热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
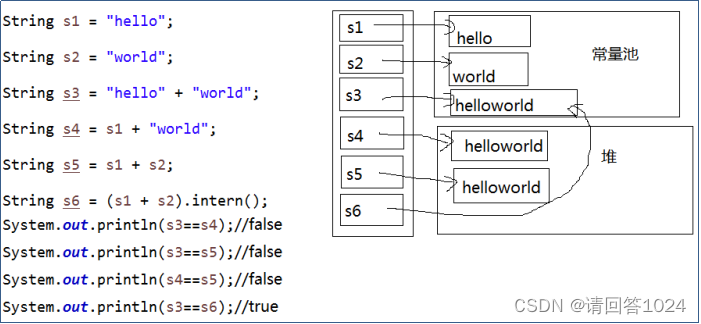
Java 的 String StringBuilder StringBuffer(下)
第八章 Python可迭代对象、迭代器和生成器
Java 的 String StringBuilder StringBuffer
第七章 Python异常处理
不标识@TableName、@TableField和@TableID注解会发生什么?
第六章 Python类(面向对象编程)
深入理解 @TableName 和 @TableField 注解
解释pom中的依赖dependency
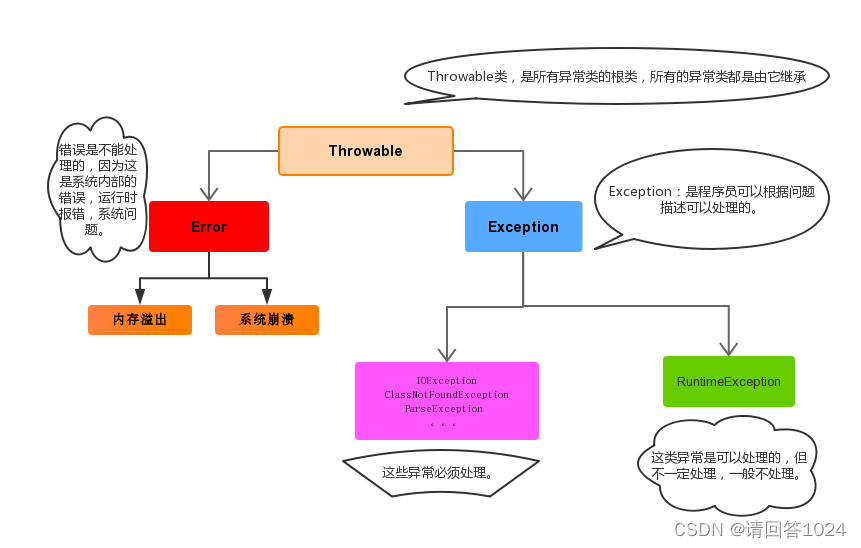
JavaSE&Java的异常
第五章 Python函数你知多少
store下的getter.js什么作用
Vue.js 路由时用于提高应用程序性能
一键云端,AList 整合多网盘,轻松管理文件多元共享
第四章 Python运算符与流程控制
【Vue】内置指令真的很常用!
