1.2 大数据特征
大数据的数据集至少拥有一个或多个在解决方案设计和分析环境架构中需要考虑的特征。这些特征大多数由道格·兰尼早在2001年发布的一篇讨论电子商务数据的容量、速率和多样性对企业数据仓库的影响的文章中最先提出。考虑到非结构化数据的较低信噪比需要,数据真实性随后也被添加到这个特征列表中。最终,其目的还是执行能够及时向企业传递高价值、高质量结果的分析。
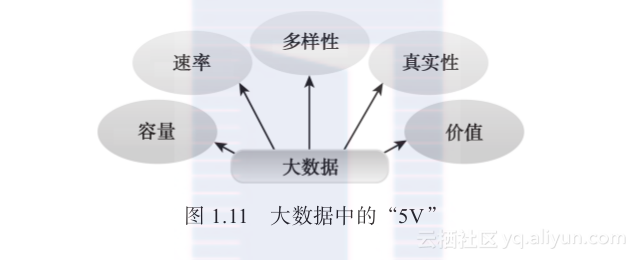
这一节将探究5个大数据的特征,这些特征可以用来将大数据的“大”与其他形式的数据区分开。这5个大数据的特征如图1.11所示,我们也常常称为5V:容量(volume);速率(velocity);多样性(variety);真实性(veracity);价值(value)。
1.2.1 容量
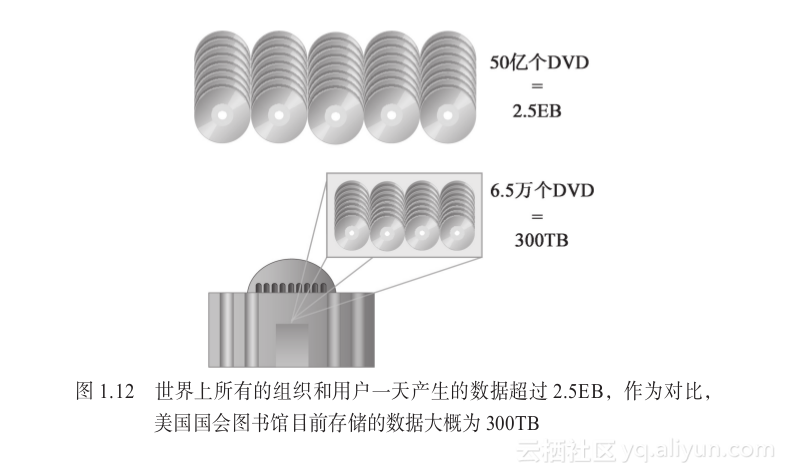
最初考虑到数据的容量,是指被大数据解决方案所处理的数据量大,并且在持续增长。数据容量大能够影响数据的独立存储和处理需求,同时还能对数据准备、数据恢复、数据管理的操作产生影响。图1.12形象地展示了每天来自世界范围内的组织和用户所产生的大量数据。
典型的生成大量数据的数据源包括:
在线交易,例如官方在线销售点和网银。
科研实验,例如大型强子对撞机和阿塔卡玛大型毫米及次毫米波阵列望远镜。
传感器,例如GPS传感器,RFID标签,智能仪表或者信息技术。
社交媒体、脸书(Facebook)和推特(Twitter)等。
1.2.2 速率
在大数据环境中,数据产生得很快,在极短的时间内就能聚集起大量的数据集。从企业的角度来说,数据的速率代表数据从进入企业边缘到能够马上进行处理的时间。处理快速的数据输入流,需要企业设计出弹性的数据处理方案,同时也需要强大的数据存储能力。
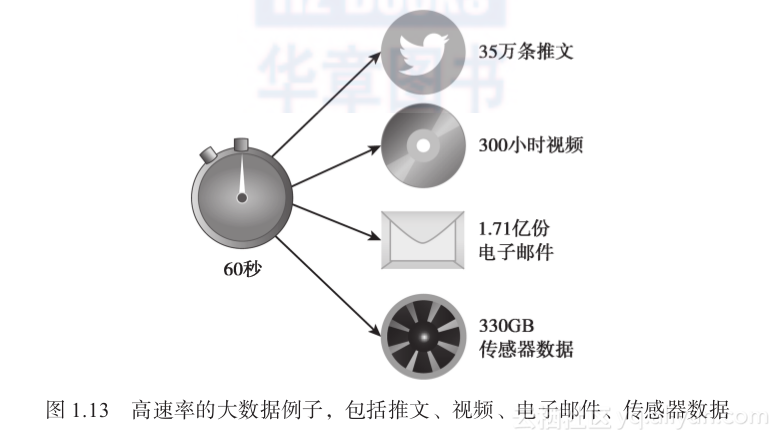
