Functional Programming
A key characteristic of Clojure is that it is a functional language, which means that functions are the fundamental building-block for programs rather than instructions, as is the case in most other programming languages (known asimperative languages).
Note Nearly all programming languages have some construct called a function. In most programming languages, the best way to think of a function is as a subroutine, a series of instructions that are grouped together for convenience. In Clojure and other functional languages, functions are best thought of as more like their counterparts in mathematics—a function is simply an operation that takes a number of parameters (also called arguments) and returns a value.
对于函数语言, 函数是代码最基本的单位, 而其他命令(imperative )语言, 最基本的单位是指令(instructions)
函数几乎在每个语言里面都有, 但是在大部分语言中function只是作为子程序(subroutine), 为了方便将一系列指令组合在一起. 而对于clojure, 函数更接近于他在数学上的概念, 函数只是一个有参数和返回值的operation
Imperative languages perform complex tasks by executing large numbers of instructions, which sequentially modify a program state until a desired result is achieved.
Functional languages achieve the same goal through nested function composition—passing the result of one function as a parameter to the next. By composing and chaining function calls, along with recursion (a function calling itself), a functional program can express any possible task that a computer is capable of performing.
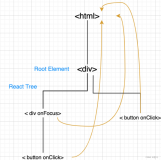
An entire program can itself be viewed as a single function, defined in terms of smaller functions. The nesting structure determines the computational flow, and all the data is handled through function parameters and return values (see Figures 1-1 and 1-2).


命令语言通过执行大量的指令, 不断的改变程序状态来达到最终的结果
函数语言通过函数的嵌套, 一个函数的返回作为下一个的参数,来得到最终的结果.
通过上面两个图就可以很好的看出不同的执行过程...
下面这段很有意思, 介绍两种语言的历史, 分别来源于图灵机和lambda算子...但是这两种计算模型其实是等价的, 所以function language可以handle所有imperative可以解决的问题
Equivalency of Functional and Imperative Styles
It is an important fact of computer science that the functional and imperative models of computation are formally equivalent, and therefore equally capable of expressing any computational task.
This notion dates back to the earliest days of computer science. Alan Turing's seminal paper, On Computable Numbers (1936) describes the abstract workings of an imperative computer, which became known as the Turing Machine. It was to become the conceptual model upon which modern computer architectures are based.
Earlier that year, Alonzo Church had independently written another paper called, An Unsolvable Problem of Elementary Number Theory. In this paper, he created a formal system known as
the lambda calculus—the formal system upon which functional languages are based.
These two ways of expressing computability were quickly recognized to be mathematically equivalent, and became known collectively as the Church-Turing thesis. This thesis, in addition to being extremely important to several fields of mathematics, became the starting point for the fledgling field of computer science.
Purely Functional Programming
纯不纯从下面的图, 很容易看明白, 纯的完全没有state和side effect
State is any data the program stores that can possibly be changed by more than one piece of code.
Side effects are anything a function does when it is executed, besides just returning a value. If it changes program state, writes to a hard disk, or performs any kind of IO, it has executed a side effect.

Purely functions have a number of advantages:
• They are remarkably easy to parallelize. Since each function is a distinct, encapsulated unit, it does not matter if functions are run in the same process or even on the same machine.
非常有利于并行运行, 因为没有状态改变, 不要做同步
• Pure functions lead to a high degree of code encapsulation and reusability. Each function is effectively a black box. Therefore, understand the inputs and the outputs, and you understand the function. There's no need to know or care about the implementation. Object-oriented languages try to achieve this with objects, but actually it is impossible to guarantee, because objects have their own state. An object’s type and method signatures can never tell the whole story; programmers also have to account for how it manages its state and how its methods impact that state. In a complex system, this quickly grows in complexity and often the advantages of class encapsulation quickly disappear. A pure function, however, is guaranteed to be entirely described by its nterface—no extra knowledge required.
有利于代码的封装和重用, function完全是一个黑盒, 只用关心input和output.
在面向对象编程时也应该考虑, 尽量减少全局变量, 减少耦合, 否则黑盒就会越来越烫…
但是对于function language天然就有这个优势...
• They are easier to reason about. In a purely functional program, the execution tree is very straightforward. By tracing the function call structure, you can tell exactly and entirely what the program is doing. In order to understand an imperative, stateful program you need not only to understand the code, but all of the possible permutations of state that may exist at any point in time. Purely functional code is much more transparent. In some cases, it is even possible to write tools that do automated analysis and transformations of source code, something that is next to impossible in an imperative language.
利于调试, purely function program的问题是每次必现的, 不会出现很多由于状态改变导致的不可重现的问题...蛋疼
• Pure functions are very easy to write unit tests for. One of the most difficult aspects of unit testing is anticipating and accounting for all the possible combinations of state and execution paths. Pure functions have well-defined, stateless behavior that is extremely simple to test.