第三章 Python丰富的数据类型
Servlet3.0 新特性全解
硬盘对拷(硬盘复制)操作指南
【Vue】过滤器Filters
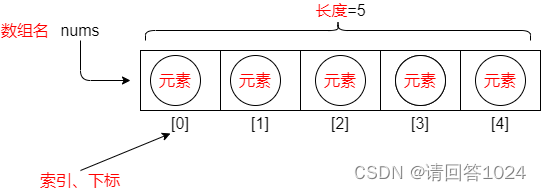
Java的数组
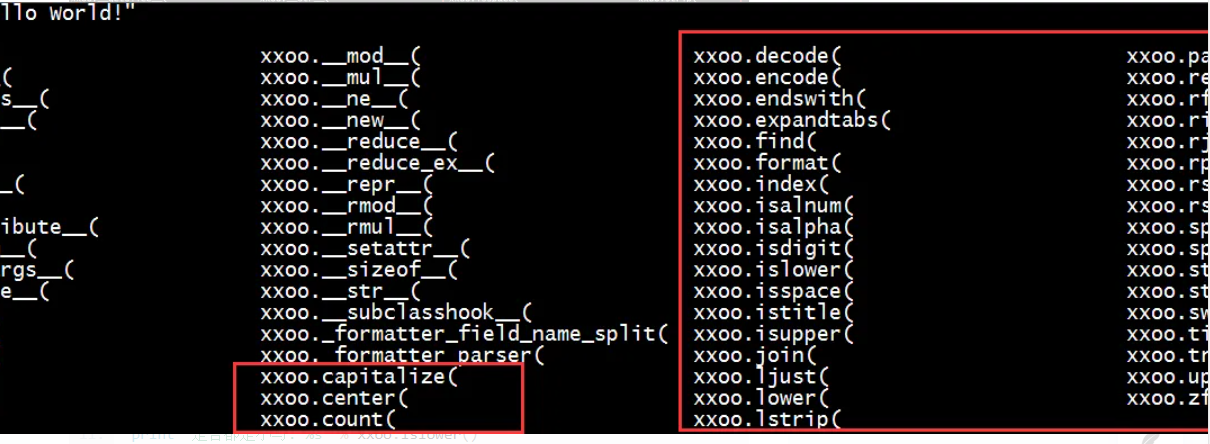
第二章 Python字符串处理和编码不再发愁
Mysql的NULLIF
Linux系统之jq工具的基本使用
