热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
效地减小图片文件的大小
html性能优化
产品优势及应用场景
日志服务产品架构
日志服务主要功能
Hadoop节点扩容网络性能测试
ECS使用体验的文章
Hadoop节点扩容网络设备与交换机检查
Hadoop节点扩容检查物理连接
要确定云服务提供商的数据安全性
如何选择云服务提供商?
网站建设步骤
无向图最小割问题取得新突破,谷歌研究获SODA 2024最佳论文奖
Meta无限长文本大模型来了:参数仅7B,已开源
极长序列、极快速度:面向新一代高效大语言模型的LASP序列并行
Linux服务器如何查询连接服务器的IP
centos如何将一般用户设置为超级权限
yum 如何设置可以将安装的rpm包都缓存下来
逻辑卷简介
Linux中的软RAID
磁盘
Java基础教程(17)-Java8中的lambda表达式和Stream、Optional
Threejs搭建web3D场景
8-20|https://gitlab.xx.com/api/v4/projects/4/trigger/pipeline Request failed状态码400
ubuntu升级Python版本
【JAVA】Java内存模型中的happen-before
【JAVA】强引用、软引用、弱引用、幻象引用有什么区别?
深度解析Redis的缓存双写一致性
精妙绝伦:玩转Spring事务编程的艺术
流畅把控:Redis中的滑动窗口算法实现限流
解放配置之道:Spring引入外部属性文件
探寻密码学的历史:从古代密码到现代加密技术的演变
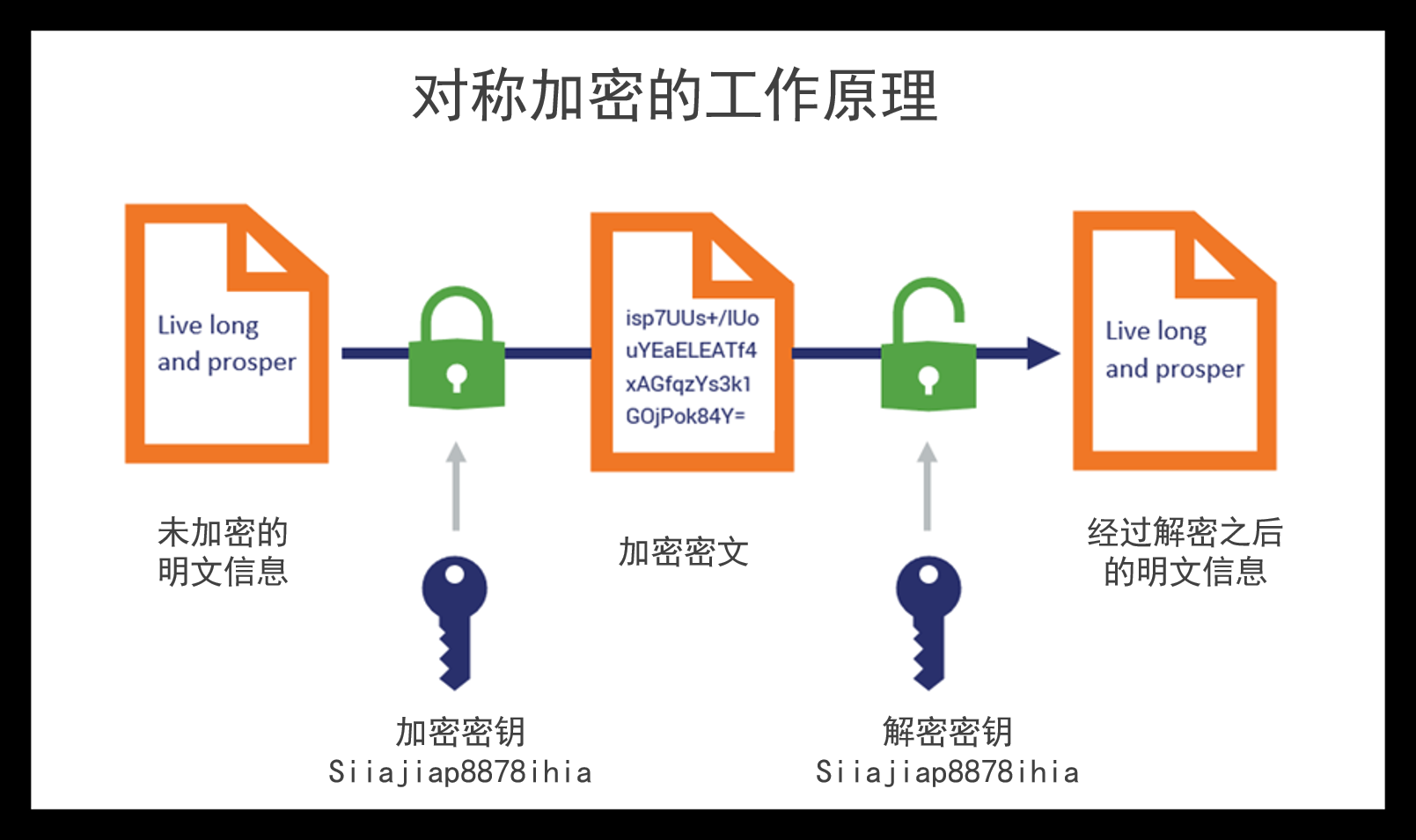
密码保护的神奇力量:对称密码算法的奥秘解析
公钥密码学:解密加密的魔法世界
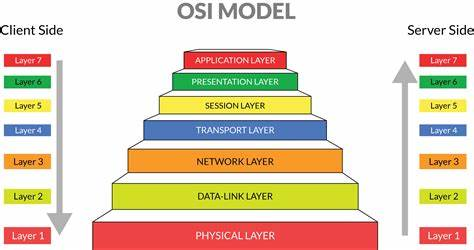
深入剖析:OSI模型解密
TCP IP协议簇:网络通信的基石
数字藏品开发原理丨鲸探幻核数字藏品系统开发功能分析
深入探讨MySQL中Varchar(50)和Varchar(500)的区别
如何实现基于Redis的在线人数统计功能?
MySQL锁解密:读锁与写锁
解锁MySQL的奥秘:探究表级锁、行级锁和页级锁的神秘面纱
MySQL锁之较量:悲观锁与乐观锁的对决
MySQL锁:解析隐式锁与显式锁
MySQL锁之权谋较量:共享锁、排它锁、独占锁的角逐
Spring Boot与Flowable的完美整合
Spring Boot接收参数的多种方式