利于UT,
在面向对象写过UT的都知道, 有时候UT是很困难的, 很多function都是依赖外部状态的, 比如读写数据库等
Clojure’s Compromise, 妥协
Of course, most programs can't be programmed entirely in pure functions.
Side effects are inevitable. Displaying something to the screen, reading from a file on a hard disk, or sending a message over a network are all examples of side effects that cannot be dispensed with.
Similarly, programs can't do entirely without state. The real world is stateful, and real-world programs need to store and manipulate data that can change over time.
In effect, Clojure does not enforce functional purity. A few languages do, such as Haskell, but they are (rightly or wrongly) considered to be academic, difficult to learn, and difficult to apply to problems found in the real world. Clojure's goal is not to prevent programmers from using state or side effects, but to make it safe and straightforward.
pure function非常好, 但是side effects无处不在, print, I/O操作...并且现实世界充满了stateful, 所以pure function很难用来解决实际问题, 比如Haskell
Clojure选择做出妥协, 既尽量保留pure function带来的好处, 又融入side effects和state(在严格的监管下)
对于Side effects, 显式的当做exception放在自然的程序flow之外
对于state, 放在thread-safe structures, 来避免冲突和竞争
Clojure has two ways of maintaining functional purity as much as possible while still allowing a developer to easily do everything they need.
• Side effects are explicit, and the exception rather than the rule.
They are simple to add, when necessary, but they stand out from the natural flow of the language. This ensures that developers are precisely aware of when and why they occur and
what their precise effects are.
• All program state is contained in thread-safe structures, backed by Clojure’s thoughtfully planned inventory of concurrency-mangement features. This ensures that with an absolute minimum of effort, program state is always safe and consistent. Updates to state are explicit and atomic and clearly identifiable.
Caution There is a major exception to Clojure’s rules about state management and side effects: Java objects.
Clojure allows you to work with Java object as well as native Clojure structures, but Java objects are still Java objects and full of umanaged state. It cannot be helped. A good Clojure program will use Java objects only for interfacing with Java libraries, and therefore restrict the use of mutable state.
Immutability
immutable data structures, 非常重要的特性, 对于数据结构的改变采取copy的方式, 并通过share and only store differential (persistence data)的方式来提高效率. 当数据结构没人使用时, 会被silently的GC掉. 这种模式还非常有利于, rollback, 实现undo, backtracking
One of the most important ways in which Clojure encourages purely functional style where possible is to provide a capable, high-performance set of immutable data structures.
Immutable data structures are, as their name suggests, data structures that cannot change. They are created with a specific value or contents, which remain constant over the entire life cycle of the object. This ensures that the object can be freely used in multiple places, from multiple threads, without any fear of race conditions or other conflicts. If an object is read-only, it can always be safely and immediately read from any point in the program.
This begs the obvious question: What if the program logic requires that the value of a data structure change? The answer is simple—rather than modifying the existing data structure (causing all kinds of potentially bad effects for other parts of the program that use it), the structure is copied with the changes in place (see Figures 1-4 and 1-5). The old object remains exactly as it was, and other threads or portions of code currently operating on it will continue to function without problems, unaware that there is a new version. Meanwhile, the code that “changed” the object uses the new object, identical to the old one except for the modifications.


This sounds as if it might be extremely inefficient, but it isn't. Because the base object is immutable, the “modified” object can share its structure except for the actual point of change. The system only needs to store the differential, not an entire copy. This property is called persistence—a data structure shares memory with the previous version of itself. There is a small computational time overhead when making a change, but the memory usage can often actually be lower. In many scenarios, objects can share large parts of their structure, increasing efficiency. Old versions of objects are maintained as long as they are used as part of a newer version (or referenced from elsewhere), and are silently garbage collected when they are no longer useful.
Another interesting effect of immutable, persistent data objects is that it is easy to maintain previous versions and roll back through them as necessary. This makes it extremely easy and efficient to implement things like undo histories or backtracking algorithms.
Clojure provides the following common immutable data structures:
• Linked lists: These are simple, singly-linked lists that support fast traversal and insertion.
• Vectors: Similar to an array, vectors are indexed by integer values and support extremely fast lookup by index.
• Hash maps: Hash maps use hash trie datastructures to provide unordered storage for key/value pairs and support extremely fast lookups.
• Sorted maps: Sorted maps also provide key/value lookups, using a balanced binary tree as the underlying implementation. They are also, unsurprisingly, sorted, and provide operations for range-based access at the cost of being slightly slower than hash maps.
• Hash and sorted sets: Sets are groups of distinct items, similar to the mathematical concept. They support operations such as finding the union, difference, and intersection. They can be implemented as hash tries or using a binary tree with similar performance tradeoffs as the map implementations.
State Management
In this paradigm, it is entirely the responsibility of the programmer to ensure that state manipulation and access is done in a reasonable way that does not cause problems.