Linux 防火墙开启端口
java使用jodd操作html
filebeat 设置索引的 max_result_window
第一章 Python基础知识
HTTP 协议初探
【好玩的经典游戏】Docker部署FC-web游戏模拟器
suno-api
[AIGC 大数据基础] 大数据流处理 Kafka
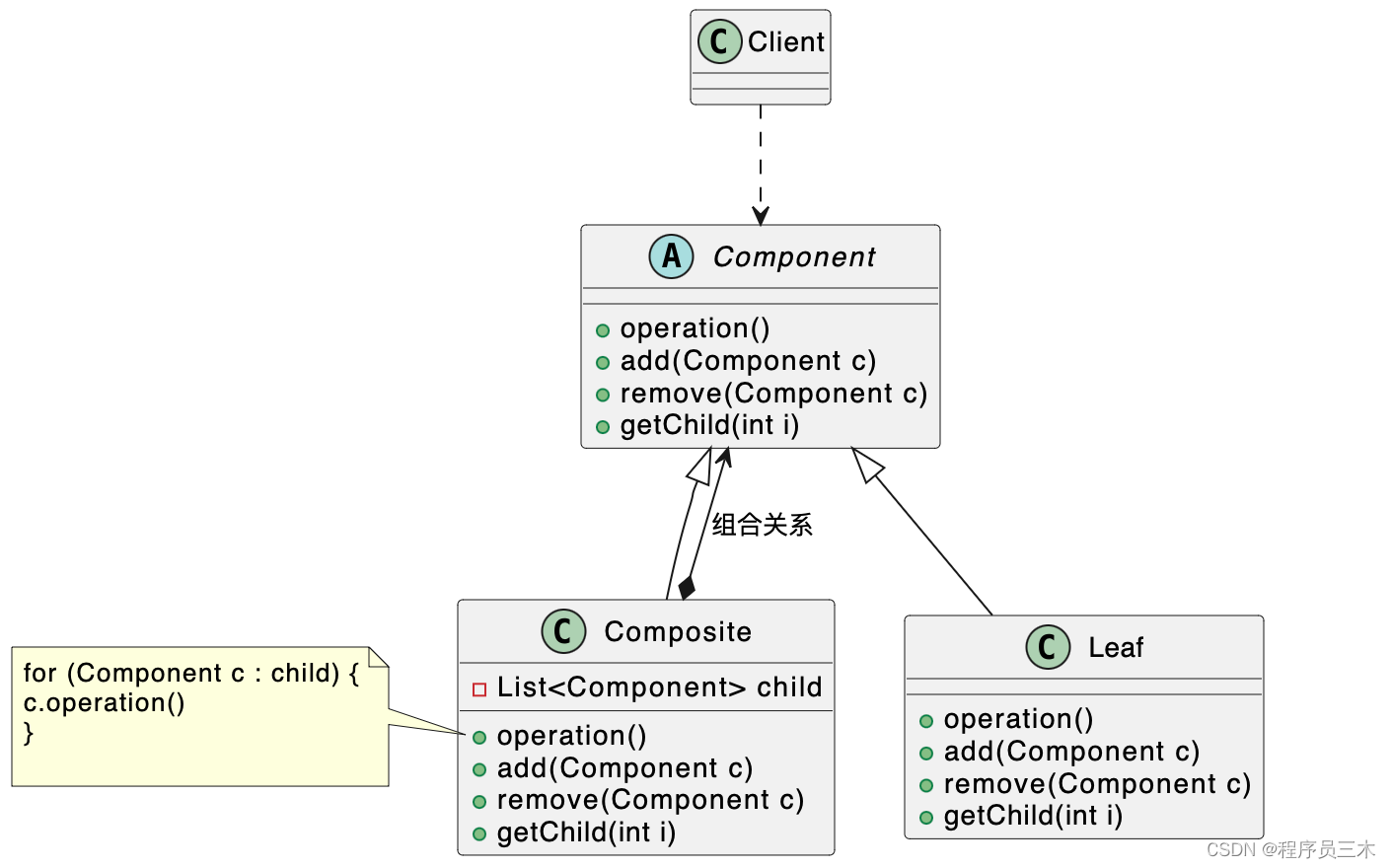
[设计模式Java实现附plantuml源码~结构型]树形结构的处理——组合模式
