很多领域产生了显著的影响。例如,在商业活动中,商业组织收集海量的客户相关数据,并利用这些数据去发现市场趋势、广告投放对象以及客户忠诚度等信息。受到公共资金资助的科研项目也被要求对外公开其数据,以方便公众和其他科研项目能够对这些数据进行多方面的利用和分析。警察系统则利用海量的通信信息和信用卡交易信息,从中发现犯罪分子。所有这些领域都开始主动寻求数据科学家、数据分析师以及数据系统设计师来帮助他们进行数据分析工作。
计算机科学家在其中的贡献主要体现在两个方面。一方面是关于更高效地数据分析方法,另一方面则是能够支持海量数据处理的系统或技术架构。例如,Richard Karp(1993)基于组合方法实现了对基因数据片段进行融合从而形成基因组图谱的高效算法。Tony Chan和Yousef Saad(1986)的研究工作表明,hypercube(一种早期出现的并行计算架构)对于多重网格算法(一类重要的数字计算方法)具有最优的效果,而多重网格算法能够对大规模数据空间的数学模型进行求解。Jeffrey Dean和Sanjay Ghemawat(2008)设计了MapReduce算法,能够支持数千个处理器通过并行的方式对海量数据进行处理。
在商业领域中,如何对大规模数据集进行处理和分析一直以来都是一个重要的问题。商业组织会收集关于客户、库存、产品制造、财务等方面的各种数据,这些数据对于一个大型的国际化商业组织的正常运转具有非常重要的作用。20世纪30年代,一个电子计算机还未出现的年代,IBM靠出售类似卡片分类器和检索器的简单设备从数据处理市场获得了巨大的财富。20世纪50年代,IBM开始向电子数据处理领域发展,转型成为一家计算机公司。1956年,IBM对外发布了第一个硬盘存储系统RAMAC 305,受到了广泛关注。IBM声称,任何商业组织都可以将其堆满仓库的文件资料转移到一个小小的硬盘中,进而能够对数据进行极为高效的处理。随着数据存储需求的不断增长,设计者开始关注如何对数据进行有效的组织从而实现对数据的快速访问和简易维护。当时,两个主流且存在竞争关系的方法分别是综合数据系统(Integrated Data System,IDS)(Bachman 1973)和关系数据库系统(Relational Database System,RDS)(Codd 1970,1990)。综合数据系统具有简单、快速、实用等特点,能够在管理大量数据文件的同时隐藏文件在硬盘上的物理结构和位置。关系数据库系统则基于数学化的集合理论,它具有一个非常清晰的概念模型,但在经过了多年的发展后才实现了与综合数据系统相当的处理效率。从20世纪70年代开始,研究领域形成了一个关于大规模数据库(very large databases)的研究团体,并每年召开一次学术会议(VLDB)对相关议题进行讨论。
从20世纪50年代开始,计算领域的研究者进入了文档管理领域:帮助文档管理员组织数据以实现更加快速的文档检索。图书馆是这些信息检索系统的第一代用户。研究者开发了模糊查询系统。例如,用户可以发出“请查找关于信息检索的文档”,而返回的文档中不一定包含“信息检索”这个字符串。今天,互联网就是一个巨大的无结构的存储系统。在互联网上进行关键词检索非常快速但却不够准确,因此,有效的互联网信息检索仍然是一个困难的问题(Dreyfus 2001)。
Gartner Group将现代的“大数据”定义为4V:数据体量巨大(Volume)、数据的产生速度快(Velocity)、数据的表现格式丰富(Variety)、数据对决策活动具有重要的支持作用(Veracity is important to decisions)。从2014年开始,数据科学的课程或关于数据科学的研究中心在大学和其他研究机构中如雨后春笋般出现。多个领域都涉及其中,例如,来自运筹学和统计学领域的分析师、来自计算机科学和信息系统领域的架构设计师以及来自建模和仿真领域的可视化工程师。这些实践和研究活动也确立了“数据科学”领域的主要研究问题:寻找对大规模数据集进行处理和分析的科学理论基础。
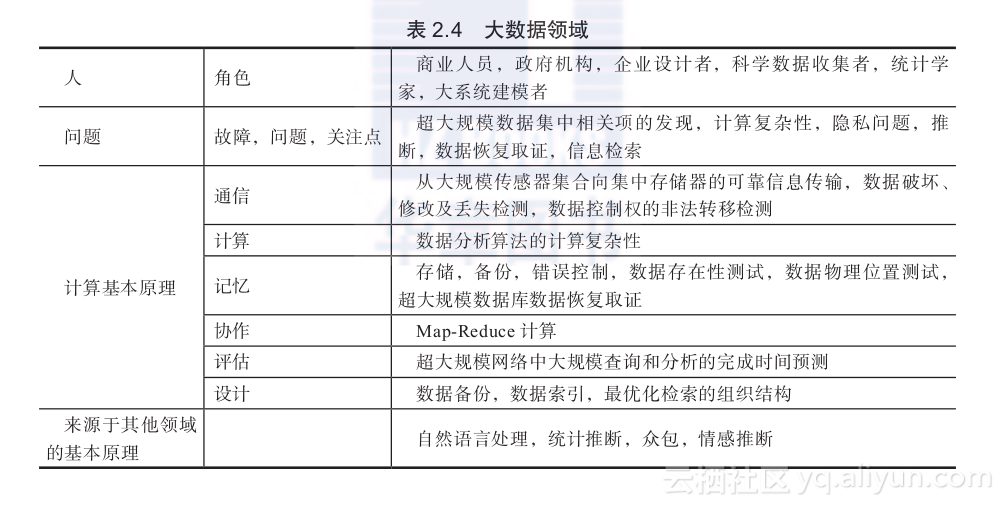
表2.4给出了大数据领域涉及的人、问题以及计算基本原理。
总结
本书采用的关于计算重要原理的框架提供了一种有效的方式去分析特定技术所涉及的基本原理。这种框架也可以用来分析特定计算应用领域背后所基于的计算基本原理,在这些领域中,具有不同技术或工程背景的人之间相互配合来解决该应用领域中存在的问题。