什么是快速排序
快速排序简介
快速排序(英文名:Quicksort,有时候也叫做划分交换排序)是一个高效的排序算法,由Tony Hoare在1959年发明(1961年公布)。当情况良好时,它可以比主要竞争对手的归并排序和堆排序快上大约两三倍。这是一个分治算法,而且它就在原地排序。
所谓原地排序,就是指在原来的数据区域内进行重排,就像插入排序一般。而归并排序就不一样,它需要额外的空间来进行归并排序操作。为了在线性时间与空间内归并,它不能在线性时间内实现就地排序,原地排序对它来说并不足够。而快速排序的优点就在于它是原地的,也就是说,它很节省内存。
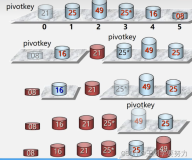
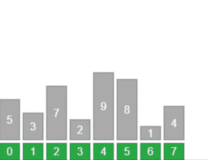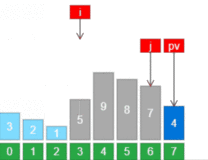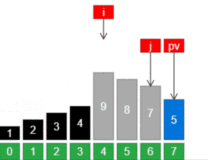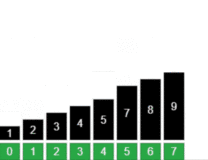
引用一张来自维基百科的能够非常清晰表示快速排序的示意图如下:

快速排序的分治思想
由于快速排序采用了分治算法,所以:
一、分解:本质上快速排序把数据划分成几份,所以快速排序通过选取一个关键数据,再根据它的大小,把原数组分成两个子数组:第一个数组里的数都比这个主元数据小或等于,而另一个数组里的数都比这个主元数据要大或等于。

二、解决:用递归来处理两个子数组的排序。 (也就是说,递归地求上面图示中左半部分,以及递归地求上面图示中右半部分。)
三、合并:因为子数组都是原址排序,所以不需要合并操作,通过上面两步后数组已经排好序了。
所以快速排序的主要思想是递归与划分。
如何划分
当然最重要的是它的复杂度是线性的,也就是Θ(n)个划分的子程序。
Partition(A,p,q) // A[p,..q]
1 x=A[p] // pivot=A[p] 主元
2 i=p
3 for j=p+1 to q
4 do if A[j]<=x
5 then i=i+1
6 exch A[i]<->A[j]
7 exch A[p]<->A[i]
8 return i // i pivot 这就是划分的伪代码,基本的结构就是一个for循环语句,中间加上了一个if条件语句,它实现了对子数组A[p...q]的原址排序。

刚开始时i等于p,j等于p+1。在这个循环中查找i下标的数据,如果它比x大,那就将其存放到“>=x”区域并将j加1后进行下一次循环。而如果它比x小,那就要做些动作来维持循环不变量了。将i的下标加1后将下标i对应的数据和下标j所对应的数据互换位置。然后再移动区域的界限并开始下一次循环。
那么这个算法在n个数据下的运行时间大约是O(n),因为它几乎把每个数都比较了一遍,而每个步骤所需的时间都为O(1)。

上面这幅图详细的描述了Partition过程,每一行后也加了注释。
将递归的思想作用于划分上
有了上面这些准备工作,再加上分治的思想实现快速排序的伪代码也是很简单的。
Quicksort(A,p,q)
1 if p<q
2 then r=Partition(A,p,q)
3 Quicksort(A,p,r-1)
4 Quicksort(A,r+1,q) 为了排序一个数组A的全部元素,初始调用时Quicksort(A,1,A.length)。
快速排序的算法分析
相信通过前面的诸多实践,大家也发现了快速排序的运行时间依赖于Partition过程,也就是依赖于划分是否平衡,而归根结底这还是由于输入的元素决定的。
如果划分是平衡的,那么快速排序算法性能就和归并排序一样。
如果划分是不平衡的,那么快速排序的性能就接近于插入排序。
怎样是最坏的划分
1)输入的元素已经排序或逆向排序
2)每个划分的一边都没有元素
也就是说当划分产生的两个子问题分别包含了n-1个元素和0个元素时,快速排序的最坏情况就发生了。
T(n)=T(0)+T(n−1)+\Theta(n)=Θ(1)+T(n−1)+Θ(n)=Θ(n−1)+Θ(n)=Θ(n2)
这是一个等差级数,就和插入排序一样。它并不比插入排序快,因为当同样是输入元素已经逆向排好序时,插入算法的运行时间为Θ(n)。但快速排序仍旧是一个优秀的算法,这是因为在平均情况下它已经很高效。
我们为最坏情况画一个递归树。