MySQL 数据类型剖析
dromara-newcar
[大数据] mac 史上最简单 hadoop 安装过程
[AIGC 大数据基础]浅谈hdfs
linux系统被×××后处理经历
参加训练营 提升SQL技能
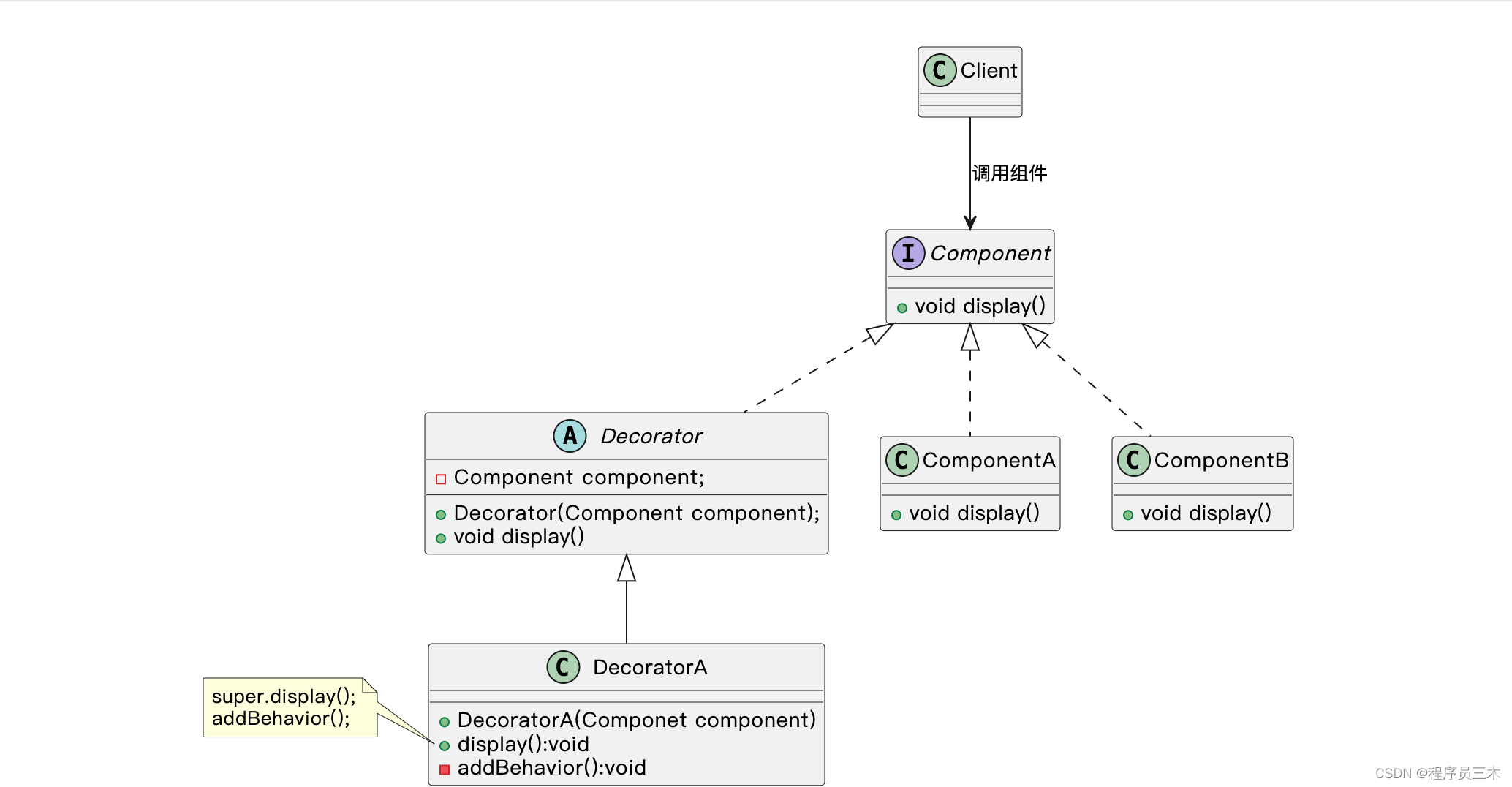
[设计模式Java实现附plantuml源码~结构型] 扩展系统功能——装饰模式
《SQL必知必会》个人笔记