It was never easy. Even in the simplest case, extensive use of mutable state makes programs difficult to reason about—any part of the program can change state, and it's not easy to tell where it's happening. Rich Hickey, Clojure's inventor, calls mutable, stateful objects “the new spaghetti code.”
Unfortunately, with the advent of multithreaded programs, the difficult of managing state increases exponentially.
Not only must a programmer understand possible program states, but they must go to great lengths to ensure that state is protected and modified in an orderly way to prevent corrupted data and race conditions. This, in turn, requires complicated locking policies—policies which there is no way of enforcing. Failure to comply with these policies does not cause obvious problems, but rather insidious bugs that often do not surface until the application is under load in a production setting, and can be nearly impossible to track down.
In general, enabling concurrency in a traditional language requires thoughtful planning, an extremely thorough grasp of execution paths and program structure, and extreme care in implementation.
Clojure provides an alternative: a fast, easy way for programmers to use as much state as they need without any extra effort to manage it, even in a highly concurrent setting.
It accomplishes this through its particular philosophy of state and identity, its immutable objects, and software transactional memory (STM).
State确实造成代码的难以debug和难以维护, 尤其是在多线程的情况下, 管理难度成指数增长.
Clojure使用STM机制来简单的解决这个问题...
Software Transactional Memory
STM技术基于数据不变性, 其实数据不变性一直存在
对于传统语言, 如c++,
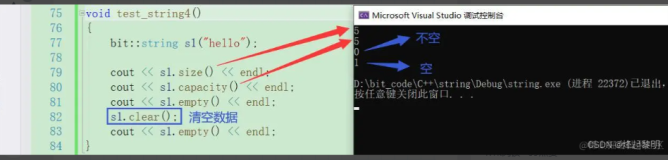
如, x=3, x+1
确实是将x变量地址上的数据, 从011替换成了100, 但你肯定不会认为3本身变成了4, 常量本身是客观存在的.
对于象Python这样的动态语言其实和clojure很像, 一切都是object, 3, 4本身也是object,
x=3, x+1 , 只是将reference x分别指向3和4的object
只不过, clojure做的很彻底, 所有数据结构都是这样的不可变的, 包括list, set等, 而这点确实之前的语言都没有这样处理, 当然主要因为他们计算模型不同
当然clojure里面也引入identity, 即reference, 使其指向不同的不可变的value, 就可以实现状态的变化.
这样处理的好处是, 直接改数据结构可能需要一段时间, 比如list插入10个item, 原子性很容易被破坏.
而现在你可以花很长时间构造新的数据结构, 这不影响任何人, 然后只是切换一下identity, 完美是实现了原子性.
这个思路和couchDB非常的象, nothing or all
还没完, 因为多线程会并发修改identity的指向, 所以如果要做到互不干扰, 就引入transaction概念, 完全和数据库的概念一样, 在transaction中可以保证atomic, consistent, isolated
Clojure tracks this by introducing the concept of identity, as distinct from value. Identity, in Clojure, is a named referencethat points to an object.
In the above example, there would be one identity, for example, debtors. At one point in time, debtors refers to S1, and, at another time, is updated to refer to S2. But this update is atomic, and therefore avoids concurrency effects like race conditions. There is no point at which the value of debtors is in an ambiguous state—it always refers to either S1 or S2,never something halfway. It is always safe to retrieve the current value of debtors, and it is always safe to swap its value for a new one.

Clojure provides software transactional memory (STM).
STM works by providing an extra management layer between the program and the computer's memory.
Whenever a program needs to coordinate changes to one or more identities, it wraps the exchange in a transaction, similar in concept to those used to ensure integrity in database systems.
Within a transaction, the programmer can perform multiple calculations based on identities, assign them new values and then commit the changes. From the perspective of the rest of the program, transactions happen instantaneously and atomically: First the identities have one value, and then another, with no need to worry about intermediate states or inconsistent data. If two transactions conflict, one is forced to retry, starting over with new values of the identities involved. This happens automatically; the programmer just writes the code, the transaction logic is handled automatically by the STM engine.
Clojure makes the following guarantees. Transactions are always:
• Atomic. Either all the changes made in a transaction are committed to an identity or none are. The program will never commit some changes and not others. This provides guaranteed protection from corrupting data or creating any kind of inconsistent state.
• Consistent. Transactions can be validated before they are committed. Clojure provides an easy mechanism for adding run-time checks to make sure that the new value is always what it ought to be, and that there are no problems with the new value before it is assigned to an identity.
• Isolated. No transaction “sees” the effects of any other transaction while it is running. At the beginning of the transaction, the program takes a “snapshot” of all identities involved, which it uses for all its operations. This ensures code within transactions can be written freely, without any worry that the identities might have changed and, so to speak, swept the rug out from under the executing code.
本文章摘自博客园,原文发布日期:2013-01-18