这是一课高度不平衡的递归树,图中左边的那些T(0)的运行时间都为Θ(1),而总共有n个。
所以算法的中运行时间为:
T(n)=Θ(n)+Θ(n2)=Θ(n2)
最坏划分的算法分析
通过上面的图示我们知道了在最坏情况下快速排序的复杂度是Θ(n2),但以图示的方式并不是一种严谨的证明方式,我们应该使用代入法来证明它。
当输入规模为n时,时间T(n)有如下递归式:
T(n)=max0≤r≤n−1(T(r)+T(n−r−1))+Θ(n)
除去主元后,在Partition函数中生成的两个子问题的规模的和为n-1,所以r的规模才是0到n-1。
假设T(n)≤cn2成立,其中c为常数这个大家都知道的。于是上面的递归式为:
T(n)≤max0≤r≤n−1(cr2+c(n−r−1)2)+Θ(n)≤c∗max0≤r≤n−1(r2+(n−r−1)2)+Θ(n)
1)而r2+(n−r−1)2对于r的二阶导数为正,所以在区间0≤r≤n−1的右端点取得最大值。
于是有max0≤r≤n−1(r2+(n−r−1)2)≤(n−1)2=n2−2n+1,所以对于T(n)有:
T(n)≤cn2−c(2n−1)+Θ(n)
最终因为我们可以选择一个足够大的c,来使得c(2n−1)大于Θ(n),所以有T(n)=O(n2)。
2)r2+(n−r−1)2对于r的二阶导数为正,所以在区间0≤r≤n−1的左端点取得最小值。
于是有max0≤r≤n−1(r2+(n−r−1)2)≥(n−1)2=n2−2n+1,所以对于T(n)有:
T(n)≥cn2−c(2n−1)+Θ(n)
同样我们也可以选择一个足够小的c,来使得c(2n−1)小于Θ(n),所以有T(n)=Ω(n2)。
综上这两点得到T(n)=Θ(n2)
怎样是最好的划分
当Partition将数组分为n/2和n/2两个部分时是最高效的。此时有:
T(n)=2T(n/2)+Θ(n)=Θ(nlgn)
怎样是平衡的划分
快速排序的平均运行时间更接近于其最好情况,而非最坏情况。
此处有一个经典的示例,将数组按1:9的比例进行划分会怎样呢?这种划分看似很不平衡,但真的会因此而影响效率么?
其中此时的递归式是:
T(n)=T(110n)+T(910n)+Θ(n)
这里依旧通过递归树来观察一番。

因为每次都减少十分之一,需要减多少次才能达到n呢,也恰好也是以10为底对数的定义。所以左侧的高度为log10n了,相应的右侧的高度为log109n。
所有那些叶子加在一起也只有Θ(n),所以有:
T(n)≤cn∗log109n+Θ(n)
其实T(n)的下界也渐近为nlgn,所以总时间为:
T(n)=Θ(nlgn)
只要划分是常数比例的,算法的运行时间总是O(nlgn)。
随机化快速排序
随机算法的思想
在前面分析快速排序的平均情况性能时,是建立在输入数据的所有排列都是等概率的条件下的,但在实际工程中往往不会总出现这种良好的情况。
在【算法】3 由招聘问题看随机算法中我们介绍了随机算法,它使得对于所有的输入都有着较好的期望性能,因此随机化快速排序在有大量数据输入的情况下是一种更好的排序算法。
以下是随机化快速排序的好处:
1)其运行时间不依赖与输入序列的顺序
2)无需对输入序列的分布做任何假设
3)没有 一种特别的输入会引起最差的运行情况
4)最差的情况由随机数产生器决定
随机抽样技术
现在我们来使用一种叫做随机抽样(random sampling)的随机化技术,使用该技术就不再始终采用A[p]作为主元,而是从A[p…q]中随机选择一个元素作为主元。
为了达到这一目的,首先将A[p]与从A[p...q]中随机选出的一个元素交换。
通过对序列p...q的随机抽样,我们可以保证主元元素x=A[p]是等概率地从子数组的q−p+1个元素中选取的。
因为主元元素是随机选择的,我们可以期望在平均情况下对输入数组的划分是比较均衡的。所以对前面的两份伪代码做如下修改:
RANDOMIZED-PARTITION(A,p,q)
1 i=RANDOM(p,q)
2 exchange A[p] with A[i]
3 return PARTITION(A,p,q)RANDOMIZED-QUICKSORT(A,p,q)
1 if p<q
2 r=RANDOMIZED-PARTITION(A,p,q)
3 RANDOMIZED-QUICKSORT(A,p,r-1)
4 RANDOMIZED-QUICKSORT(A,r+1,q)有了随机抽样技术后再也不用担心快速排序遇到最坏划分的情况啦,所以说随机化快速排序的期望运行时间是O(nlgn)。
回顾比较排序
相信阅读过前面5篇博文的童鞋们已经发现了“在排序的最终结果中,各元素的次序依赖于它们之间的比较”。于是乎,这类排序算法被统称为”比较排序“。
比较排序是通过一个单一且抽象的比较运算(比如“小于等于”)读取列表元素,而这个比较运算则决定了每两个元素中哪一个应该先出现在最终的排序列表中。
声明:下面通过在维基百科中找到的非常完美的图示来介绍一系列比较排序。
插入排序
在该系列的【算法】1中我们便介绍了这个基本的算法,它的比较过程如下:

