热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
python自定义日历库,与对应calendar库函数功能基本一致
C语言中逻辑表达式的深入探讨
C语言中字符串的引用与数组元素操作
C语言字符常量详解
DSP加密方式研究
DSP芯片分类与应用
Java Class类
Java Object类
Python 一步一步教你用pyglet制作汉诺塔游戏
Java String类
Java包装类
JAVA变量类型
JAVA对象和类
python INI文件操作与configparser内置库
Java枚举类
Java日期与时间处理详解
Java日期与时间
JAVA注解
Python安装与配置
Pyglet综合应用|推箱子游戏地图编辑器之图片跟随鼠标
Python变量
Python变量类型
Python常用镜像源
Python函数
python环境搭建
Python基础语法文章大纲
Linux 网络操作命令FTP
Python简史
Python开根号的几种方式
Linux 网络操作命令Telnet
Python控制语句
Python列表转字符串
python 又一个点运算符操作的字典库:Munch
Python实现计算器的设计与实现
Python线程池
Python运算符
Linux文件查看和编辑命令
Python运算深入探索
Python中的逻辑运算符:且(and)与或(or)
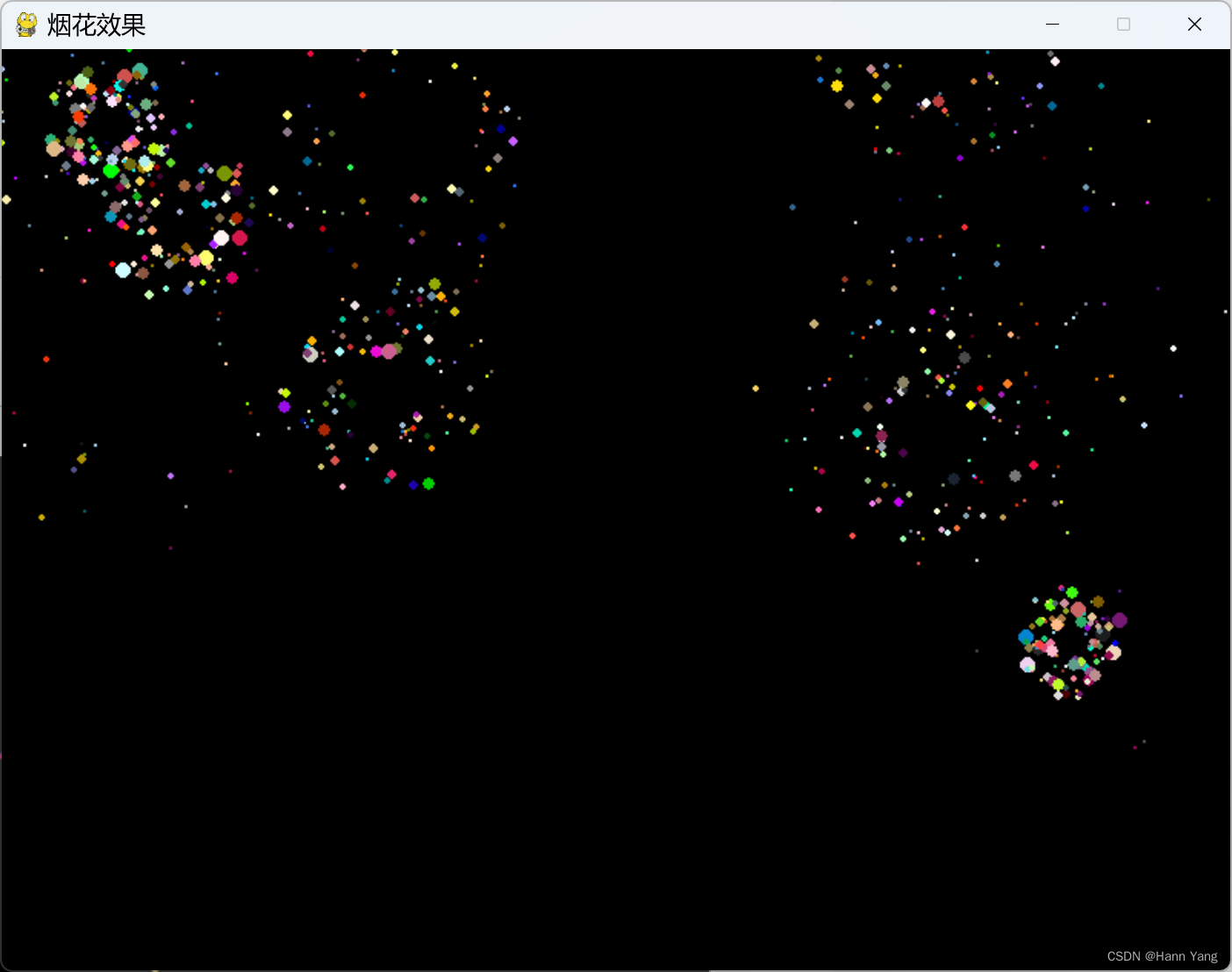
pygame 烟花效果
Python中的注释
单片机与存储器
关于C语言中关系表达式
使用 Python 循环创建多个列表
< 每日算法:一文带你认识 “ 双指针算法 ” >
前端UI组件