octokit.js
[AIGC大数据基础] Flink: 大数据流处理的未来
mybatis判断批量操作是否全部执行成功
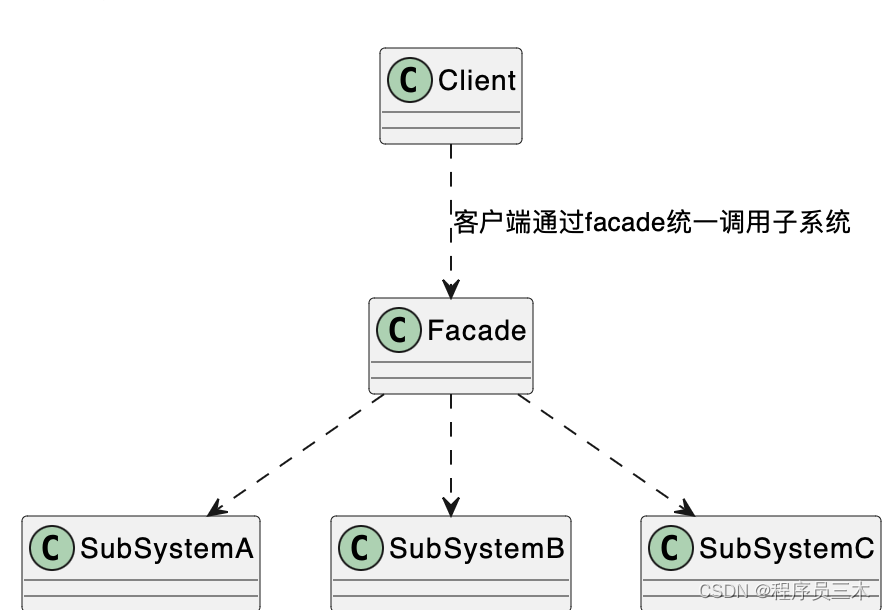
[设计模式Java实现附plantuml源码~结构型] 提供统一入口——外观模式
Awk使用案例总结(运维必会)
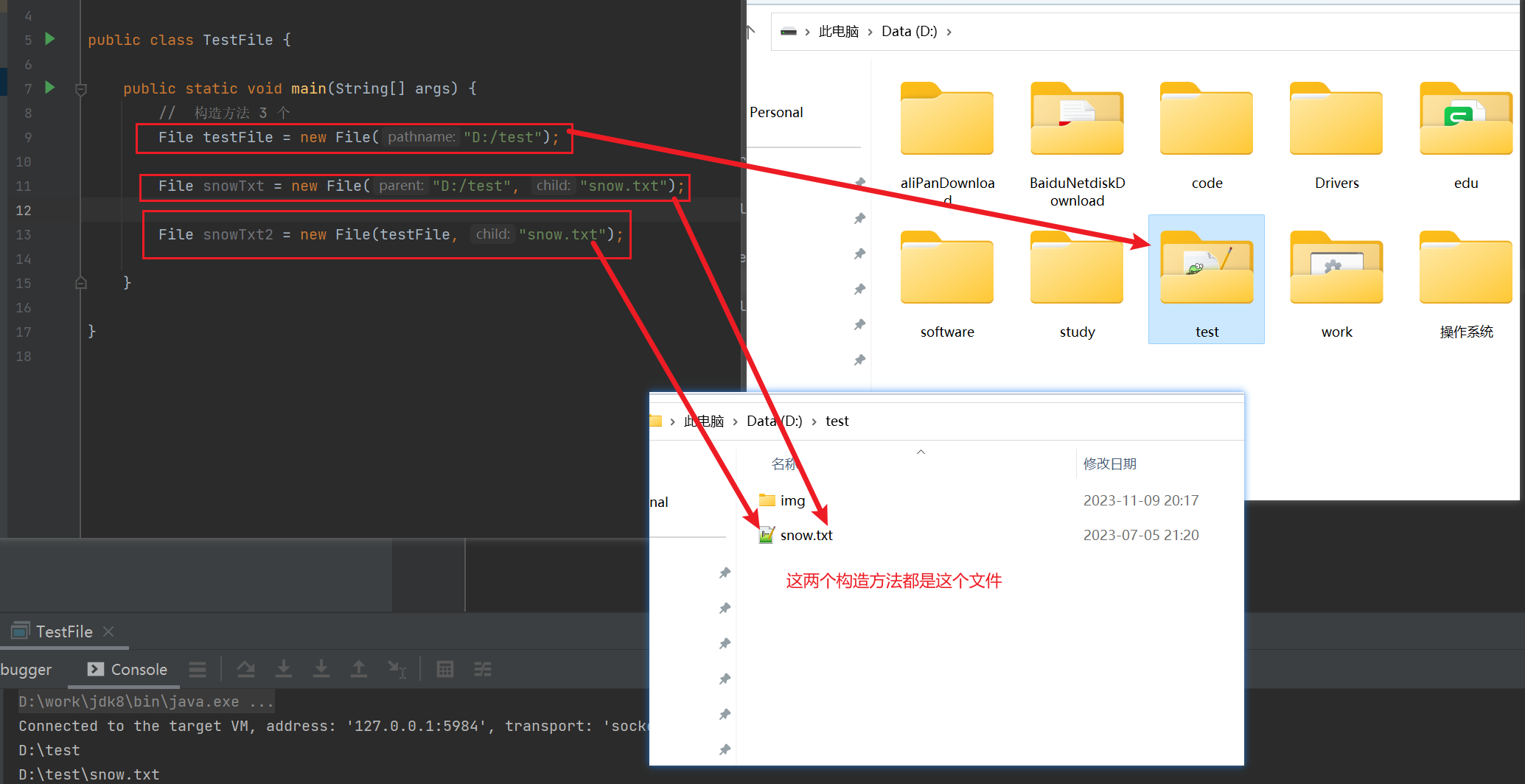
File 类及其方法