根据数据源的不同,速率不可能一直很快。例如,核磁共振扫描图像不会像高流量Web服务器的日志条目生成速度那么快。图1.13给出了高速率大数据生成示例,一分钟内能够生成下列数据:35万条推文、300小时的YouTube视频、1.71亿份电子邮件,以及330GB飞机引擎的传感器数据。
1.2.3 多样性
数据多样性指的是大数据解决方案需要支持多种不同格式、不同类型的数据。数据多样性给企业带来的挑战包括数据聚合、数据交换、数据处理和数据存储等。图1.14展示了数据多样性的可视化形象,其中包括经济贸易的结构化数据,电子邮件的半结构化数据以及图像等非结构化数据。
1.2.4 真实性
数据真实性指的是数据的质量和保真性。进入大数据环境的数据需要确保质量,这样可以使数据处理消除掉不真实的数据和噪音。就数据的真实性而言,数据在数据集中可能是信号,也可能是噪音。噪音是无法被转化为信息与知识的,因此它们没有价值,相对应的,信号则能够被转化成有用的信息并且具有价值。信噪比越高的数据,真实性越高。从可控的行为中获取的数据(例如通过网络消费注册获得的数据)常常比通过不可控行为(例如发布的博客等)获取的数据拥有更少的噪音。而数据的信噪比独立于数据源和数据类型。
1.2.5 价值
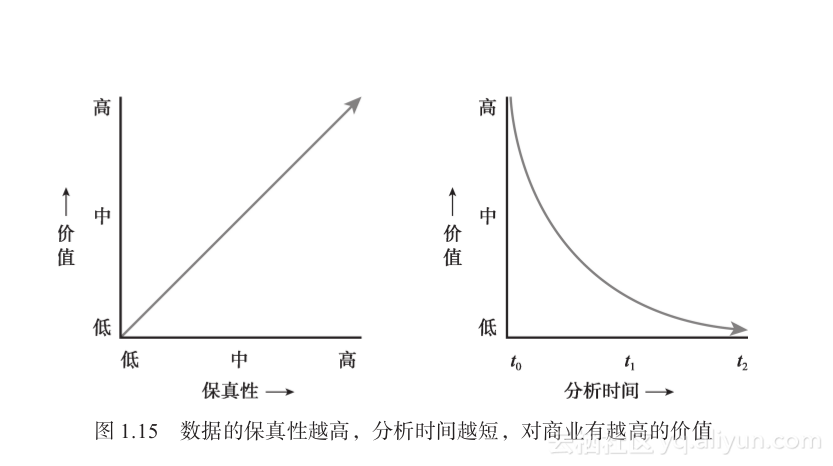
数据的价值是指数据对一个企业的有用程度。价值特征直观地与真实性特征相关联,真实性越高,价值越高。同时,价值也依赖于数据处理的时间,因为分析结果具有时效性。例如20分钟的股票报价延迟与20毫秒的股票报价延迟相比,明显后者的价值远大于前者。正如前面所说,价值与时间紧密相关。数据转变为有意义的信息的时间越长,这份信息对于商业的价值就越小。过时的结果将会抑制决策的效率和质量。图1.15阐述了价值是如何被数据真实性以及生成结果的时间所影响的。
除了数据真实性和时间,价值也受如下几个生命周期相关的因素影响:
数据是否存储良好?
数据有价值的部分是否在数据清洗的时候被删除了?
数据分析时我们提出的问题是正确的吗?
数据分析的结果是否准确地传达给了做决策的人员?