以下是用插入排序对30个元素的数组进行排序的动画:

选择排序
选择排序的比较过程如下:

其动画效果如下:

归并排序
前面多次写到归并排序,它的比较过程如下:

归并排序的动画如下:

堆排序
在该系列的【算法】4中我们便介绍了快排,构建堆的过程如下:

堆排序的动画如下:

快速排序
在该系列的【算法】5中我们便介绍了快排,它的比较过程如下:

快速排序的动画如下:

另外一些比较排序
以下这些排序同样也是比较排序,但该系列中之前并未提到。
Intro sort
该算法是一种混合排序算法,开始于快速排序,当递归深度超过基于正在排序的元素数目的水平时便切换到堆排序。它包含了这两种算法优良的部分,它实际的性能相当于在典型数据集上的快速排序和在最坏情况下的堆排序。由于它使用了两种比较排序,因而它也是一种比较排序。
冒泡排序
大家应该多少都听过冒泡排序(也被称为下沉排序),它是一个非常基本的排序算法。反复地比较相邻的两个元素并适当的互换它们,如果列表中已经没有元素需要互换则表示该列表已经排好序了。(看到列表就想到半年前在学的Scheme,欢迎大家也去看看,我开了2个专栏来介绍它们)
上面的描述中已经体现了比较的过程,因而冒泡排序也是一个比较排序,较小的元素被称为“泡(Bubble)”,它将“浮”到列表的顶端。
尽管这个算法非常简单,但大家应该也听说了,它真的非常的慢。
冒泡排序的过程如下:

冒泡排序的动画演示:

其最好情况、最坏情况的运行时间分别是:Θ(n)、Θ(n2)。
奇偶排序
奇偶排序和冒泡排序有很多类似的特点,它通过比较在列表中所有的单双号索引的相邻元素,如果有一对是错误排序(也就是前者比后者大),那么将它们交换,之后不断的重复这一步骤,直到整个列表排好序。
而鉴于此,它的最好情况、最坏情况的运行时间均和冒泡排序相同:Θ(n)、Θ(n2)。
奇偶排序的演示如下:

下面是C++中奇偶排序的示例:
template <class T>
void OddEvenSort (T a[], int n)
{
for (int i = 0 ; i < n ; i++)
{
if (i & 1) // 'i' is odd
{
for (int j = 2 ; j < n ; j += 2)
{
if (a[j] < a[j-1])
swap (a[j-1], a[j]) ;
}
}
else
{
for (int j = 1 ; j < n ; j += 2)
{
if (a[j] < a[j-1])
swap (a[j-1], a[j]) ;
}
}
}
}双向冒泡排序
双向冒泡排序也被称为鸡尾酒排序、鸡尾酒调酒器排序、摇床排序、涟漪排序、洗牌排序、班车排序等。(再多再华丽丽的名字也难以弥补它的低效)
和冒泡排序的区别在于它是在两个方向上遍历列表进行排序,虽然如此但并不能提高渐近性能,和插入排序比起来也没太多优势。
它的最好情况、最坏情况的运行时间均和冒泡排序相同:Θ(n)、Θ(n2)。

排序算法的下界
我们可以将排序操作进行得多块?
这取决于计算模型,模型简单来说就是那些你被允许的操作。
决策树
决策树(decision tree)是一棵完全二叉树,它可以表示在给定输入规模情况下,其一特定排序算法对所有元素的比较操作。其中的控制、数据移动等其他操作都被忽略了。

这是一棵作用于3个元素时的插入排序的决策树。标记为i:j的内部结点表示ai和aj之间的比较。
由于它作用于3个元素,因此共有A33=6种可能的排列。也正因此,它并不具有一般性。
而对序列<a1=7,a2=2,a3=5>和序列<a1=5,a2=9,a3=6>进行排序时所做的决策已经由灰色和黑色粗箭头指出了。

决策树排序的下界
如果决策树是针对n个元素排序,那么它的高度至少是nlgn。
在最坏情况下,任何比较排序算法都需要做Ω(nlgn)次比较。
因为输入数据的Ann种可能的排列都是叶结点,所以Ann≤l,由于在一棵高位h的二叉树中,叶结点的数目不多于2h,所以有:
n!≤l≤2h
对两边取对数:
=> lg2h≥lgn!
=> lg2h=hlg2≥lgn!
又因为:
lg2<1
所以:
n≥lgn!=Ω(nlgn)
因为堆排序和归并排序的运行时间上界均为O(nlgn),因此它们都是渐近最优的比较排序算法。
线性时间排序
计数排序
计数排序(counting sort)的思路很简单,就是确定比x小的数有多少个。加入有10个,那么x就排在第11位。
严谨来讲,在计算机科学中,计数排序是一个根据比较键值大小的排序算法,它也是一个整数排序算法。它通过比较对象的数值来操作,并通过这些计数来确定它们在即将输出的序列中的位置。它的运行时间是线性的且取决于最大值和最小值之间的差异,当值的变化明显大于数目时就不太适用了。而它也可以作为基排序的子程序。
COUNTING-SORT(A,B,k)
1 let C[0...k] be a new array
2 for i=0 to k
3 C[i]=o
4 for j=1 to A.length
5 C[A[j]]=C[A[j]]+1
6 // C[i] now contains the number of element equal to i.
7 for i=1 to k
8 C[i]=C[i]+C[i-1]
9 // C[i] now contains the number of element less than or equal to i.
10 for j=A.length downto 1
11 B[C[A[j]]]=A[j]
12 C[A[j]]=C[A[j]]-1第2-3步,C数组的元素被全部初始化为0,此时耗费Θ(k)时间。
第4-5步,也许不太好想象,其实就是在C数组中来计数A数组中的数。比如说,A数组中元素”3”有4个,那么C[3]=4。此时耗费Θ(n)时间。
第7-8步,也是不太好想象的计算,也就是说如果C[0]=1、C[1]=4,那么计算后的C[0]不变,C[1]=5。此时耗费Θ(k)时间。
第10-12步,把每个元素A[j]放到它在输出数组B中的合适位置。比如此时的第一次循环,先找到A[8],然后找到C[A[8]]的值,此时C[A[8]]的意义就在于A[8]应在B数组中的位置。完成这一步后将C[A[8]]的值减一,因为它只是一个计数器。这里耗费的时间为Θ(n)。

当k=O(n)时,计数排序的运行时间为Θ(n)。
基数排序
基数排序(radix sort)是一个古老的算法,它用于卡片排序机上。说来也巧,写这篇博客的前一天晚上还在书上看到这种机器,它有80列,每一列都有12个孔可以打。
它可以使用前面介绍的计数排序作为子程序,然而它并不是原址排序;相比之下,很多运行时间为Θ(nlgn)的比较排序却是原址排序。因此当数据过大而内存不太够时,使用它并不是一个明智的选择。

关键在于依次对从右往左每一列数进行排序,其他的列也相应移动。
桶排序
这倒是一个有趣的算法了,它充分利用了链表的思想。
桶排序(bucket sort)在平均情况下的运行时间为O(n)。
计数排序假设n个输入元素中的每一个都在0和k之间,桶排序假设输入数据是均匀分布的,所以他们的速度都非常快。但并不能因为这些是假设就说它们不实用不准确,真正的意义在于你可以根据情况选择合适的算法。比如说,输入的n个元素并不是均匀分布的,但它们都在0到k之间,那么就可以用计数排序。
说到桶,我想到的是装满葡萄酒的酒桶以及装满火药的火药桶。这里是桶是指的算法将[0,1)区域划分为了n个相同大小的空间,它们被称为桶。
既然有了这个划分,那么就要用到它们。假设输入的是n个元素的数组A,且对于所有的i都有0≤A[i]<1。你也许会觉得怎么可能输入的数组元素都凑巧满足呢,当然不会这么凑巧,但是你可以人为地改造它们呀。比如<10,37,31,87>,你可以将它们都除以100,得到<0.10,0.37,0.31,0.87>。
还需要一个临时的数组B[0…n-1]来保存这些桶(也就是链表),而链表支持搜索,删除和插入。关于链表的部分后面的博客中会有详细介绍。
BUCKET-SORT(A)
1 n=A.length
2 let B[0...n-1] be a new array
3 for i=0 to n-1
4 make B[i] an empty list
5 for i=1 to n
6 insert A[i] into list B[小于等于nA[i]的最大整数]
7 for i=0 to n-1
8 sort list B[i] with insertion sort
9 concatenate the lists B[0],B[1],...B[n-1] together in order
学习算法一定要体会到这种算法内每一步的改变,也要体会不同算法之间的演化和进步。在后面的链表中,我会更加侧重于思路以及算法的进化。